







运行第一个SparkStreaming程序(及过程中问题解决)
Windows下IntelliJ IDEA中调试Spark Standalone
sbt-assembly 发布 Scala 项目
使用IDEA开发及测试Spark的环境搭建及简单测试
基于spark运行scala程序(sbt和命令行方法)主要是实践一下scala开发项目的流程
创建项目
创建一个scala项目取名为streaming,使用sbt构建,因为我使用的spark版本为2.0.0,所以官方要求scala的版本要大于0.13.6,所以要注意一下兼容的问题
添加spark-streaming依赖
在build.sbt中添加依赖
name := "streaming"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.0.0" % "provided"sbt-assembly插件添加
在project/plugins.sbt中添加下面一行,然后重新编译项目
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.3")编码
在src目录下添加QNetworkWordCount.scala文件
代码如下:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by doctorq on 16/9/2.
*/
object QNetworkWordCount{
def main(args: Array[String]): Unit = {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
val sparkConf = new SparkConf().setAppName("QNetworkWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
运行
两种方式运行,一种是IDE直接运行,一种是命令行使用spark-submit运行,无论哪种方式运行,都需要执行nc -lk 9999开启通道

idea运行
首先配置一下运行参数
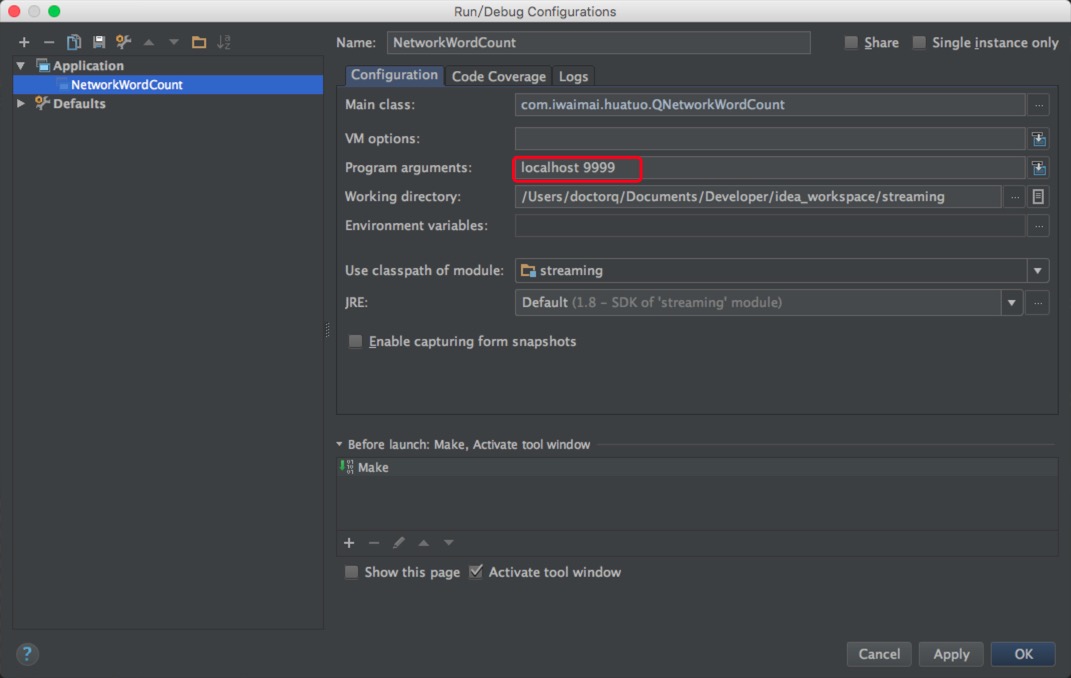
红框标注的为传递的参数,然后来执行看看效果
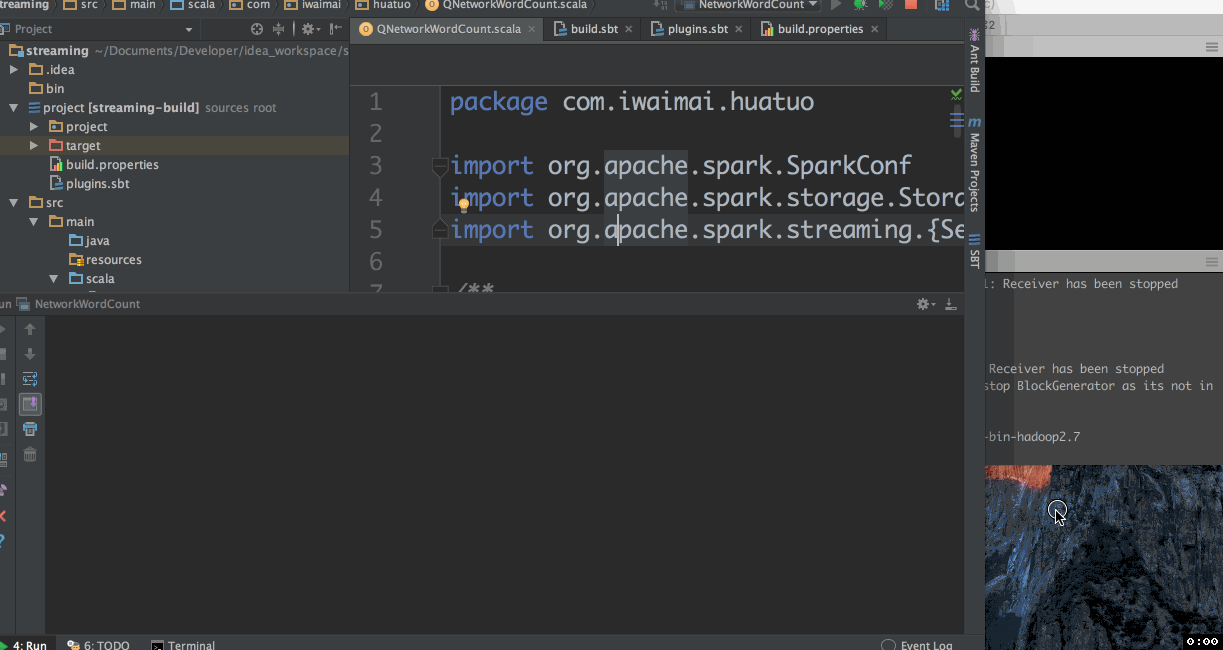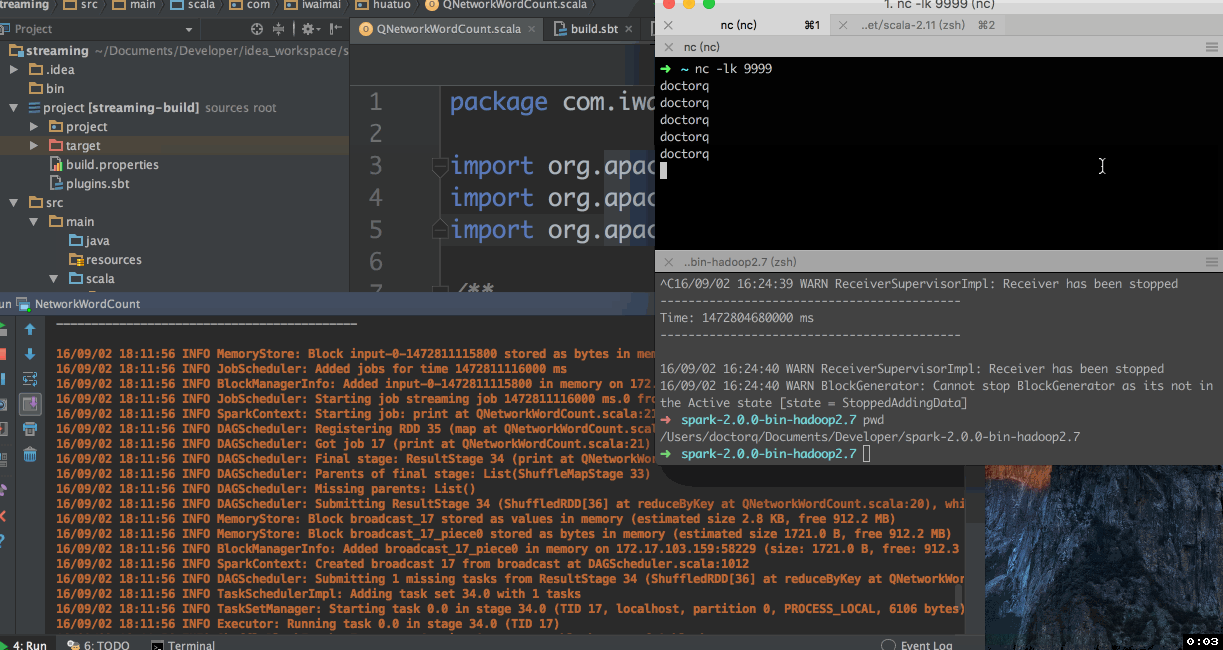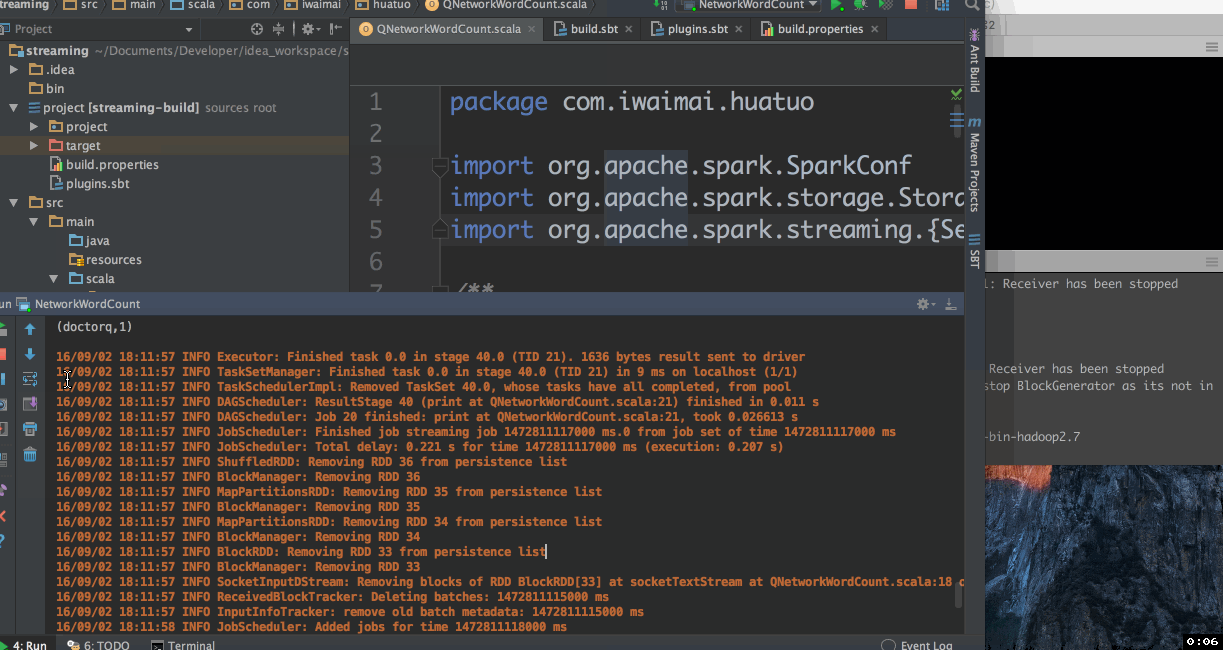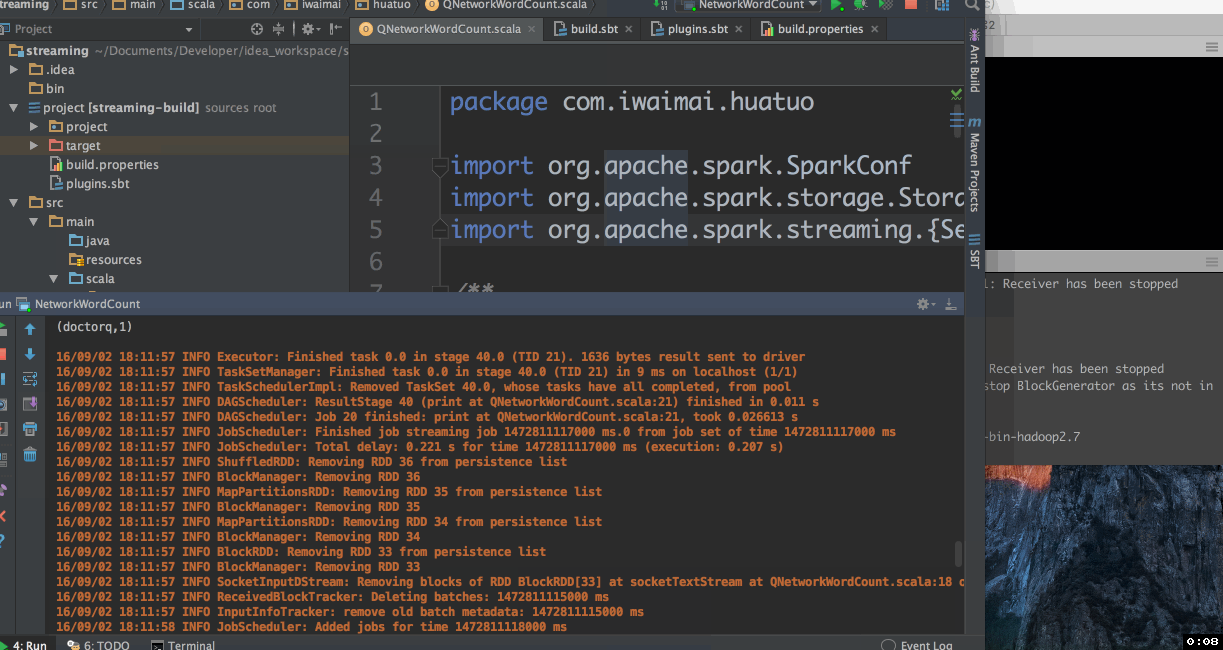
命令行运行
首先需要sbt打包
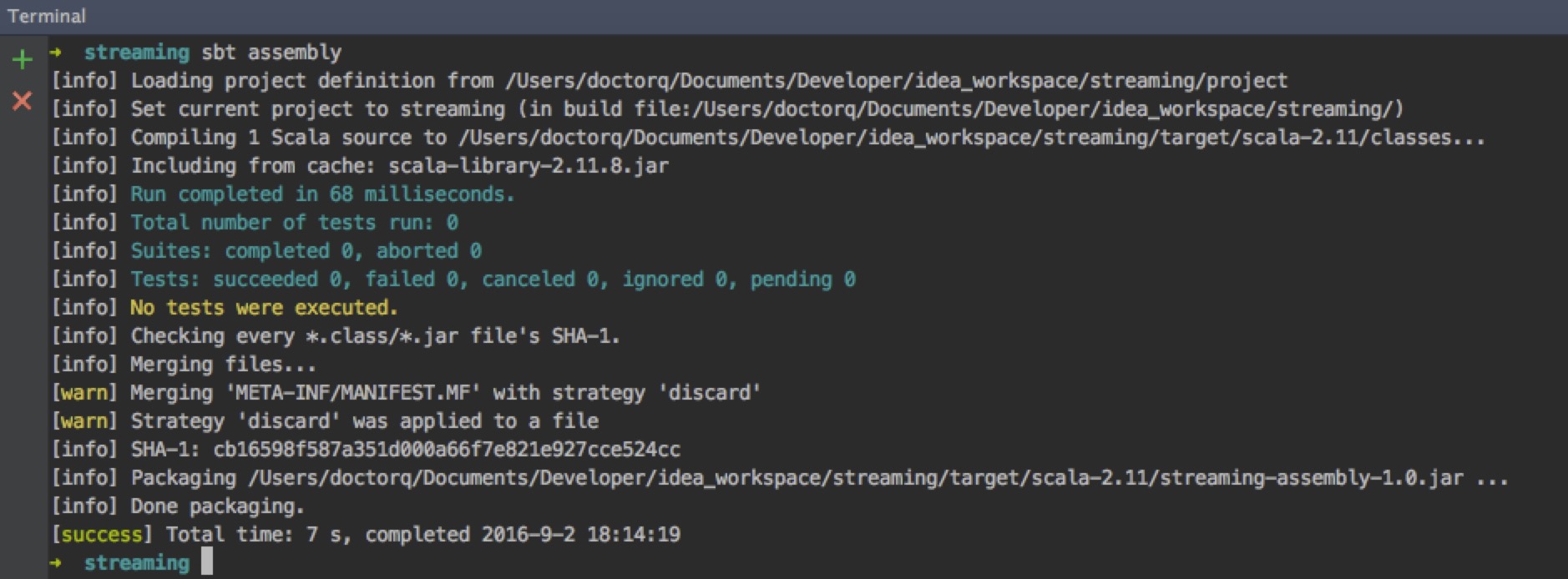
在spark目录下执行命令
