






一水 发自 凹非寺
量子位 | 公众号 QbitAI
大幅节省算力资源,又又又有新解了!!
DeepMind团队提出了一种新的数据筛选方法JEST——
将AI训练时间减少13倍,并将算力需求降低90%。

简单来说,JEST是一种用于联合选择最佳数据批次进行训练的方法。
它就像一个智能的图书管理员,在一大堆书(数据)中挑选出最适合当前读者(模型)阅读的几本书(数据批次)。
这样做可以让读者更快地学到知识(训练模型),还能节省时间(减少迭代次数)和精力(减少计算量)。
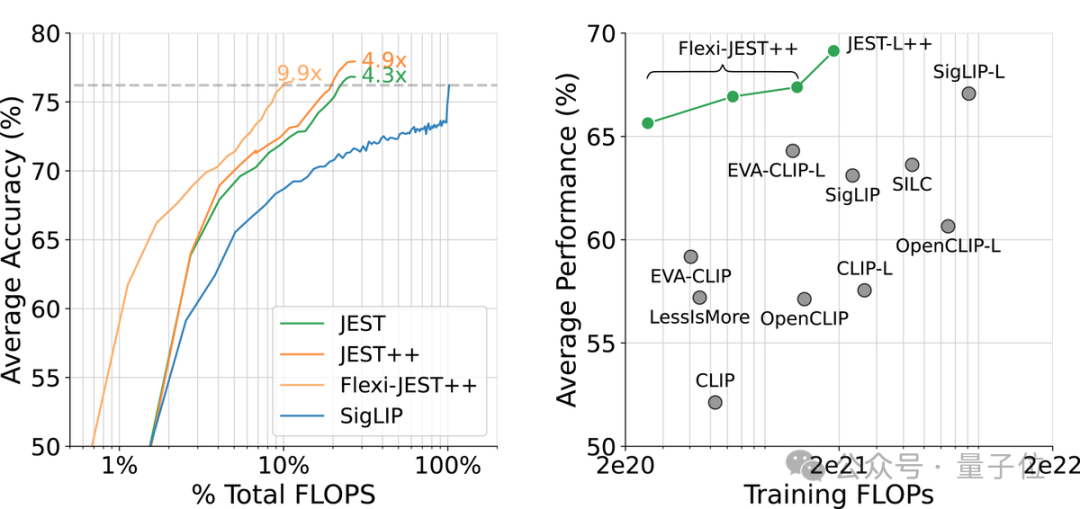
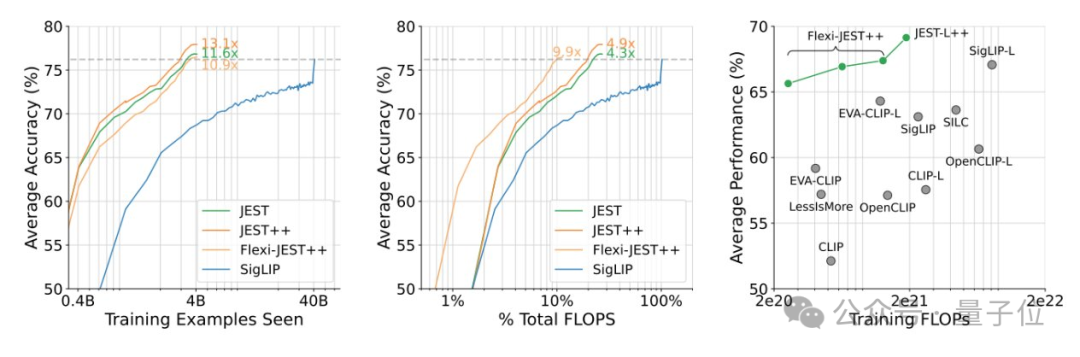
研究显示,JEST大幅加速了大规模多模态预训练,与之前的最先进水平(SigLIP)相比,迭代次数和浮点运算次数减少了10倍。
对于上述结果,有网友惊呼:
新研究将成为AI训练的游戏规则改变者!
还有人点出了关键:
对于担心人工智能需求过高的电网来说,这可能是个极好的消息!
那么,新方法究竟是如何运作的?接下来一起看团队成员相关揭秘。
揭秘新方法JEST
首先,现有的大规模预训练数据筛选方法速度慢、成本高,并且没有考虑到批次组成或训练过程中数据相关性的变化,这限制了多模态学习中的效率提升。
因此,DeepMind团队研究了联合选择数据批次而非单个样本是否能够加速多模态学习。
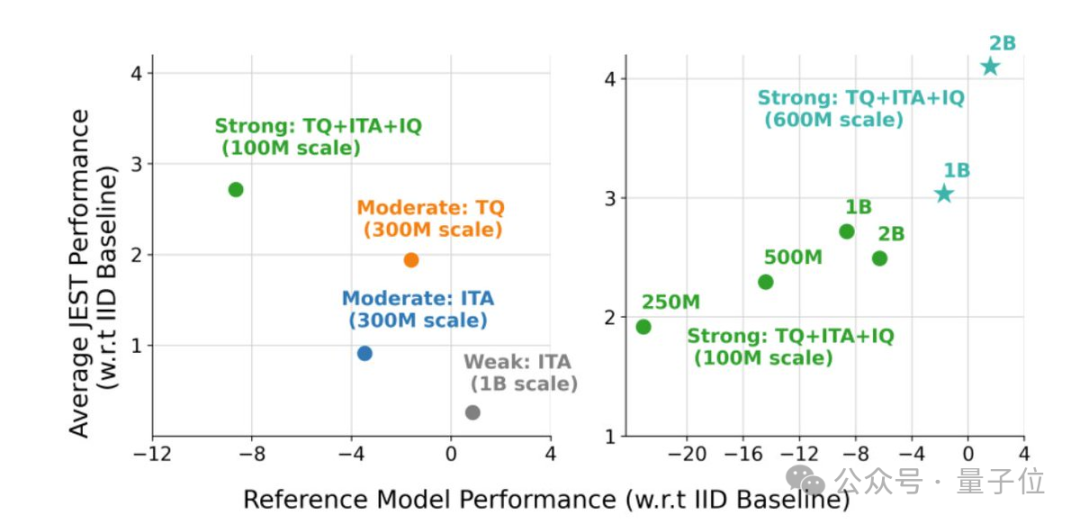
研究得出了3个结论:
挑选好的数据批次比单独挑选数据点更为有效
在线模型近似可用于更高效地过滤数据
可以引导小型高质量数据集以利用更大的非精选数据集
基于上述,JEST能够在仅使用10%的FLOP预算的情况下超越之前的最先进水平。
这一结果是如何实现的呢?
据团队介绍,他们在之前的工作中已展示了,对最好的50%数据进行训练如何显著提高FLOP效率。

