






论文地址:https://arxiv.org/abs/2211.15518
代码地址:https://github.com/microsoft/ReCo
目录
Abstract:
Recently, large-scale text-to-image (T2I) models have shown impressive performance in generating high-fidelity images, but with limited controllability, e.g., precisely specifying the content in a specific region with a free-form text description. In this paper, we propose an effective technique for such regional control in T2I generation. We augment T2I models’ inputs with an extra set of position tokens, which represent the quantized spatial coordinates. Each region is specified by four position tokens to represent the top-left and bottom-right corners, followed by an open-ended natural language regional description. Then, we fine-tune a pre-trained T2I model with such new input interface. Our model, dubbed as ReCo (Region-Controlled T2I), enables the region control for arbitrary objects described by open-ended regional texts rather than by object labels from a constrained category set. Empirically, ReCo achieves better image quality than the T2I model strengthened by positional words (FID: 8.82 → 7.36, SceneFID: 15.54 → 6.51 on COCO), together with objects being more accurately placed, amounting to a 20.40% region classification accuracy improvement on COCO. Furthermore, we demonstrate that ReCo can better control the object count, spatial relationship, and region attributes such as color/size, with the free-form regional description. Human evaluation on PaintSkill shows that ReCo is +19.28% and +17.21% more accurate in generating images with correct object count and spatial relationship than the T2I model. Code is available at https://github.com/microsoft/Reeo.
最近,大规模文本到图像(T2I)模型展现出了令人印象深刻的性能,在生成高保真图像方面表现出色,但其可控性有限,例如,精确指定特定区域的内容,通过自由形式的文本描述。在本文中,我们提出了一种有效的技术,用于T2I生成中的区域控制。我们通过额外添加一组位置标记来增强T2I模型的输入,这些标记代表了量化的空间坐标。每个区域由四个位置标记来指定,分别表示左上角和右下角,然后是一个开放式的自然语言区域描述。然后,我们使用这种新的输入界面对预训练的T2I模型进行微调。我们的模型,命名为ReCo(区域控制T2I),使得通过开放式区域文本描述而不是受限的类别集合中的对象标签来控制任意对象的区域。根据经验,ReCo在图像质量上优于通过位置词强化的T2I模型(FID: 8.82 → 7.36,SceneFID: 15.54 → 6.51 on COCO),同时对象被更准确地放置,COO上的区域分类准确率提高了20.40%。此外,我们证明了ReCo可以更好地控制对象数量、空间关系和区域属性,如颜色/大小,通过自由形式的区域描述。在PaintSkill上的人类评估表明,ReCo在生成具有正确对象数量和空间关系的图像方面比T2I模型更准确,分别提高了+19.28%和+17.21%。代码可在https://github.com/microsoft/Reeo获取。
1、Introduction
Text-to-image (T2I) generation aims to generate faithful images based on an input text query that describes the image content. By scaling up the training data and model size, large T2I models [31], [34], [36], [45] have recently shown remarkable capabilities in generating high-fidelity images. However, the text-only query allows limited controllability, e.g., precisely specifying the content in a specific region. The naive way of using position-related text words, such as “top left” and “bottom right,” often results in ambiguous and verbose input queries, as shown in Figure 2 (a). Even worse, when the text query becomes long and complicated, or describes an unusual scene, T2I models [31], [45] might overlook certain details and rather follow the visual or linguistic training prior. These two factors together make region control difficult. To get the desired image, users usually need to try a large number of paraphrased queries and pick an image that best fits the desired scene. The process known as “prompt engineering” is time-consuming and often fails to produce the desired image.
文本到图像(T2I)生成旨在根据描述图像内容的输入文本查询生成忠实的图像。通过扩大训练数据和模型规模,最近出现的大型T2I模型[31]、[34]、[36]、[45]在生成高保真图像方面展现出了显著的能力。然而,仅使用文本查询的方式具有有限的可控性,例如,精确指定特定区域的内容。直接使用与位置相关的文本词汇,如“左上角”和“右下角”,往往会导致模糊而冗长的输入查询,如图2(a)所示。更糟糕的是,当文本查询变得又长又复杂,或描述一个不寻常的场景时,T2I模型[31]、[45]可能会忽略某些细节,而是遵循视觉或语言训练的先验。这两个因素共同使得区域控制变得困难。为了获得期望的图像,用户通常需要尝试大量的释义查询,并选择最适合所需场景的图像。这个过程被称为“提示工程”,耗时且通常无法产生期望的图像。

Figure 1. (a) Reco extends pre-trained text-to-image models (stable diffusion [34]) with an extra set of input position tokens (in dark blue color) that represent quantized spatial coordinates. Combining position and text tokens yields the region-controlled text input, which can specify an open-ended regional description precisely for any image region. (b) With the region-controlled text input, reco can better control the object count/relationship/size properties and improve the t2i semantic correctness. We empirically observe that position tokens are less likely to get overlooked than positional text words, especially when the input query is complicated or describes an unusual scene.
图1。(a)ReCo通过额外添加一组表示量化空间坐标的输入位置标记(深蓝色)扩展了预训练的文本到图像模型(Stable Diffusion[34])。结合位置和文本标记可以得到区域控制的文本输入,可以为任何图像区域精确指定一个开放式的区域描述。(b)通过区域控制的文本输入,ReCo可以更好地控制对象数量/关系/大小属性,并提高T2I语义的正确性。我们经验性地观察到,位置标记比位置文本词更不容易被忽视,特别是当输入查询复杂或描述一个不寻常的场景时。
The desired region-controlled T2I generation is closely related to the layout-to-image generation [7], [9], [22], [23], [34], [38], [44], [49]. As shown in Figure 2(b), layout-to-image models take all object bounding boxes with labels from a close set of object vocabulary [24] as inputs. Despite showing promise in region control, they can hardly understand free-form text inputs, nor the region-level combination of open-ended text descriptions and spatial positions. The two input conditions of text and box provide complementary referring capabilities. Instead of separately modeling them as in text-to-image and layout-to-image generations, we study “region-controlled T2I generation” that seamlessly combines these two input conditions. As shown in Figure 2 ©, the new input interface allows users to provide open-ended descriptions for arbitrary image regions, such as precisely placing a “brown glazed chocolate donut” in a specific area.
期望的区域控制T2I生成与布局到图像生成[7]、[9]、[22]、[23]、[34]、[38]、[44]、[49]密切相关。如图2(b)所示,布局到图像模型将所有带有标签的对象边界框从一个有限的对象词汇表[24]作为输入。尽管在区域控制方面表现出了前景,但它们很难理解自由形式的文本输入,也无法理解开放式文本描述和空间位置的区域级组合。文本和框的两种输入条件提供了互补的引用能力。我们不像文本到图像和布局到图像生成中分别对它们进行建模,而是研究“区域控制T2I生成”,无缝地结合了这两种输入条件。如图2©所示,新的输入界面允许用户为任意图像区域提供开放式描述,例如在特定区域精确放置一个“棕色的涂有巧克力的甜甜圈”。
To this end, we propose ReCo (Region-Controlled T2I) that extends pre-trained T2I models to understand spatial coordinate inputs. The core idea is to introduce an extra set of input position tokens to indicate the spatial positions. The image width/height is quantized uniformly into N b i n s N_{bins} Nbins. Then, any float-valued coordinate can be approximated and tokenized by the nearest bin. With an extra embedding matrix ( E P E_P EP), the position token can be mapped onto the same space as the text token. Instead of designing a text-only query with positional words “in the top red donut” as in Figure 2 (a), ReCo takes region-controlled text inputs “ < x 1 > , < y 1 > , < x 2 > , < y 2 > <x_{1}>,<y_{1}>,<x_{2}>,<y_{2}> <x1>,<y1>,<x2>,<y2> red donut,” where < x > , < y > <x>,<y> <x>,<y> are the position tokens followed by the corresponding free-form text description. We then fine-tune a pre-trained T2I model with E P E_P EP to generate the image from the extended input query. To best preserve the pre-trained T2I capability, ReCo training is designed to be similar to the T2I pre-training, i.e., introducing minimal extra model parameters ( E P E_P EP), jointly encoding position and text tokens with the text encoder, and prefixing the image description before the extended regional descriptions in the input query.
