







论文地址:https://arxiv.org/abs/2303.17189
代码地址:https://github.com/ZGCTroy/LayoutDiffusion
目录
1、存在的问题
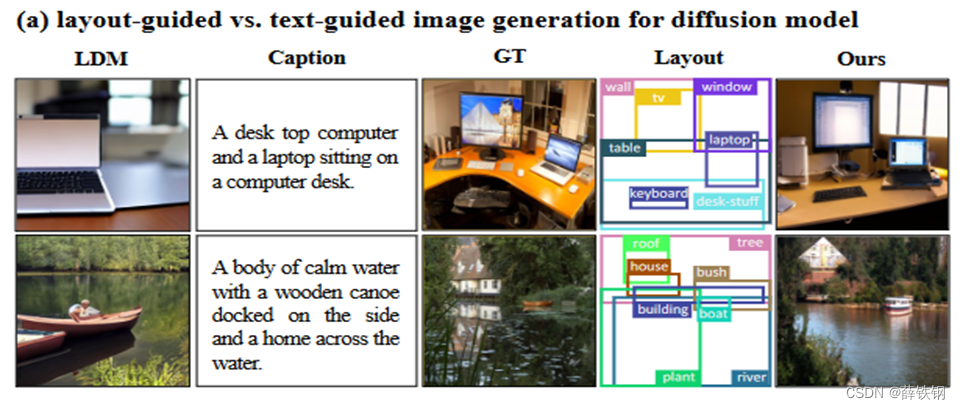
1、文生图方法存在的问题:当需要生成包含多个对象的复杂图像时,很难设计出适当而全面的prompt,这是由于文本无法精确地描述图像空间位置。
2、可控图像生成的一种主流方法,是将类别、文本等作为condition分支,与图像分支一起利用无分类器指导的技术进行联合训练(例如条件GAN,条件DDPM等)。这类方法涉及多模态融合,即将文本等数据和图像结合起来。
综合以上,本文考虑使用布局作为指导,探究布局生成图像的方法。同时,解决将图片和布局图进行融合的问题。
2、算法简介
本文提出了一种用于布局到图像生成的扩散模型LayoutDiffusion;
将图像的每个块作为一个特殊的对象,以统一的形式完成布局和图像的困难多模态融合;
提出了布局融合模块(LFM)、对象感知交叉注意机制(OaCA)。
3、算法细节
3.1、数据定义
布局图实际上是一系列物体在图片上的布局信息,一个布局序列中的每个对象o都对应着图片中的一个物体,每个对象由2D边界框和该物体的类别标签组成。
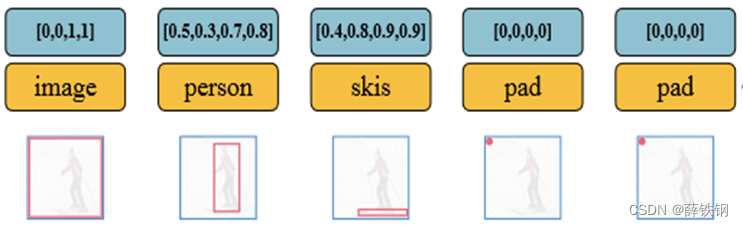
l = { o 1 , o 2 , ⋯ , o n } o i = { b i , c i } b i = ( x 0 i , y 0 i , x 1 i , y 1 i ) c i ∈ [ 0 , C + 1 ] \begin{equation} \begin{aligned} l&=\{o_1,o_2,\cdots,o_n\} \\ o_i&=\{b_i,c_i\} \\ b_i &= (x_0^i,y_0^i,x_1^i,y_1^i) \\ c_i&\in[0,\mathcal{C}+1] \end{aligned} \end{equation} loibici={
