







 数据标准化是通过计算每个属性的均值和标准差,将数据转化为平均值为0,标准差为1的标准正态分布。Python中,可以使用sklearn.preprocessing.scale()函数或StandardScaler类来实现数据标准化。scale()函数直接处理数据,而StandardScaler类则能保存训练集参数以应用于测试集。
数据标准化是通过计算每个属性的均值和标准差,将数据转化为平均值为0,标准差为1的标准正态分布。Python中,可以使用sklearn.preprocessing.scale()函数或StandardScaler类来实现数据标准化。scale()函数直接处理数据,而StandardScaler类则能保存训练集参数以应用于测试集。
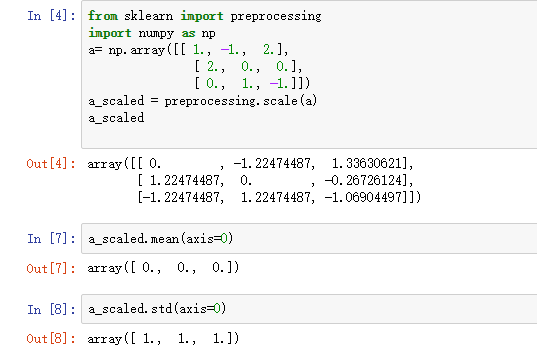
公式为:(X-mean)/std 计算时对每个属性/每列分别进行。将数据按期属性(按列进行)减去其均值,并处以其方差。得到的结果是 ,对于每个属行/每列来说所有数据都聚集在0附近,方差为1。
实现时,有两种不同的方式:
1、sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
from sklearn import preprocessing
import numpy as np
a= np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
a_scaled = preprocessing.scale(a)
a_scaled.mean(axis=0)
a_scaled.std(axis=0)
2、使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2839
2839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