为此,我们提出了ReCo(区域控制T2I),将预训练的T2I模型扩展到理解空间坐标输入。其核心思想是引入一组额外的输入位置标记来指示空间位置。图像的宽度/高度均匀量化为 N b i n s N_{bins} Nbins。然后,任何浮点坐标都可以通过最近的箱近似和标记化。通过一个额外的嵌入矩阵( E P E_P EP),位置标记可以映射到与文本标记相同的空间上。与在图2(a)中设计仅包含位置词的文本查询不同,“在顶部的红色甜甜圈”,ReCo采用区域控制的文本输入“ < x 1 > , < y 1 > , < x 2 > , < y 2 > <x_{1}>,<y_{1}>,<x_{2}>,<y_{2}> <x1>,<y1>,<x2>,<y2>红色甜甜圈”,其中 < x > , < y > <x>,<y> <x>,<y>是位置标记,后跟相应的自由形式文本描述。然后,我们使用 E P E_P EP微调预训练的T2I模型,从扩展的输入查询生成图像。为了最大限度地保留预训练的T2I能力,ReCo训练被设计为与T2I预训练相似,即引入最少的额外模型参数( E P E_P EP),将位置和文本标记与文本编码器一起编码,并在输入查询中在扩展的区域描述之前加上图像描述前缀。
Figure 1 visualizes ReCo’s use cases and capabilities. As shown in Figure 1(a), ReCo could reliably follow the input spatial constraints and generate the most plausible images by automatically adjusting object statues, such as the view (front/side) and type (single-/double-deck) of the “bus.” Position tokens also allow the user to provide free-form regional descriptions, such as “an orange cat wearing a red hat” at a specific location. Furthermore, we empirically observe that position tokens are less likely to get overlooked or misunderstood than text words. As shown in Figure 1(b), ReCo has better control over object count, spatial relationship, and size properties, especially when the query is long and complicated, or describes a scene that is less common in real life. In contrast, T2I models [34] may struggle with generating scenes with correct object counts (“ten”), relationships (“boat below traffic light”), relative sizes (“chair larger than airplane”), and camera views (“zoomed out”).
图1展示了ReCo的用例和能力。如图1(a)所示,ReCo可以可靠地遵循输入的空间约束,并通过自动调整对象的状态(如“公交车”的视图(正面/侧面)和类型(单层/双层))生成最合理的图像。位置标记还允许用户提供自由形式的区域描述,例如在特定位置“一个戴着红帽子的橙色猫”。此外,我们经验性地观察到,位置标记比文本词更不容易被忽视或误解。如图1(b)所示,ReCo在对象数量、空间关系和大小属性方面具有更好的控制能力,特别是当查询是长而复杂的,或描述一个在现实生活中较少见的场景时。相比之下,T2I模型[34]可能会难以生成具有正确对象数量(“十个”)、关系(“船在红绿灯下”)、相对大小(“椅子比飞机大”)和摄像机视图(“拉远视角”)的场景。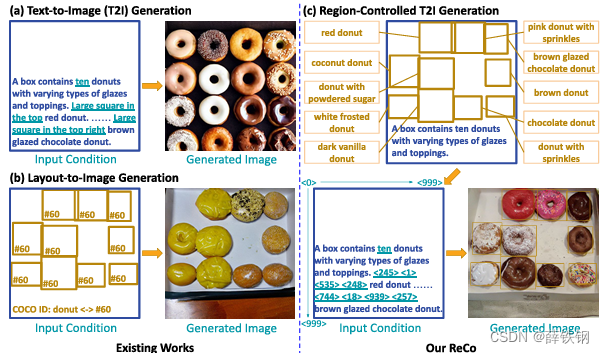
Figure 2. (a) With positional words (e.g., bottom/top/left/right and large/small/tall/long), the t2i model (stable diffusion [34]) does not manage to create objects with desired properties. (b) Layout-to-image generation [22], [34], [38], [49] takes all object boxes and labels as the input condition, but only works well with constrained object labels. © Our reco model synergetically combines the text and box referring, allowing users to specify an open-ended regional text description precisely at any image region.
图2。(a)使用位置词(例如,底部/顶部/左侧/右侧和大/小/高/长),T2I模型(Stable Diffusion[34])无法创建具有所需属性的对象。(b)布局到图像生成[22]、[34]、[38]、[49]将所有对象框和标签作为输入条件,但仅适用于受限的对象标签。(c)我们的ReCo模型协同地结合了文本和框引用,允许用户在任何图像区域精确指定一个开放式的区域文本描述。
To evaluate the region control, we design a comprehensive experiment benchmark based on a pre-trained regional object classifier and an object detector. The object classifier is applied on the generated image regions, while the detector is applied on the whole image. A higher accuracy means a better alignment between the generated object layout and the region positions in user queries. On the COCO dataset [24], ReCo shows a better object classification accuracy (42.02% → 62.42%) and detector averaged precision (2.3 → 32.0), compared with the T2I model with carefully designed positional words. For image generation quality, ReCo improves the FID from 8.82 to 7.36, and Scene-FID from 15.54 to 6.51. Furthermore, human evaluations on PaintSkill [5] show +19.28% and +17.21% accuracy gain in more correctly generating the query-described object count and spatial relationship, indicating ReCo’s capability in helping T2I models to generate challenging scenes.
为了评估区域控制,我们设计了一个基于预训练的区域对象分类器和对象检测器的综合实验基准。对象分类器应用于生成的图像区域,而检测器应用于整个图像。较高的准确性意味着生成的对象布局与用户查询中的区域位置之间的对齐更好。在COCO数据集[24]上,与精心设计的位置词的T2I模型相比,ReCo显示出更高的对象分类准确率(42.02% → 62.42%)和检测器平均精度(2.3 → 32.0)。对于图像生成质量,ReCo将FID从8.82提高到7.36,将Scene-FID从15.54提高到6.51。此外,对PaintSkill[5]的人类评估显示,在更准确地生成描述查询的对象数量和空间关系方面,ReCo的准确率提高了+19.28%和+17.21%,表明了ReCo在帮助T2I模型生成具有挑战性场景方面的能力。
Our contributions are summarized as follows.
1、We propose ReCo that extends pre-trained T2I models to understand coordinate inputs. Thanks to the introduced position tokens in the region-controlled input query, users can easily specify free-form regional descriptions in arbitrary image regions.
2、We instantiate ReCo based on Stable Diffusion. Extensive experiments show that ReCo strictly follows the regional instructions from the input query, and also generates higher-fidelity images.
3、We design a comprehensive evaluation benchmark to validate ReCo’s region-controlled T2I generation capability. ReCo significantly improves both the region control accuracy and the image generation quality over a wide range of datasets and designed prompts.
我们的贡献总结如下:
- 我们提出了ReCo,将预训练的T2I模型扩展到理解坐标输入。通过在区域控制输入查询中引入位置标记,用户可以轻松地在任意图像区域指定自由形式的区域描述。
- 我们基于Stable Diffusion实例化了ReCo。广泛的实验证明,ReCo严格遵循输入查询中的区域指令,并生成更高保真度的图像。
- 我们设计了一个全面的评估基准来验证ReCo的区域控制T2I生成能力。在各种数据集和设计的提示中,ReCo显著提高了区域控制的准确性和图像生成的质量。
2、Related Work
Text-to-image generation. Text-to-image (T2I) generation aims to generate a high-fidelity image based on an open-ended image description. Early studies adopt conditional GANs [33], [42], [46]–[48] for T2I generation. Recent studies have made tremendous advances by scaling up both the data and model size, based on either auto-regressive [10], [45] or diffusion-based models [31], [34], [36]. We build our study on top of the successful large-scale pre-trained T2I models, and explore how to better control the T2I generation by extending a pre-trained T2I model to understand position tokens.
文本到图像生成。 文本到图像(T2I)生成旨在基于开放式图像描述生成高保真度的图像。早期的研究采用条件GANs [33]、[42]、[46]–[48]进行T2I生成。最近的研究通过扩大数据和模型规模,在自回归[10]、[45]或扩散模型[31]、[34]的基础上取得了巨大进展。我们建立在成功的大规模预训练T2I模型之上,并探索如何通过扩展预训练的T2I模型以理解位置标记来更好地控制T2I生成。
Layout-to-image generation. Layout-to-image studies aim to generate an image from a complete layout, i.e., all bounding boxes and the paired object labels. Early studies [9], [22], [23], [38], [49] adopt GAN-based approaches by properly injecting the encoded layout as the input condition. Recent studies successfully apply the layout query as the input condition to the auto-regressive framework [10], [44] and diffusion models [7], [34]. Our study is related to the layout-to-image generation as both directions require the model to understand coordinate inputs. The major difference is that our design synergetically combines text and box to help T2I generation. Therefore, ReCo can take open-ended regional descriptions and benefit from large-scale T2I pre-training.
