







神经网络初步学习笔记
以下为本人学习过程中的笔记,刚开始接触,内容会有些繁琐。
若同样是入门,可以参考 https://www.zybuluo.com/hanbingtao/note/485480 的内容,较为易懂。
深度学习中,每一个神经元接受输入x,通过带权重w的连接进行传递,将总输入信号与神经元的阈值进行比较,最后通过激活函数处理确定是否激活,并将激活后的计算结果y输出。而我们需要训练权重w。
神经网络
1 表示
输入层(一个)、隐藏层(多个)、输出层(一个)
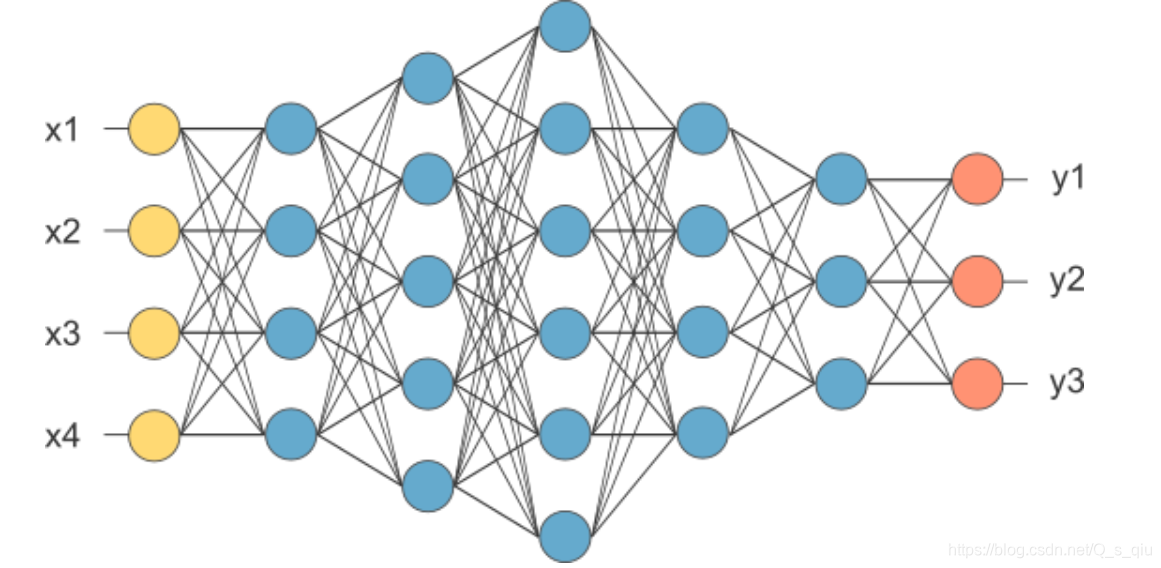
注:输出层也可有多个。
2 激活函数
激活函数,用来判断我们所计算的信息,是否达到了往后传输的条件。
激活函数都是非线性的,这样可增加神经网络模型泛化的特性。常见的激活函数有以下几种:
- sigmod 函数
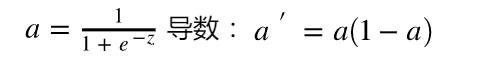
图像为:
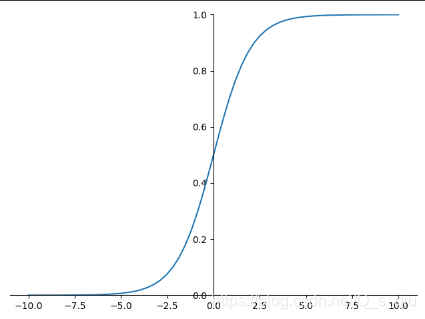
此函数其输出为(0,1),它能够把输入的连续实值变换为0和1之间的输出。起到了抑制的作用。但由于需要进行指数运算,且函数输出不是以0为中心,在反向传播时不利于权重的优化。因此使用受限,只在做二元分类(0,1)时的输出层使用。 - tanh 函数
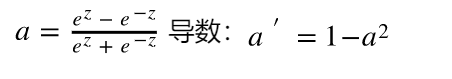
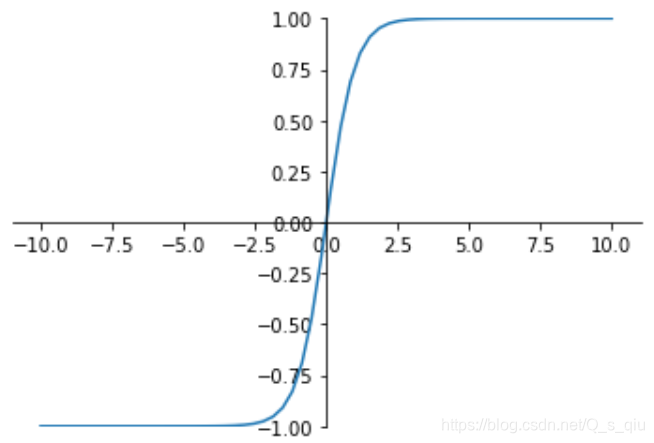
此函数能起到归一化的效果。一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。 - ReLU 函数
a = m a x ( 0 , z ) a=max(0,z) a=max(0,z) 导数大于0时1,小于0时0。

Relu修正线性单元,无论前向传播、后向传播都比较快。
即z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当 z<0时,梯度一直为0。
当输入负数时,Relu不被激活。
3 正向传播
正向传播是输入x,通过一系列的网络计算,得到预测值y的过程。
借鉴在github上看到的一段对正向传播的解释:
对于一个神经网络来说,把输入特征 a [ 0 ] a^{[0]} a[0]这个输入值就是我们的输入 x x x,放入第一层并计算第一层的激活函数,用 a [ 1 ] a^{[1]} a[1]表示,本层中训练的结果用 W [ 1 ] W^{[1]} W[1]和 b [ l ] b^{[l]} b[l]来表示。
这两个值和计算的结果 z [ 1 ] z^{[1]} z[1]值都需要进行缓存,而计算的结果还需要通过激活函数生成激活后的 a [ 1 ] a^{[1]} a[1],即第一层的输出值,这个值会作为第二层的输入传到第二层。
