










背景
我们需要一个酒店预订应用程序,满足用户预定功能以及一个酒店管理后台;
目标
为用户提供了从酒店列表---->预订------>付款一套完整的流程;
功能模块拆解
- 酒店管理服务 hotel management service
- 顾客服务之搜索--customer service search
- 顾客服务之预定--customer service booking
- 查询预定服务 view booking service
酒店管理服务 Hotel Management service
管理服务将提供给酒店经理/业主使用。经理可以管理酒店的相关信息。管理员有一个单独的门户来访问和更新数据。
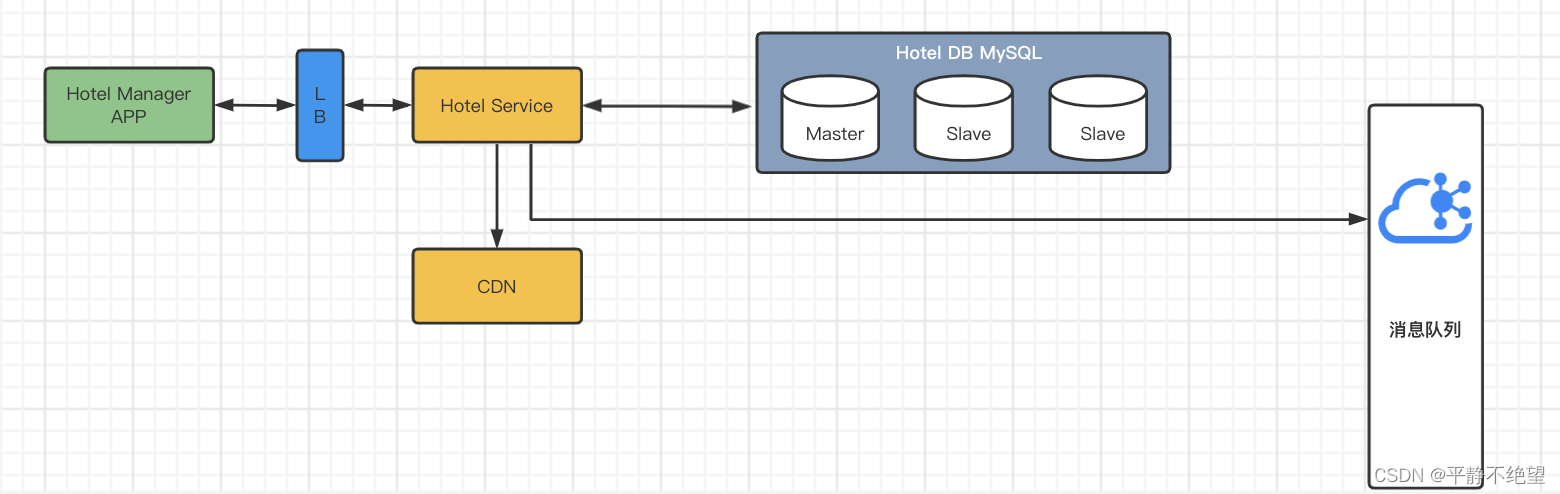
酒店经理使用管理应用程序触发一个 API 时,初始请求就被发送到负载平衡器LB,然后负载平衡器将请求分发到所需的服务器进行处理。酒店服务集群有多个服务器,其中包含与酒店服务相关的 API 的服务。
Hotel Service 酒店服务与 Hotel DB 集群进行交互,后者遵循主从架构,以减少数据库中的负载。数据库集群实现,我们可以创建一个或多个主数据库的副本,称为从数据库。主数据库用于写操作,从数据库只用于读操作。每当对主数据库执行写操作时,它都会将数据同步到从数据库。