布局到图像生成。 布局到图像的研究旨在从完整的布局生成图像,即所有边界框和配对的对象标签。早期的研究[9]、[22]、[23]、[38]、[49]采用基于GAN的方法,通过适当地将编码的布局注入为输入条件。最近的研究成功地将布局查询作为自回归框架[10]、[44]和扩散模型[7]、[34]的输入条件。我们的研究与布局到图像生成相关,因为两个方向都要求模型理解坐标输入。主要区别在于,我们的设计协同地结合文本和框来帮助T2I生成。因此,ReCo可以采用开放式的区域描述,并从大规模的T2I预训练中受益。
Unifying open-ended text and localization conditions. Previous studies have explored unifying open-ended text descriptions with localization referring (box, mask, mouse trace) as the input generation condition. One modeling approach [8], [10], [14], [17], [20], [28], [33] is to separately encode the image description in T2I and the layout condition in layout-to-image, and trains a model to jointly condition on both input types. TRECS [19] takes mouse traces in the localized narratives dataset [29] to better ground open-ended text descriptions with a localized position. Other than taking layout as user-generated inputs, previous studies [16], [21] have also explored predicting layout from text to ease the T2I generation of complex scenes. Unlike the motivation of training another conditional generation model parallel to T2I and layout-to-image, we explore how to effectively extend pre-trained T2I models to understand region queries, leading to significantly better controllability and generation quality than training from scratch. In short, we position ReCo as an improvement for T2I by providing a more flexible input interface and alleviating controllability issues, e.g., being difficult to override data prior when generating unusual scenes, and overlooking words in complex queries.
统一开放式文本和定位条件。 先前的研究探索了将开放式文本描述与定位引用(框、掩码、鼠标轨迹)统一为输入生成条件的方法。一种建模方法[8]、[10]、[14]、[17]、[20]、[28]、[33]是分别对图像描述进行编码并在布局到图像中对布局条件进行训练,并训练模型同时考虑这两种输入类型。TRECS [19] 使用定位叙述数据集 [29] 中的鼠标轨迹来更好地将开放式文本描述与局部位置联系起来。除了将布局作为用户生成的输入外,先前的研究[16]、[21]还探索了从文本中预测布局以简化复杂场景的T2I生成。与训练另一个与T2I和布局到图像平行的条件生成模型的动机不同,我们探索如何有效地扩展预训练的T2I模型以理解区域查询,从而比从头开始训练获得更好的可控性和生成质量。简而言之,我们将ReCo定位为T2I的改进,提供了更灵活的输入接口,并缓解了可控性问题,例如在生成不寻常的场景时难以覆盖数据先验,以及在复杂查询中忽视单词。
3、Reco Model
Region-Controlled T2I Generation (ReCo) extends T2I models with the ability to understand coordinate inputs. The core idea is to design a unified input token vocabulary containing both text words and position tokens to allow accurate and open-ended regional control. By seamlessly mixing text and position tokens in the input query, ReCo obtains the best from the two worlds of text-to-image and layout-to-image, i.e., the abilities of free-form description and precise position control. In this section, we present our ReCo implementation based on the open-sourced Stable Diffusion (SD) [34]. We start with the SD preliminaries in Section 3.1 and introduce the core ReCo design in Section 3.2.
区域控制T2I生成(ReCo)通过扩展T2I模型的能力来理解坐标输入。其核心思想是设计一个统一的输入标记词汇,包含文本词和位置标记,以实现准确且开放式的区域控制。通过在输入查询中无缝混合文本和位置标记,ReCo充分利用了文本到图像和布局到图像两个世界的优势,即自由形式描述和精确位置控制的能力。在本节中,我们基于开源的Stable Diffusion[34]介绍了我们的ReCo实现。我们从SD的初步介绍开始(第3.1节),然后在第3.2节介绍核心ReCo设计。
3.1. Preliminaries
We take Stable Diffusion as an example to introduce the T2I model that ReCo is built upon. Stable Diffusion is developed upon the Latent Diffusion Model [34], and consists of an auto-encoder, a U-Net [35] for noise estimation, and a CLIP ViT-L/14 text encoder. For the auto-encoder, the encoder E \mathcal{E} E with a down-sampling factor of 8 encodes the image x into a latent representation z = E ( x ) z = \mathcal{E}(x) z=E(x) that the diffusion process operates on, and the decoder D \mathcal{D} D reconstructs the image x ^ = D ( z ) \hat{x}=\mathcal{D}(z) x^=D(z) from the latent z z z. U-Net [35] is conditioned on denoising timestep t t t and text condition τ θ ( y ( T ) ) \tau_{\theta}(y(T)) τθ(y(T)), where y ( T ) y(T) y(T) is the input text query with text tokens T T T and τ θ \tau_{\theta} τθ is the CLIP ViT-L/14 text encoder [30] that projects a sequence of tokenized texts into the sequence embedding.
我们以Stable Diffusion为例介绍ReCo构建的T2I模型。Stable Diffusion是基于Latent Diffusion Model[34]开发的,包括一个自动编码器、用于噪声估计的U-Net [35]和一个CLIP ViT-L/14文本编码器。对于自动编码器,具有8倍下采样因子的编码器 E \mathcal{E} E将图像 x x x编码成扩散过程操作的潜在表示 z = E ( x ) z = \mathcal{E}(x) z=E(x),解码器 D \mathcal{D} D从潜在 z z z重构图像 x ^ = D ( z ) \hat{x}=\mathcal{D}(z) x^=D(z)。U-Net [35]受到去噪时间步 t t t和文本条件 τ θ ( y ( T ) ) \tau_{\theta}(y(T)) τθ(y(T))的约束,其中 y ( T ) y(T) y(T)是具有文本标记 T T T的输入文本查询,而 τ θ \tau_{\theta} τθ是CLIP ViT-L/14文本编码器[30],将一系列标记化文本投影为序列嵌入。
The core motivation of ReCo is to explore more effective and interaction-friendly conditioning signals y y y, while best preserving the pre-trained T2I capability. Specifically, ReCo extends text tokens with an extra vocabulary specialized for spatial coordinate referring, i.e., position tokens P P P, which can be seamlessly used together with text tokens T T T in a single input query y y y. ReCo aims to show the benefit of synergetically combining text and position conditions for region-controlled T2I generation.
ReCo的核心动机是探索更有效和用户友好的条件信号 y y y,同时最大限度地保留预训练的T2I能力。具体而言,ReCo通过额外的专门用于空间坐标引用的词汇扩展文本标记,即位置标记 P P P,可以与文本标记 T T T一起无缝地在单个输入查询 y y y中使用。ReCo旨在展示通过协同地结合文本和位置条件来进行区域控制T2I生成的好处。
3.2. Region-Controlled T2I Generation
ReCo input sequence. The text input in T2I generation provides a natural way of specifying the generation condition. However, text words may be ambiguous and verbose in providing regional specifications. For a better input query, ReCo introduces position tokens that can directly refer to a spatial position. Specifically, the position and size of each region can be represented by four floating numbers, i.e., top-left and bottom-right coordinates. By quantizing coordinates [3], [41], [43], we can represent the region by four discrete position tokens P , < x 1 > , < y 1 > , < x 2 > , < y 2 > P, <x_{1}>,<y_{1}>,<x_{2}>,<y_{2}> P,<x1>,<y1>,<x2>,<y2>, arranged as a sequence similar to a short natural language sentence. The left side of Figure 3 illustrates the ReCo input sequence design. Same as T2I, we start the input query with the image description to make the best use of large-scale T2I pre-training. The image description is followed by multiple region-controlled texts, i.e., the four position tokens and the corresponding open-ended regional description. The number of regional specifications is unlimited, allowing users to easily create complex scenes with more regions, or save time on composing input queries with fewer or even no regions. ReCo introduces position token embedding E p ∈ R N b i n s × D E_{p}\in\mathbb{R}^{N_{bins}\times D} Ep∈RNbins×D alongside the pre-trained text word embedding, where N b i n s N_{bins} Nbins is the number of the position tokens, and D D D is the token embedding dimension. The entire sequence is then processed jointly, and each token, either text or spatial, is projected into a D−dim token embedding e e e. The pre-trained CLIP text encoder from Stable Diffusion takes the token embeddings in, and projects them as the sequence embedding that the diffusion model conditions on.