而现在,新研究证明过滤更多数据(高达90%)可以产生更好的性能。
这里有三个关键:
选择好的批次 > 选择稍微好的数据点
调整默认的ADAM超参数
非常高质量(但很小)的参考数据集
具体而言,JEST是从一个更大的候选数据集中选择最佳的训练数据批次。
在数据选择标准上,JEST借鉴了之前关于RHO损失的研究,并结合了学习模型和预训练参考模型的损失来评估数据点的可学习性。JEST选择那些对于预训练模型来说较容易,但对于当前学习模型来说较难的数据点,以此提高训练效率和效果。
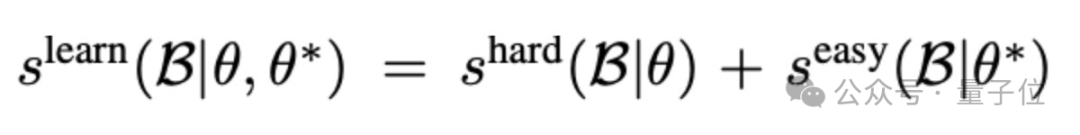
成员Nikhil进一步解释了多模态对比学习的过程,即通过最大化文本和图像嵌入的对齐性,同时最小化不相关数据之间的对齐性,来提高模型的性能。
利用这一点,团队采用一种基于阻塞吉布斯采样的迭代方法,逐步构建批次,每次迭代中根据条件可学习性评分选择新的样本子集。
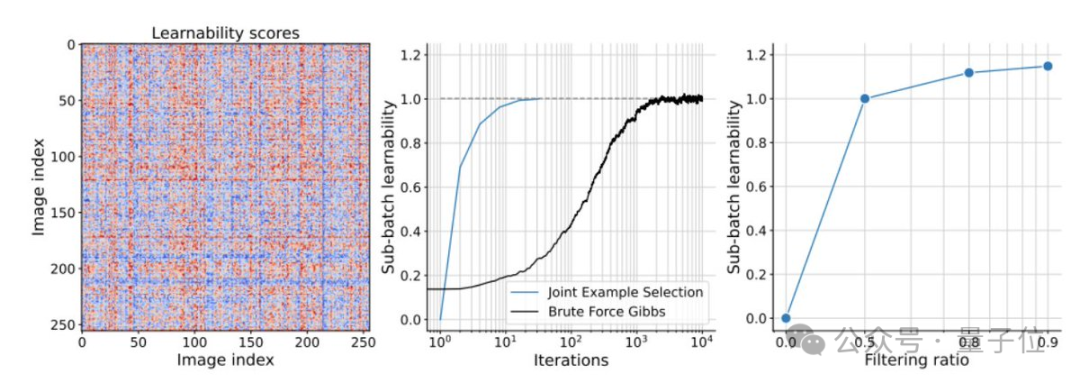
与单独选择数据相比,新方法在过滤更多数据时持续改进。包括使用仅基于预训练的参考模型来评分数据也是如此,即CLIPScore,这是离线基础数据集筛选的流行基线。