o1,o2,⋯,on}={
bi,ci}=(x0i,y0i,x1i,y1i)∈[0,C+1]
每张图片也是可以理解成一张布局图。
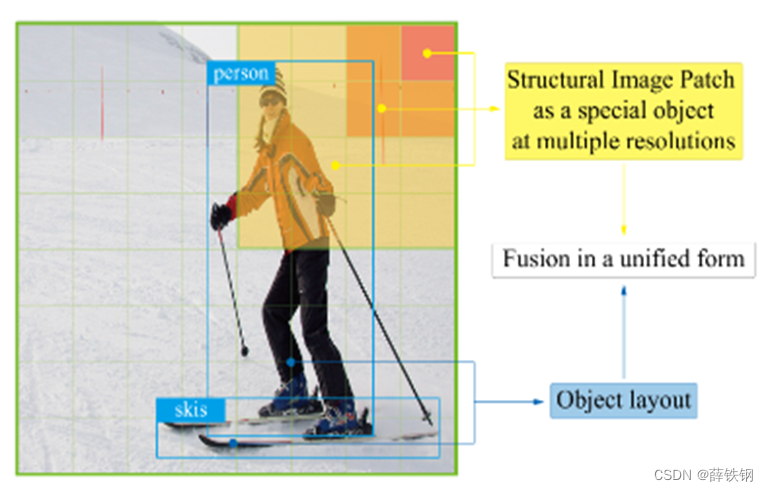
将图片分patch,每个patch代表一个物体,patch的位置信息就看作是该patch的2D边界框,不同尺度的patch则具有不同大小的2D边界框。Patch的深度图像特征则可以看作是该patch的内容信息。
这样一来,就可以将一张图片转化成结构化的布局图,将原本困难的图片和布局图的多模态融合问题转变成了分块图像的布局图和物体的布局图的融合问题。
3.2、Pipeline
1、Layout Embedding Module:构造适合深度网络处理的布局图数据
2、Layout Fusion Module:提取布局图深度特征,完成图中各物体的信息融合
3、Image-Layout Fusion Module:布局图和图像的融合
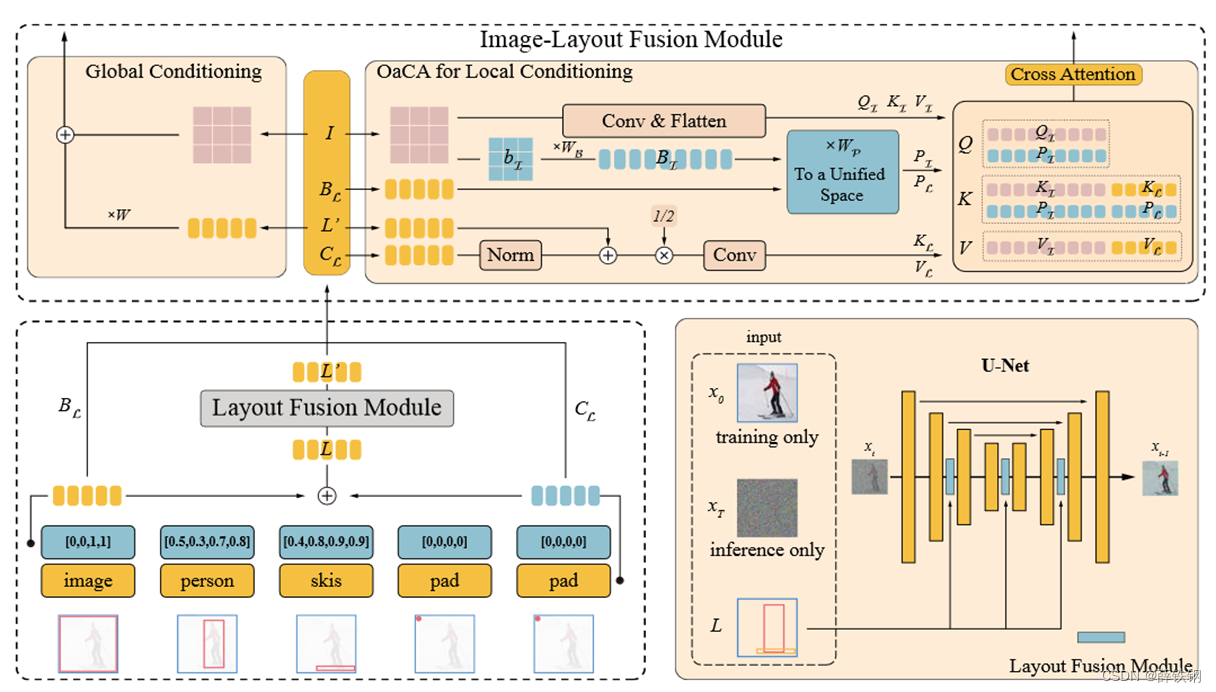
3.3、Layout Embedding Module
正如3.1所定义的,对于一幅输入图像,其对应的布局图中的每个物体都有相应边界框和类别,所有的物体对应的边界框和类别构成一个布局序列:
l = { o 1 , o 2 , ⋯ , o n } o i = { b i , c i } b i = ( x 0 i , y 0 i , x 1 i , y 1 i ) c i ∈ [ 0 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1656
1656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