ReCo输入序列。 在T2I生成中,文本输入提供了一种自然的方式来指定生成条件。然而,文本词在提供区域规格时可能存在歧义和冗长。为了更好的输入查询,ReCo引入了位置标记,可以直接引用空间位置。具体而言,每个区域的位置和大小可以用四个浮点数表示,即左上角和右下角的坐标。通过量化坐标[3]、[41]、[43],我们可以用四个离散的位置标记
P
,
<
x
1
>
,
<
y
1
>
,
<
x
2
>
,
<
y
2
>
P, <x_{1}>,<y_{1}>,<x_{2}>,<y_{2}>
P,<x1>,<y1>,<x2>,<y2>来表示区域,这些标记排列成一个类似于短自然语言句子的序列。图3的左侧说明了ReCo输入序列设计。与T2I相同,我们从图像描述开始输入查询,以充分利用大规模T2I预训练。图像描述后跟多个区域控制文本,即四个位置标记和相应的开放式区域描述。区域规格的数量是无限的,允许用户轻松创建具有更多区域的复杂场景,或节省时间编写具有较少甚至没有区域的输入查询。ReCo引入了位置标记嵌入
E
p
∈
R
N
b
i
n
s
×
D
E_{p}\in\mathbb{R}^{N_{bins}\times D}
Ep∈RNbins×D与预训练的文本词嵌入一起,其中
N
b
i
n
s
N_{bins}
Nbins是位置标记的数量,
D
D
D是标记嵌入维度。然后,整个序列被联合处理,每个标记,无论是文本还是空间标记,都被投影到一个
D
D
D维的标记嵌入
e
e
e中。Stable Diffusion的预训练CLIP文本编码器接受标记嵌入,并将它们投影为扩散模型条件的序列嵌入。
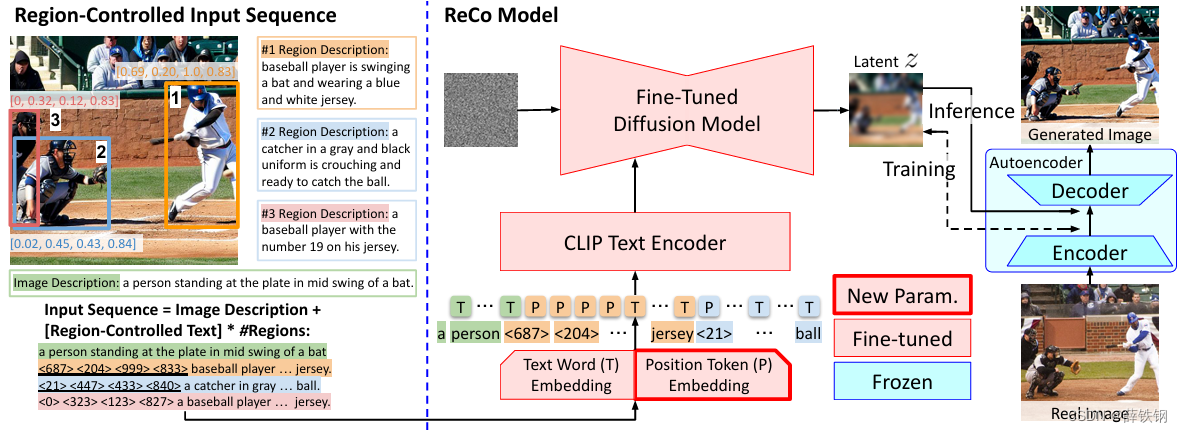
Figure 3. Reco extends Stable Diffusion [34] with position tokens P P P to support open-ended text description at both image- and region-level. We minimize the amount of introduced new model parameters (i.e., position token embedding E P E_P EP) to best preserve the pre-trained t2i capability. The diffusion model and text encoder are fine-tuned together to support the extended position token inputs.
图3。 Reco扩展了Stable Diffusion[34],使用位置标记 P P P来支持图像和区域级别的开放式文本描述。我们最小化引入的新模型参数的数量(即位置标记嵌入 E P E_P EP),以最好地保留预训练的T2I能力。扩散模型和文本编码器一起微调以支持扩展的位置标记输入。
ReCo fine-tuning. ReCo extends the text-only query y ( T ) y(T) y(T) with text tokens T T T into ReCo input query y ( P , T ) y(P,T) y(P,T) that combines the text word T T T and position token P P P. We fine-tune the Stable Diffusion with the same latent diffusion modeling objective [34], following the notations in Section 3.1:
L = E E ( x ) , y ( P , T ) , ∈ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t , τ θ ( y ( P , T ) ) ) ∥ 2 2 ] , \begin{equation*} L=\mathrm{E}_{\mathcal{E}(x),y(P,T),\in\sim \mathcal{N}(0,1),t}\left[\Vert\epsilon-\epsilon_{\theta}(z_{t},t,\tau_{\theta}(y(P,T)))\Vert_{2}^{2}\right], \end{equation*} L=EE(x),y(P,T),∈∼N(0,1),t[∥ϵ−ϵθ(zt,t,τθ(y(P,T)))∥22],
where ϵ θ \epsilon_{\theta} ϵθ and τ θ \tau_{\theta} τθ are the fine-tuned network modules. All model parameters except position token embedding E P E_P EP are initiated from the pre-trained Stable Diffusion model. Both the image description and several regional descriptions are required for ReCo model fine-tuning. For the training data, we run a state-of-the-part captioning model [40] on the cropped image regions (following the annotated bounding boxes) to get the regional descriptions. During fine-tuning, we resize the image with the short edge to 512 and randomly crop a square region as the input image x x x. We will release the generated data and fine-tuned model for reproduction.
ReCo微调。 ReCo将仅包含文本查询
y
(
T
)
y(T)
y(T)扩展为包含文本标记
T
T
T和位置标记
P
P
P的ReCo输入查询
y
(
P
,
T
)
y(P,T)
y(P,T)。我们对Stable Diffusion进行微调,使用相同的潜在扩散建模目标[34],遵循第3.1节中的符号:
L
=
E
E
(
x
)
,
y
(
P
,
T
)
,
∈
∼
N
(
0
,
1
)
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
,
τ
θ
(
y
(
P
,
T
)
)
)
∥
2
2
]
,
\begin{equation*} L=\mathrm{E}_{\mathcal{E}(x),y(P,T),\in\sim \mathcal{N}(0,1),t}\left[\Vert\epsilon-\epsilon_{\theta}(z_{t},t,\tau_{\theta}(y(P,T)))\Vert_{2}^{2}\right], \end{equation*}
L=EE(x),y(P,T),∈∼N(0,1),t[∥ϵ−ϵθ(zt,t,τθ(y(P,T)))∥22],
其中
ϵ
θ
\epsilon_{\theta}
ϵθ和
τ
θ
\tau_{\theta}
τθ是参与微调的网络模块。除了位置标记嵌入
E
P
E_P
EP之外,所有模型参数均从预训练的Stable Diffusion模型中初始化。对于ReCo模型的微调,需要图像描述以及几个区域描述。对于训练数据,我们运行一个最先进的图像描述模型[40],在按照标注的bounding boxes在图像上裁剪出相应的图像区域,并在图像区域上使用图像描述模型获得区域描述。在微调过程中,我们将图像的短边调整为512,并随机裁剪一个正方形区域作为输入图像
x
x
x。我们将发布生成的数据和微调后的模型以供再现。
We empirically observe that ReCo can well understand the introduced position tokens and precisely place objects at arbitrary specified regions. Furthermore, we find that position tokens can also help ReCo better model long input sequences that contain multiple detailed attribute descriptions, leading to fewer detailed descriptions being neglected or incorrectly generated than the text-only query. By introducing position tokens with a minimal change to the pre-trained T2I model, ReCo obtains the desired region controllability while best preserving the appealing T2I capability.
