







以下是我看了ViViT这篇文章的理解,如果理解有误,欢迎各位大佬指正。
原文:https://arxiv.org/abs/2103.15691
代码:https://github.com/google-research/scenic.
目录
三.Video Vision Transformer原理(ViViT)
2.“central frame initialisation”3D滤波器生成方法
1)Spatio-Temporal Attention Model
3)Factorised Self-Attention Model
4)Factorised Dot-Product Attention Model
一.介绍
ViViT是一个视频分类模型,基于ViT模型进行了一些改进。ViT只用于2D图像的分类识别,视频与图像的区别是,视频引入了时间维度,因此ViViT模型在识别视频的时候也引入了时间维度,提出了tublet embedding来划分patches;3D滤波器的另一种生成方式;引入了时间维度的4种变体Attention模型,在各个数据集上的精确度都表现优秀:
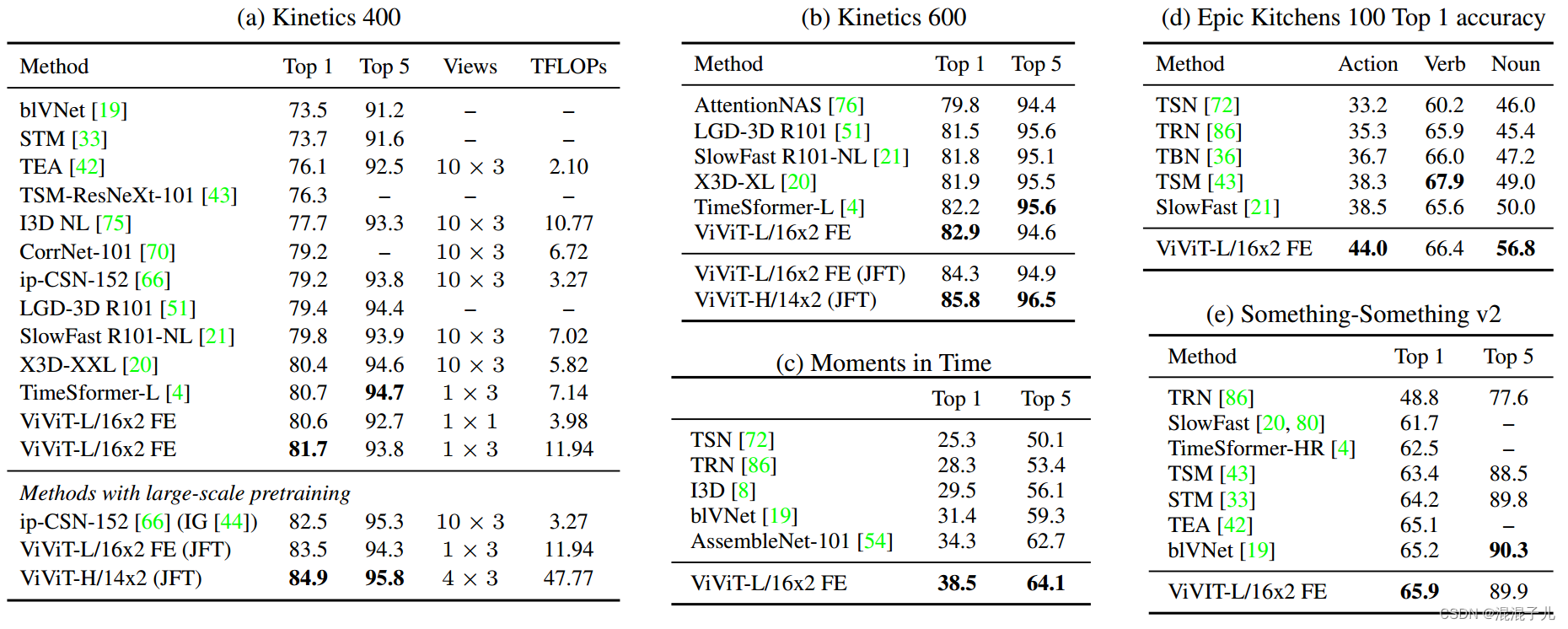
改进点:
1.提出了一种"Tubelet embedding "方法划分patches
2.提出了3D卷积滤波器的另一种生成方法:"central frame initialisation",来生成tokens
3.提出了4种变体Attention的模型:
1) Spatial-Temporal Attention Model(采用了joint space-time attention机制)
2)Factorised Encoder Model(效果在这四个提出的模型中最好)
3)Factorised Self-Attention Model(类似于TimeSformer的divided space-time attention机制)
4)Factorised Dot-Product Attention(在MSA多头自注意力机制中,一半的头只算空间的Attention,一半的头只算时间的Attention)