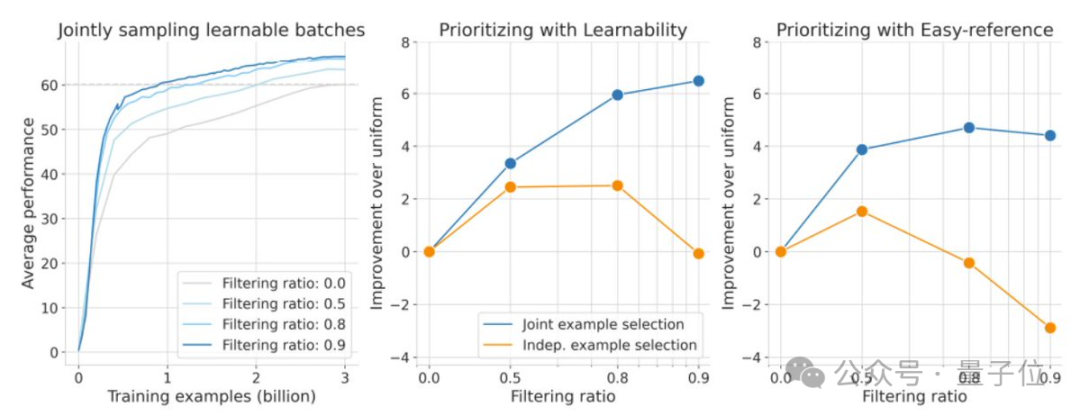
不过,过滤更多数据会增加浮点运算次数(FLOPs),因为评分需要学习者和参考模型进行推理传递。
对此,团队在数据集中缓存了预训练的参考模型分数,他们采用了FlexiViT架构进行低分辨率评分,并在多种分辨率下进行了训练。
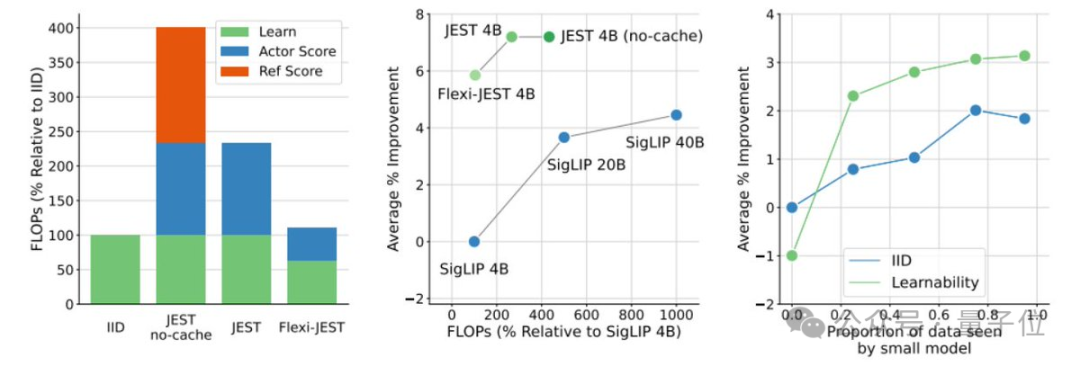
这一研究证明了:
多分辨率训练对于协调评分和学习者模型至关重要
另外,研究强调了使用高质量的精选数据集来训练参考模型的重要性,这有助于优化大规模预训练的数据分布,从而提升模型的泛化能力。
总而言之,相关变体JEST++和FlexiJEST++的性能显著优于许多其他先前的SOTA模型,同时使用的计算量更少。
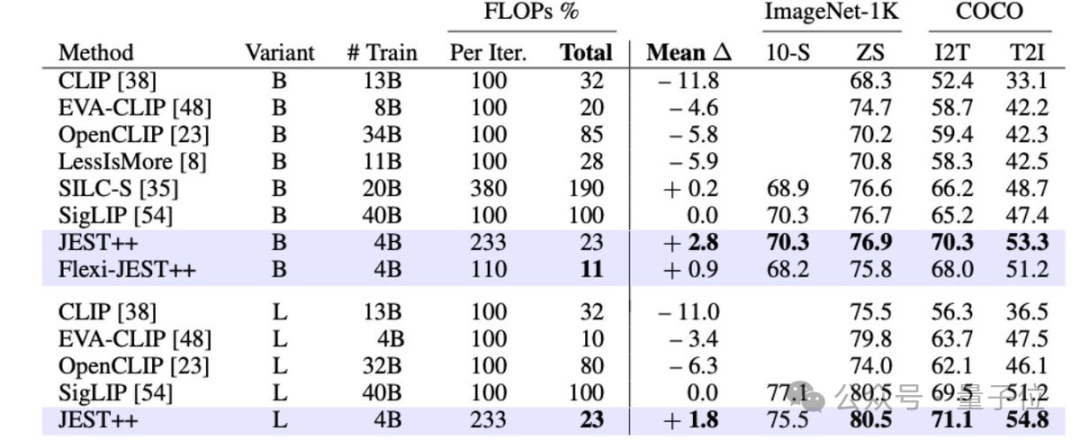
针对大家可能的疑问:
为什么不只在用于参考模型的精选数据集上进行训练呢?
团队预先解释,相关结果表明精选的参考模型是专家型模型(在某些任务上表现良好)。JEST++利用专家型参考模型,将其转化为通用模型,在所有基准测试中都取得了改进。

