






原文:How Yelp Runs Millions of Tests Every Day
作者:Chunky G.
翻译:贺雨言
快速进行功能开发对企业至关重要,开发团队都试图通过减少测试、配置和监控变化的时间来提高开发人员的效率。为了让开发人员安全地敲代码,Yelp使用内部分布式系统Seagull运行2000多万个测试。

什么是Seagull?
Seagull是一个容错和故障恢复的分布式系统,用来并行执行测试包。Seagull由以下几部分组成:
- Apache Mesos(管理Seagull集群上的资源)
- AWS EC2(提供组成Seagull和Jenkins集群的实例)
- AWS DynamoDB(存储调度器的元数据)
- Docker(隔离测试需要的服务)
- Elasticsearch(追踪测试运行次数和集群使用数据)
- Jenkins(搭建代码项目并运行Seagull调度器)
- Kibana和SignalFx(提供监控和报警)
- AWS S3(为测试日志提供真实数据来源)
挑战
在准备单片Web应用和Yelp主机配置新的生产代码之前,Yelp开发人员在特定的主机上运行整个测试包。测试前,开发人员需启动用来调度集群测试的Seagull。以下两点需要着重考虑:
- 性能:每个Seagull-run包含将近10万个测试,依次运行完毕需要大约2天时间。
- 规模:通常一天有300多个seagull-runs在运行,高峰时段要同时运行30-40个测试。
这项任务的挑战在于执行每一个Seagull-run所花费的时间是以“分钟”而不是以“天”来计算,同时保证在这个时间段内成本效益好。
Seagull怎样运作?
首先,开发人员在控制台启动Seagull-run,即启动Jenkins搭建代码项目并生成测试列表。然后,将测试打包传给Seagull集群上的调度器进行测试。最后,将测试结果存储在Elasticsearch和S3中。
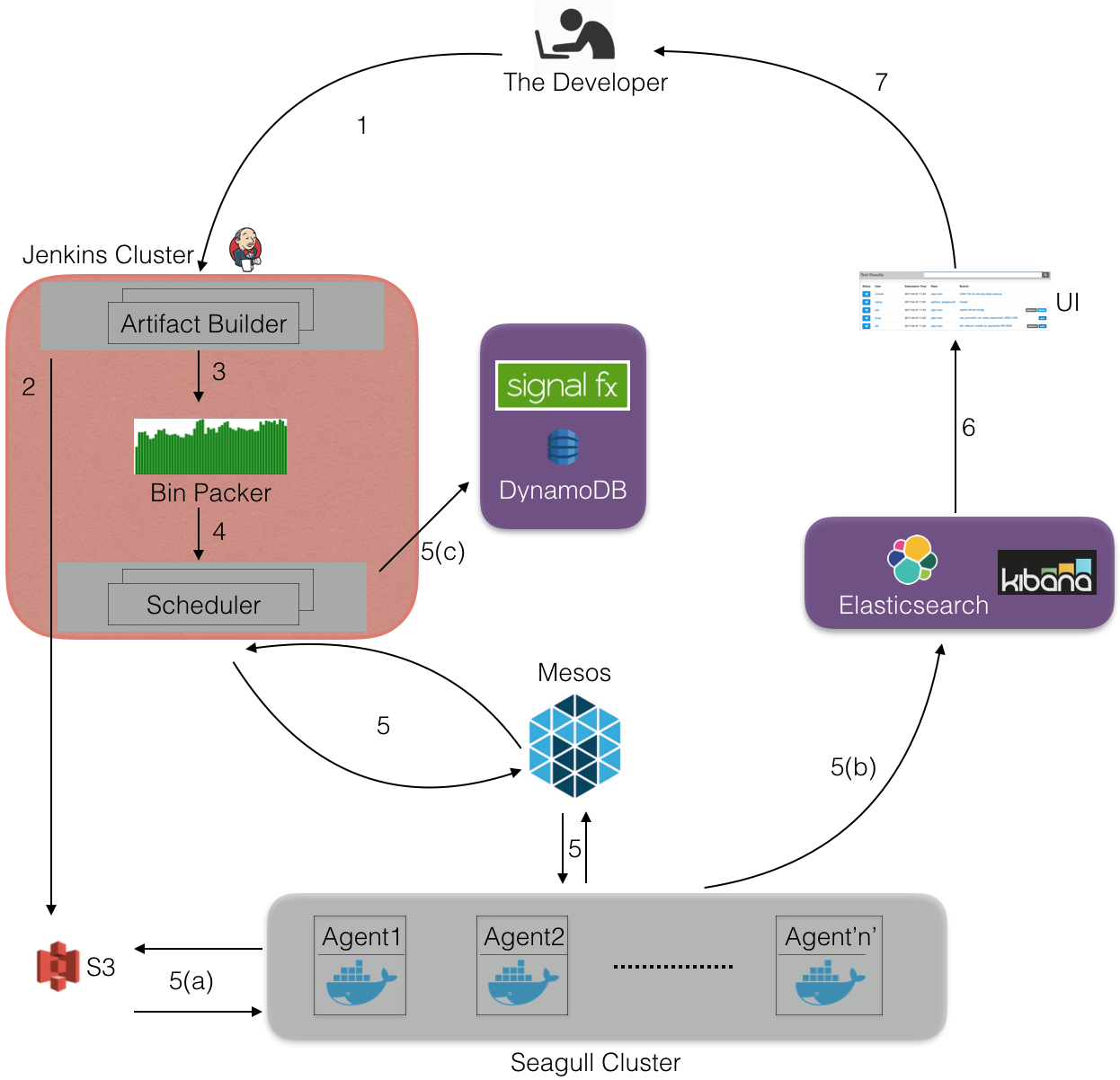
- 开发人员为特定的代码版本(基于其分支git SHAs)启动Seagull-run,设git分支为test_branch。
- 生成test_branch的代码项目和测试列表并上传到S3。
Bin Packer抓取测试列表和测试的历史时序元数据,从而构建包含测试的多包。有效打包是一个装箱问题,可以用以下两个算法解决,(选择哪种算法)取决于研发人员传给Seagull的参数:
- 贪婪算法:首先根据历史测试时长将测试分类,然后将测试时长设置为10分钟的测试归档。
