







Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review
Summary
本篇文章对AD检测的文献进行了整理,包括其使用的特征、数据集、分类器、评估方法。
Background
- 阿兹海默症(AD)由于其不断上升的患病率、对患者和社会的影响以及相关的医疗成本而具有至关重要的意义
- 目前的诊断技术并不能用于频繁的大规模筛查,延误治疗干预和恶化预后。为了能够在早期阶段(理想情况下是在临床前阶段)检测到AD,语音分析作为一种简单、低成本的非侵入性手术出现了。
- 语言技能和沟通能力的丧失是痴呆症患者的常见症状,可以作为相关的生物标志物
Significance
- 介绍了最常用的识别特征
- 列出了常用的和性能最好的机器学习模型
详细介绍
背景
-
一般而言,MCI(轻度认知障碍)是了非痴呆老化和具有遗忘型主要特征的痴呆之间的点 。
-
痴呆症的评估基于以下四个关键问题:
- 是否存在个体自身检测或者亲近个体观察到的主观残疾
- 所进行的测试是否有认知障碍的客观证据
- 有无功能衰退
- 是否出现某些由痴呆症固有的某些东西引起的症状
-
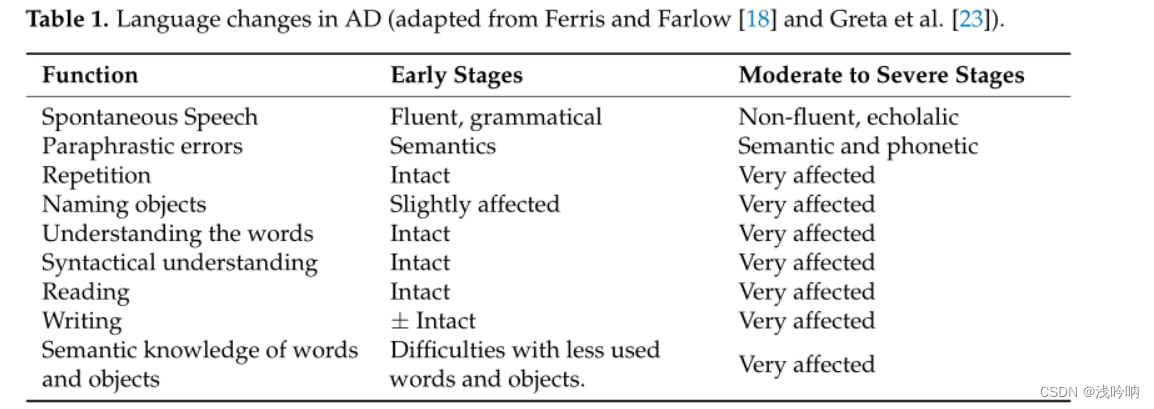
阿兹海默症的特征是包括语言在内的几个认知领域的缺陷逐渐恶化。失语症和构音障碍是AD的常见症状,语言障碍的发生主要是由于语言处理的语义和语用水平下降。
语言障碍是大多数痴呆症患者的主要问题,特别是随着疾病的发展.