第二层里,需要用到 W [ 2 ] W^{[2]} W[2]和 b [ 2 ] b^{[2]} b[2],计算结果为 z [ 2 ] z^{[2]} z[2],第二层的激活函数 a [ 2 ] a^{[2]} a[2]。 后面几层以此类推,直到最后算出了 a [ L ] a^{[L]} a[L],第 L L L层的最终输出值 y ^ \hat{y} y^,即我们网络的预测值。
4 反向传播
反向传播是正向传播的反向迭代。通过反向计算梯度,优化w和b。
卷积神经网络
1 结构组成
- 卷积层
卷积计算:定义一个权重矩阵,即W(也称作卷积核或过滤器)。这个权重矩阵大小一般为33或55,极少用到77。我们在输入矩阵上使用权重矩阵W进行滑动,每滑动一步,将所覆盖的值与矩阵对应的值相乘并求和,将结果作为输出矩阵的一项。依次类推。
以一维为例,看一下滑动的计算过程,首先第一个计算过程为11+1*1 = 2(对应的值相乘求和)。依次类推,结果为[2;3;2;1]。(为了使输入数据长度与输出数据长度相同;我们可以进行补零操作,也就是对边缘没有数据的地方按零处理。也可以用其他数填充)
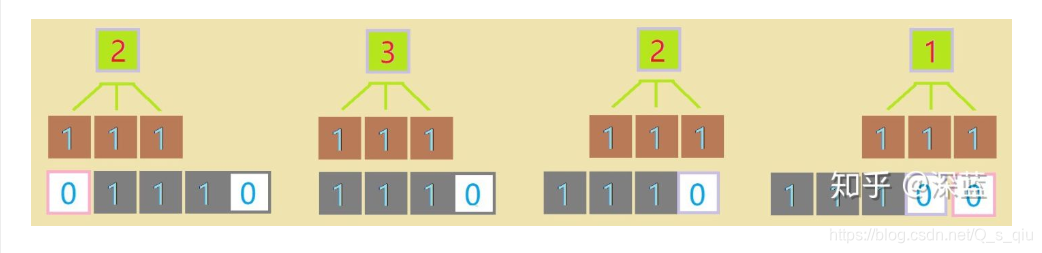
二维如下图,进行卷积操作:
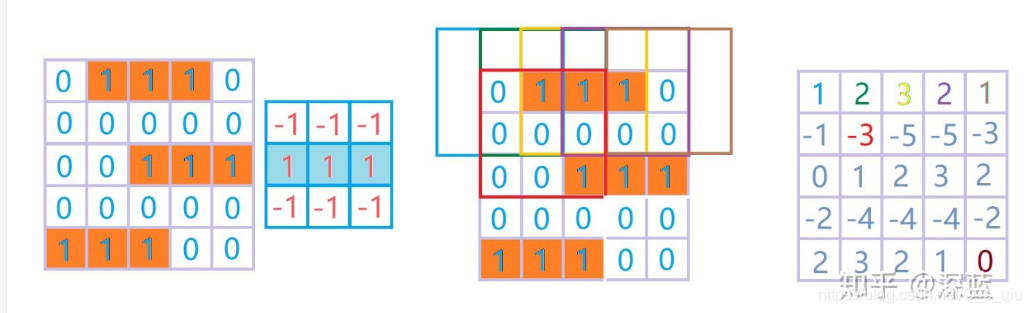
步长:规定每次滑动的距离。
计算公式:n为输入矩阵的大小、f为卷积核大小、p为边界填充的数、s为步长
卷积后Feature Map的尺寸(宽、高):以下公式中n、f换为对应的宽/高
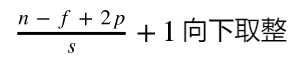
每个卷积层可以有多个核,每个核代表不同的特征。这些特征需要传递到下一层。另外由于卷积的操作是线性的,会使用激活函数,一般relu。
注:输入图像的深度和filter的深度相同。 - 池化层
池化层主要作用——下采样,降低运算复杂程度,其操作相当于合并。与卷积操作类似,依次滑动,但对W覆盖的区域进行合并只保留一个值。合并方法例如maxpooling(最大值),avgpooling(平均值)
池化层的计算公式与卷积层一样,其中p=0。
经过pooling后,深度不变。 - dropout层
为防止过拟合,增强了模型的泛化能力。
dropout是指在深度学习网络的训练中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,找到一个更小的网络。即随机将一部分网络的传播掐断。 - 全连接层
作为最后的输出层,通过卷积提取出的特征来计算,输出结果。
由于特征是用矩阵表示的,因此需要在传入全连接层之前将特征变成一维向量。分类使用softmax作为输出,回归用linear。
2 经典模型
- LeNet-5
结构:
输入->卷积层C1(6个核,55)->pooling层S2->卷积层C3(16个核,55)->pooling层S4->卷积层C5(120个,5*5)->全连接层(10个类别) - AlexNet