线性规划(LP):为了防止相关测试,一个测试需要和另一个测试在同一个包里运行。因此,我们使用LP进行打包,LP方程的目标函数和约束条件定义如下:
- 目标函数:对生成的包总数取最小值
- 主要约束条件:
- 单包的测试时长少于10分钟;
- 一个测试只能放入一个包;
- 相关测试放入同一个包。
我们使用Pulp LP解算器求解方程:
# Objective function:
problem = LpProblem('Minimize bundles', LpMinimize)
problem += lpSum([bundle[i] for i in range(max_bundles)]), 'Objective: Minimize bundles'
# One of the constraint, constraint (1), looks like:
for i in range(max_bundles):
sum_of_test_durations = 0
for test in all_tests:
sum_of_test_durations += test_bundle[test, i] * test_durations[test]
problem += (sum_of_test_durations) <= bundle_max_duration * bundle[i], ''
其中,bundle和test_bundle是LP变量,max_bundles和bundle_max_duration是整数。
通常,在LP约束条件中,我们会考虑测试用例的搭建和解除的时长,但是为了简便,在这里我们忽略不计。
4. 在Jenkins主机上启动调度器进程,Jenkins主机抓包然后搭建mesos架构。我们为每一个Seagull-run创立一个新的调度器。每一次运行生成300多个包,将运行时长在10分钟左右的包归为一类。调度器为每一个包建立一个Mesos执行器,只要Mesos控制器提供充足的资源,就将Mesos执行器列入Seagull集群时间计划表。
5. 一旦执行器被列入到集群,执行器内部将进行以下步骤:
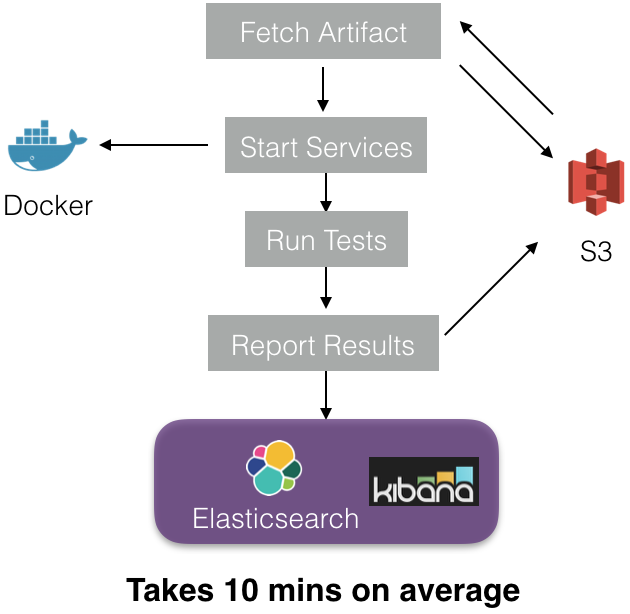
每一个执行器建立一个沙箱,从S3(在步骤(2)中已上传)下载新建项目。然后下载对应于相关测试服务的Docker图片就可以建立Docker容器(服务)了。当所有的容器都启动并运行,就开始进行测试了。最后,测试结果和元数据存储在Elasticsearch(ES)和S3中。我们用内部代理服务Apollo写入ES。
