







中文分词 (Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。下面简单介绍几个中文分词工具。中文版本主要介绍ICTCLAS系列,英文版的包括LingPipe,StarnfordWord Segmenter,以及OpenNlp软件包。
1. ICTCLAS
1.1. ICTCLAS 介绍
- ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System)分词系统是由中科院计算所的张华平、刘群所等开发的一套获得广泛好评的分词系统,主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。
- ICTCLAS全部采用C/C++编写,支持Linux、FreeBSD及Windows系列操作系统,支持C/C++/C#/Delphi/Java等主流的开发语言。
- ICTCLAS采用了层叠隐马尔可夫模型(Hierarchical Hidden Markov Model),将汉语词法分析的所有环节都统一到了一个完整的理论框架中,获得最好的总体效果,相关理论研究发表在顶级国际会议和杂志上,从理论上和实践上都证实了该模型的先进性。
1.2. ICTCLAC分词原理简介
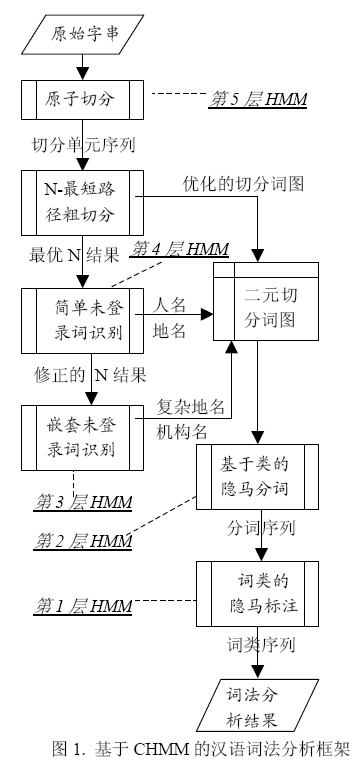
- 该系统基于隐马尔科夫模型提出了层叠隐马尔科夫模型(CHMM),CHMM实际上是若干个层次的简单HMM组合,各层隐马尔科夫模型之间以以下几种方式相互关联:各层HMM之间共享一个切分词图作为公共数据结构(如图1),每一层隐马尔科夫模型都采用N-Best策略,将产生的最好的若干个结果送到此图中供更高层次的模型使用。
- 该CHMM由低到高依次为:原子切分,简单未登录词识别,嵌套未登录词识别,这几层中共享二元切分词图,并在每层对该数据结构进行修改,使得传递给基于类地隐马分词的参数越来越准确,最后一层为隐马词性标注。
1.3. ICTCLAC实现版本
1.3.1 原始版本
- ICTCLAS Free版本于 2002 年 8 月 16 日发布于中文自然语言处理开放平台(http://www.nlp.org.cn/)并于 2002 年 9 月发布相应的论文及测试报告。测试报告主要包括国家 973 英汉机器翻译第二阶段的评测报告及在 1998 年 1 月标注人民语料库上的自评结果。
1.3.2 中科天玑商业版 ICTCLAS汉语分词系统
- 应用户要求,作者在原来基础上做了改进,推出 ICTCLAS 2011。内核版本5.0,改版后分词速度更快;稳定性更高。 ICTCLAS 2011c/c++/c#版、JNI版均支持多线程调用。以往版本需要进行编码转换,统一转换成GB2312之后才能做进一步处理。系统当前版本支持GB2312、GBK、UTF-8、BIG5等编码。以上编码无需做任何转换,即可进行后续处理。用户可指定需要处理数据的具体编码(有利于提高速度)也可让系统自动识别编码。本版新增了对繁体中文即BIG5的识别处理。 本版对Windows7支持良好。支持大用户词典。
- 该版本的源码还是C++,不过有java ,C#等的接口
- 下载地址:http://www.ictclas.org/ictclas_download.aspx
测试使用
C++版本没调试通过,代码也没看懂,各种心塞,继续努力
1.3.3 ICTCLAS4J版本
ICTCLAS4J介绍
ICTCLAS4J中文分词系统是sinboy在FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复杂度,旨在为广大的中文分词爱好者一个更好的学习机会。不同于以前的C++版提供的JNI调用,ICTCLAS4J是纯Java版本的ICTCLAS。但是也由于开源有很多的不足。
ICTCLAS4J测试使用
- 下载ICTCLAS4J: http://ictclas.org/Down_OpenSrc.asp

- 将下载下的ICTCLAS4J解压缩得到bin,data,src, segtag.bat 4个文件
- 在Eclipse上建立一个project,命名为ictclas4jTest
- 把Data文件夹整个拷贝到Eclipse项目的文件夹下,而bin目录下的org文件夹整个拷贝到Eclipse项目的bin目录下,把src目录下的org文件夹整个拷贝到Eclipse项目的src目录下
- 导入commons-lang.jar http://download.csdn.net/detail/qianwen5201314/7716237

- 现在就可以在你的项目里新建一个类来试试。这里新建了一个test类,代码如下:

- 分词结果(可以改变源码使其出现词性标注)

BUG与不足
- BUG1: 在使用分词时候,人名会出现漏字问题(如上测试) 。
PosTagger.java文件中人名识别部分personRecognize方法里面出错了,注释掉if (sn.getPos() <4 &&unknownDict.getFreq(sn.getWord(),sn.getPos()) < Utility.LITTLE_FREQUENCY),参见 http://tinypig.iteye.com/blog/250926
- BUG2: AdjustSeg.java里面的 finaAdjust()函数里要注意将while语句的判断条件while (true)改为while (true && i + 1 < optSegPath.size()) ,否则也可能发生越界错误
- BUG3: 当汉字首字节为负如“癵”*(实际上可能是乱码),转换找词表的时候会发生越界错误,这个bug在开源的ictclas里面也存在,但是c++不检查越界,因此不报错。因此在Dictionary.java中的findInOriginalTable方法中加入判断if(index < 0 || index >=Utility.CC_NUM) return -1;
- 不足:速度比较慢。
代码里面用到了很多java的String的操作,这个其实比较废时间,还有词典的组织,也是用的String的数组,再二分查找,用hash应该会快一点。
ICTCLAS因为有一个卖钱的商业版,所以这个开源的版本毛病还是比较多的。比如有一些词库中不存在的词,就会扔空指针的错误,比如“深圳”,“大阪”这样的词。 还有对一些特殊的字符串模式,比如单引号隔几个字符再加一个什么什么的,就会报错还有一些特殊的字符,也会报错。
1.3.4 imdict-Chinese-analyzer版本
imdict-chinese-analyzer简单介绍
imdict-chinese-analyzer是 imdict智能词典的智能中文分词模块,作者高小平,算法基于隐马尔科夫模型(Hidden Markov Model, HMM),是中国科学院计算技术研究所的ictclas中文分词程序的重新实现(基于Java),可以直接为lucene搜索引擎提供中文分词支持。
imdict-chinese-analyzer测试使用
- 下载链接http://ictclas.org/Down_OpenSrc.asp
- 下到的压缩包解压后就是一个java工程,eclipse直接导入即可,但由于其开发的环境是UTF8所以要将eclipse的工作空间的编码也设置为utf8,test包里面的AnalyzerTest就是其用法,看了以后就可以直接用了
imdict-chinese-analyzer优缺点
- 优点
开源,分词速度快,效率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4298
4298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









