







HTML在运用于web端,手机端越来越频繁。采用python等脚本语言,能够读取HTML代码。这里介绍采用java程序来读取HTML代码,由于java的通用性,可以很好的解析HTML中的数据,并存放到数据库中。读取网页中的HTML代码,见博客【JAVA】JAVA程序根据url请求网站HTML页面
【开发环境】
1.Eclipse ,JDK1.7,Windows。
2.第三方jar包,jsoup-1.8.2.jar。(MVN仓库,可以下载jar包)
3.源代码HtmlParser.java。
工程文件所在位置 git仓库
【开发流程】
1.通过Jsoup解析HTML的字符形式,生成Document类,该类具有一定的HTML文档格式;
2.Document通过select(String)方法或者getElementsByXxx(String)方法获取HTML标签,类型为Elements;
3..其中select方法中的String
如:<table id = "table1"></table> ,采用select(“#table1”)
<table class = "table2"></table>,采用select(".table2")
<table ></table>,采用select("table")。
其中getElementsById(“table1”)
getElementsByClass("table2")
getElementsByTag("table"),与上面一一对应。
4.Elements元素为多个Element,Element也可以采用select(String )和getElementsByXxx()方法获取子层的Element。
5.Element可以采用getText()方法获取标签之间的文本,采用getAttr(String)方法获取标签内的属性值。
如:<a id="link" href="www.kaifa.com">开发</a>,doc.select("#link").getText()得到字符串 "开发",
doc.select("#link").getAttr("href")得到字符串“www.kaifa.com”。
【源代码】
//HtmlParser.java
package HtmlBody;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* Jsoup解析html标签时类似于JQuery的一些符号
*
* @author chixh
*
*/
public class HtmlParser {
protected List<List<String>> data = new LinkedList<List<String>>();
/**
* 获取value值
*
* @param e
* @return
*/
public static String getValue(Element e) {
return e.attr("value");
}
/**
* 获取
* <tr>
* 和
* </tr>
* 之间的文本
*
* @param e
* @return
*/
public static String getText(Element e) {
return e.text();
}
/**
* 识别属性id的标签,一般一个html页面id唯一
*
* @param body
* @param id
* @return
*/
public static Element getID(String body, String id) {
Document doc = Jsoup.parse(body);
// 所有#id的标签
Elements elements = doc.select("#" + id);
// 返回第一个
return elements.first();
}
/**
* 识别属性class的标签
*
* @param body
* @param class
* @return
*/
public static Elements getClassTag(String body, String classTag) {
Document doc = Jsoup.parse(body);
// 所有#id的标签
return doc.select("." + classTag);
}
/**
* 获取tr标签元素组
*
* @param e
* @return
*/
public static Elements getTR(Element e) {
return e.getElementsByTag("tr");
}
/**
* 获取td标签元素组
*
* @param e
* @return
*/
public static Elements getTD(Element e) {
return e.getElementsByTag("td");
}
/**
* 获取表元组
* @param table
* @return
*/
public static List<List<String>> getTables(Element table){
List<List<String>> data = new ArrayList<>();
for (Element etr : table.select("tr")) {
List<String> list = new ArrayList<>();
for (Element etd : etr.select("td")) {
String temp = etd.text();
//增加一行中的一列
list.add(temp);
}
//增加一行
data.add(list);
}
return data;
}
/**
* 读html文件
* @param fileName
* @return
*/
public static String readHtml(String fileName){
FileInputStream fis = null;
StringBuffer sb = new StringBuffer();
try {
fis = new FileInputStream(fileName);
byte[] bytes = new byte[1024];
while (-1 != fis.read(bytes)) {
sb.append(new String(bytes));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fis.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
return sb.toString();
}
public static void main(String[] args) {
// String url = "http://www.baidu.com";
// String body = HtmlBody.getBody(url);
// System.out.println(body);
Document doc = Jsoup.parse(readHtml("./index.html"));
// 获取html的标题
String title = doc.select("title").text();
System.out.println(title);
// 获取按钮的文本
