







Fiber概念和背景
为什么叫fiber
对于进程(Process)和线程(Thread)的概念,我们应该比较了解,在计算机科学中还有一个概念叫做Fiber,英文含义就是“纤维”,意指比Thread更细的线,也就是比线程(Thread)控制得更精密的并发处理机制。react把最新的调度架构取名为fiber,也意为实现更精密的任务控制。但是react fiber和这个fiber是不同的两个概念。
React Fiber架构在当下很火,react 16之后重构了react核心的算法,将vdom从树结构变成了链表结构。主要是为了解决react在进行计算时一直占用浏览器js线程,导致用户一些更高级的操作不能得到及时渲染的问题。比如对于更新频繁的动画,react老版本会出现卡顿现象。
为了解决这个问题React利用RequestIdCallback在浏览器空闲的时候进行计算,确保浏览器可以优先执行更加高级的更新。采取的措施就是将react的计算任务分片。React重新设计了一种链表的vdom结构,每个节点称之为一个fiber,每个fiber有一下属性:
{
stateNode, // 状态节点
child, // 子节点
return, // 表示当前节点处理完毕后,应该向谁提交自己的成果(effect list)
sibling, // 兄弟节点
...
}这也就保证了每一个fiber都可以访问到整棵树。
用图来展示15,16的区别:
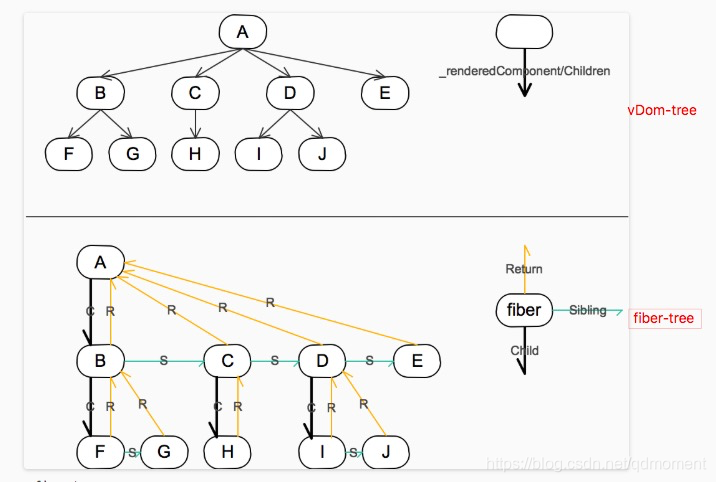
上图很形象的展示出react15和16两个版本在更新策略上的差异
前者是典型的树结构,后者是链表结构。
对于fiber结构链表的约定:父节点指向第一个子节点, 每个子节点都指向父节点,同层节点间是单向链表。
Fiber的生命周期
Fiber分为两个阶段:
1,diff阶段(render/reconciliation),创建新的fiberTree,获取patch(可以打断)
2,commit阶段,提交patch(不可打断)
diff阶段详解:
以fiber tree为基础,把每一个fiber作为一个工作单元,自顶向下构建新的WorkInProgress tree。
在遍历该链表时,是一个循环的过程,每次循环会把结束时所在的组件打上tag,下一个循环在上一次循环结束的组件重新开始diff。每一个workInProgress tree节点上都有一个effect list, 用来存储diff结果,当遍历完当前节点时,会向上merge effect list。具体过程如下:
1,如果节点不需要更新会直接把节点clone过来,需要更新会打上tag,记录需要更新的信息,记录到effect list;
2,更新当前节点状态(props, state, context等)
3,当前节点没有子节点时,当前节点遍历结束,把effect list归并到return,去遍历兄弟节点,如果没有剩余可用时间了,等到下 一次主线程空闲时才开始下一个工作单元;否则,立即开始做
4,当遍历到最后一个节点后,工作单元遍历结束,render/reconciliation结束,进入commit阶段;
说明:当diff阶段被高级任务打断后,react会记录结束时所在节点的位置,恢复diff时,会放弃之前结束时diff的节点,重新开始;但是这里的放弃只是重新遍历某个工作单元,不会放弃已经生成的节点树,要不调度就没有意义了。
commit阶段
commit阶段是不能被打断的,需要一次执行完毕。
1,处理render/reconciliation阶段创建的effect list
更新dom操作, 更新ref,调用生命周期函数(componentDidMount,componentDidUpdate,componentWillUnmount)
2,该阶段结束后,dom完成更新
对应源码:
beginWork(),completeWork(),commitWork()
关键特性总结
像这种将计算任务分片可控的形式,称为增量更新,浏览器分片渲染的方式称为增量渲染,这种形式主要利用了浏览器requestIdCallback的特性,加上react实现的精密的调度算法,最终实现了react fiber架构。
参考:https://www.cnblogs.com/MuYunyun/p/10424430.html#_label1
https://zhuanlan.zhihu.com/p/26027085
https://zhuanlan.zhihu.com/p/58863799















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









