






声明:本文首发于CSDN,禁止未经许可的任何形式转载,可咨询文末的责编。
UPYUN 创业于2005 年,当时服务器使用的网卡还是Marvell的芯片,要通过自定义内核和驱动源代码做编译才能驱动起来。而十年后在运维方面已经产生了翻天覆地的变化,本文系统地总结了 UPYUN 的云运维的野蛮成长、踩过的坑以及现阶段的状况。
运维的艺术
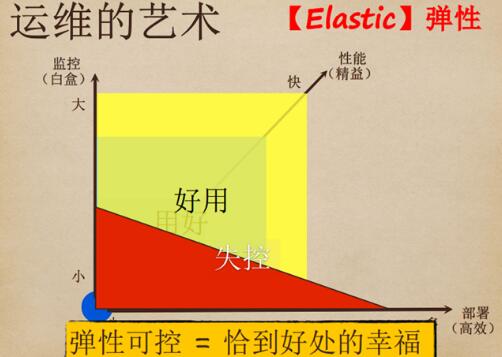
运维的艺术是弹性。首先,从无到有,这非常重要。无论运维做得多厉害,只是前面的“1”之后,加上多少“0”而已。从无到有很困难,但它是可以实现的,全力以赴去做,增长会很迅猛。
运维总共有几条线呢?
- 一是部署。由少到多,这是一种机器的控制方法;
- 二是从小到大。当服务器的数量达到有多少屏都看不全的时候,监控的手段就变得非常重要。这时候有一种方法是白盒运维;
- 三是性能,精益运维。
一家公司从小到大,不可能一口吃成胖子。第一阶段的重点是可用,第二阶段着重把现有的技术用好,第三阶段就要让它变得更好用。
随着业务增长越来越快,客户的要求越来越高。在UPYUN 的架构里面有了非常深入的应用,做了二次开发。当服务器数量越来越多,运维自动化越来越快的时候,如果监控做不上去,很容易失控。因此运维的技术弹性可控,是很好的方式。
架构是计划出来的,不是设计出来的,在不同的时间和阶段,要用不同的方法实现目标。并不是发展得越快越好,而是要接地气。
运维的法宝

