







 这篇博客介绍了Python数据分析的基础,包括Numpy、Pandas、Matplotlib、Scipy、Statsmodels和Scikit-learn等库的用途。内容涵盖数据导入导出、数据筛选、统计描述、处理缺失值、统计分析和可视化等方面,特别提到了数据读取CSV、Excel和SQL数据库的方法,以及t检验、卡方检验等统计方法的使用。
这篇博客介绍了Python数据分析的基础,包括Numpy、Pandas、Matplotlib、Scipy、Statsmodels和Scikit-learn等库的用途。内容涵盖数据导入导出、数据筛选、统计描述、处理缺失值、统计分析和可视化等方面,特别提到了数据读取CSV、Excel和SQL数据库的方法,以及t检验、卡方检验等统计方法的使用。
本博客总结数据分析的相关基础知识,思维导图如下:
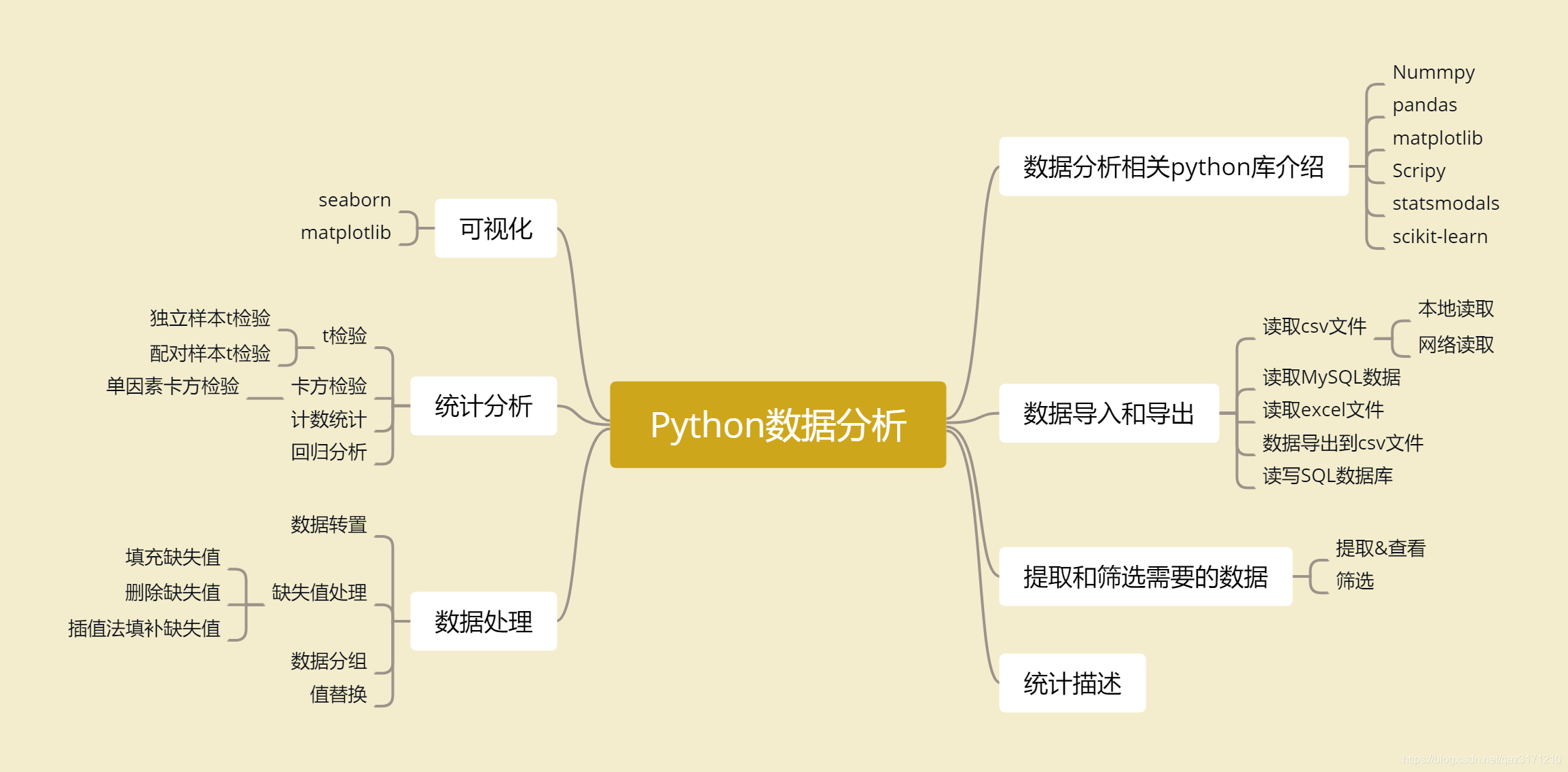
1.Numpy
Numpy是python科学计算的基础包,它提供以下功能(不限于此)
(1)快速高效的多维数据对象ndarray。
(2)用于对数组执行元素级计算以及直接对数据执行数学运算的函数。
(3)用于读写硬盘上基于数组的数据集的工具。
(4)线性代数运算、傅里叶变换,以及随机数生成。
(5)用于将C、C++、Fortran代码集成到python工具。
2.pandas
pandas提供了使我们能够快速便捷地处理机构化数据地大量数据结构和函数。pandas兼具Numpy高性能地数据计算功能以及电子表格和关系型数据(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,以便更为便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
3.matplotlib
matplotlib是最流行地用于绘制数据图表地python库。
4.Scipy
Scipy是一组专门解决科学计算中各种标准问题域地包的集合。
5.statsmodels
statsmodels是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化。statsmodels包含更多的“经典”频率学派统计方法,而贝叶斯方法和机器学习模型可在其他库中找到。
包含在statsmodels中的一些模型:
线性模型,广义线性模型和鲁棒线性模型。
象形混合效应模型。
方差分析(ANOVA)方法。
时间序列过程和状态空间模型。
广义的矩量法。
6.scikit-learn
scikit-learn项目需要NumPy和Scipy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
一.数据导入和导出
(一)读取csv文件
1.本地读取
import pandas as pd
df = pd.read_csv('E:\\tips.csv') 2.网络读取
import pandas as pd
data_url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv" #填写url读取
df = pd.read_csv(data_url)(二)读取MySQL数据
假设数据库安装在本地,用户名为root,密码为空,要读取test数据库中的数据。
import pandas as pd
import MySQLdb
mysql_cn= MySQLdb.connect(host='localhost', port=1024,user='root', passwd='', db='test')
