







这几天把流式计算系统跑起来了,跑了一天后,负责HBase的同学跟我说我存储的方式有问题,最后问题追踪到了hbase的rowkey问题上,也是很神奇
问题
- 存储过来的文件都是几十KB一个文件
- region split太多,一天后region增加到46个
找问题
因为第一次接触spark,第一次接触scala,反正从听说流式计算开始到现在也才一个月,新手一个。听到这个问题后也是很懵逼,反复跟Hbase的op确认后,确实是我的问题,我采用的是Hbase-rdd库中的toBHbaseBulk的方式将spark数据存在HDFS中,然后从底层导入到HBase中,没有走正规的请求方式,但是我没找到这个地方可以控制我导入文件大小的设置方式,所以放弃了这种方式,改成了正常的PUT方式将数据导入HBase中,小文件的问题解决了,随之而来的是OP又说这种随时间增加的rowkey会造成热点问题(又懵逼了),需要做一下hash,一开始我是拒绝的,再反复对比后,抱着试试看的方式去研究了下,其实实现起来也简单,就是在之前的rowkey前缀加了一下下面的方法
MD5Hash.getMD5AsHex(Bytes.toBytes("之前的rowkey前缀"))rowkey的变化如下:
| 原rowkey | hash化后的rowkey |
|---|---|
| 506573390_1474947840000 | ffcbf35613ec83d2ad15ea08576ec496_1474947840000 |
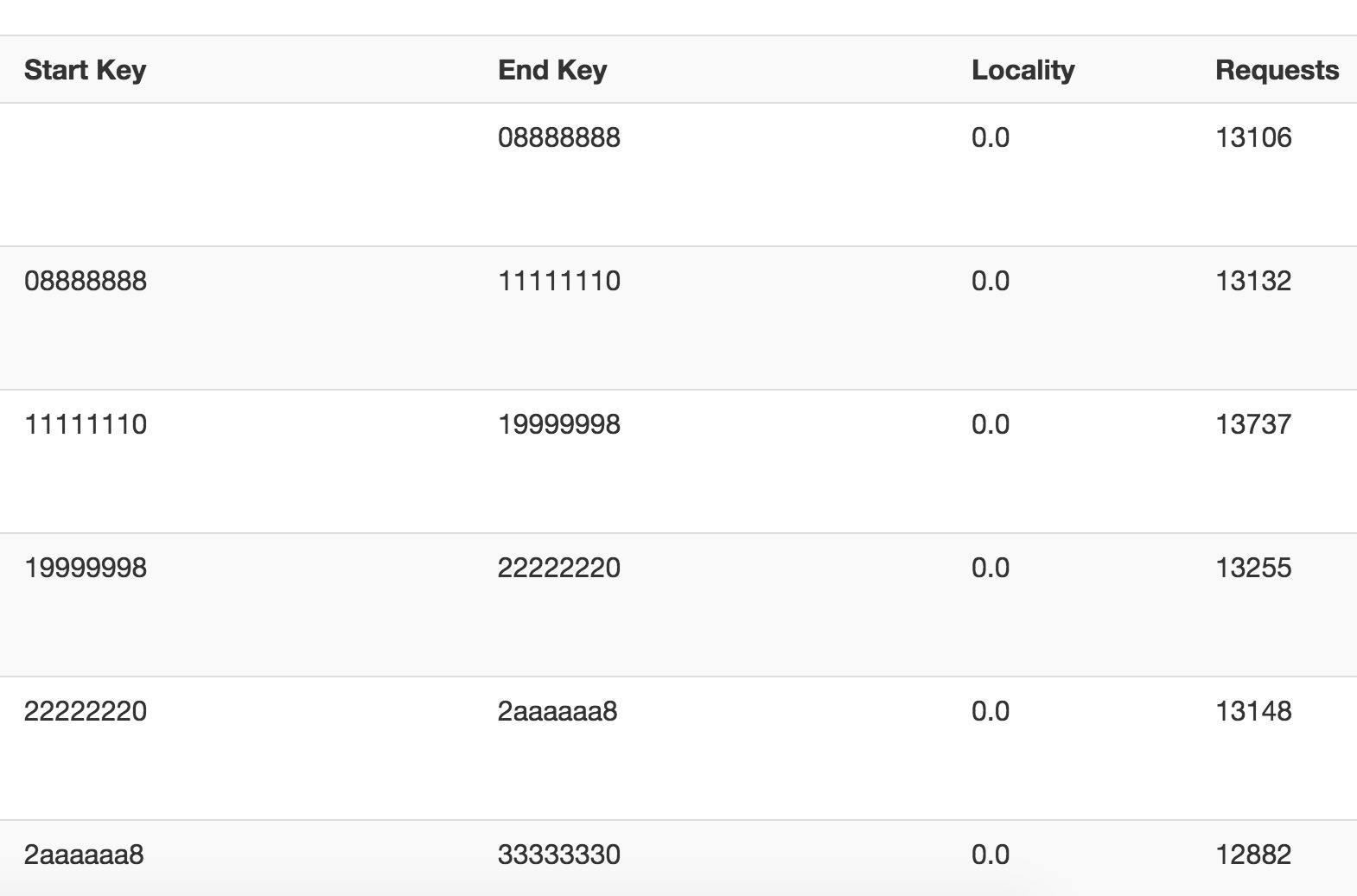
实际效果
op给我的表做了30个预分区,然后会发现我们的请求均匀的分布在了各个region中,有效的防止了热点效应,起到分布式的效果,问题解决,至于bulkload的方式为什么都是小文件,留待以后解决吧,等我成长为老鸟的时候















 31
31

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









