 数据库比较:关系型与非关系型优缺点及性能测试
数据库比较:关系型与非关系型优缺点及性能测试




 本文探讨了关系型数据库(如MySQL、Oracle)和非关系型数据库(如MongoDB、Cassandra)的优缺点,以及图数据库(如Neo4j、TuGraph)的特点。通过实例,对比了不同数据库在查询效率上的表现,包括Docker部署和Python生成测试数据的应用。
本文探讨了关系型数据库(如MySQL、Oracle)和非关系型数据库(如MongoDB、Cassandra)的优缺点,以及图数据库(如Neo4j、TuGraph)的特点。通过实例,对比了不同数据库在查询效率上的表现,包括Docker部署和Python生成测试数据的应用。
常见数据库优缺点
—结合文心一言总结,如有不当请指正
| 数据库 | 优点 | 缺点 |
|---|---|---|
| 关系型数据库 | (1)二维表易理解; (2)通用SQL易操作; (3)支持复杂操作; (4)ACID特性保障数据正确可靠。 | (1)海量数据读写性能差; (2)表结构预先固定灵活度差; (3)扩展性较差; (4)成本较高。 |
| MySQL | 开源、轻量级、成本低。 | 大数据处理性能较差。 |
| Oracle | 功能强大、稳定性好。 | 硬件等成本高。 |
| SQL Server | 与Windows集成好、易用性强。 | 跨平台支持有限。 |
| PostgreSQL | 开源、稳定、数据类型多。 | 市场份额小生态不够成熟。 |
| DB2 | 稳定、高性能、高安全性。 | 成本高。 |
| 非关系型数据库 | (1)通常分布式架构易扩展; (2)支持多种数据模型; (3)结构简单性能较高。 | (1)复杂查询受限; (2)成熟度和工具支持度较差; (3)数据安全性和一致性较差。 |
| Hbase | 大规模存储,可扩展性高,列存储和查询。 | 非列族查询效率低,不支持事务,实时分析查询效率低。 |
| MongoDB | 文档存储可处理复杂数据结构,支持全文索引,操作简单。 | 大量写或复杂聚合查询占用空间大。 |
| Cassandra | 高可用,线性扩展,节点间自动复制易管理,适合写密集型应用。 | 不适合复杂聚合,高一致性数据访问可能有问题。 |
| Redis | 内存存储读写性能优异,数据类型丰富,适合缓存或消息队列。 | 数据量受限于内存大小,不支持复杂查询和事务。 |
| 图数据库 | (1)复杂关联关系处理能力强; (2)易于扩展; (3)可视化效果好。 | (1)生态系统相对不成熟; (2)资源消耗较大; (3)部分查询复杂性较高。 |
| Neo4j | 原生图数据库,图遍历性能高,Cypher查询易编写和执行,社区活跃有大量插件、工具。 | 处理超大规模数据集可能性能瓶颈,非遍历类查询性能可能较差。 |
| OrientDB | 支持多模型如图、文档和键值对灵活性较高,支持分布式集群水平扩展性较好,SQL查询易于使用。 | 复杂图查询性能可能不如专门图数据库,分布式功能不够成熟。 |
| JanusGraph | 开源分布式图库,可处理大规模数据,支持高并发、高可用和可扩展,定制存储和查询策略灵活性高。 | 配置和管理工作更复杂,门槛较高。 |
| TuGraph | 支持强Schema,提供多种接口,并行处理提升复杂查询效率。 | 社区支持和成熟度不足,并行处理在特定场景资源消耗和复杂度增加。 |
TuGraph和Mysql查询效率对比
运行环境
1.win11下载安装Docker Desktop;
2.Docker部署TuGraph;
3.Docker部署Mysql。
—网上安装教程很多,不再赘述
测试数据
使用Python随机生成测试数据(借助AI工具code):
测试数据及生成程序下载
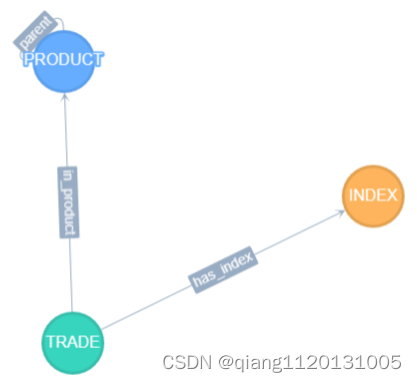
| 图/表 | 属性 | 数量 |
|---|---|---|
| 点 PRODUCT | ID、NAME | 85 |
| 表 PRODUCT | PRODUCT_ID、NAME | 85 |
| 边parent | PRODUCT > PRODUCT | 85 |
| 表PARENT | PRODUCT_ID、PARENT | 85 |
| 点 TRADE | ID、DATE、BUY_SELL、NOMINAL | 10000 |
| 表 TRADE | TRADE_ID、DATE、BUY_SELL、NOMINAL | 10000 |
| 边in_product | TRADE > PRODUCT | 10000 |
| 表IN_PRODUCT | TRADE_ID、PRODUCT_ID | 10000 |
| 点 TRADE_INDEX | ID、DATE、VALUE | 3650000 |
| 表 TRADE_INDEX | INDEX_ID、DATE、VALUE | 3650000 |
| 边has_index | TRADE > INDEX | 3650000 |
| 表HAS_INDEX | TRADE_ID、INDEX_ID | 3650000 |
查询耗时对比
–陆续更新对比语句
| 查询 | GQL/SQL | 首次 | 二次 |
|---|---|---|---|
| 最大值 | MATCH (n:INDEX) RETURN max(n.VALUE) | 30s | 4s |
| 最大值 | SELECT MAX(VALUE) FROM TRADE_INDEX; | 1.2s | 1.2s |
| 分组平均值 | MATCH (t:TRADE)-[r:has_index]->(i:INDEX) RETURN t.ID,avg(i.VALUE) | 12.8s | 7s |
| 分组平均值 | SELECT TRADE_ID,AVG(VALUE) FROM TRADE_INDEX ti LEFT JOIN HAS_INDEX hi ON ti.INDEX_ID+0=hi.INDEX_ID+0 GROUP BY TRADE_ID; | 8.4s | 8.2s |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









