







scrapy爬虫框架简单Demo
github地址:https://github.com/lawlite19/PythonCrawler-Scrapy-Mysql-File-Template
使用scrapy爬虫框架将数据保存Mysql数据库和文件中
settings.py
- 修改Mysql的配置信息
#Mysql数据库的配置信息
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'testdb' #数据库名字,请修改
MYSQL_USER = 'root' #数据库账号,请修改
MYSQL_PASSWD = '123456' #数据库密码,请修改
MYSQL_PORT = 3306 #数据库端口,在dbhelper中使用- 指定pipelines
ITEM_PIPELINES = {
'webCrawler_scrapy.pipelines.WebcrawlerScrapyPipeline': 300,#保存到mysql数据库
'webCrawler_scrapy.pipelines.JsonWithEncodingPipeline': 300,#保存到文件中
}items.py
- 声明需要格式化处理的字段
class WebcrawlerScrapyItem(scrapy.Item):
'''定义需要格式化的内容(或是需要保存到数据库的字段)'''
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() #修改你所需要的字段
url = scrapy.Field()pipelines.py
一、保存到数据库的类WebcrawlerScrapyPipeline(在settings中声明)
- 定义一个类方法
from_settings,得到settings中的Mysql数据库配置信息,得到数据库连接池dbpool
@classmethod
def from_settings(cls,settings):
'''1、@classmethod声明一个类方法,而对于平常我们见到的则叫做实例方法。
2、类方法的第一个参数cls(class的缩写,指这个类本身),而实例方法的第一个参数是self,表示该类的一个实例
3、可以通过类来调用,就像C.f(),相当于java中的静态方法'''
dbparams=dict(
host=settings['MYSQL_HOST'],#读取settings中的配置
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8',#编码要加上,否则可能出现中文乱码问题
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=False,
)
dbpool=adbapi.ConnectionPool('MySQLdb',**dbparams)#**表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
return cls(dbpool)#相当于dbpool付给了这个类,self中可以得到__init__中会得到连接池dbpool
def __init__(self,dbpool):
self.dbpool=dbpoolprocess_item方法是pipeline默认调用的,进行数据库操作