每当数据库 API 中的任何数据被更新时,就将数据发送到 CDN (内容分布网络)和消息队列系统(如 Kafka、 RabbitMQ)以进行进一步处理。CDN 是一组在地理上分布的服务器,它们协同工作以提供 Internet 内容的快速传输。
顾客服务---搜索 预定 Customer Service For Search And Booking
该服务提供顾客搜索和预订酒店的能力。客户有一个单独的门户来访问和处理数据。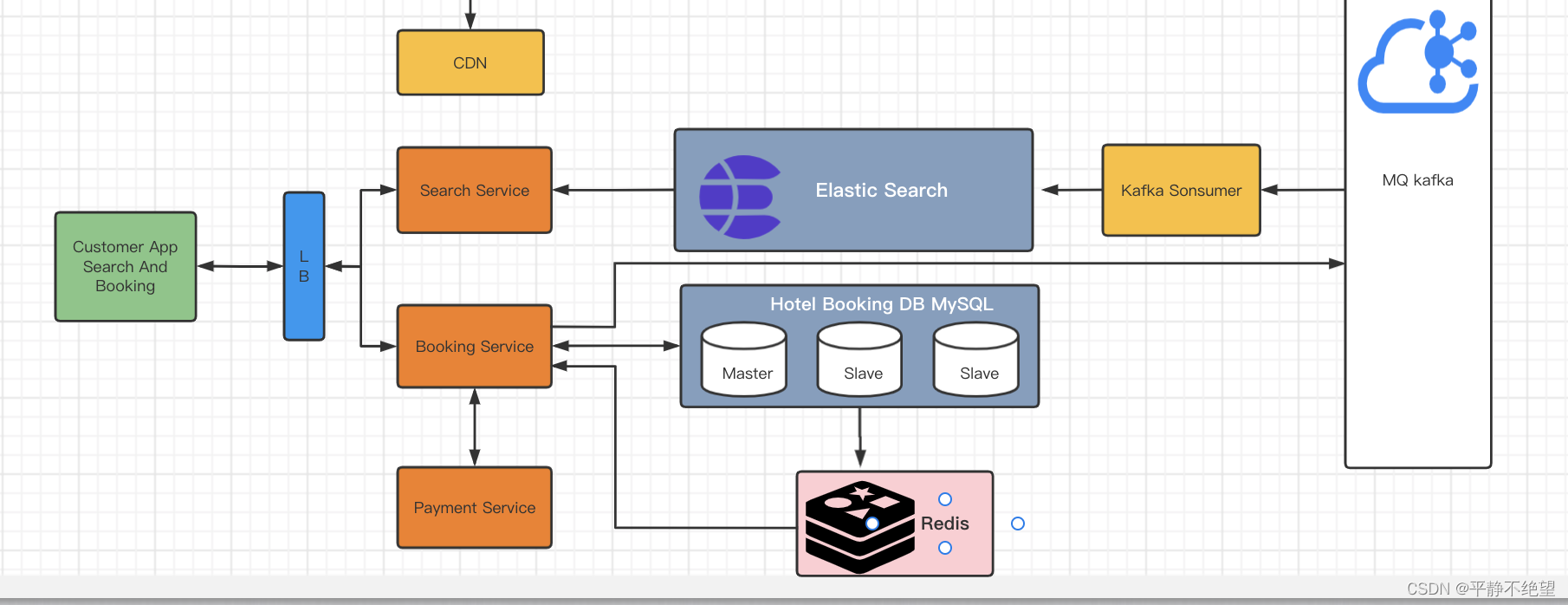
CDN 应用程序向客户显示内容,如附近的酒店、推荐、优惠等。酒店数据在消息传递队列系统中发送以处理它。这里我们有一个消息传递队列使用者,它从队列中获取数据并存储数据到ES服务中。客户应用程序请求 API,然后负载均衡LB重定向和分发请求到各自的服务,以处理请求。这里两个服务,一个是搜索酒店和预订服务,预订酒店和预订服务也将与第三方服务的支付服务Payment Service交互。
搜索服务必须从ES中获取数据。Elasticsearch 是一个最适合其搜索引擎功能的 NoSQL 数据库。预订服务与 Redis 和预订数据库集群通信。Redis 是一个缓存系统,它存储临时数据,这样数据就不需要查询数据库,最终可以减少数据库中的负载Load,同时也减少了 API 的响应时间。