用Relu得到非线性;使用了dropout技巧缓解模型的过拟合,使用GPU减少训练时间,可用于更大的数据集和图像上。
AlexNet有特殊的计算层LRN层,其主要工作是对当前层的输出结果做平滑处理。 - VGG
卷积层3*3,并组合成卷积序列;图像像素缩小一倍,卷积核数量增加一倍。 - GoogLeNet
卷积层1*1,减少特征数量,从而减少网络计算负担。(太复杂了,具体内容,就不说了) - ResNet
循环神经网络
参考学习内容 https://github.com/lakomi/pytorch-handbook/blob/master/chapter2/2.5-rnn.ipynb
RNN 的本质是:拥有记忆的能力,并且会根据这些记忆的内容来进行推断。因此,他的输出是依赖于当前的输入和记忆。
RNN在许多NLP任务中取得成功。最常用的RNN类型是LSTM。LSTM与RNN基本相同,只是采用不同的方式来计算隐藏状态。
1 网络结构
将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。下图是一个简单的循环神经网络在输入时的结构示意图。
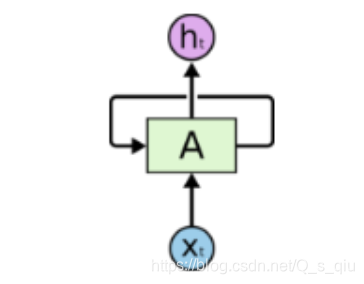
pytorch中使用nn.RNN类来搭建基于序列的RNN,其中构造函数有以下几个参数,其中主要参数是前两个,其余参数可以使用默认值:
- input_size:输入数据x的特征值数目
- hidden_size:隐藏层的神经元数量,即隐藏层的特征数量
- num_layers:RNN的层数,默认1
- bias:默认True,若为false表示神经元不使用bias偏移参数
- batch_first:如果设置为 True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是 - - batch,第三个维度是特征数目。
- dropout:如果不为空,则表示最后跟一个 dropout 层抛弃部分数据,抛弃数据的比例由该参数指定。
RNN中多了一个hidden_state来保存以前的状态,RNN有一个公式如下:
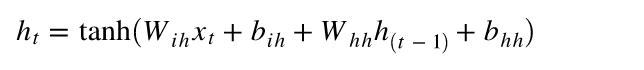
x
t
x_t
xt 是我们当前状态的输入值,
h
(
t
−
1
)
h_{(t-1)}
h(t−1) 就是hidden_state。 整个网络要训练的部分就是
W
i
h
W_{ih}
Wih 当前状态输入值的权重,
W
h
h
W_{hh}
Whh
h
(
t
−
1
)
h_{(t-1)}
h(t−1)是上一个状态的权重还有这两个输入偏置值。tanh为激活函数。这个过程进行n次,n为序列设置的个数。
2 LSTM
解决了短期依赖的问题,并且通过设计避免长期依赖问题。
LSTM有4层:
- 忘记层:决定状态中丢弃什么信息
- tanh层:用来更新值的候选项,说明状态在某些维度上需要加强,在某些维度上需要减弱
