







以下是我看了TimeSformer这篇文章的理解,如果理解有误,欢迎各位大佬指正。
一.介绍
原文:https://arxiv.org/pdf/2102.05095.pdf
代码:: https://github.com/facebookresearch/TimeSformer.
TimeSformer是一种用于处理视频分类的模型,它在ViT模型的基础上提出了Divided Space-Time
Attention (T+S)注意力机制,先计算只有time变量的时间自注意力分数,再计算只有space变量的空间自注意力分数。
该论文提出的TimeSformer模型相比于ViT模型,可以学到更多的可分离特征。
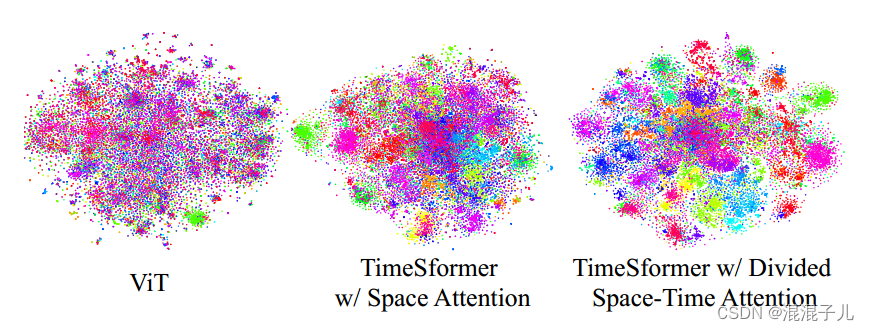
相比于其他用于视频分类的模型在K400,K600,SSV2等数据集上速度更快,精度更高,推理成本更低。
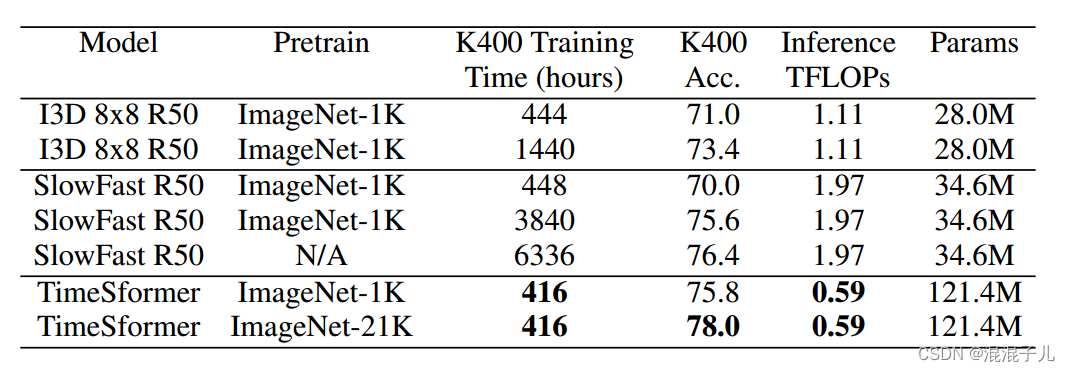
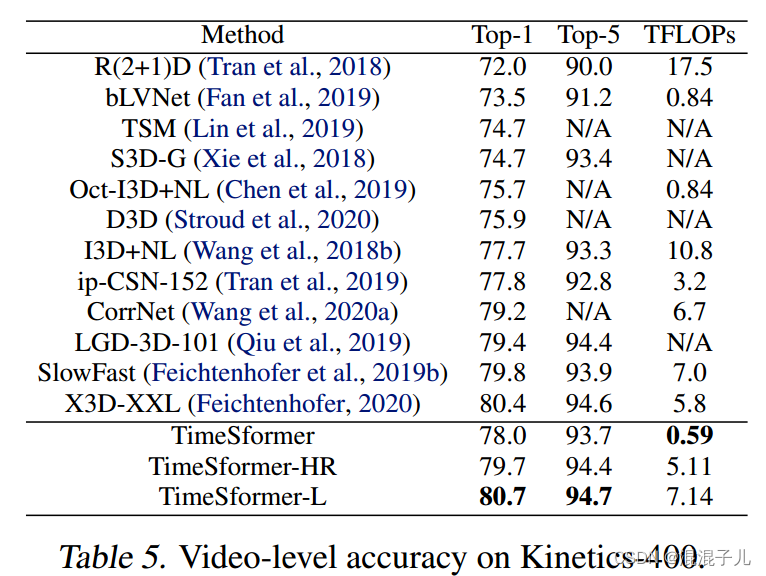
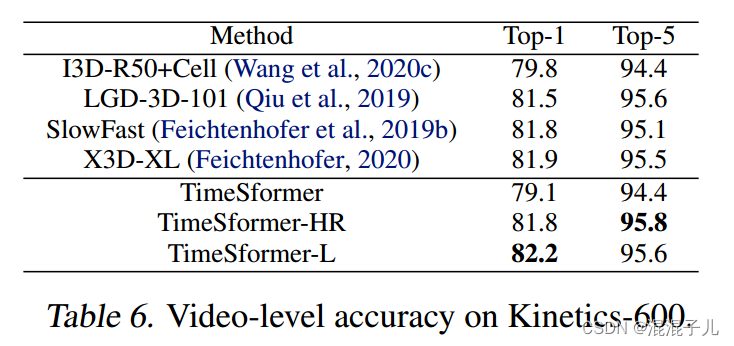
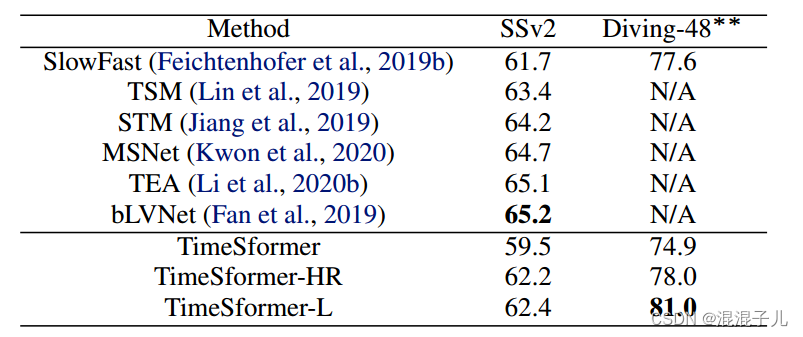
改进点:
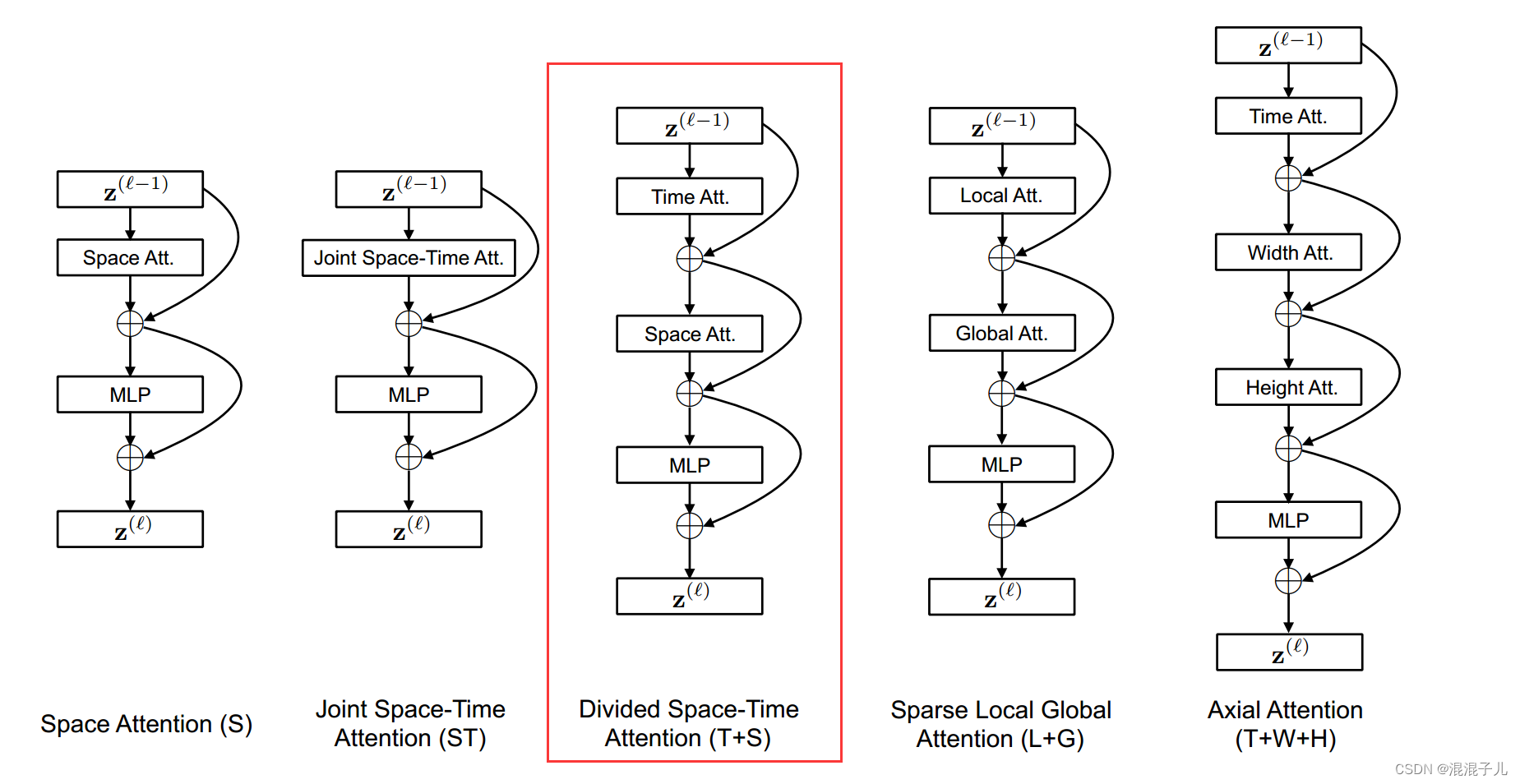
1.提出了Divided Space-Time Attention计算方式
2.提出了Space-Time Self Attention 模型
二.原理
TimeSformer主要结构如下图所示:
1.输入片段:F个RGB帧组成的片段作为输入。
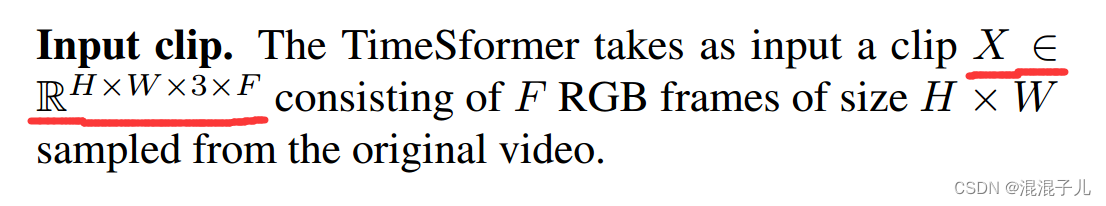
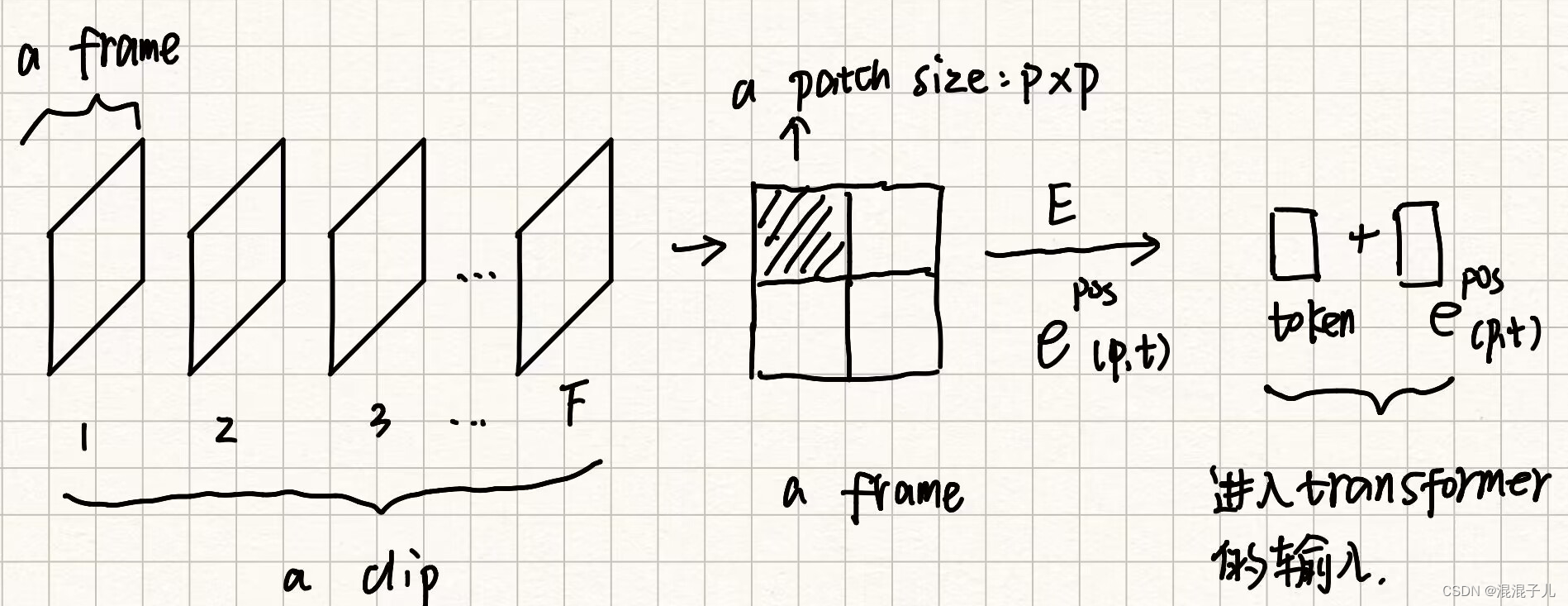
2.拆分patches:每一帧分成size=P×P的patches : x(p,t),其中p=1,2...,N(表示这个patch的空间位置,即是一帧上的哪一块);t=1,2...,F(表示这个patch的时间位置,即是哪一帧上的)。
3.线性嵌入:对每一个patch进行时间和空间上的位置编码和卷积滤波,生成token。

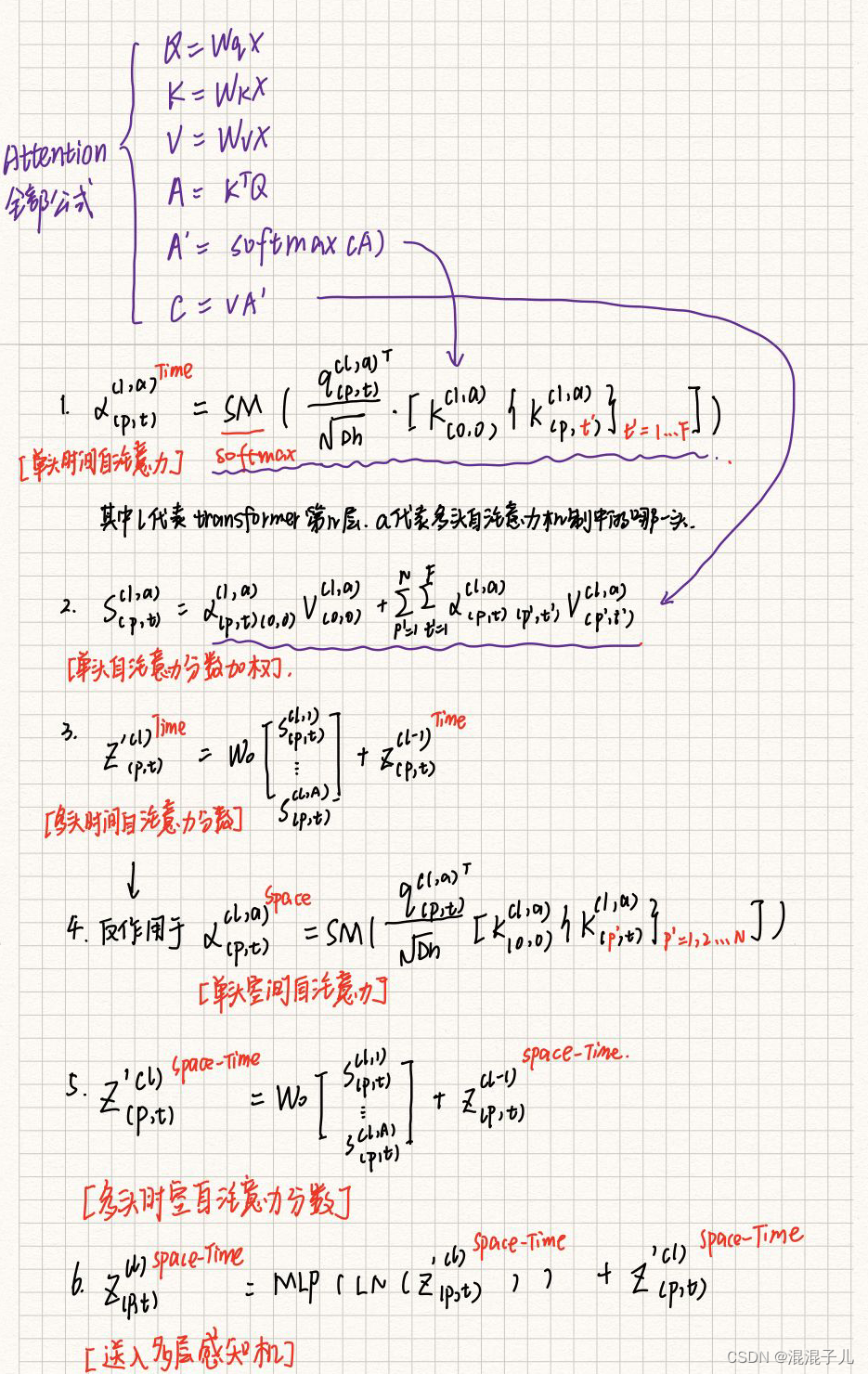
 4.Q,K,V计算
4.Q,K,V计算

5.时空自注意力机制模型(Space-Time Self-Attention Models):


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