在数据库中所做的任何更改都将发送到消息传递队列。然后消费者将从队列中获取数据并将其放到 Casandra。Casandra (Apache Cassandra)是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于改善电子邮件系统的搜索性能的简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身(NoSQL 数据库,擅长处理大量数据)。
查询预定服务 View Booking Service
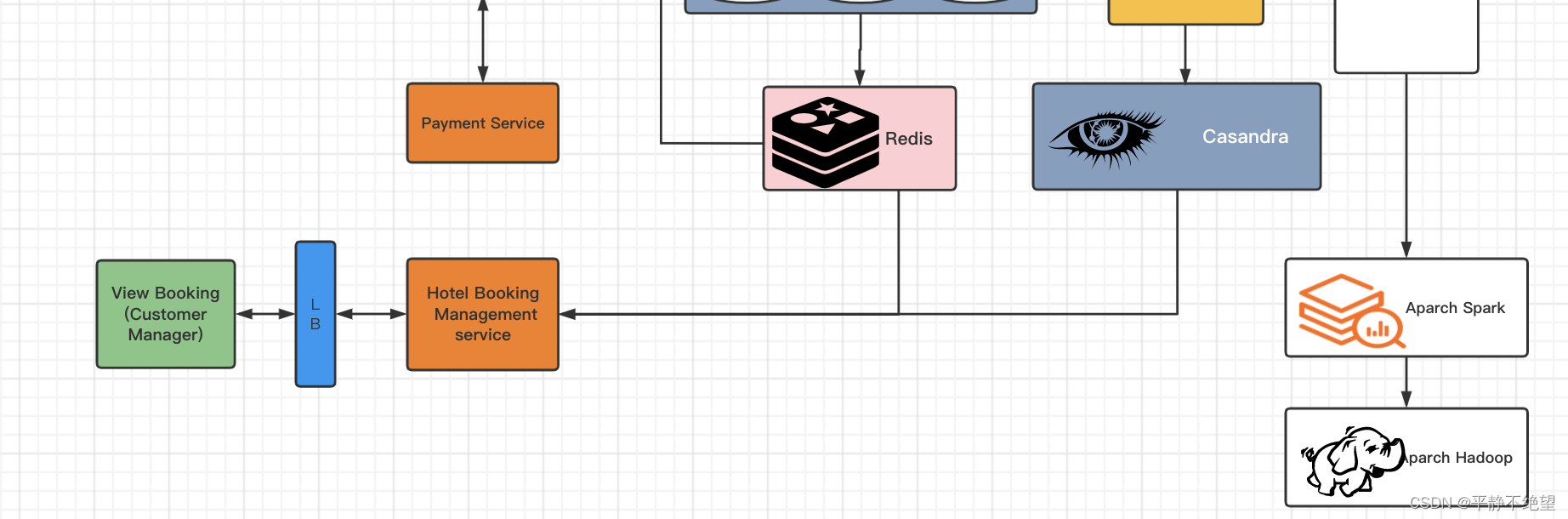
该服务会把当前和旧的预订信息都显示给用户。酒店经理也会访问该服务,如导出历史订单等;
Customer/Manager 应用程序将请求发送到负载均衡器,并将请求分发到预订管理服务器。然后通过 Redis 和 Cassandra 对数据进行服务请求。它通过 Redis 请求最近的数据,因为它是一个缓存服务器。这可以减少应用程序端的加载时间。Apache Streaming 服务从消息队列获取数据,并将其存储在 Hadoop 中,可用于多种目的的 BigData 分析。像业务分析,寻找潜在客户,受众分类等。
最后还有一个通知模块:
消费kafka的消息并向消费者发送通知。这可以发送给客户/经理,比如每当客户预订酒店时,酒店通知就会发送给经理,或者如果有新的报价,就会通知客户。
汇总后的架构图
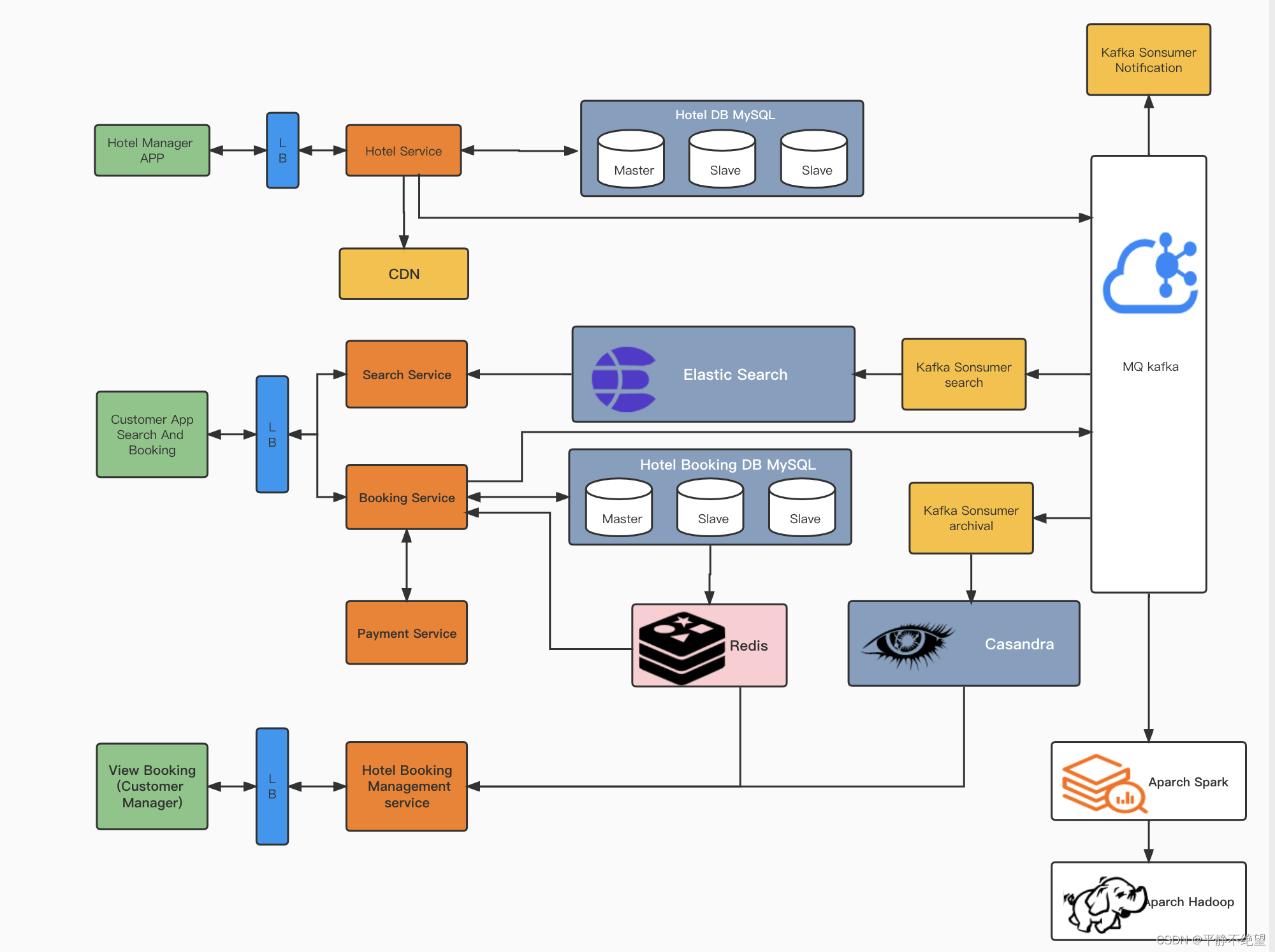
参考:
Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在执行完工作后将中介资料存放到磁盘中,Spark使用了存储器内运算技术,能在资料尚未写入硬盘时即在存储器内分析运算。Spark在存储器内执行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是执行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将资料加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理[3]。
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高[4][5]。
Apache Hadoop框架由以下基本模块构成:



















 6938
6938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











