










闲聊
晚上失眠,把之前使用MongoDB时碰到的问题以及处理方法写下来,我是菜鸟,希望大家提出宝贵的意见。
环境
centos7+MongoDB3.2
问题描述
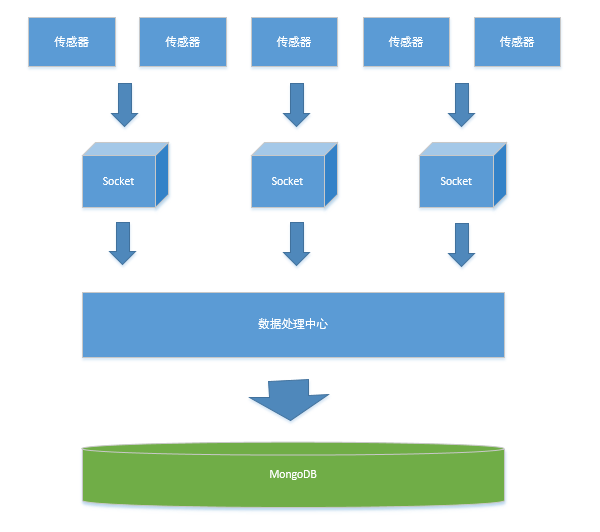
经过一段时间的使用发现MongoDB各方面都还算稳定,每天所有传感器通过socket采集过来的数据量大概有10w+,很快存放的集合数据量过于
庞大,而数据处理时的需求需要按升序处理并且过滤掉已经处理的数据,这样导致类似sql数据库的全表扫描和排序,严重占用了服务器cpu的资源。
之前的流程示例图
解决方法
方案一:开始的设想是采用redis等缓存数据库来存放未处理的数据,但是基于缓存数据库的搭建需要时间并且服务器当机等意外可能导致数据丢失,而服务器性能被影响,需要短时间内解决,暂时放弃。
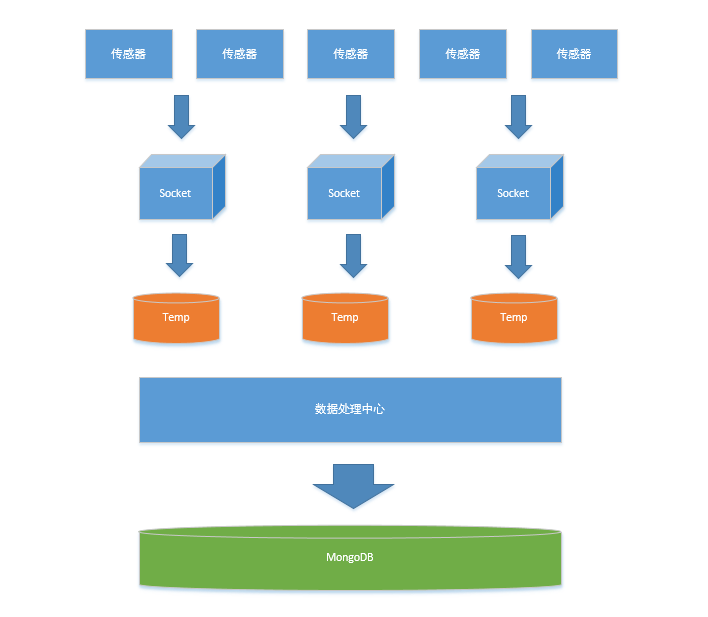
方案二:发现MongoDB在某些场合下也可以当缓存数据库来使用,于是直接在进入集合前,先放入MongoDB的临时集合存放,数据处理完毕后再移入集合。这样比较简单的解决了问题。
方案二示例图
未来方案设想:为了缩短中间存入操作产生的通讯成本(ps:soa架构牺牲了一些的通讯成本)后期设想通过MQ消息队列实现socket采集完数据直接推送至数据处理模块,欢迎大家留言讨论,后期还会继续更新实践。
明天还要上班,冲2个小时电先,晚安。 ^.^















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