我们的实证观察表明,ReCo能够很好地理解引入的位置标记,并精确地将对象放置在任意指定的区域。此外,我们发现位置标记还可以帮助ReCo更好地对包含多个详细属性描述的长输入序列进行建模,从而比仅包含文本查询时忽略或错误生成更少的详细描述。通过引入位置标记对预训练的T2I模型进行最小变更,ReCo在最大程度地保留吸引人的T2I能力的同时,获得了所需的区域可控性。
4、Experiments
4.1. Experiment Settings
ReCo takes region-controlled inputs specified by the users. However, gathering sufficient real user queries paired with images for quantitative evaluations may be challenging. Therefore, in addition to the arbitrarily-shaped boxes from PaintSkill [5] and manually designed challenging queries in Figure 7, we also include in-domain boxes from COCO [4] and LVIS [11] to construct evaluation queries.
ReCo接受用户指定的区域控制输入。然而,收集足够的真实用户查询与图像配对进行定量评估可能具有挑战性。因此,除了来自PaintSkill [5]的任意形状框和图7中手动设计的具有挑战性的查询外,我们还包括来自COCO [4]和LVIS [11]的领域内框,以构建评估查询。
Datasets. We quantitatively evaluate ReCo on COCO [4], [24], PaintSkill [5], and LVIS [11]. For input queries, we take image descriptions and boxes from the datasets [5], [11], [24] and generate regional descriptions with GIT [40]. For COCO [4], [24], we follow the established T2I setting [32], [41], [45] that reports the results on a subset of 30,000 captions sampled from the COCO 2014 val set. We fine-tune stable diffusion with image-text pairs from the COCO 2014 train set. PaintSkill [5] evaluates models’ capabilities on following arbitrarily-shaped boxes and generating images with the correct object type/count/relationship. We conduct the T2I inference with val set prompts, which contain 1,050/2,520/3,528 queries for object recognition, counting, and spatial relationship skills, respectively. LVIS [11] tests if the model understands open-vocabulary regional descriptions, with the object categories unseen in COCO fine-tuning. We report the results on the 4,809 LVIS val images [11] from the COCO 2017 val set [18], [49]. We do not fine-tune ReCo when experimenting on PaintSkill and LVIS to test its generalization capability with out-of-domain data.
数据集。 我们在COCO [4]、[24]、PaintSkill [5]和LVIS [11]上对ReCo进行定量评估。对于输入查询,我们从数据集[5]、[11]、[24]中获取图像描述和边界框,并使用GIT [40]生成区域描述。对于COCO [4]、[24],我们遵循已建立的T2I设置[32]、[41]、[45],报告了从COCO 2014验证集中随机抽样的30,000个标题的结果。我们使用COCO 2014训练集中的图像-文本对对Stable Diffusion进行微调。PaintSkill [5]评估模型对以下任意形状框的能力,并生成具有正确对象类型/数量/关系的图像。我们使用val集提示进行T2I推理,其中包含1,050/2,520/3,528个用于对象识别、计数和空间关系技能的查询。LVIS [11]测试模型是否理解开放词汇的区域描述,其中包括COCO微调中未见的对象类别。我们报告了来自COCO 2017验证集 [18]、[49]的4,809张LVIS验证图像[11]的结果。在进行PaintSkill和LVIS的实验时,我们不对ReCo进行微调,以测试其对跨领域数据的泛化能力。

Figure 4. Qualitative results on coco [24]. Reco’s extra regional control (shown in the dark blue color) can improve t2i generation on (a) object counting and relationships, (b) images with unique camera views, and © images with detailed regional attribute descriptions.
图4。 COCO [24]上的定性结果。ReCo的额外区域控制(以深蓝色显示)可以改善T2I生成,包括(a)对象计数和关系,(b)具有独特相机视角的图像,以及(c)具有详细区域属性描述的图像。
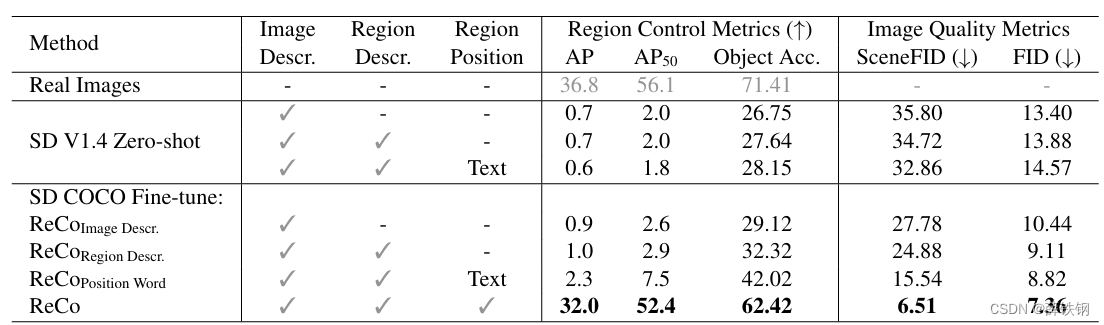
Table 1. Region control accuracy and image generation quality evaluations on the coco (2014) 30k validation subset [24], [32], [41], [45].
表1。 在COCO(2014)30k验证子集[24]上的区域控制准确性和图像生成质量评估[32],[41],[45]。
Evaluation metrics. We evaluate ReCo with metrics on region control accuracy and image generation quality. For region control accuracy, we use Object Classification Accuracy [49] and DETR detector Average Precision (AP) [2]. Object accuracy trains a classifier with queried image crops to classify cropped regions on generated images. The generation model should generate objects in specified regions to obtain a high classification accuracy. DETR detector AP detects objects on generated images and compares the results with input object queries. Thus, higher accuracy and AP can indicate a better layout alignment. For image generation quality, we use the Fréchet Inception Distance (FID) [13] to evaluate the image quality. We take SceneFID [39] as an indicator for region-level visual quality, which computes FID on the regions cropped based on input object boxes. We compute FID and SceneFID with the Clean-FID repo [27] against center-cropped COCO images. We further conduct human evaluations on PaintSkill, due to the lack of GT images and effective automatic evaluation metrics.
评估指标。 我们使用区域控制准确性和图像生成质量的指标来评估ReCo。对于区域控制准确性,我们使用对象分类准确率[49]和DETR检测器的平均精度(AP)[2]。对象准确度训练一个分类器,使用查询的图像裁剪来对生成的图像上的裁剪区域进行分类。生成模型应该在指定的区域生成对象以获得高分类准确度。DETR检测器AP在生成的图像上检测对象,并将结果与输入对象查询进行比较。因此,更高的准确度和AP可以指示更好的布局对齐。对于图像生成质量,我们使用Fréchet Inception Distance(FID)[13]来评估图像质量。我们将SceneFID [39]作为区域级视觉质量的指标,它基于输入对象框裁剪的区域计算FID。我们使用Clean-FID仓库[27]对中心裁剪的COCO图像计算FID和SceneFID。由于缺乏GT图像和有效的自动评估指标,我们进一步在PaintSkill上进行人工评估。
Implementation details. We fine-tune ReCo from the Stable Diffusion v1.4 checkpoint. We introduce N = 1000 N=1000 N=1000 position tokens and increase the max length of the text encoder to 616. The batch size is 2048. We use AdamW optimizer [26] with a constant learning rate of 1 e − 4 1e^{-4} 1e−4 to train the model for 20,000 steps, equivalent to around 100 epochs on COCO 2014 train set. The inference is conducted with 50 PLMS steps [25]. We select a classifier-free guidance scale [15] that gives the best region control performance, i.e., 4.0 for ReCo and 7.5 for original Stable Diffusion, detailed in Section 4.3. We do not use CLIP image re-ranking.
