







英文文档 http://www.nltk.org/book/
中文文档 https://www.bookstack.cn/read/nlp-py-2e-zh/0.md
以下编号按个人习惯
1 语言学数据管理
1 语料库结构
TIMIT语料库是一个已标注语音数据库,被设计用来为声学-语音知识的获取提供数据,并支持自动语音识别系统的开发和评估。
语料库中的每个文件名的结构如下:
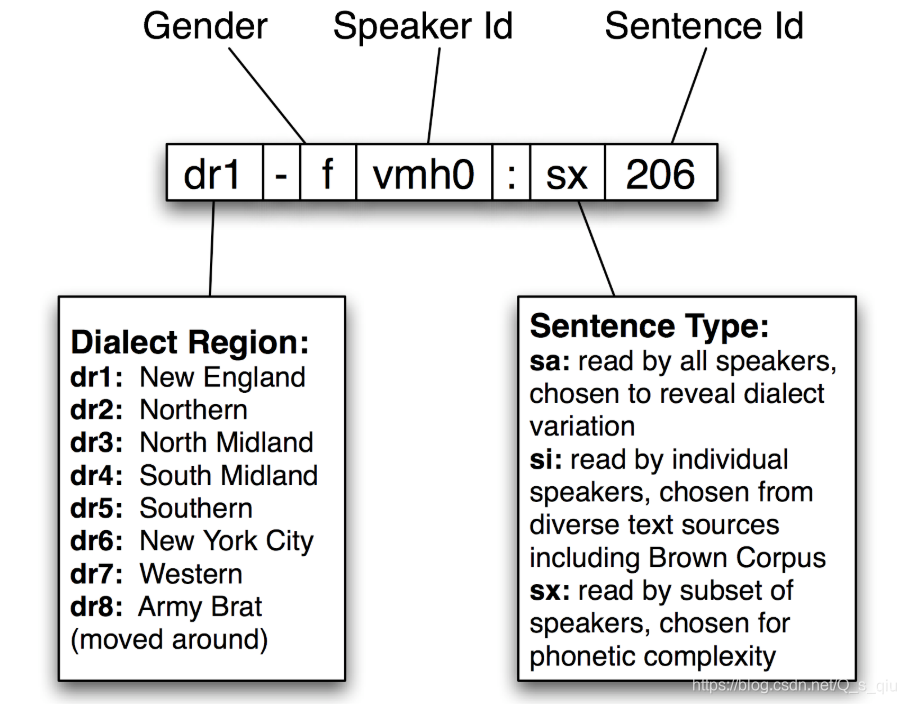
每个项目有一个音标,可以用phones()方法访问。除此之外,TIMIT还包括一个字典,提供每个词的发音。
phonetic = nltk.corpus.timit.phones('dr1-fvmh0/sa1')
print(phonetic) # ['h#', 'sh', 'iy', 'hv', 'ae', 'dcl', 'y', 'ix', 'dcl',...,]
# 字典,提供每个词的发音
timitdict = nltk.corpus.timit.transcription_dict()
dict_pron = timitdict['greasy']+timitdict['wash']+timitdict['water']
print(dict_pron) # ['g', 'r', 'iy1', 's', 'iy', 'w', 'ao1', 'sh', 'w', 'ao1', 't', 'axr']
TIMIT中还包括对speaker的统计。
# 说话人的人口学统计。可用于仔细研究声音、社会和性别特征
speaker_info = nltk.corpus.timit.spkrinfo('dr1-fvmh0')
print(speaker_info) # SpeakerInfo(id='VMH0', sex='F', dr='1', use='TRN', recdate='03/11/86', birthdate='01/08/60', ht='5\'05"', race='WHT', edu='BS', comments='BEST NEW ENGLAND ACCENT SO FAR')
基本数据类型有
- 词典,具有记录结构
- 文本,具有时间组织。一个文本可以是一个词或句子,或是一个完整的叙述或对话。
2 语料库生命周期
语料库创建的三种方案:
- 在创作者的探索过程中逐步展现
- 实验研究
- 为一个特定的语言收集参考语料
高质量的语料库涉及到许多方面。例如
- 标注指南确定任务并记录标记约定
- 定期更新以覆盖不同的情况
- 制定实现更一致的标注的新规则
测量语言输入的两个独立分割的一致性,例如分词、句子分割、命名实体识别。windowdiff是评估两个分割一致性的一个简单算法。
# 将词符预处理成0和1序列,确定出分割边界
s1 = "00000010000000001000000"
s2 = "00000001000000010000000"
s3 = "00010000000000000001000"
# 窗口大小为3,计算得到差异。数值越大,差异越大
result_1 = nltk.windowdiff(s1, s1, 3)
print(result_1)
result_2 = nltk.windowdiff(s1, s2, 3)
print(result_2)
result_3 = nltk.windowdiff(s2, s3, 3)
print(result_3)
3 数据采集
从电子表格和数据库中获取数据。电子表格常用于获取词表或范式,常见为csv格式,可使用python中csv模块访问。
# 从电子表格和数据库中获取数据
def obtaining_data_from_spreadsheets_and_databases():
# 读取csv格式内容
lexicon = csv.reader(open('dict.csv'))
pairs = [(lexeme, defn) for (lexeme, _, _, defn) in lexicon]
lexemes, defns = zip(*pairs)
print(lexemes)
print(defns)
defn_words = set(w for defn in defns
for w in defn.split())
# 找出defn_words中,不是lexemes的单词
result_1 = sorted(defn_words.difference(lexemes))
