






 本文回顾了语音识别技术从诞生至今的发展历程,包括GMM-HMM、DNN-HMM和端到端时代的演进。深度学习技术极大地提高了语音识别精度,尤其是在安静环境和标准口音下的识别率超过95%。尽管存在挑战,如多语种、大词汇量和多人识别,但语音识别已经在智能家居等领域得到广泛应用。未来,技术将朝着远场化和融合化方向发展,重点关注远场识别、噪声下的识别和多轮交互等问题。
本文回顾了语音识别技术从诞生至今的发展历程,包括GMM-HMM、DNN-HMM和端到端时代的演进。深度学习技术极大地提高了语音识别精度,尤其是在安静环境和标准口音下的识别率超过95%。尽管存在挑战,如多语种、大词汇量和多人识别,但语音识别已经在智能家居等领域得到广泛应用。未来,技术将朝着远场化和融合化方向发展,重点关注远场识别、噪声下的识别和多轮交互等问题。
语音识别自半个世纪前诞生以来,一直处于不温不火的状态,直到2009年深度学习技术的长足发展才使得语音识别的精度大大提高,虽然还无法进行无限制领域、无限制人群的应用,但也在大多数场景中提供了一种便利高效的沟通方式。本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。
语音识别,通常称为自动语音识别,英文是AutomaticSpeechRecognition,缩写为ASR,主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别(SpeechToText,STT)更合适,这样就能与语音合成(TextToSpeech,TTS)对应起来。
语音识别是一项融合多学科知识的前沿技术,覆盖了数学与统计学、声学与语言学、计算机与人工智能等基础学科和前沿学科,是人机自然交互技术中的关键环节。但是,语音识别自诞生以来的半个多世纪,一直没有在实际应用过程得到普遍认可,一方面这与语音识别的技术缺陷有关,其识别精度和速度都达不到实际应用的要求;另一方面,与业界对语音识别的期望过高有关,实际上语音识别与键盘、鼠标或触摸屏等应是融合关系,而非替代关系。
深度学习技术自2009年兴起之后,已经取得了长足进步。语音识别的精度和速度取决于实际应用环境,但在安静环境、标准口音、常见词汇场景下的语音识别率已经超过95%,意味着具备了与人类相仿的语言识别能力,而这也是语音识别技术当前发展比较火热的原因。
随着技术的发展,现在口音、方言、噪声等场景下的语音识别也达到了可用状态,特别是远场语音识别已经随着智能音箱的兴起成为全球消费电子领域应用最为成功的技术之一。由于语音交互提供了更自然、更便利、更高效的沟通形式,语音必定将成为未来最主要的人机互动接口之一。
当然,当前技术还存在很多不足,如对于强噪声、超远场、强干扰、多语种、大词汇等场景下的语音识别还需要很大的提升;另外,多人语音识别和离线语音识别也是当前需要重点解决的问题。虽然语音识别还无法做到无限制领域、无限制人群的应用,但是至少从应用实践中我们看到了一些希望。
本篇文章将从技术和产业两个角度来回顾一下语音识别发展的历程和现状,并分析一些未来趋势,希望能帮助更多年轻技术人员了解语音行业,并能产生兴趣投身于这个行业。
语音识别的技术历程
现代语音识别可以追溯到1952年,Davis等人研制了世界上第一个能识别10个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到今天已经有70多年,但从技术方向上可以大体分为三个阶段。
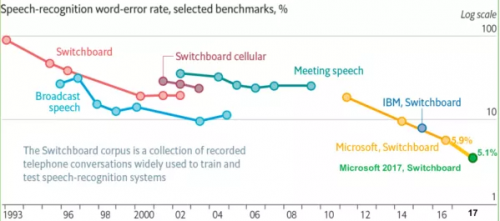
下图是从1993年到2017年在Switchboard上语音识别率的进展情况,从图中也可以看出1993年到2009年,语音识别一直处于GMM-HMM时代,语音识别率提升缓慢,尤其是2000年到2009年语音识别率基本处于停滞状态;2009年随着深度学习技术,特别是DNN的兴起,语音识别框架变为DNN-HMM,语音识别进入了DNN时代,语音识别精准率得到了显著提升;2015年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到2017年微软在Swichboard上达到词错误率5.1%,从而让语音识别的准确性首次超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。
GMM-HMM时代
70年代,语音识别主要集中在小词汇量、孤立词识别方面,使用的方法也主要是简单的模板匹配方法,即首先提取语音信号的特征构建参数模板,然后将测试语音与参考模板参数进行一一比较和匹配,取距离最近的样本所对应的词标注为该语音信号的发音。该方法对解决孤立词识别是有效的,但对于大词汇量、非特定人连续语音识别就无能为力。因此,进入80年代后,研究思路发生了重大变化,从传统的基于模板匹配的技术思路开始转向基于统计模型(HMM)的技术思路。
HMM的理论基础在1970年前后就已经由Baum等人建立起来,随后由CMU的Baker和IBM的Jelinek等人将其应用到语音识别当中。HMM模型假定一个音素含有3到5个状态,同一状态的发音相对稳定,不同状态间是可以按照一定概率进行跳转;某一状态的特征分布可以用概率模型来描述,使用最广泛的模型是GMM。因此GMM-HMM框架中,HMM描述的是语音的短时平稳的动态性,GMM用来描述HMM每一状态内部的发音特征。
基于GMM-HMM框架,研究者提出各种改进方法,如结合上下文信息的动态贝叶斯方法、区分性训练方法、自适应训练方法、HMM/NN混合模型方法等。这些方法都对语音识别研究产生了深远影响,并为下一代语音识别技术的产生做好了准备。自上世纪90年代语音识别声学模型的区分性训练准则和模型自适应方法被提出以后,在很长一段内语音识别的发展比较缓慢ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2429
2429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