实现细节。 我们从Stable Diffusion v1.4 checkpoint微调ReCo。我们引入了 N = 1000 N=1000 N=1000个位置标记,并将文本编码器的最大长度增加到616。批量大小为2048。我们使用AdamW优化器[26],学习率为 1 e − 4 1e^{-4} 1e−4,在COCO 2014训练集上训练模型20,000步,相当于大约100个epoch。推理过程中使用50个PLMS步骤[25]。我们选择一个无分类器的指导尺度[15],以获得最佳的区域控制性能,即对于ReCo为4.0,对于原始的Stable Diffusion为7.5,详见第4.3节。我们不使用CLIP图像重新排序。
4.2. Region-Controlled T2I Generation Results
COCO. Table 1 reports the region-controlled T2I generation results on COCO. The first row “real images” provides an oracle reference number on applicable metrics. The top part of the table shows the results obtained with the pre-trained Stable Diffusion (SD) model without fine-tuning on COCO, i.e., the zero-shot setting. As shown in the left three columns, we experiment with adding “region description” and “region position” information to the input query in addition to “image description.” Since T2I models can not understand coordinates, we carefully design positional text descriptions, indicated by “text” in the “region position” column. Specifically, we describe a region with one of the three size words (small, medium, large), three possible region aspect ratios (long, square, tall), and nine possible locations (top left, top,…, bottom right). We note that the resulting R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word serves as a strengthened T2I baseline for reference purposes, and it is unfair to directly compare it with ReCo that understands coordinates. The bottom part compares the main ReCo model with other variants fine-tuned with the corresponding input queries. The middle three rows report the results on region control accuracy. For AP and AP50, we use a DETR ResNet-50 object detector trained on COCO [1], [2] to get the detection results on images generated based on the input texts and boxes from the COCO 2017 val5k set [24]. The “object accuracy” column reports the region classification accuracy [49]. The trained ResNet-101 region classifier [12] yields a 71.41% oracle 80-class accuracy on real images. The right two columns report the image generation quality metrics SceneFID a nd FID, which evaluate the region and image visual qualities.
COCO. 表1报告了COCO上的区域控制T2I生成结果。第一行“真实图像”提供了适用指标的Oracle参考数字。表的上部分显示了在COCO上未进行微调的预训练Stable Diffusion(SD)模型的结果,即零-shot设置。如左三列所示,我们尝试在输入查询中添加“区域描述”和“区域位置”信息,以及“图像描述”。由于T2I模型无法理解坐标,我们仔细设计了位置文本描述,由“文本”列中的“区域位置”表示。具体来说,我们使用三个大小词(小、中、大)、三种可能的区域长宽比(长方形、正方形、高)、以及九种可能的位置(左上、上…、右下)来描述区域。我们注意到,由此产生的 R e C o P o s i t i o n ReCo_{Position} ReCoPosition单词作为了加强型T2I基线,供参考,不公平地将其与理解坐标的ReCo直接进行比较。底部部分比较了主要的ReCo模型与其他经过相应输入查询微调的变体。中间的三行报告了区域控制准确性的结果。对于AP和AP50,我们使用在COCO [1],[2]上训练的DETR ResNet-50对象检测器获得了基于COCO 2017 val5k集[24]中的输入文本和框的图像的检测结果。“对象准确度”列报告了区域分类准确率[49]。经过训练的ResNet-101区域分类器[12]在真实图像上获得了71.41%的Oracle 80类准确率。右边两列报告了图像生成质量指标SceneFID和FID,评估了区域和图像的视觉质量。

Figure 5. Qualitative results on paintskill [5]. Reco’s extra regional control (shown in the dark blue color) can help t2i models more reliably generate scenes with exact object counts and unusual object relationships/relative sizes.
图5。 PaintSkill [5]上的定性结果。ReCo的额外区域控制(以深蓝色显示)可以帮助T2I模型更可靠地生成具有精确对象计数和不寻常对象关系/相对大小的场景。
One advantage of ReCo is its strong region control capability. As shown in the bottom row, ReCo achieves an AP of 32.0, which is close to the real image oracle of 36.8. Despite the careful engineering of positional text words, R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word only achieves an AP of 2.3. Similarly, for object region classification, 62.42% of the cropped regions on ReCo-generated images can be correctly classified, compared with 42.02% of R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word. ReCo also improves the generated image quality, both at the region and image level. At the region level, ReCo achieves a SceneFID of 6.51, indicating strong capabilities in both generating high-fidelity objects and precisely placing them in the queried position. At the image level, ReCo improves the FID from 10.44 to 7.36 with the region-controlled text input that provides a localized and more detailed image description. We present additional FID comparisons to state-of-the-art conditional image generation methods in Table 5©.
ReCo的一个优势是其强大的区域控制能力。如底部所示,ReCo实现了32.0的AP,接近真实图像的36.8。尽管对位置文本词进行了精心设计,但 R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word只能实现2.3的AP。类似地,对于对象区域分类,ReCo生成的图像上62.42%的裁剪区域可以被正确分类,而 R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word只有42.02%。ReCo还提高了生成图像的质量,无论是在区域还是在图像级别。在区域级别,ReCo实现了6.51的SceneFID,表明其在生成高保真对象并将其精确放置在查询位置方面具有强大的能力。在图像级别,ReCo通过提供定位更精细的图像描述,将FID从10.44提高到7.36。我们在表5©中对与最先进的有条件图像生成方法的FID进行了进一步的比较。
We show representative qualitative results in Figure 4. (a) ReCo can more reliably generate images that involve counting or complex object relationships, e.g., “five birds” and “sitting on a bench.” (b) ReCo can more easily generate images with unique camera views by controlling the relative position and size of object boxes, e.g., “a top-down view of a cat” that T2I models struggle with. © Separating detailed regional descriptions with position tokens also helps ReCo better understand long queries and reduce attribute leakage, e.g., the color of the clock and person’s shirt.
我们在图4中展示了代表性的定性结果。(a) ReCo可以更可靠地生成涉及计数或复杂对象关系的图像,例如,“五只鸟”和“坐在长凳上”。(b) 通过控制对象框的相对位置和大小,ReCo可以更轻松地生成具有独特摄像机视角的图像,例如,T2I模型难以处理的“俯视一只猫”。© 使用位置标记分离详细的区域描述还有助于ReCo更好地理解长查询并减少属性泄漏,例如,时钟的颜色和人的衬衫。
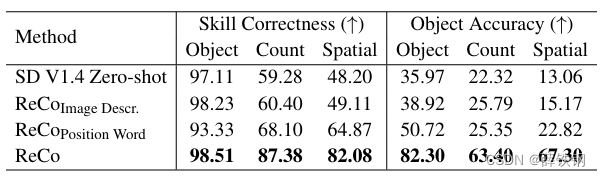
Table 2. Evaluations on the images generated with paintskill [5] prompts. We evaluate skill correctness with human judges, and object classification accuracy with the COCO-trained classifier.
表 2。 对使用 paintskill [5] 提示生成的图像进行的评估。我们使用人类来评估技能的正确性,并使用 COCO 训练的分类器来评估对象分类的准确性。
PaintSkill. Table 2 shows the skill correctness and region control accuracy evaluations on PaintSkill[5]. Skill correctness [5] evaluates if the generated images contain the query-described object type/count/relationship, i.e., the “object,” “count,” and “spatial” subsets. We use human judges to obtain the skill correctness accuracy. For region control, we use object classification accuracy to evaluate if the model follows those arbitrarily shaped and located object queries. We reuse the COCO region classifier introduced in Table 1.
PaintSkill。表2显示了对PaintSkill[5]上生成的图像的技能正确性和区域控制准确性的评估结果。技能正确性[5]评估生成的图像是否包含了查询描述的对象类型/数量/关系,即“对象”、“计数”和“空间”子集。我们使用人类评审员来获取技能正确性的准确度。对于区域控制,我们使用对象分类准确度来评估模型是否遵循了那些任意形状和位置的对象查询。我们重复使用了表1中介绍的COCO区域分类器。
Based on the human evaluation for “skill correctness,” 87.38% and 82.08% of ReCo-generated images have the correct object count and spatial relationship (“count” and “spatial”), which is +19.28% and +17.21% more accurate than R e C o P o s i t i o n ReCo_{Position} ReCoPosition Word, and +26.98% and +32.97% higher than the T2I model with image description only. The skill correctness improvements suggest that region-control text inputs could be an effective interface to help T2I models more reliably generate user-specified scenes. The object accuracy evaluation makes the criteria more strict by requiring the model to follow the exact input region positions, in addition to skills. “ReCo” achieves a strong region control accuracy of 63.40% and 67.30% on count and skill subsets, surpassing “ R e C o P o s i t i o n W o r d ReCo_{Position~Word} ReCoPosition Word” by +38.05% and +44.48%.
