







 数据不平衡问题在自动驾驶、医学图像诊断等领域普遍存在,表现为长尾分布,常见类别样本多,罕见类别样本少。这种分布导致模型在少数类别的泛化能力下降,易过拟合。解决策略包括重采样、过采样、欠采样、生成合成样本等,以提升模型对罕见类别的识别能力。
数据不平衡问题在自动驾驶、医学图像诊断等领域普遍存在,表现为长尾分布,常见类别样本多,罕见类别样本少。这种分布导致模型在少数类别的泛化能力下降,易过拟合。解决策略包括重采样、过采样、欠采样、生成合成样本等,以提升模型对罕见类别的识别能力。
数据不平衡的问题在现实世界中无处不在。例如,自动驾驶,医学图像诊断,物种分类,数据本质上是严重不平衡的。
如果把不同类别的数据按照出现的频率从高到低进行排序,就会得到一条递减的曲线。在曲线的头部,数据出现的频率很高,随着数据的出现频率逐渐降低,曲线也逐渐下降,缓慢趋近于横轴,看起来就像拖着一条长长的尾巴,如下图所示。
例如,在物种分类问题中,将不同类别的物种按照稀有程度从高到低进行排序,那么最常见的物种拥有最多的样本数量,稀有的物种拥有较少的样本数量。
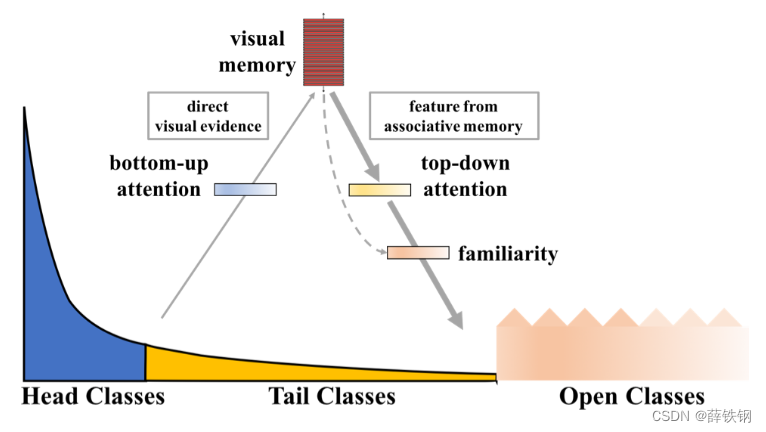
在实际应用中,训练样本通常表现为长尾类分布。位于曲线头部的一小部分类别含有较多数量的样本,剩下的类别含有较少数量的样本。那么,为什么会出现样本数据不平衡的问题呢?例如,在医学图像诊断问题中,需要对CT图像进行识别和分类,较为常见的病症拥有大量的临床实例,因而能够获取大量病症的CT图像,而对于罕见病来说,发病率低,患病人数占比少,相应的CT图像数量就十分匮乏;在自动驾驶问题中,通常情况下的路况都是正常的,很少遇到不正常或者不常见的路况。在这些情况下想要采集大量数据就比较困难。
数据的长尾分布会大大降低模型的泛化性能,出现过拟合的问题。试想一下,如果将分布不均衡的数据不加以任何处理直接输入到模型中进行训练,那么模型必定会在数量较多的样本上学习效果更好,而在数量较小的样本上学习效果更差。

















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