如果你生活在一个分布式系统的世界,你一定无法避免主机故障。Seagull对任何实例故障都具有容错功能。
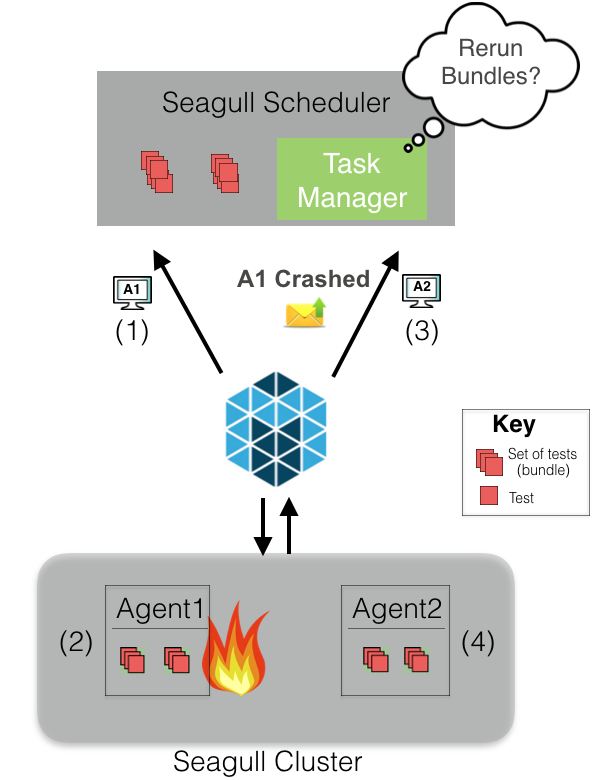
例如,假设一个调度器要运行两个包。Mesos会提供一个代理(A1)的资源给调度器。假设调度器认为资源充足,那么这两个包会被安排在A1上。假如出于某种原因,A1出故障了,那么Mesos会通知到调度器。调度器的任务管理器决定重试或者丢弃那两个包。如果重试,当Mesos下一次提供充分的资源(这种情况下,是提供代理A2的资源)时,那两个包会被重新安排到时间计划表里。为了防止包被丢弃,调度器会将那两个包测试标记为“未执行”。
6. Seagull UI用Apollo从ES获取结果,并将结果加载到UI供开发人员查看。如果结果全部通过,就可以准备配置了。
规模化挑战
为了确保测试包的及时性,尤其是在高峰期,Seagull集群需要保证大量实例一直处于可用状态。之前我们使用AWS的按需实例AWS ASGs,但对我们来说,要想达到这个容量成本太高了。
为了降低成本,我们开始使用一个叫FleetMiser的内部工具去维持Seagull集群。FleetMiser是一个用来测量基于不同信号的集群的自动缩放引擎,这些信号包括当前集群使用率、管道内的流量数等等。FleeMiser主要由以下两部分组成:
- AWS Spot Fleet:AWS有现场实例,现场实例比按需实例成本低很多,Spot Fleet能提供交互界面更简单的现场实例。
- 自动缩放:集群的使用时间不稳定,使用高峰主要集中在10:00-19:00(太平洋标准时间),此时,开发人员工作强度最大。为了动态调整范围,FleetMiser使用集群在不同优先级别下的当前和历史使用数据。Seagull集群每天的波动范围大概介于1500CPU内核和10000CPU内核之间。
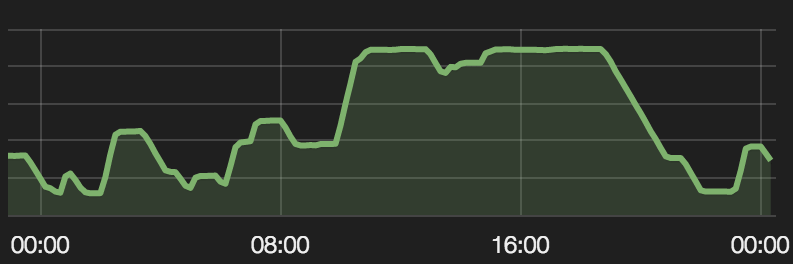
FleeMiser为我们的集群节省了大约80%的成本。在使用FleetMiser之前,我们是使用AWS按需实例,没有自动缩放功能。

总结
Seagull使测试结果时长从2天缩短到了30分钟,同时也大大降低了执行成本。从今以后,开发人员可以安心敲代码,不用再花大量时间等待验证变化却束手无策。















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









