







[python爬虫笔记]
💕学习爬虫的第二天💕
HTTP协议
HTTP(超文本传输协议,HyperText Transfer Protocol)是一种用于分布式、协作式、超媒体信息系统的应用层协议。
HTTP 是万维网(WWW)的数据通信的基础,设计目的是确保客户端与服务器之间的通信,是互联网上最常用的协议之一。
HTTP 是一个基于 TCP/IP 通信协议来传递数据的(HTML 文件、图片文件、查询结果等)。
设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法,通过 HTTP 或者 HTTPS 协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
HTTP 的请求-响应
HTTP 的基本工作原理是客户端(通常是 web 浏览器)向服务器发送请求,服务器接收到请求后,返回相应的资源。这些资源可以是网页、图像、音频文件、视频等。
HTTP 使用了客户端-服务器模型,其中客户端发送请求,服务器返回响应。

HTTP 的请求-响应模型通常由以下几个步骤组成
- 建立连接:客户端与服务器之间建立连接。在传统的 HTTP 中,这是基于 TCP/IP 协议的。最近的 HTTP/2 和 HTTP/3 则使用了更先进的传输层协议,例如基于 TCP 的二进制协议(HTTP/2)或基于 UDP 的 QUIC 协议(HTTP/3)。
- 发送请求:客户端向服务器发送请求,请求中包含要访问的资源的 URL、请求方法(GET、POST、PUT、DELETE 等)、请求头(例如,Accept、User-Agent)以及可选的请求体(对于 POST 或 PUT 请求)。
- 处理请求:服务器接收到请求后,根据请求中的信息找到相应的资源,执行相应的处理操作。这可能涉及从数据库中检索数据、生成动态内容或者简单地返回静态文件。
- 发送响应:服务器将处理后的结果封装在响应中,并将其发送回客户端。响应包含状态码(用于指示请求的成功或失败)、响应头(例如,Content-Type、Content-Length)以及可选的响应体(例如,HTML 页面、图像数据)。
- 关闭连接:在完成请求-响应周期后,客户端和服务器之间的连接可以被关闭,除非使用了持久连接(如 HTTP/1.1 中的 keep-alive)。
注:在爬虫的时需要使用.close()关闭链接,否则链接会一直存在,降低效率和造成服务器资源浪费

HTTP 方法
HTTP 方法指定了客户端可以对服务器上的资源执行哪些动作。
主要的HTTP方法有:
- GET:请求从服务器获取指定资源。这是最常用的方法,用于访问页面。
- POST:请求服务器接受并处理请求体中的数据,通常用于表单提交。
- PUT:请求服务器存储一个资源,并用请求体中的内容替换目标资源的所有内容。
- DELETE:请求服务器删除指定的资源。
- HEAD:与 GET 类似,但不获取资源的内容,只获取响应头信息。
HTTP 状态码
HTTP状态码是服务器对客户端请求的响应。状态码分为五类:
- 1xx(信息性状态码):表示接收的请求正在处理。
- 2xx(成功状态码):表示请求正常处理完毕。
- 3xx(重定向状态码):需要后续操作才能完成这一请求。
- 4xx(客户端错误状态码):表示请求包含语法错误或无法完成。
- 5xx(服务器错误状态码):服务器在处理请求的过程中发生了错误。
比如404代表服务器崩溃等。日常生活中这些也都比较常见,当我们遇到这些的时候最烦人,懂的都懂😭~
HTTP 版本
HTTP 有多个版本,目前广泛使用的是 HTTP/1.1 和 HTTP/2,以及正在逐步推广的 HTTP/3。
- HTTP/1.1:支持持久连接,允许多个请求/响应通过同一个 TCP 连接传输,减少了建立和关闭连接的消耗。
- HTTP/2:基于二进制分帧,支持多路复用,允许同时通过单一的 HTTP/2 连接发起多重的、独立的、双向的交流。
- HTTP/3:基于 QUIC 协议,旨在减少网络延迟,提高传输速度和安全性。
安全性
HTTP 本身是不安全的,因为传输的数据未经加密,可能会被窃听或篡改。为了解决这个问题,引入了 HTTPS(下一章节会详细说明),即在 HTTP 上加入 SSL/TLS 协议,为数据传输提供了加密和身份验证。
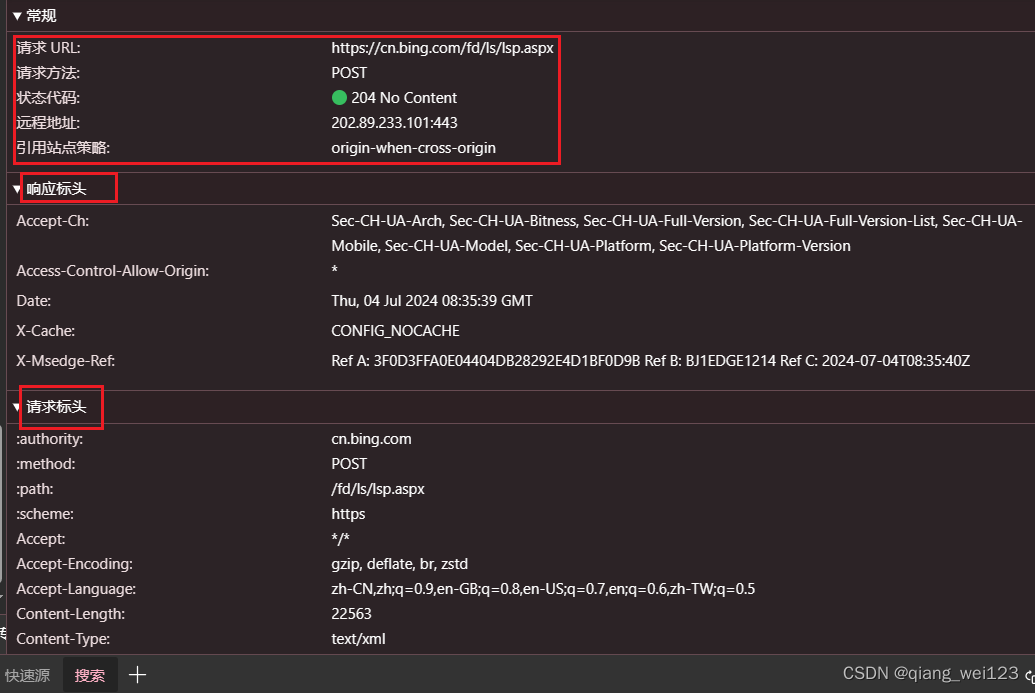
请求:
请求行->请求方式(get/post)请求url地址 协议
请求头->放一些服务器要使用的附加信息
请求体->放一些请求参数
响应:
状态行-> 协议 状态码
响应头-> 放一些客户端要使用的一些附加信息
响应体-> 服务器返回的真正客户端要使用的内容(HTML,json)等
在后面我们写爬虫的时候要格外注意请求头和响应头。这两个地方一般都隐含着一些比较重要的内容
请求头中最常见的一些重要内容(爬虫需要):
- User-Agent:请求载体的身份标识符(用啥发送的请求)
- Referer:防盗链(这次请求是从哪个页面发来的?反爬会用到)
- cookie:本地字符串数据信息(j用户登录信息,反爬虫的token
响应头中的一些重要信息:
- cookie:本地字符串数据信息(j用户登录信息,反爬虫的token
- 一般都是toten字样,防止各种攻击和反爬虫
请求头:
- GET:显示提交 -> 一般用于查询较多
- POST;隐式提交 -> 一般用户修改、增加等操作















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