String btnText = doc.select("div div div div div form").select("#su").attr("value");
System.out.println(btnText);
// 获取导航栏文本
Elements elements = doc.select(".head_wrapper").select("#u1").select("a");
for (Element e : elements) {
System.out.println(e.text());
}
Document doc2 = Jsoup.parse(readHtml("./table.html"));
Element table = doc2.select("table").first();
List<List<String>> list = getTables(table);
for (List<String> list2 : list) {
for (String string : list2) {
System.out.print(string+",");
}
System.out.println();
}
}
}
【解析的HTML页面文件】
//index.html
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv=content-type content=text/html;charset=utf-8>
<meta http-equiv=X-UA-Compatible content=IE=Edge>
<meta content=always name=referrer>
<link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css>
<title>百度一下,你就知道</title>
</head>
<body link=#0000cc>
<div id=wrapper>
<div id=head>
<div class=head_wrapper>
<div class=s_form>
<div class=s_form_wrapper>
<div id=lg>
<img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129>
</div>
<form id=form name=f action=//www.baidu.com/s class=fm>
<input type=hidden name=bdorz_come value=1>
<input type=hidden name=ie value=utf-8>
<input type=hidden name=f value=8>
<input type=hidden name=rsv_bp value=1>
<input type=hidden name=rsv_idx value=1>
<input type=hidden name=tn value=baidu>
<span class="bg s_ipt_wr">
<input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>
</span>
<span class="bg s_btn_wr">
<input type=submit id=su value=百度一下 class="bg s_btn">
</span>
</form>
</div>
</div>
<div id=u1>
<a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a>
<a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a>
<a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a>
<a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a>
<a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a>
<noscript>
<a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a>
</noscript>
<script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script>
<a href=//www.baidu.com/more / name=tj_briicon class=bri style="display: block;">更多产品</a>
</div>
</div>
</div>
<div id=ftCon>
<div id=ftConw>
<p id=lh>
<a href=http://home.baidu.com>关于百度</a>
<a href=http://ir.baidu.com>About Baidu</a>
</p>
<p id=cp>
©2017 Baidu
<a href=http://www.baidu.com/duty />
使用百度前必读
</a>
<a href=http://jianyi.baidu.com / class=cp-feedback>意见反馈</a>
京ICP证030173号 <img src=//www.baidu.com/img/gs.gif>
</p>
</div>
</div>
</div>
</body>
</html>
//table.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>table</title>
</head>
<body>
<table border="0" width="750" bgcolor="#000000" cellspacing="1" cellpadding="2">
<tr bgcolor="#efefef">
<td width="80">基金代码</td>
<td width="100">基金名称</td>
<td>单位基金净值(元)</td>
<td>单位累计净值(元)</td>
<td>年中年末份额净值(元)</td>
<td>年中年末累计净值(元)</td>
<td>基金资产净值(元)</td>
<td></td>
<td></td>
</tr>
<tr bgcolor="#FFFFFF" height="30">
<td>010101</td>
<td>天弘股票基金</td>
<td style="color: blue">2.100</td>
<td style="color: blue">4.001</td>
<td style="color: blue"></td>
<td style="color: blue"></td>
<td style="color: blue"></td>
<td style="color: blue"></td>
<td style="color: blue"></td>
</tr>
</table>
</body>
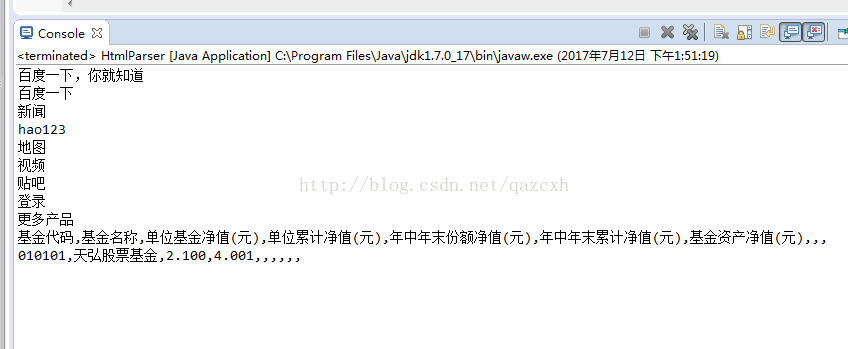
</html>【程序结果】















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