- sigmoid层:它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的状态不需要更新
- 最后一层决定输出什么,输出值与状态有关。
lstm = torch.nn.LSTM(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
# 输入网络
output, hn = lstm(input, (h0, c0))
print(output.size(), hn[0].size(), hn[1].size()) # torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
3 GRU
GRU中,网络不再额外给出记忆状态,将输出结果作为记忆状态不断向后循环传递,网络的输入和输出都变得特别简单。
gru = torch.nn.GRU(10, 20, 2)
input = torch.randn(5, 3, 10)
h_0 = torch.randn(2, 3, 20)
output, hn = gru(input, h_0)
print(output.size(), hn.size()) # torch.Size([5, 3, 20]) torch.Size([2, 3, 20])
4 循环网络的向后传播
向后传播过程:
- 使用预测输出和实际输出,计算交叉熵误差
- 网络按照时间步完全展开
- 对于展开的网络,对于每一个实践步计算权重的梯度
- 因为对于所有时间步来说,权重都一样。所以对于所有的时间步,可以一起得到梯度
- 随后对循环神经元的权重进行升级
5 词嵌入
RNN在NLP中应用火热。
用不同的特征来对各个词汇进行表征,相对于不同的特征,不同的单词均有不同的值,这便是词嵌入。(具体内容,之后深入了解补充)
词嵌入不仅对不同单词实现了特征化的表示,还能通过计算词与词之间的相似度,实际上是在多维空间中,寻找词向量之间各个维度的距离相似度,我们就可以实现类比推理,比如说夏天和热,冬天和冷,都是有关联关系的。
# 表示有多少词(10个),向量维度(大小为3的张量),的嵌入模块
embedding = torch.nn.Embedding(10, 3)
# 2个样品,各4个指标
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
output = embedding(input)
print(output.size())
6 Beam search
集束搜索(可看做 做了约束优化的广度优先搜索),通常用在图的解空间很大的情况下,可以减少搜索所占用的空间和时间。
在每一步深度扩展时,去除质量较差的节点,保留质量较高的节点。首先使用广度优先策略建立搜索树,之后按照启发代价对节点排序,留下预先确定个数的节点,然后仅这些节点在下一层继续扩展,其他的减掉。














 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