#pipeline默认调用
def process_item(self, item, spider):
query=self.dbpool.runInteraction(self._conditional_insert,item)#调用插入的方法
query.addErrback(self._handle_error,item,spider)#调用异常处理方法
return item- 插入数据库方法
_conditional_insert
#写入数据库中
def _conditional_insert(self,tx,item):
#print item['name']
sql="insert into testpictures(name,url) values(%s,%s)"
params=(item["name"],item["url"])
tx.execute(sql,params)- 错误处理方法
_handle_error
#错误处理方法
def _handle_error(self, failue, item, spider):
print failue二、保存到文件中的类JsonWithEncodingPipeline(在settings中声明)
- 保存为json格式的文件,比较简单,代码如下
class JsonWithEncodingPipeline(object):
'''保存到文件中对应的class
1、在settings.py文件中配置
2、在自己实现的爬虫类中yield item,会自动执行'''
def __init__(self):
self.file = codecs.open('info.json', 'w', encoding='utf-8')#保存为json文件
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"#转为json的
self.file.write(line)#写入文件中
return item
def spider_closed(self, spider):#爬虫结束时关闭文件
self.file.close()dbhelper.py
- 自己实现的操作Mysql数据库的类
- init方法,获取settings配置文件中的信息
def __init__(self):
self.settings=get_project_settings() #获取settings配置,设置需要的信息
self.host=self.settings['MYSQL_HOST']
self.port=self.settings['MYSQL_PORT']
self.user=self.settings['MYSQL_USER']
self.passwd=self.settings['MYSQL_PASSWD']
self.db=self.settings['MYSQL_DBNAME']- 连接到Mysql
#连接到mysql,不是连接到具体的数据库
def connectMysql(self):
conn=MySQLdb.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
#db=self.db,不指定数据库名
charset='utf8') #要指定编码,否则中文可能乱码
return conn- 连接到settings配置文件中的数据库名(MYSQL_DBNAME)
