







定义:给定一种语言,定义他的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中句子。
类型:行为类模式
类图:

解释器模式是一个比较少用的模式,本人之前也没有用过这个模式。下面我们就来一起看一下解释器模式。
解释器模式的结构
- 抽象解释器:声明一个所有具体表达式都要实现的抽象接口(或者抽象类),接口中主要是一个interpret()方法,称为解释操作。具体解释任务由它的各个实现类来完成,具体的解释器分别由终结符解释器TerminalExpression和非终结符解释器NonterminalExpression完成。
- 终结符表达式:实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符。终结符一半是文法中的运算单元,比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
- 非终结符表达式:文法中的每条规则对应于一个非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中,+就是非终结符,解析+的解释器就是一个非终结符表达式。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。
- 环境角色:这个角色的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,很多情况下我们使用Map来充当环境角色就足够了。
代码实现
- class Context {}
- abstract class Expression {
- public abstract Object interpreter(Context ctx);
- }
- class TerminalExpression extends Expression {
- public Object interpreter(Context ctx){
- return null;
- }
- }
- class NonterminalExpression extends Expression {
- public NonterminalExpression(Expression...expressions){
- }
- public Object interpreter(Context ctx){
- return null;
- }
- }
- public class Client {
- public static void main(String[] args){
- String expression = "";
- char[] charArray = expression.toCharArray();
- Context ctx = new Context();
- Stack<Expression> stack = new Stack<Expression>();
- for(int i=0;i<charArray.length;i++){
- //进行语法判断,递归调用
- }
- Expression exp = stack.pop();
- exp.interpreter(ctx);
- }
- }
文法递归的代码部分需要根据具体的情况来实现,因此在代码中没有体现。抽象表达式是生成语法集合的关键,每个非终结符表达式解释一个最小的语法单元,然后通过递归的方式将这些语法单元组合成完整的文法,这就是解释器模式。
解释器模式的优缺点
解释器是一个简单的语法分析工具,它最显著的优点就是扩展性,修改语法规则只需要修改相应的非终结符就可以了,若扩展语法,只需要增加非终结符类就可以了。
但是,解释器模式会引起类的膨胀,每个语法都需要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来非常多的麻烦。同时,由于采用递归调用方法,每个非终结符表达式只关心与自己相关的表达式,每个表达式需要知道最终的结果,必须通过递归方式,无论是面向对象的语言还是面向过程的语言,递归都是一个不推荐的方式。由于使用了大量的循环和递归,效率是一个不容忽视的问题。特别是用于解释一个解析复杂、冗长的语法时,效率是难以忍受的。
解释器模式的适用场景
在以下情况下可以使用解释器模式:
- 有一个简单的语法规则,比如一个sql语句,如果我们需要根据sql语句进行rm转换,就可以使用解释器模式来对语句进行解释。
- 一些重复发生的问题,比如加减乘除四则运算,但是公式每次都不同,有时是a+b-c*d,有时是a*b+c-d,等等等等个,公式千变万化,但是都是由加减乘除四个非终结符来连接的,这时我们就可以使用解释器模式。
注意事项
解释器模式真的是一个比较少用的模式,因为对它的维护实在是太麻烦了,想象一下,一坨一坨的非终结符解释器,假如不是事先对文法的规则了如指掌,或者是文法特别简单,则很难读懂它的逻辑。解释器模式在实际的系统开发中使用的很少,因为他会引起效率、性能以及维护等问题。
定义:解释器模式(Interpreter),给定一个语言,定义它的文法的一种表示,并定义一个解释器,用这个解释器使用该表示来解释语言中句子。解释器模式需要解决的是,如果一种特定类型的问题发生的频率足够高,那么可能就值得。
结构图:
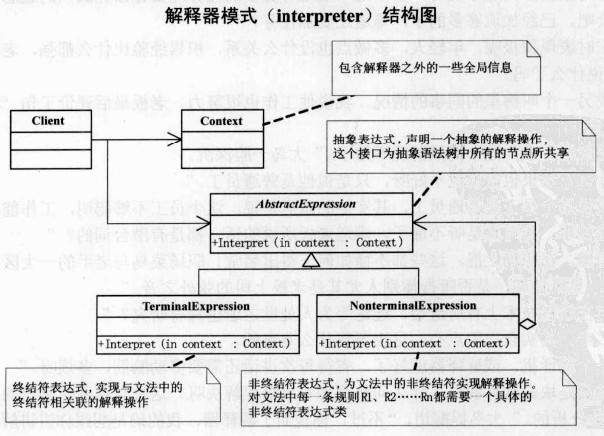
所涉及的角色:
AbstractExpression 抽象解释器:具体的解释任务由各个实现类完成,具体的解释器分别由TerminalExpression和NonterminalExpression完成。
TerminalExpression终结符表达式:实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符。具体到我们例子就是VarExpression类,表达式中的每个终结符都在堆栈中产生了一个VarExpression对象。
NonterminalExpression 非终结符表达式:文法中的每条规则对应于一个非终结表达式,具体到我们的例子就是加减法规则分别对应到AddExpression和SubExpression两个类。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。
Context 环境角色:包含解释之外的一些全局信息。
代码示例:
在银行、证券类项目中,经常会有一些模型运算,通过对现有数据的统计、分析而预测不可知或未来可能发生的商业行为。模型运算大部分是针对海量数据的,例如建立一个模型公式,分析一个城市的消费倾向,进而影响银行的营销和业务扩张方向,一般的模型运算都有一个或多个运算公式,通常是加减乘除四则运算,偶尔也有指数、开方等复杂运算。具体到一个金融业务中,模型公式是非常复杂的,虽然只有加减乘除四则运算,但是公式有可能有十多个参数,而且上百个业务品各有不同的取参路径,同时相关表的数据量都在百万级,呵呵,复杂了吧,不复杂那就不叫金融业务,我们就来讲讲运算的核心——模型公式,如何实现。
业务需求:
输入一个模型公式(加减四则运算),然后输入模型中的参数,运算出结果。
设计要求:
公式可以运行期编辑,并且符合正常算术书写方式,例如a+b-c;
高扩展性,未来增加指数、开方、极限、求导等运算符号时,较少改动量;
效率可以不用考虑,晚间批量运算。
分析过程:
需求不复杂,若仅仅对数字采用四则运算,每个程序员都可以写出来。但是增加了增加模型公式就复杂了。先解释一下为什么需要公式, 而不采用直接计算的方法,例如有如下3个公式:
业务种类1的公式:a+b+c-d;
业务种类2的公式:a+b+e-d;
业务种类3的公式:a-f。
其中,a、b、c、d、e、f参数的值都可以取得,如果使用直接计算数值的方法需要为每个品种写一个算法,目前仅仅是3个业务种类,那上百个品种呢?歇菜了吧!建立公式,然后通过公式运算才是王道。
我们以实现加减算法(由于篇幅所限,乘除法的运算读者可以自行扩展)的公式为例,讲解如何解析一个固定语法逻辑。由于使用语法解析的场景比较少,而且一些商业公司(比如SAS、SPSS等统计分析软件)都支持类似的规则运算,亲自编写语法解析的工作已经非常少,以下例程采用逐步分析方法,带领大家了解这一实现过程。
很简单的一个类图,VarExpression用来解析运算元素,各个公式能运算元素的数量是不同的,但每个运算元素都对应一个VarExpression对象。SybmolExpression负责运算符号解析,由两个子类AddExpression(负责加法运算)和SubExpression(负责减法运算)来实现。解析的工作完成了,我们还需要把安排运行的先后顺序(加减法是不用考虑,但是乘除法呢?注意扩展性),并且还要返回结果,因此我们需要增加一个封装类来进行封装处理,由于我们只做运算,暂时还不与业务有关联,定义为Calculator类,分析到这里,思路就比较清晰了,优化后加减法类图如下图所示
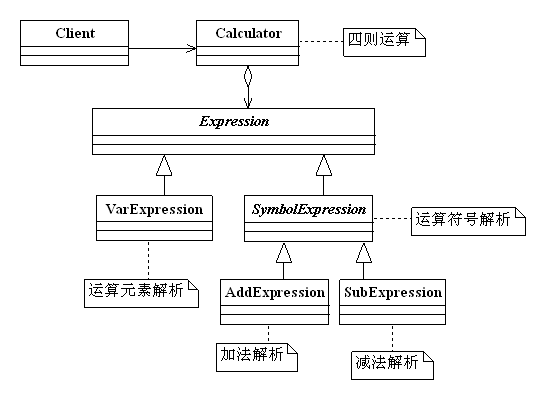
抽象表达式类:Expression
- package com.jin.model.interpreter;
- import java.util.HashMap;
- public abstract class Expression {
- // 解析公式和数值,其中var中的key值是是公式中的参数,value值是具体的数字
- public abstract int interpreter(HashMap<String, Integer> var);
- }
变量解析器:VarExpression
- package com.jin.model.interpreter;
- import java.util.HashMap;
- public class VarExpression extends Expression {
- private String key;
- public VarExpression(String _key) {
- this.key = _key;
- }
- // 从map中取之
- public int interpreter(HashMap<String, Integer> var) {
- return var.get(this.key);
- }
- }
抽象运算符号解析器:SymbolExpression
- package com.jin.model.interpreter;
- public abstract class SymbolExpression extends Expression {
- protected Expression left;
- protected Expression right;
- // 所有的解析公式都应只关心自己左右两个表达式的结果