根据对“技能正确性”的人类评估,87.38%和82.08%的ReCo生成图像具有正确的对象计数和空间关系(“计数”和“空间”),比
R
e
C
o
P
o
s
i
t
i
o
n
ReCo_{Position}
ReCoPosition Word分别高出+19.28%和+17.21%,比仅具有图像描述的T2I模型高出+26.98%和+32.97%。技能正确性的改善表明,区域控制文本输入可能是一种有效的界面,可以帮助T2I模型更可靠地生成用户指定的场景。对象准确度评估通过要求模型遵循精确的输入区域位置,进一步提高了评判标准,除了技能外。ReCo在计数和技能子集上实现了强大的区域控制准确度,分别为63.40%和67.30%,比
R
e
C
o
P
o
s
i
t
i
o
n
W
o
r
d
ReCo_{Position~Word}
ReCoPosition Word高出+38.05%和+44.48%。
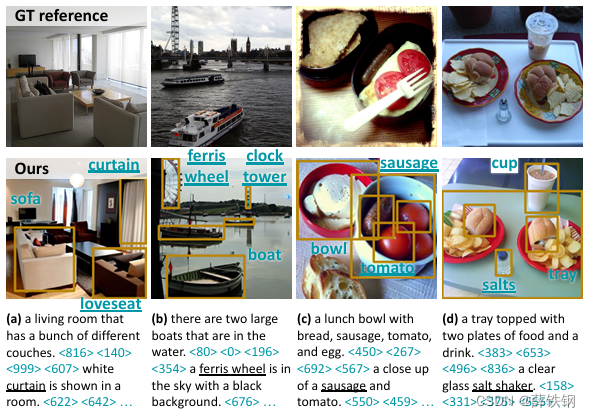
Figure 6. Qualitative results on lvis [11]. Reco can understand open-vocabulary regional descriptions, including keywords such as “curtain,” “ferris wheel,” “sausage,” and “salt shaker.”
图 6。 lvis 的定性结果[11]。Reco 可以理解开放词汇的区域描述,包括 “窗帘”、“摩天轮”、“香肠 ”和 “盐瓶 ”等关键词。
PaintSkill contains input queries with randomly assigned object types, locations, and shapes. Because of the minimal constraints, many queries describe challenging scenes that appear less frequently in real life. We observe that ReCo not only precisely follows position queries, but also fits objects and their surroundings naturally, indicating an understanding of object properties. In Figure 5(a), the three buses with different aspect ratios each have their unique viewing angle and direction, such that the object “bus” fits tightly with the given region. More interestingly, the directions of each bus go nicely with the road, making the image look real to humans. Figure 5(b) shows challenging cases that require drawing two less commonly co-occurred objects into the same image. ReCo correctly fits “bed” and “fire hydrant,” “boat” and “bus” into the given region. More impressively, ReCo can create a scene that makes the generated image look plausible, e.g., “looking through a window with a bed indoors,” with the commonsense knowledge that “bed” is usually indoor while “fire hydrant” is usually outdoor. The randomly assigned region categories can also lead to objects with unusual relative sizes, e.g., the bag that is larger than the airplane in Figure 5©. ReCo shows an understanding of image perspectives by placing smaller objects such as “backpack” and “dog” near the camera position.
PaintSkill包含了随机分配的物体类型、位置和形状的输入查询。由于约束条件较少,许多查询描述的是在现实生活中出现频率较低的具有挑战性的场景。我们观察到ReCo不仅精确地遵循位置查询,而且自然地适应物体及其周围环境,表明其对物体属性有一定的理解。在图5(a)中,具有不同长宽比的三辆公共汽车各自具有独特的观察角度和方向,使得“公共汽车”对象与给定区域紧密相连。更有趣的是,每辆公共汽车的方向与道路相配,使得图像看起来更真实。图5(b)展示了需要将两个不常共现的物体绘制到同一图像中的具有挑战性的情况。ReCo将“床”和“消防栓”、“船”和“公共汽车”正确放置在给定区域。更令人印象深刻的是,ReCo可以创建一个场景,使生成的图像看起来很合理,例如,“透过窗户看室内的床”,这是因为“床”通常在室内而“消防栓”通常在室外。随机分配的区域类别也可能导致具有不寻常相对大小的物体,例如图5©中大于飞机的包。ReCo通过将较小的物体(如“背包”和“狗”)放置在相机位置附近展现了对图像视角的理解。
LVIS. Table 3 reports the T2I generation results with out-of-vocabulary regional entities. We observe that ReCo can understand open-vocabulary regional descriptions, by transferring the open-vocab capability learned from large-scale T2I pre-training to regional descriptions. ReCo achieves the best SceneFID and object classification accuracy over the 1,203 LVIS classes of 10.08 and 23.42%. The results show that the ReCo position tokens can be used with open-vocabulary regional descriptions, despite being trained on COCO with 80 object types. Figure 6 shows examples of generating objects that are not annotated in COCO, e.g., “curtain” and “loveseat” in (a), “ferris wheel” and “clock tower” in (b), “sausage” and “tomato” in ( c), “salts” in (d).
LVIS. 表3报告了具有超出词汇表范围的区域实体的T2I生成结果。我们观察到,ReCo能够理解开放式词汇的区域描述,通过将从大规模T2I预训练中学到的开放式词汇能力转移到区域描述上。ReCo在1,203个LVIS类别上实现了最佳的SceneFID和对象分类准确率,分别为10.08和23.42%。结果表明,尽管是在COCO的80种对象类型上训练的,但ReCo位置标记可以与开放式词汇的区域描述一起使用。图6显示了在COCO中未标注的对象的生成示例,例如(a)中的“窗帘”和“小型沙发”,(b)中的“摩天轮”和“钟楼”,( c)中的“香肠”和“番茄”,(d)中的“盐”。
Qualitative results. We next qualitatively show ReCo’s other capabilities with manually designed input queries. Figure 1(a) shows examples of arbitrary object manipulation and regional description control. As shown in the “bus” example, ReCo will automatically adjust the object viewing (from side to front) and type (from single- to double-deck) to reasonably fit the region constraint, indicating the knowledge about object “bus.” ReCo can also understand the free-form regional text and generate “cats” in the specified region with different attributes, e.g., “wearing a red hat,” “pink,” “sleeping,” etc. Figure 7 (a) shows an example of generating images with different object counts. ReCo’s region control provides a strong tool for generating the exact object count, optionally with extra regional texts describing each object. Figure 7 (b) shows how we can use the box size to control the camera view, e.g., the precise control of the exact zoom-in ratio. Figure 7 © presents additional examples of images with unusual object relationships.
定性结果。 接下来我们通过手动设计的输入查询定性展示ReCo的其他能力。图1(a)展示了任意对象操作和区域描述控制的示例。如“公共汽车”示例所示,ReCo将自动调整对象的视角(从侧面到正面)和类型(从单层到双层),以合理地适应区域约束,表明了对对象“公共汽车”的了解。ReCo还可以理解自由形式的区域文本,并在指定的区域生成具有不同属性的“猫”,例如“戴着红帽子”,“粉红色”,“睡觉”等。 图7(a)显示了生成具有不同物体计数的图像的示例。ReCo的区域控制为生成精确的物体计数提供了一个强大的工具,可选择性地使用额外的区域文本描述每个物体。图7(b)展示了如何使用框大小来控制相机视图,例如对精确缩放比例的精确控制。 图7©展示了具有不寻常对象关系的图像的其他示例。
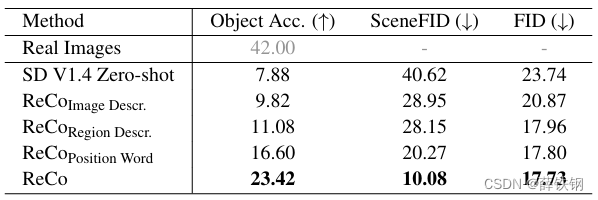
Table 3. Evaluations on the images generated with the 4,809 lvis validation samples [11] from coco val2017. The object classification is conducted over the 1,203 lvis classes.
表3。 对使用来自coco val2017的4,809个lvis验证样本[11]生成的图像进行的评估。物体分类是在1,203个lvis类别上进行的。
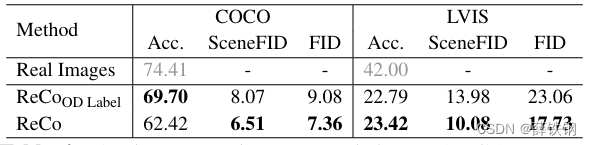
Table 4. Analyses on using open-ended texts (ReCo) vs. constrained object labels (ReCoOD Label) as the regional description.