二.简单介绍ViT原理
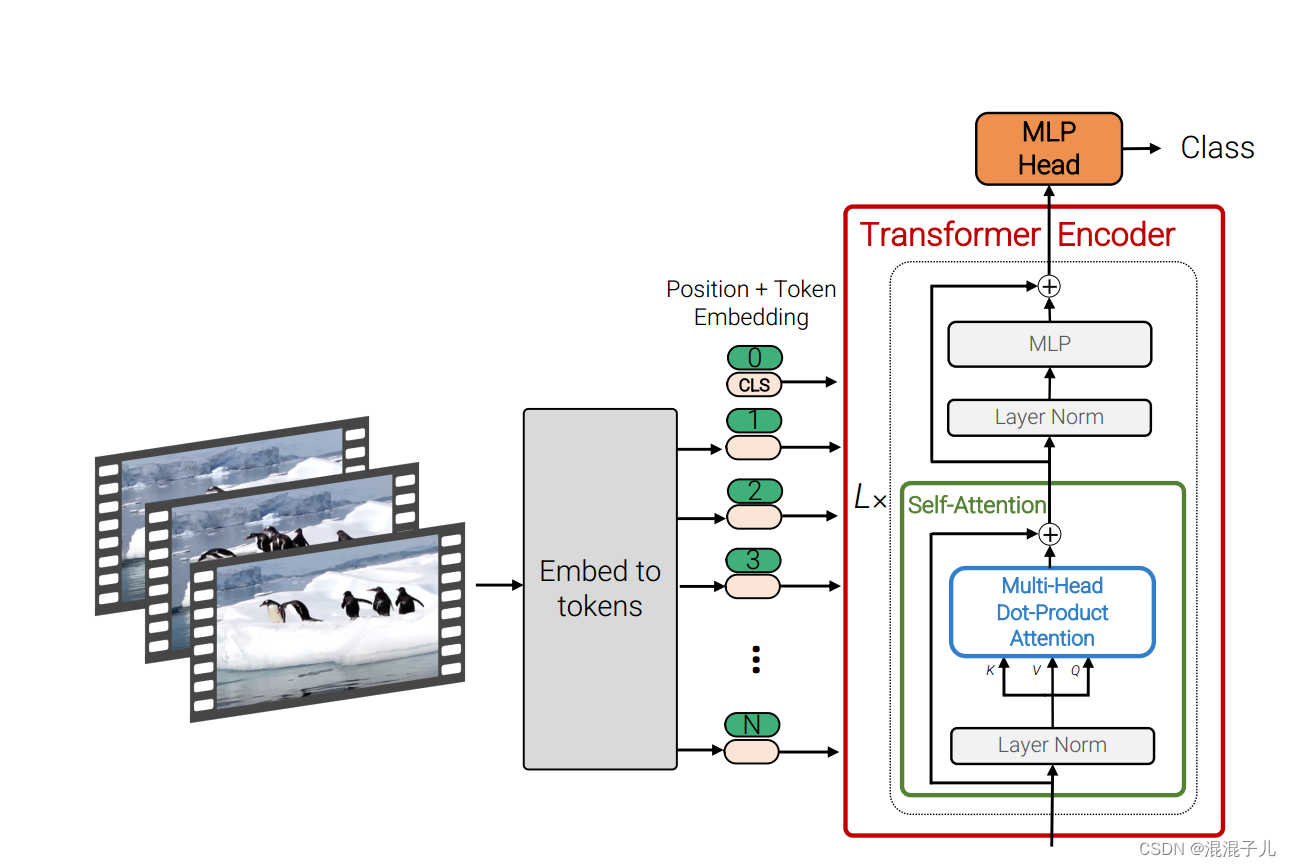
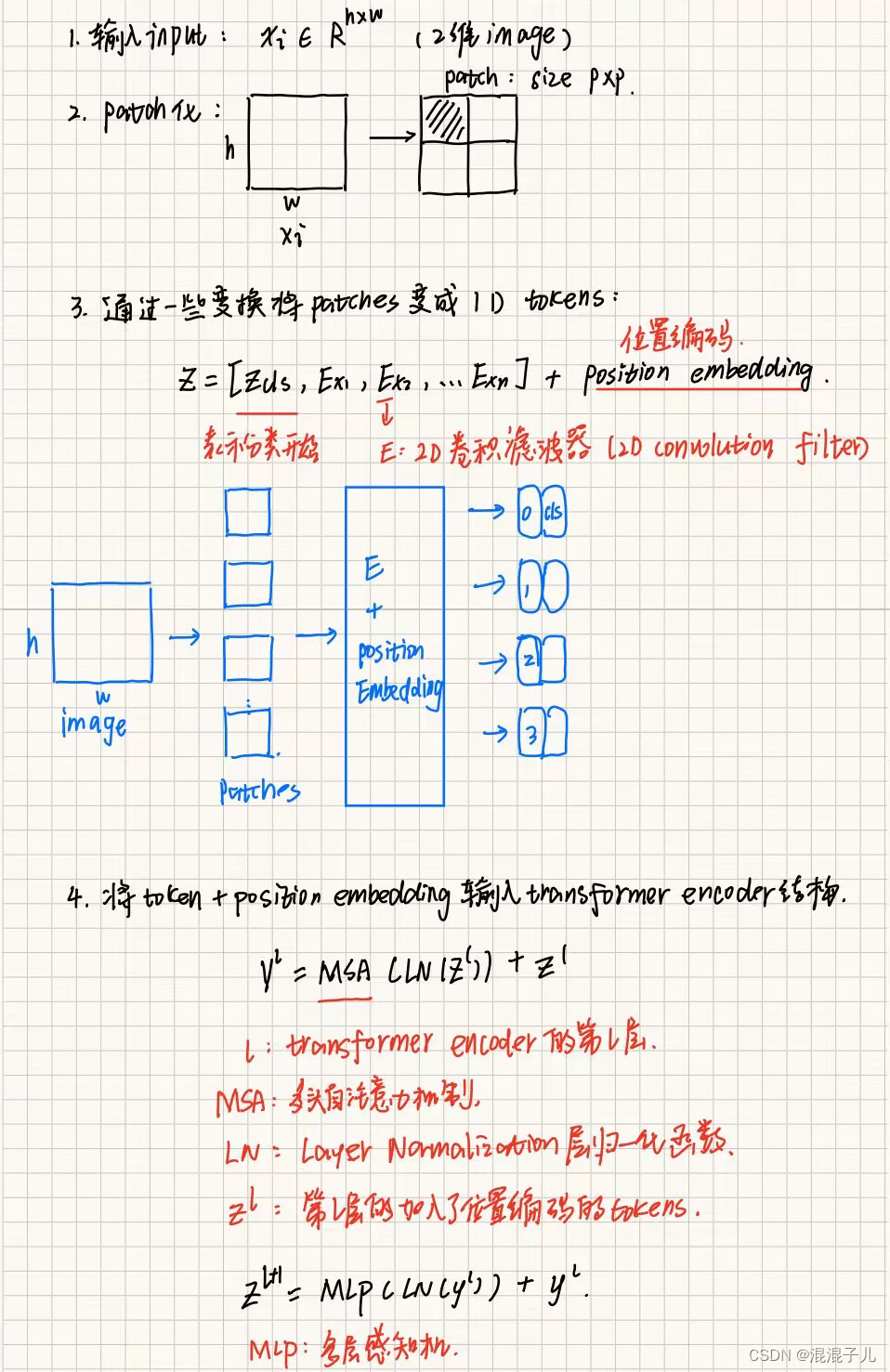
三.Video Vision Transformer原理(ViViT)
1.Tublet Embedding
在没有提出tublet embedding之前,一般用于划分视频patches用的是Uniform Frame Sampling:
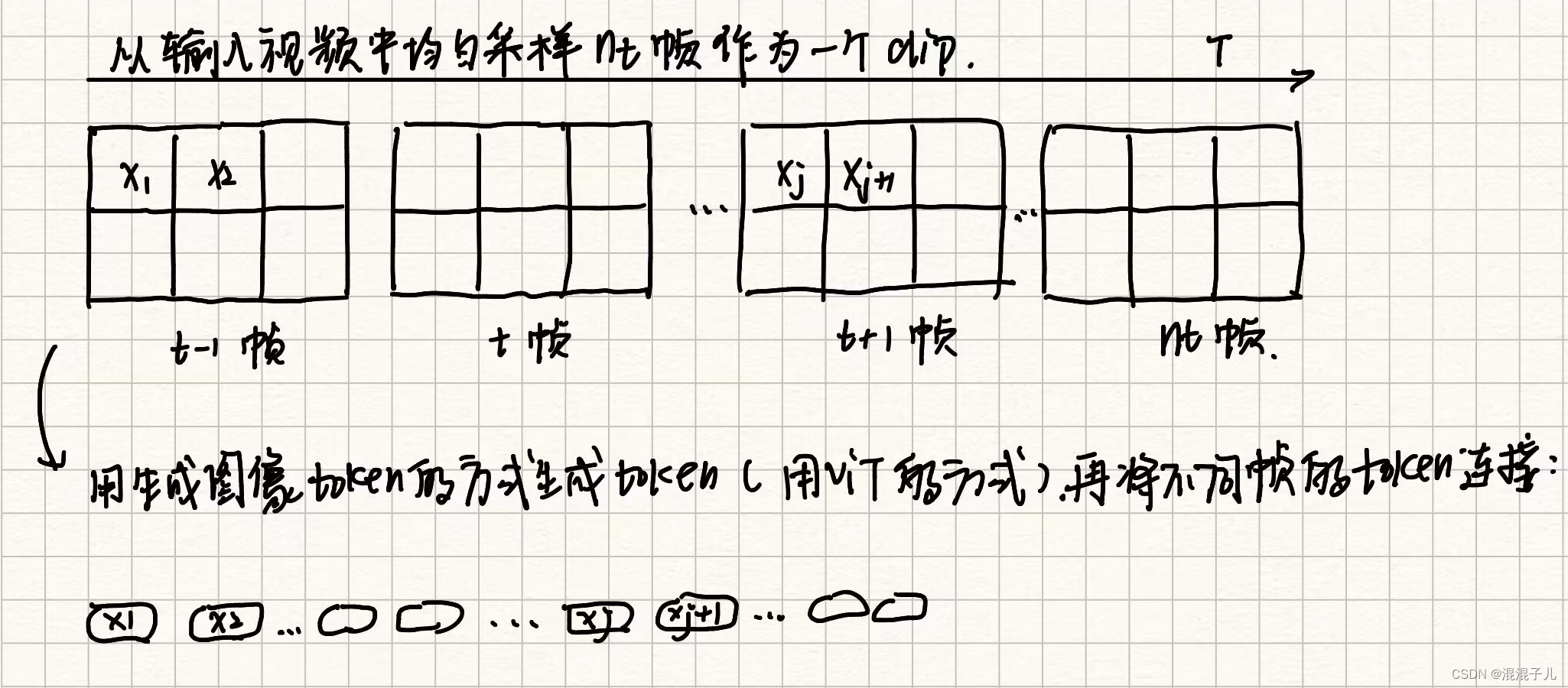
该论文提出了Tubelet embedding生成patches:
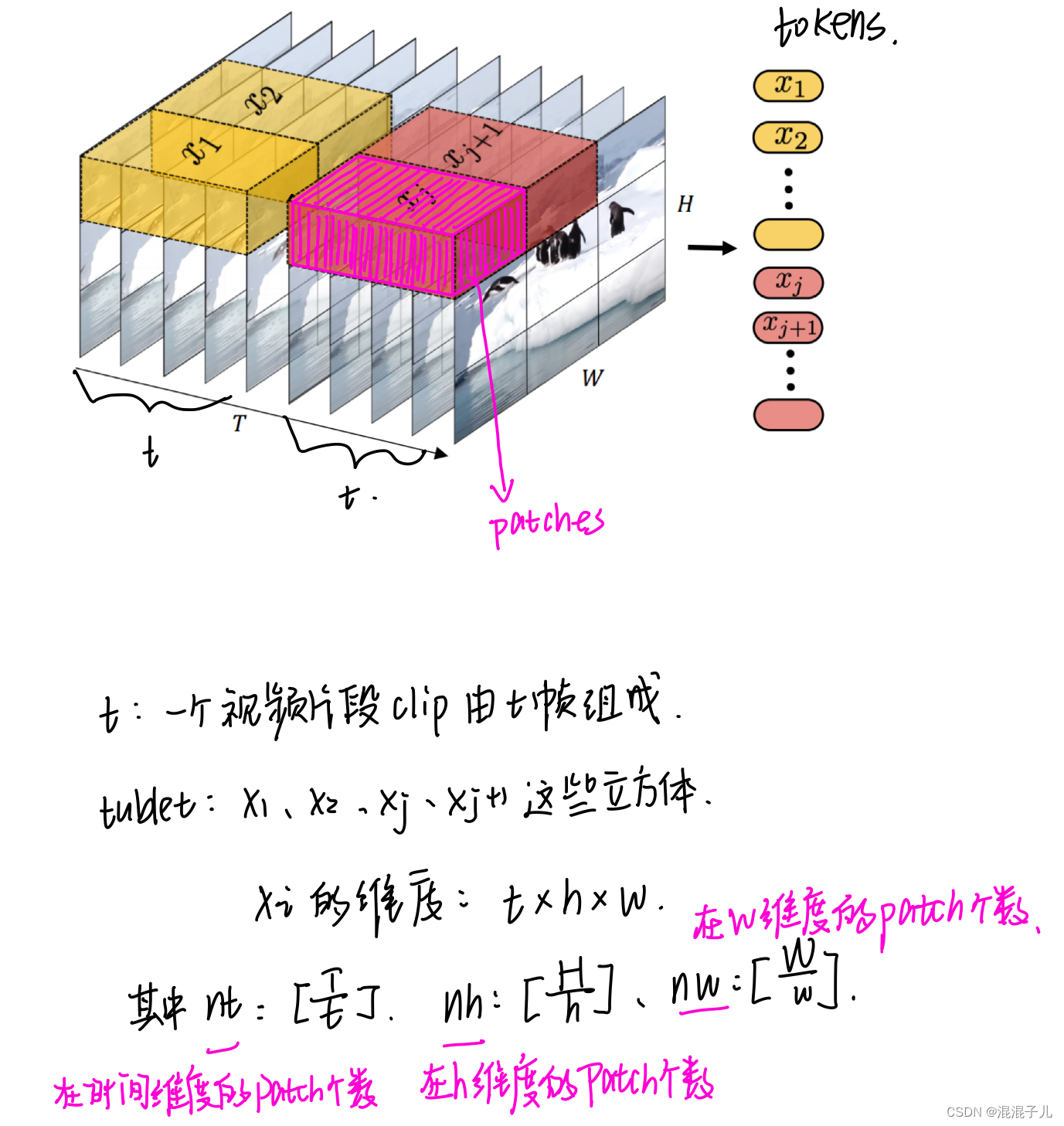
2.“central frame initialisation”3D滤波器生成方法
不论图像或者视频变成token都需要对划分的patches进行变换,其中图像生成token用的是2D卷积滤波器,因为图像划分的patches是2D的,而tublet embedding划分的patches是3D的,需要用3D卷积滤波器对其进行处理。通常3D滤波器生成用的是沿着时间维度复制2D滤波器并将其平均化,以此来“膨胀”它们变成3D滤波器:
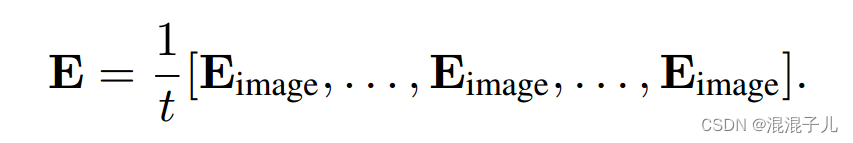
该论文提出了用“central frame initialisation”:即只有在[t/2]取整数的位置有2D滤波器,其余沿时间位置都是0,这样模型能够在训练过程中学习从多个帧中聚合时间信息:
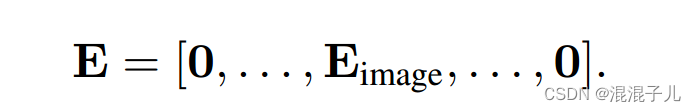
3.四种变体Attention的模型原理
1)Spatio-Temporal Attention Model
该模型与ViT模型不同之处在于计算注意力的方式不同,采用了联合时空注意力机制,同时输入的token也不同,ViT是2D patches通过2D卷积滤波器降维生成token,该模型是3D tublet embedding patches通过3D卷积滤波器(用“central frame initialisation”方法生成)降维生成token,将 token输入到以下结构中:
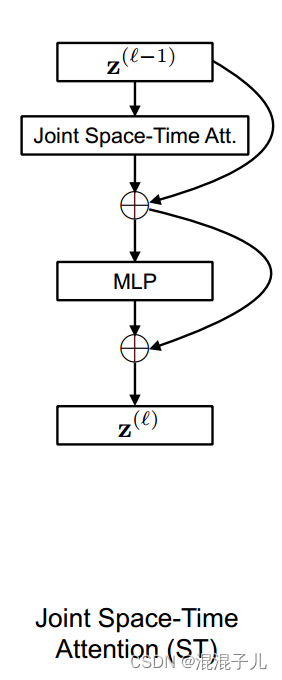
我通过TimeSformer那篇论文,觉得这里的Joint Space-Time Attention中计算注意力得分的公式应该是:

2) Factorised Encoder Model
Factorised Encoder的主要思想是用了两个编码器来处理时间和空间的信息:空间编码器来提取空间特征;时间编码器用来提取时间特征,由于该结构是分别处理时间维度和空间维度的信息的,因此计算量相比于1)的联合时空计算大大降低,下图的Factorised Encoder的结构:
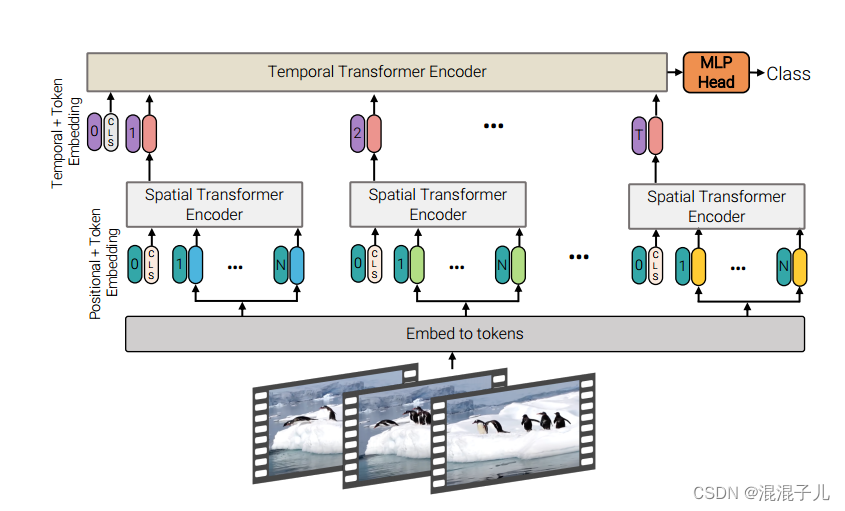
从这个结构来看,Factorised Encoder将来自不同patch的tokens分别输入空间transformer编码器中,生成空间分类token, 再将生成的空间分类token(一个patch生成一个空间分类token)输入到时间transformer编码器中,经过MLP,得到最终的分类结果。