- public SymbolExpression(Expression _left, Expression _right) {
- this.left = _left;
- this.right = _right;
- }
- }
加法解析器:AddExpression
- package com.jin.model.interpreter;
- import java.util.HashMap;
- public class AddExpression extends SymbolExpression {
- public AddExpression(Expression _left, Expression _right) {
- super(_left, _right);
- }
- // 把左右两个表达式运算的结果加起来
- public int interpreter(HashMap<String, Integer> var) {
- return super.left.interpreter(var) + super.right.interpreter(var);
- }
- }
减法解析器:SubExpression
- package com.jin.model.interpreter;
- import java.util.HashMap;
- public class SubExpression extends SymbolExpression {
- public SubExpression(Expression _left, Expression _right) {
- super(_left, _right);
- }
- // 左右两个表达式相减
- public int interpreter(HashMap<String, Integer> var) {
- return super.left.interpreter(var) - super.right.interpreter(var);
- }
- }
解析器封装类:Calculator
- package com.jin.model.interpreter;
- import java.util.HashMap;
- import java.util.Stack;
- public class Calculator {
- // 定义的表达式
- private Expression expression;
- // 构造函数传参,并解析
- public Calculator(String expStr) {
- // 定义一个堆栈,安排运算的先后顺序
- Stack<Expression> stack = new Stack<Expression>();
- // 表达式拆分为字符数组
- char[] charArray = expStr.toCharArray();
- // 运算
- Expression left = null;
- Expression right = null;
- for (int i = 0; i < charArray.length; i++) {
- switch (charArray[i]) {
- case '+': // 加法
- // 加法结果放到堆栈中
- left = stack.pop();
- right = new VarExpression(String.valueOf(charArray[++i]));
- stack.push(new AddExpression(left, right));
- break;
- case '-':
- left = stack.pop();
- right = new VarExpression(String.valueOf(charArray[++i]));
- stack.push(new SubExpression(left, right));
- break;
- default: // 公式中的变量
- stack.push(new VarExpression(String.valueOf(charArray[i])));
- }
- }
- // 把运算结果抛出来
- this.expression = stack.pop();
- }
- // 开始运算
- public int run(HashMap<String, Integer> var) {
- return this.expression.interpreter(var);
- }
- }
客户端:Client
- package com.jin.model.interpreter;
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.util.HashMap;
- public class Client {
- // 运行四则运算
- public static void main(String[] args) throws IOException {
- String expStr = getExpStr();
- // 赋值
- HashMap<String, Integer> var = getValue(expStr);
- Calculator cal = new Calculator(expStr);
- System.out.println("运算结果为:" + expStr + "=" + cal.run(var));
- }