#连接到具体的数据库(settings中设置的MYSQL_DBNAME)
def connectDatabase(self):
conn=MySQLdb.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset='utf8') #要指定编码,否则中文可能乱码
return conn - 创建数据库(settings文件中配置的数据库名)
#创建数据库
def createDatabase(self):
'''因为创建数据库直接修改settings中的配置MYSQL_DBNAME即可,所以就不要传sql语句了'''
conn=self.connectMysql()#连接数据库
sql="create database if not exists "+self.db
cur=conn.cursor()
cur.execute(sql)#执行sql语句
cur.close()
conn.close()- 还有一些数据库操作方法传入sql语句和参数即可(具体看代码)
实现具体的爬虫.py(即模板中的pictureSpider_demo.py文件)
- 继承
scrapy.spiders.Spider类 - 声明三个属性
name="webCrawler_scrapy" #定义爬虫名,要和settings中的BOT_NAME属性对应的值一致
allowed_domains=["desk.zol.com.cn"] #搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页
start_urls=["http://desk.zol.com.cn/fengjing/1920x1080/1.html"] #开始爬取的地址- 实现
parse方法,该函数名不能改变,因为Scrapy源码中默认callback函数的函数名就是parse
def parse(self, response):- 返回item
item=WebcrawlerScrapyItem() #实例item(具体定义的item类),将要保存的值放到事先声明的item属性中
item['name']=file_name
item['url']=realUrl
print item["name"],item["url"]
yield item #返回item,这时会自定解析item测试
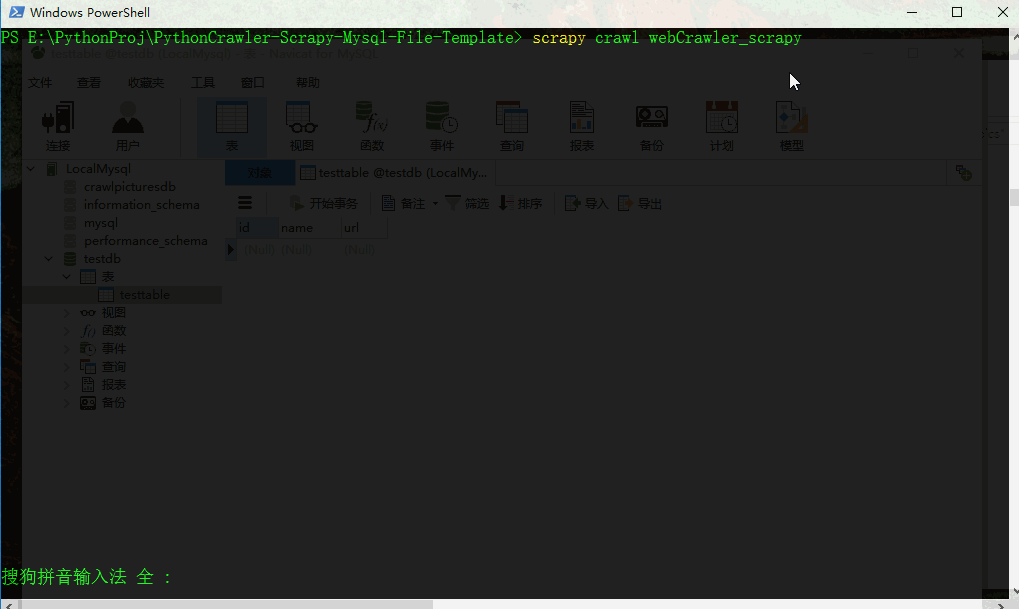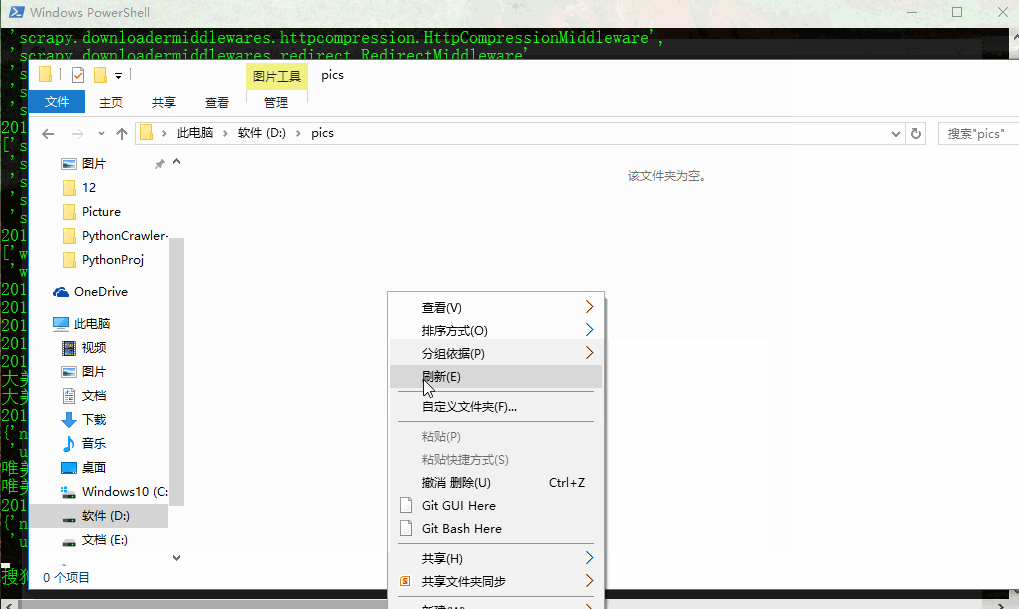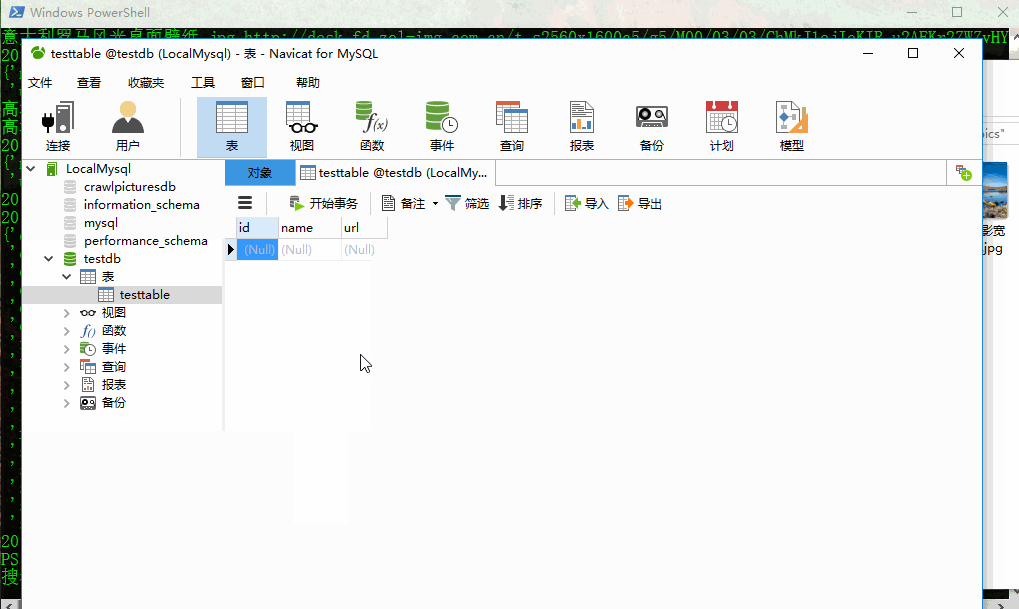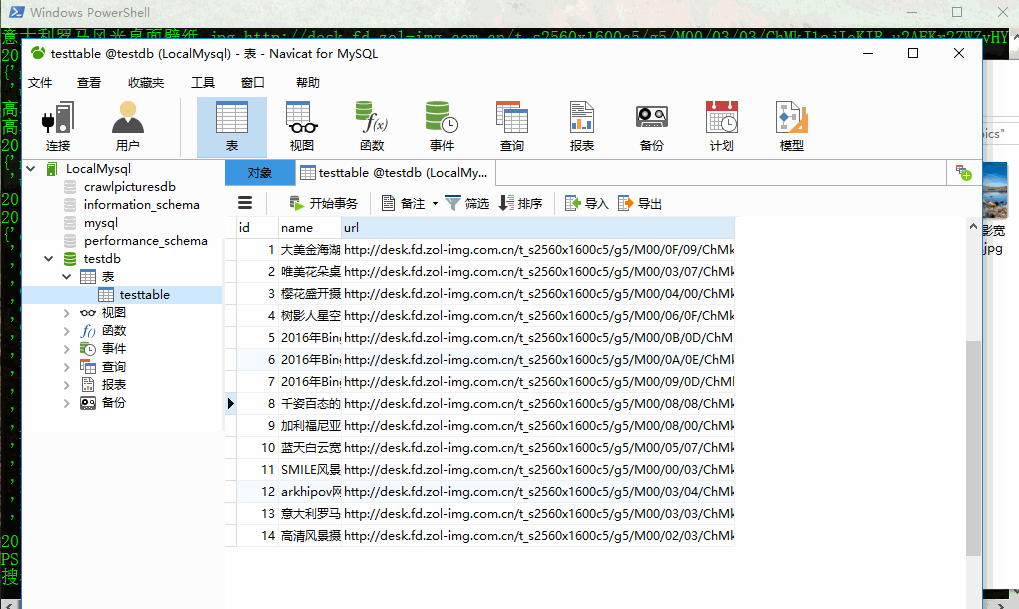
测试DBHelper
创建testdb数据库和testtable表- 测试爬虫
scrapy crawl webCrawler_scrapy运行爬虫后会将爬取得图片保存到本地,并且将name和url保存到数据库中
![![创建testdb数据库和testtable表][1]](https://img-blog.csdn.net/20160919215618717)














 8153
8153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