运维的法宝是三位一体。其一是运维自动化和流程化,方法有很多种。原来我做的是车载,既然要做到12兆,里面不可能有拍摄,一个拍摄的包没三、四十兆做不到。目标是一样的,一定要会用工具,把容易出错的事情用脚本规范好。
其二是监控常态化,及时报警及隔离,触发补救措施。事故不可能无缘无故的发生,肯定是之前的工作留下了什么隐患,需要及时查清。要对异常采取及时的处理,UPYUN 使用第一人称的脚本做监控,发生异常状况它就会出来汇报。
最明显的是DDos攻击,总是事后才发现,因为流量打过来,最先感知的应该是网卡。针对这点,UPYUN用脚本捕捉网卡的异常上升流量,可以接收到它“临死前”发出的警报,运维人员就可以根据这个及时把受攻击的节点摘掉。
其三是性能可视化,运维要对自己的业务负责,提供连续的健康度报表,以争取资源。因为运维需要拿到机器或足够的硬件,否则工作很难进行。当运维和老板或是上级讲技术点时,如果他们听不懂,就可以把报表拿给他们看。这就是性能可视化的一个重要的意义。
方向比努力更重要,流程比补位更重要,方法比拼命更重要。在2015年,UPYUN 都在做流程的改进,之前太粗放了。
部署自动化
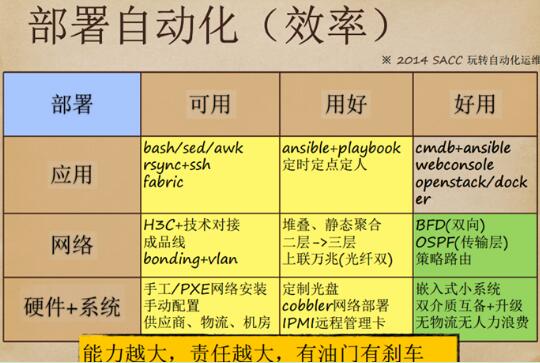
部署自动化的三个要素:应用、网络、硬件+系统。第一期时UPYUN用awk、sed、bash,第二期换成了Ansible+playbook,第三期开始使用cmdb+Ansible。发布流程之前很不规范。比如运维需要cmdb+Ansible的结合,但发现还没做,怎么办呢?就可以用定时定点的方式规定好星期三做发布、星期二做测试。届时大家去一个会议室,事先设定好,届时开始观察。星期五继续观察,发现有问题就回退。
这些只是中间过程,因为运维知道我要做什么。定下目标之后,中间的过程就可以很好的控制。起初UPYUN和H3C做对接,购买它的设备,它提供技术解决方案。现在做到BFD,有多个数据中心,可以用光纤做互通。
现在UPYUN 不仅有两根裸纤,还有八个口。UPYUN从北京、中山等数据中心做最近路径的选择。国内的中转机房,像电信、联通和移动,对于堆迭、静态聚合,云存储是内网做冷存储,公司跟交换机做堆迭,因而吞吐量有保证,交换机也可以备份。
随着体量越来越大,UPYUN从IDC拿到的筹码也就更大,比如2G的保底量,他们给UPYUN起三层,无论在抗攻击能力、网络拓扑结构上,有更大的灵活度。拿到 A 轮融资以后,UPYUN的第一件事,就是把网络设备升级成万兆交换机。因为前面有LOVS,可以做扩展扩容。而如果网络无法扩容,要扩这个点的话,业务就必须切掉。因此跟机房谈一个万兆口甚至是两个万兆口时,必须网络先行。硬件直接跳到嵌入式小系统,当机器只有一块盘的时候,把它从五变到六,机器就必须下架。
如果用小系统就会发现,这里有两种介质:U盘和磁盘。如果要升级系统,UPYUN可以把系统切到小系统,对磁盘做操作系统的写入,前后不超过三分钟。UPYUN 现在可以做到上千台的机器从来不在公司出现,直接把系统寄到生产线,在生产线上把U盘插上去,从生产线连接到机房,机房人员插线后,UPYUN 的运维团队就可以进行远程控制。
这是最基本的系统,它不会将UPYUN的敏感数据带进去。否则的话,这么多CDN机器发到公司,要解包、安装系统、测试等,运维会忙不过来的。在部署自动化方面,UPYUN有完善的工具和流程。
如今,很多大会都在谈运维自动化,这跟企业的系统架构设计紧密相关。当运维在架构上保证降级后,很多事情需要推动开发来做,开发部门要配合你降低维度。不久之前,UPYUN 就曾经做过一次降级,还是相当成功的。
监控常态化
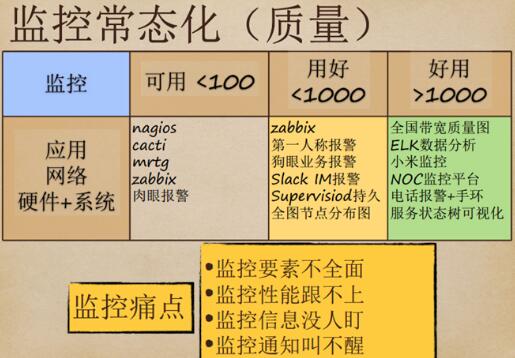
监控常态化,这其中包含了很多的经验教训。监控要素不全面,监控性能跟不上是比较大的问题。通过总结经验,UPYUN发现zabbix当采集了1000+多台服务器的各种监控指标后,性能就跟不上了。
监控要分等级。100台可以靠肉眼监控,100至1000台就需要用Zabbix 和第一人称报警。UPYUN 有自己的业务监控,还有全国节点分布图,UPYUN 有大约3000多台服务器,就把数据做汇总,进行数据可视化的处理,成功实现带宽质量图、ELK数据分析、小米监控。UPYUN 对小米监控的部分功能进行了二次开发,现在它的整体性能要比Zabbix好很多。
此外,还有UPYUN自行开发的“狗眼”监控系统。它能够监测到每一个子系统的响应速度。包含全国节点带宽图,它用红色、绿色、蓝色进行状态标记,还可以显示各节点的服务器数量。UPYUN“双十一”入驻蘑菇街时,就可以通过该系统看到所有机房的实时数据监控。其实,监控策略很简单:每天盯三个最慢的机房,逐个排查原因,这是做SLA的保证。
今年上半年,运维团队的口号是“发现问题比客户及时”,但可惜一直做不到。这是因为客户是24小时在线上,每次都是客户比我们快,这让人很苦恼。而在用了ELK的日志大数据分析后,UPYUN 很多时候就可以做到先于客户发现了。
性能可视化
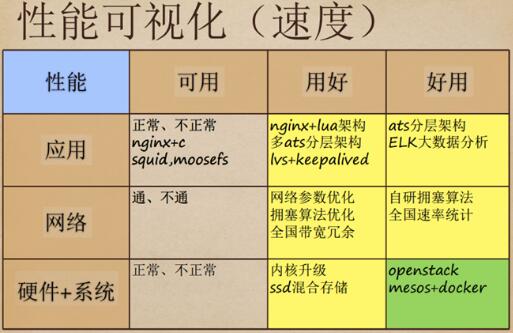
关于性能可视化,现在可以做到在缓存软件上做Nginx+lua。我们同时用两个,其中一个负责SSD,ATS可以做到秒级重启,上面有LVS做负载均衡。运维不能保证这个集群里ATS同一时间存取,但如果内容泄露过多,就得强制重启。因此UPYUN 现在招了两个专职人员研究ATS源代码。另外,UPYUN 自研了拥塞算法。第三方提供的算法可用性很低,但是它们的内核在UPYUN升级很快,Linux的代理升级要与应用程序一样快,而内核的升级会提升性能。
2015年5月份左右,UPYUN 开始关注Mesos+Docker,之前一直选择OpenStack主要是出于节约成本的考虑。而在发现Docker很好用后,团队开始集中精力研究Docker。ELK可以做很多事情,可以看到低于100毫秒、300毫秒、500毫秒、1000毫秒,有4xx、5xx的比例,数据报表一点点小波动都可以看到差异。UPYUN曾经做过测试,没使用优化内核算法和使用了新的hybla拥塞算法,从3.18的内核升到4.1的内核,数据会有提升。Kernel要自己把握,3.18到4.1的时候,我们曾经遇到过一个问题:内网做TCP的时候做大包调整很爽。但放到外围CDN的时候,4.0出现了Bug。4.0的内核在因特尔1000的网卡双向组合的时候会无响应,而3.18的内核接入就没问题。它的好处显而易见,但一定要把握度。
运维的烦恼