df = pd.read_sql('select * from test_user;', con=mysql_cn)
mysql_cn.close()上述代码读取test_user表中的所有数据到df中,而df的数据结构为Dataframe。
(三)读取excel文件
要读取excel文件需要安装xlrd模块。
df = pd.read_excel('E:\\tips.xls')(四)数据导出到csv文件
df.to_csv('E:\\demo.csv', encoding='utf-8', index=False)
#index=False表示导出时去掉行名称,如果数据中含有中文,一般encoding指定为‘utf-8’(五)读写SQL数据库
import pandas as pd
import pymysql
con = pymysql.connect(host='localhost', port=1024,user='root', passwd='', db='test')
sql = 'select * from test_user;'
df = pd.read_sql(sql, con)二.提取和筛选需要的数据
(一)提取和查看相应数据
打印数据前五行 -- print(df.head())
打印数据后五行 -- print(df.tail())
打印列名 -- print(df.columns)
打印行名 -- print(df,index)
打印10~20行前三列数据 -- print(df.ix[10:20, 0:3])
提取不连续行和列的数据,这个例子提取的是1,3,5行,第2,4列的数据 -- df.iloc[[1,3,5],[2,4]]
提取某一个数据,例如:提取第三行第二列数据(默认从0开始计算) -- df.iat[3,2]
舍弃数据前两列 -- df.drop(df.columns[1,2],axis=1)
舍弃数据前两行 -- df.drop(df.cloumns[[1,2]],axis=0)
打印维度 -- df.shape
选取第N行 -- df.iloc[N]
选取第N到第M行 -- df.iloc[N:M+1]
选取第N行M列的元素 -- df.iloc[N,M]
(二)筛选出需要的数据
筛选出小费大于$8的数据 -- df[df.tip>8]
筛选出小费大于$7或总账单大于$50的数据 -- df[(df.tip>7)|(df.total_bill>50)]
筛选出小费大于$7且总账单大于$50的数据 -- df[(df.tip>7)&(df.total_bill>50)]
筛选出结果后只关心day和time -- df[['day','time']][(df.tip>7)&(df.total_bill>50)]
三.统计描述
描述性统计 -- df.describe()
四.数据处理
(一)数据转置 -- df.T
(二)数据排序 -- df.sort_values(by='tip')
(三)缺失值处理
1.填充缺失值
import json #python有许多内置或第三方模块可以将JSON字符串转换成python字典对象import pandas as pd
import numpy as np
from pandas import DataFrame
path = 'F:\PycharmProjects\pydata-book-master\ch02\usagov_bitly_data2012 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