表4。对使用开放式文本(ReCo)与受限物体标签(ReCoOD标签)作为区域描述进行的分析。
4.3. Analysis
Regional descriptions. Alternative to the open-ended free-form texts, regional descriptions can be object indexes from a constrained category set, as the setup in layout-to-image generation [9], [22], [23], [38], [49]. Table 4 compares ReCo with R e C o L a b e l ReCo_{Label} ReCoLabel on COCO [24] and LVIS [11]. The leftmost “accuracy” column on COCO shows the major advantage of R e C o L a b e l ReCo_{Label} ReCoLabel, i.e., when fine-tuned and tested with the same regional object vocabulary, R e C o L a b e l ReCo_{Label} ReCoLabel is +7.28% higher in region control accuracy, compared with ReCo. However, the closed-vocabulary OD labels bring two disadvantages. First, the position tokens in R e C o L a b e l ReCo_{Label} ReCoLabel tend to only work with the seen vocabulary, i.e., the 80 COCO categories. When evaluated on other datasets such as LVIS or open-world use cases, the region control performance drops significantly, as shown in the “accuracy” column on LVIS. Second, R e C o L a b e l ReCo_{Label} ReCoLabel only works well with constrained object labels, which fail to provide detailed regional descriptions, such as attributes and object relationships. Therefore, R e C o L a b e l ReCo_{Label} ReCoLabel helps less in generating high-fidelity images, with FID 1.72 and 5.33 worse than ReCo on COCO and LVIS. Given the aforementioned limitations, we use the open-ended free-form regional descriptions in ReCo.
区域描述。 与开放式自由文本相比,区域描述可以是来自受限类别集的对象索引,就像布局到图像生成中的设置一样。表4将ReCo与 R e C o L a b e l ReCo_{Label} ReCoLabel在COCO [24]和LVIS [11]上进行了比较。在COCO上的最左侧的“准确性”列显示了 R e C o L a b e l ReCo_{Label} ReCoLabel的主要优势,即在与相同的区域对象词汇进行微调和测试时, R e C o L a b e l ReCo_{Label} ReCoLabel的区域控制准确度比ReCo高出7.28%。然而,封闭的OD标签带来了两个缺点。首先, R e C o L a b e l ReCo_{Label} ReCoLabel中的位置标记往往只适用于已知的词汇,即80个COCO类别。当在其他数据集(如LVIS)或开放世界的用例中进行评估时,区域控制性能会显著下降,如LVIS上的“准确性”列所示。其次, R e C o L a b e l ReCo_{Label} ReCoLabel只能与受限的对象标签一起使用,无法提供详细的区域描述,如属性和对象关系。因此,在生成高保真图像方面, R e C o L a b e l ReCo_{Label} ReCoLabel的帮助较小,其FID分别比COCO和LVIS上的ReCo差1.72和5.33。鉴于上述限制,我们在ReCo中使用开放式自由形式的区域描述。

Figure 7. Qualitative results of reco-generated images with manually designed challenging input queries.
图 7。 使用人工设计的高难度输入查询重新生成图像的定性结果。
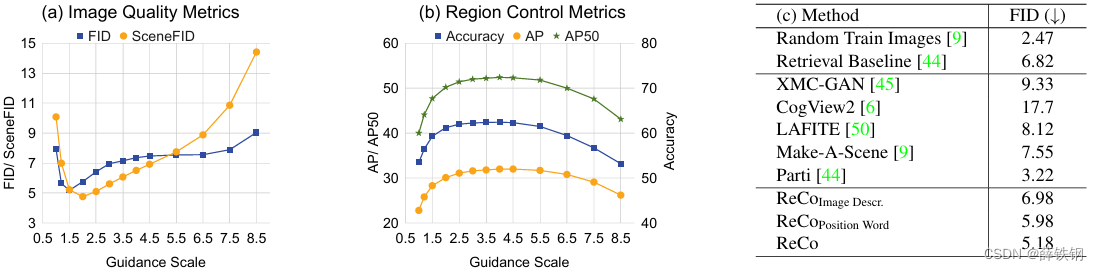
Table 5. (a,b) Analyses of different guidance scales’ influences [15] on image quality and region control accuracy. © Comparison with previous T2I works on the COCO (2014) validation 30k subset [24], [32], [41], [45]) in the fine-tuned setting.
表 5。 (a、b)不同引导尺度[15]对图像质量和区域控制精度的影响分析。© 与之前在 COCO(2014 年)验证 30k 子集[24]、[32]、[41]、[45]]上进行微调设置的 T2I 工作进行比较。
Guidance scale and T2I SOTA comparison. Table 5(a,b) examines how different classifier-free guidance scales [15] influence region control accuracy and image generation quality on the COCO 2014 val subset [24], [32], [41], [45]. We empirically observe that scale of 1.5 yields the best image quality, and a slightly larger scale of 4.0 provides the best region control performance. Table 5© compares ReCo with the state-of-the-art T2I methods in the fine-tuned setting. We reduce the guidance scale from the 4.0 in Table 1 to 1.5 for a fair comparison. We do not use any image-text contrastive models for results re-ranking. ReCo achieves an FID of 5.18, compared with 6.98 when we fine-tune Stable Diffusion with COCO T2I data without regional description. ReCo also outperforms the real image retrieval baseline [45] and most prior studies [6], [10], [46], [50].
指导尺度和T2I SOTA比较。 表5(a,b)研究了不同的无分类器引导尺度 [15] 如何影响COCO 2014验证子集 [24], [32], [41], [45] 上的区域控制准确度和图像生成质量。我们经验性地观察到,尺度为1.5提供了最佳的图像质量,稍大一些的尺度4.0提供了最佳的区域控制性能。表5©将ReCo与经过微调的最新T2I方法进行了比较。为了公平比较,我们将指导尺度从表1中的4.0减小到1.5。我们没有使用任何图像文本对比模型进行结果重新排序。与使用COCO T2I数据对Stable Diffusion进行微调但没有区域描述的情况相比,ReCo的FID为5.18。ReCo还优于实际图像检索基线[45]和大多数先前的研究[6], [10], [46], [50]。
Limitations. Our method has several limitations. First, ReCo might generate lower-quality images when the input query becomes too challenging, e.g., the unusual giant “dog” in Figure 7©. Second, for evaluation purposes, we train ReCo on the COCO train set. Despite preserving the open-vocabulary capability shown on LVIS, the generated image style does bias towards COCO. This limitation can potentially be alleviated by conducting the same ReCo fine-tuning on a small subset of pre-training data [37] used by the same T2I model [34]. We show this ReCo variant in the supplementary material. Finally, ReCo builds upon large-scale pre-trained T2I models such as Stable Diffusion [34] and shares similar possible generation biases.
局限性。 我们的方法有一些局限性。首先,当输入查询变得过于具有挑战性时,例如图7©中的异常巨大“狗”,ReCo可能会生成质量较低的图像。其次,为了评估目的,我们在COCO训练集上训练了ReCo。尽管保留了在LVIS上显示的开放式词汇能力,但生成的图像风格偏向于COCO。通过在由相同的T2I模型[34]使用的预训练数据[37]的小子集上进行相同的ReCo微调,可能可以缓解这种限制。我们在补充材料中展示了这种ReCo变体。最后,ReCo建立在大规模预训练的T2I模型,例如Stable Diffusion [34]之上,并且存在类似的可能的生成偏差。
5、Conclusion
We have presented ReCo that extends a pre-trained T2I model for region-controlled T2I generation. Our introduced position token allows the precise specification of open-ended regional descriptions on arbitrary image regions, leading to an effective new interface of region-controlled text input. We show that ReCo can help T2I generation in challenging cases, e.g., when the input query is complicated with detailed regional attributes or describes an un-usual scene. Experiments validate ReCo’s effectiveness on both region control accuracy and image generation quality.
我们提出了ReCo,它扩展了预训练的T2I模型,用于区域控制的T2I生成。我们引入的位置标记允许对任意图像区域进行精确的开放式区域描述,从而形成了一种有效的新的区域控制文本输入接口。我们展示了ReCo在挑战性情况下对T2I生成的帮助,例如,当输入查询具有详细的区域属性或描述不寻常的场景时。实验证实了ReCo在区域控制准确度和图像生成质量上的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