> bin/spark-submit --class "com.iwaimai.huatuo.QNetworkWordCount" --master local[2] /Users/doctorq/Documents/Developer/idea_workspace/streaming/target/scala-2.11/streaming-assembly-1.0.jar localhost 9999

集群运行
--master的值将local[*]修改为集群中的master url(我的机器为spark://doctorqdeMacBook-Pro.local:7077)
/Users/doctorq/Documents/Developer/spark-2.0.0-bin-hadoop2.7/bin/spark-submit --class "com.iwaimai.huatuo.QNetworkWordCount" --master spark://doctorqdeMacBook-Pro.local:7077 /Users/doctorq/Documents/Developer/idea_workspace/streaming/target/scala-2.11/streaming-assembly-1.0.jar localhost 9999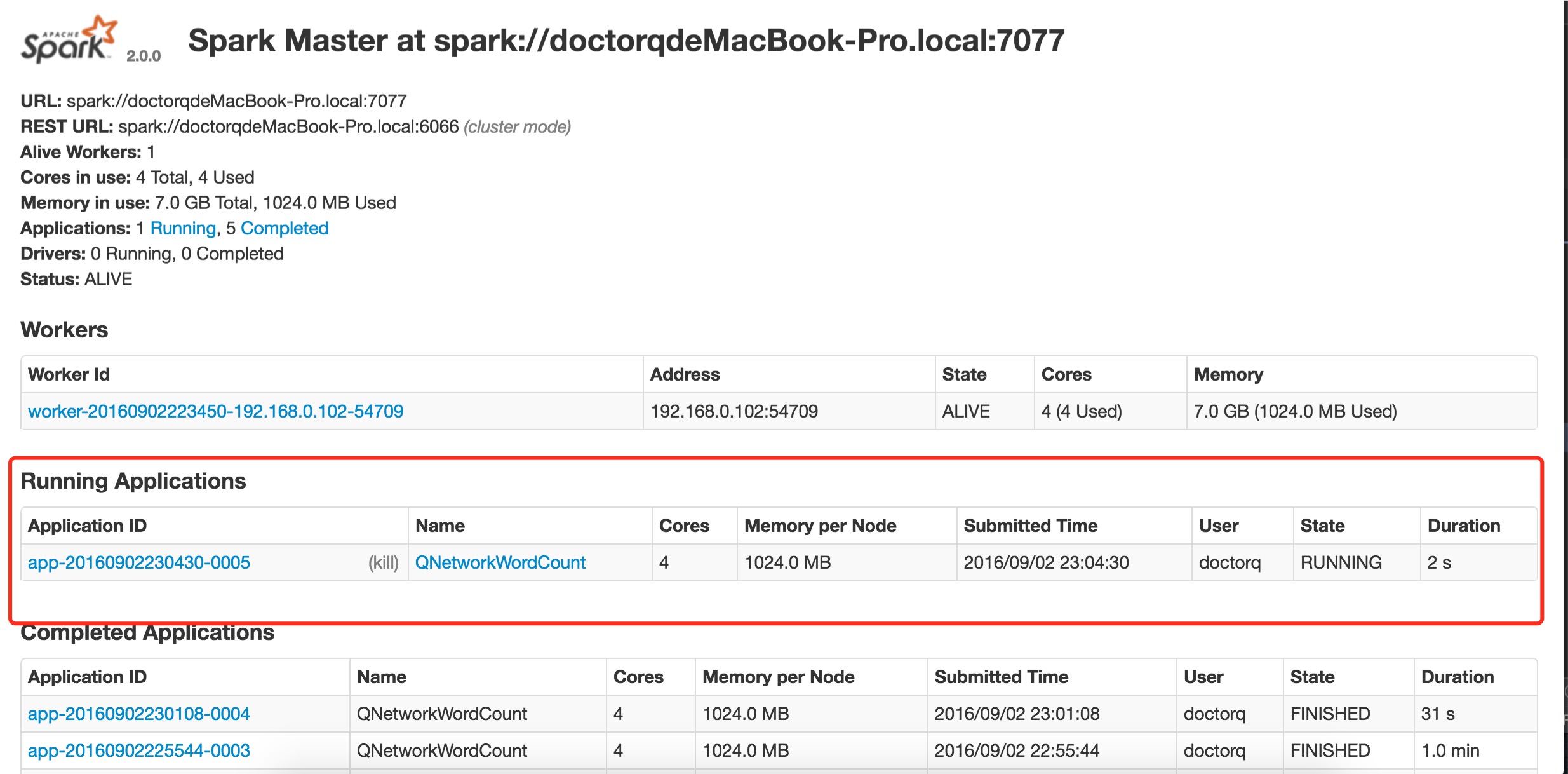
总结
主要通过这样一个实例梳理一下idea下scala开发项目一直打包的流程
spark streaming在命令行下必须先打包,使用spark-submit运行- 样例中使用的都是local模式,所以在
webUI中看不到实例的信息,如果要使用集群运行,我们需要修改下--master的值,改为master url,例如我本机的地址为spark://doctorqdeMacBook-Pro.local:7077,不要忘了代码中就不要设置master信息了















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