最后,研究发现JEST++最终可以通过消除对预训练数据集的任何筛选需求来简化数据管理流程。
通过使用预训练参考模型,在未经筛选(原始)的网络规模数据上进行训练,性能几乎没有下降。

来自DeepMind
上述研究由来自DeepMind的4位成员共同完成。
Talfan Evans,至今在DeepMind工作3年多,是机器学习团队的一名研究科学家,近期研究方向是大规模模型数据训练和任务对齐。曾就读于伦敦帝国理工学院戴森机器人实验室(空间/视觉感知系统中的实时分布式推理)。

高级研究员Olivier Hénaff,至今在DeepMind工作5年多,专注于了解生物和人工智能的基本原理。在DeepMind一直研究自监督算法,近期对视觉表征如何构建我们的记忆、实现灵活的感知推理和长视频理解感兴趣。曾就读于美国纽约大学神经科学中心博士和法国巴黎综合理工学院硕士(数学)。

研究科学家Nikhil Parthasarathy,至今在DeepMind工作5年多,负责建立视觉感知模型,研究方向涵盖表示学习、计算机视觉、计算神经科学和视觉感知。曾就读于纽约大学博士,斯坦福大学本硕。
研究工程师Hamza Merzic,2018年加入DeepMind,研究领域包括主动学习、视觉想象、表征学习、强化学习、深度学习和机器人技术。他是瑞士联邦理工学院的硕士生,并在2023年至今期间担任博士生导师。
目前相关论文已公开,感兴趣可以进一步了解。
论文:
https://arxiv.org/abs/2406.17711
参考链接:
[1]https://x.com/rohanpaul_ai/status/1809792337293566209
[2]https://x.com/olivierhenaff/status/1805995802352910557
[3]https://x.com/nikparth1/status/1806001404294672775
[4]https://x.com/talfanevans/status/1805996146826817726
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 1
1

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









