







在NLP的各项任务中,都需要对语料的长度有一个概括性的了解,例如平均长度、最大长度,大多数语料的长度范围等,以此来确定输入模型时的最大文本长度。pandas库有一种写法可以快速的统计文本语料的长度情况。
pd = pandas.Series(pos_data + neg_data).map(len)
print(pd.describe())pos_data和neg_data是存在list中的文本语料,上面两句的输出如下:
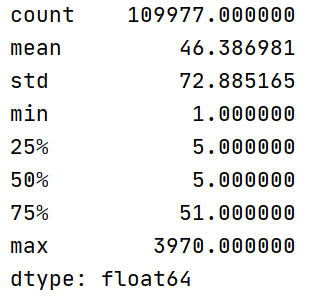
其中count表示样本数、mean表示样本平均长度、min和max分别为最小和最大样本长度。25%、50%、75%相当于将样本长度从小到大排列后的四分之一分位数、二分之一分位数、四分之三分位数。也可以理解为,75%的样本长度小于等于51。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