print(result_1) # ['...', 'a', 'and', 'body', 'by', 'cease', 'condition', 'down', 'each', 'foot', 'lifting', 'mind', 'of', 'progress', 'setting', 'to']
转换数据格式:以下是将dict.csv中的内容,转换一种形式输出。构造一个索引,映射字典定义的词汇到相应的每个词条的语意。
# 建立索引
idx = nltk.Index((defn_word, lexeme)
for (lexeme, defn) in pairs
for defn_word in nltk.word_tokenize(defn))
# 以所需的格式{}:{}写入一个文件中。
with open("dict.idx", "w") as idx_file:
for word in sorted(idx):
idx_words = ' '.join(idx[word])
idx_line = "{}:{}".format(word, idx_words)
print(idx_line, file=idx_file)
标注层可以为一些特定的数据分析任务提供需要,常用的标注层包括:分词、断句、分段、词性、句法结构、浅层语义、对话与段落。
对濒危语言,NLP尽可能提供更好的工具来收集和维护数据,特别是文本和词汇。NLP在此领域的应用包括:建立索引以方便对数据的访问、从文本中拾取词汇表、构建词典时定位词语用法的例子、在知之甚少的数据中检测普遍或特殊模式、并在创建的数据上使用各种语言的软件工具执行专门的验证。
4 使用XML
作为结构化的XML数据可使用ElementTree处理文件的内容,将其变成一棵树。
merchant_file = nltk.data.find('corpora/shakespeare/merchant.xml')
raw = open(merchant_file).read()
# 访问作为字符串的XML数据
print(raw[:163])
print(raw[1789:2006])
# 建立一棵树
merchant = ElementTree().parse(merchant_file)
# 得到元素的文本内容
content = merchant[0].text
# 得到所有子元素列表
children_list = merchant.getchildren()
使用特定名称查找子元素更方便。使用findall()方法
# 查看演员的顺序,可以使用频率分布看看谁最能说
speaker_seq = [s.text for s in merchant.findall('ACT/SCENE/SPEECH/SPEAKER')]
speaker_seq = Counter(speaker_seq)
top5 = speaker_seq.most_common(5)
print(top5)
4.1 使用 ElementTree 访问 Toolbox 数据
使用toolbox.xml()来访问 Toolbox 文件,得到的是一个elementtree对象。
lexicon = toolbox.xml('rotokas.dic')
访问内容的方法有两种,如下:
lexicon = toolbox.xml('rotokas.dic')
# 通过索引。返回3号条目,该条目的第一个字段
entry = lexicon[3][0]
print(entry.tag) # lx
print(entry.text) # kaa
# 通过路径。lexicon是一系列的record对象,每个都包含一系列字段对象
content_list = [lexeme.text.lower() for lexeme in lexicon.findall('record/lx')]
print(content_list) # ['kaa', 'kaa', 'kaa', 'kaakaaro', 'kaakaaviko', 'kaakaavo',...,]
查看 XML 格式的 Toolbox 数据,使用ElementTree
# 查看XML格式的Toolbox数据
elementtree_indent(lexicon)
tree = ElementTree(lexicon[3])
# sys.stdout用于屏幕显示输出。
tree.write(sys.stdout, encoding='unicode')














 1759
1759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