作为运维人员,会有很多烦恼。第一点,运维很多时候都要扮演“接盘侠”和“背锅侠”的角色,因为公司要有一个人出来承担责任。如果运维能够在这个压力下解决问题,获得老板认可,那你就是合格的。
另一点是频繁申请和更换资源。现在OpenStack和Docker都有这方面需求。Ansible和Mesos也很实用,现在几千台服务器都有Docker。第三是监控不到位,这点可以用ELK和Hadoop来解决。第四是消除单点,这一块可以借助LVS+Haproxy。在硬件方面,双电源、双电力、多运营商、双交换机、双机柜、多机房这些配置,需要根据业务不同的发展阶段做权衡,来进行选择。
运维的指导思路

运维的指导思路。首先是与人无关:要将机器负载均衡做得滚瓜烂熟。用脚本、Playbook做机器生成,跟人无关。其二是与己无关:要舍得把东西交出去给下属做,自己不断学习新的东西。第三是与状态无关:运维要做无状态和扩展性,有些程序员很喜欢有状态,这就要考验你、工程师和CTO的能力,推动程序员去做。最后一点是与数量无关:要做部署的恒定,运维话语权的增长,很多时候是在业务突飞猛进时,运维成本仍保持不变,自己在老板心中的威信就会提升。
运维的修炼

关于运维的修炼。首先是要闲下来,多掌握技术;其次是走出去,多参加活动,多互相学习、交叉分享;第三是多问为什么,学思结合,掌握更多信息,学以致用。而自己讲的东西要深入浅出,所有人都听得懂。
UPYUN 主要是做云 CDN 。公司鼓励创新和颠覆,因此技术革新特别快。大公司内核升级以年为周期,而UPYUN可以做到三个月把CDN的内核升一遍。现在UPYUN只有一百多号人,而就是这些人撬动了两家上市公司的市场。未来CDN市场会越来越火,但CDN厂商的数量不会太多。UPYUN将在做好分内事的基础上不断努力,把CDN的市场做大。
分享人:邵海杨资深系统运维架构师,来自杭州 Linux 用户组,新浪微博“@海洋之心-悟空”。
本文整理自UPYUN 运维总监邵海杨日前在“UPYUN架构与运维大会·北京站”上的主题演讲。UPYUN 架构与运维大会是国内领先的新一代云CDN服务商UPYUN独家主办的大型技术会议。大会面向全国运维和架构从业者,邀请业内一线的架构师和运维专家进行纯干货分享,旨在推动各项运维技术、产品架构等在互联网和移动互联网的研发和应用。
「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008入群,备注姓名+公司+职位。
(责编/钱曙光)















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