这里我认为空间transformer编码器,时间transformer编码器跟transformer编码器的区别就是注意力机制的不同,空间transformer编码器中算的是只有空间变量的自注意力分数,时间transformer编码器算的是只有时间变量的自注意力分数。
3)Factorised Self-Attention Model
该模型与ViT不同之处是采用的注意力机制不同,该模型采用的计算注意力方式类似于TimeSformer的Divided Space-Time Attention,但TimeSformer是先计算时间attention分数,再计算空间attention分数。该模型是先计算空间attention,再计算时间attention。


4)Factorised Dot-Product Attention Model
该模型与ViT不同之处也是采用的注意力机制不同,原ViT模型采用的是多头自注意力机制(MSA),每个头部(heads)都有一组Wq,Wk,Wv来计算q,k,v,qkv生成空间的自注意力分数z,对每个头部(heads)生成的z进行拼接,再线性变换降维生成了多头自注意力分数。

而该模型将MSA进行了改进,其中一半头用来计算仅空间自注意分数。另一半头用来计算仅时间自注意力分数。
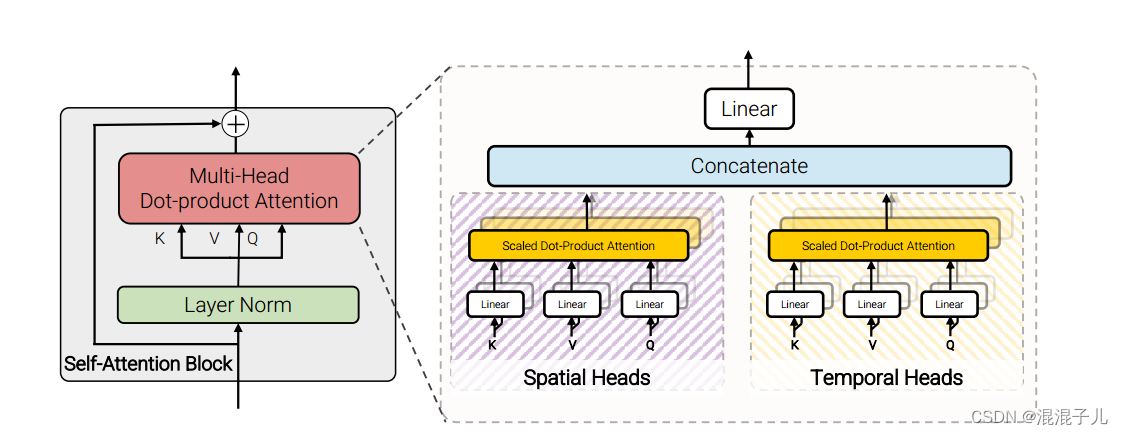
主要思想是通过对每一个query修改keys,values,使其只关注来自同一时空的tokens:

4.四个模型的区别
模型1)是一个编码器内部的计算,计算联合时空的注意力,再编码分类输出;
模型2)是两个编码器的串联,在不同编码器中计算仅时间、仅空间的注意力,在外部顺序的先执行空间注意力编码分类,再执行时间注意力编码分类输出;
模型3)是一个编码器内部的串行计算,先计算仅空间注意力,再计算仅时间注意力,再编码分类输出;
模型4)是一个编码器内部的并行计算,通过不同的头,同时计算仅时间注意力和仅空间注意力,再编码分类输出。

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