- // 获得表达式
- public static String getExpStr() throws IOException {
- System.out.print("请输入表达式:");
- return (new BufferedReader(new InputStreamReader(System.in)))
- .readLine();
- }
- // 获得值映射
- public static HashMap<String, Integer> getValue(String exprStr)
- throws IOException {
- HashMap<String, Integer> map = new HashMap<String, Integer>();
- // 解析有几个参数要传递
- for (char ch : exprStr.toCharArray()) {
- if (ch != '+' && ch != '-') {
- // 解决重复参数的问题
- if (!map.containsKey(String.valueOf(ch))) {
- System.out.print("请输入" + ch + "的值:");
- String in = (new BufferedReader(new InputStreamReader(
- System.in))).readLine();
- map.put(String.valueOf(ch), Integer.valueOf(in));
- }
- }
- }
- return map;
- }
- }
其中,getExpStr是从键盘事件中获得的表达式,getValue方法是从键盘事件中获得表达式中的元素映射值,运行过程如下。
首先,要求输入公式。
请输入表达式:a+b-c
其次,要求输入公式中的参数。
请输入a的值:100
请输入b的值:20
请输入c的值:40
最后,运行出结果。
运算结果为:a+b-c=80
看,要求输入一个公式,然后输入参数,运行结果出来了!那我们是不是可以修改公式?当然可以了,我们只要输入公式,然后输入相应的值就可以了,公式是在运行期定义的,而不是在运行前就制定好的,是不是类似于初中学过的“代数”这门课?先公式,然后赋值,运算出结果。
需求已经开发完毕,公式可以自由定义,只要符合规则(有变量有运算符合)就可以运算出结果;若需要扩展也非常容易,只要增加SymbolExpression的子类就可以了 ,这就是解释器模式。
使用场景:
重复发生的问题可以使用解释器模式
例如,多个应用服务器,每天产生大量的日志,需要对日志文件进行分析处理,由于各个服务器的日志格式不同,但是数据要素是相同的,按照解释器的说法就是终结符表达式都是相同的,但是非终结符表达式就需要制定了。在这种情况下,可以通过程序来一劳永逸地解决该问题。
一个简单语法需要解释的场景
为什么是简单?看看非终结表达式,文法规则越多,复杂度越高,而且类间还要进行递归调用(看看我们例子中的堆栈),不是一般地复杂。想想看,多个类之间的调用你需要什么样的耐心和信心去排查问题。因此,解释器模式一般用来解析比较标准的字符集,例如SQL语法分析,不过该部分逐渐被专用工具所取代。
在某些特用的商业环境下也会采用解释器模式,我们刚刚的例子就是一个商业环境,而且现在模型运算的例子非常多,目前很多商业机构已经能够提供出大量的数据进行分析。
优点:
解释器是一个简单语法分析工具,它最显著的优点就是扩展性,修改语法规则只要修改相应的非终结符表达式就可以了,若扩展语法,则只要增加非终结符类就可以了。
缺点:
解释器模式会引起类膨胀:每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。
解释器模式采用递归调用方法:每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。想想看,如果要排查一个语法错误,我们是不是要一个一个断点的调试下去,直到最小的语法单元。
效率问题:解释器模式由于使用了大量的循环和递归,效率是个不容忽视的问题,特别是用于解析复杂、冗长的语法时,效率是难以忍受的。
注意事项:
尽量不要在重要的模块中使用解释器模式,否则维护会是一个很大的问题。在项目中可以使用shell、JRuby、Groovy等脚本语言来代替解释器模式,弥补Java编译型语言的不足。我们在一个银行的分析型项目中就采用JRuby进行运算处理,避免使用解释器模式的四则运算,效率和性能各方面表现良好。
最佳实践:
解释器模式在实际的系统开发中使用的非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,比如一些数据分析工具、报表设计工具、科学计算工具等等,若你确实遇到“一种特定类型的问题发生的频率足够高”的情况,准备使用解释器模式时,可以考虑一下Expression4J、MESP(MathExpression String Parser)、Jep等开源的解析工具包(这三个开源产品都可以百度、Google中搜索到,请读者自行查询),功能都异常强大,而且非常容易使用,效率也还不错,实现大多数的数学运算完全没有问题,自己没有必要从头开始编写解释器,有人已经建立了一条康庄大道,何必再走自己的泥泞小路呢?















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