- 交流受到影响的第一个迹象是找词困难,特别是在给熟悉的人或物体命名时。单词被错误和无意义的单词取代,讲话中的停顿也增加了
- 在AD的早期阶段,语言障碍涉及词汇恢复、语言流利性丧失以及高级书面和口语理解能力的崩溃。
- 在AD的中度和重度阶段,语言流利性的丧失是严重的,表现为理解能力的丧失和显著的字面和语义释义。
- 在AD非常严重的阶段,讲话往往仅限于回声和言语刻板印象。
-
基频、声音中断、发声周期、语速等,在阿兹海默症患者和健康人中表现出不同的范围
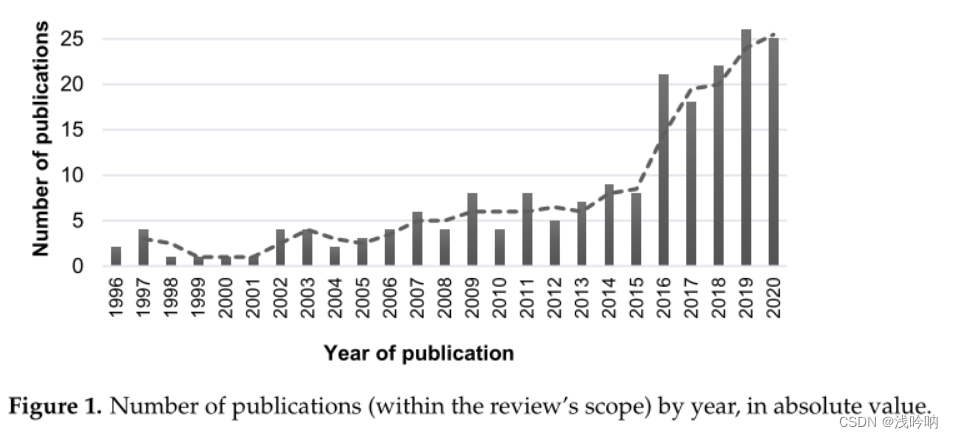
综述论文整理
-
信息源:Science Direct、PubMed和DBLP
-
时间:截至2020.5
-
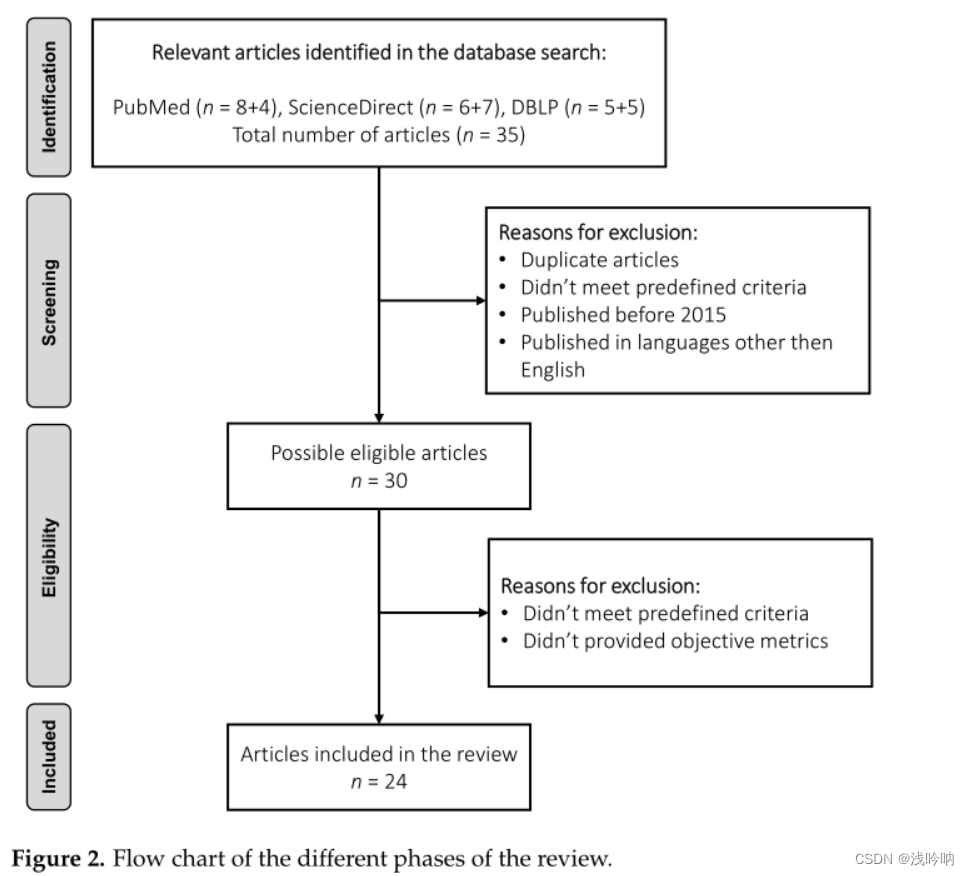
筛选流程
结果
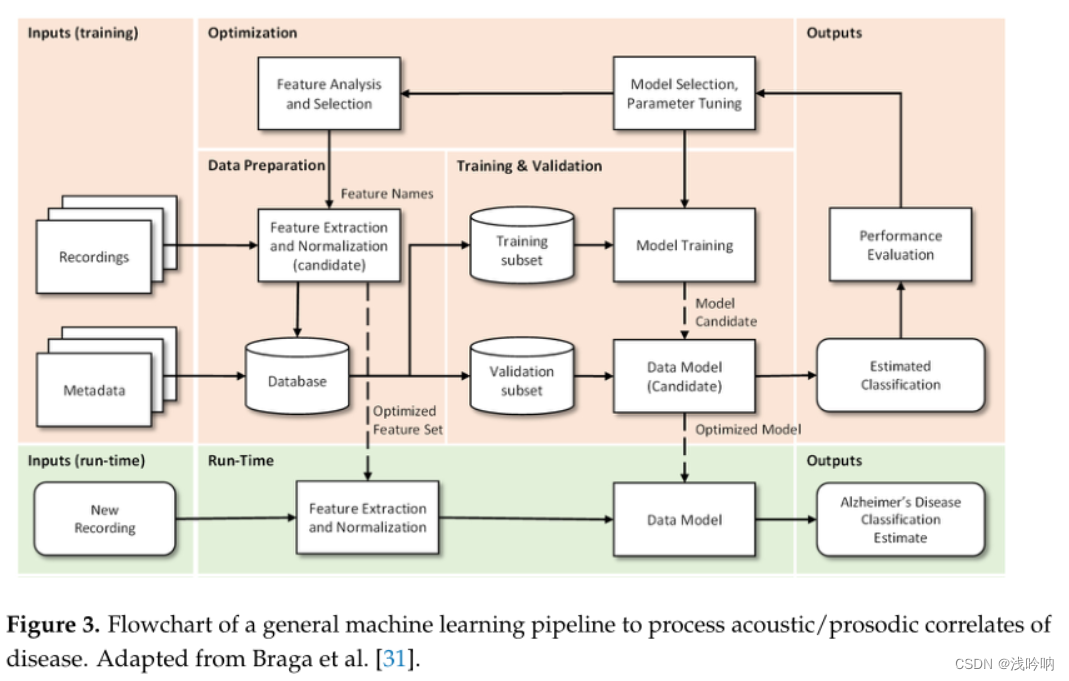
机器学习pipeline
-
数据准备:进行特征的提取、优化和归一化
😊选择最重要的特征
😊归一化
😊数据增强
-
训练和验证:
😊通常70%-90%用于训练,30%-10%用于测试
😊随机生成子集,可进行交叉验证
-
优化:
😊在模型评估后,可以得出需要改进的参数,以及以更有效的方式进行选择最感兴趣和相关的特征,从而获得新的特征,进行新的训练和迭代
-
Run-Time:
😊测试,预测
音频资源
-
BEA(其首字母缩写来自Beszélt nyelvi Adatbázis)是一个不断增长的数据库,其中包含各种类型的自发演讲、朗读和匈牙利语对话。到目前为止,它包括280名年龄在20岁到90岁之间的健康和认知衰退的受试者的记录
-
Cinderella收录了60名受试者自发讲述灰姑娘故事的录音。这60名以葡萄牙语为母语的受试者被平均分为健康组、MCI组和AD组。
-
TalkBank是一个项目,其主要目标是鼓励人类交流领域的研究。目前,它提供了涵盖34种以上语言的几个研究领域的资料库,所有这些都是应要求开放源代码的。
DementiaBank是这个项目的储存库之一,顾名思义,它专注于痴呆症患者的交流。在这个存储库中,有几个语料库正在分析中,它们具有不同的语言、任务和痴呆
特征
考虑到特征的线性度,它们可以分为线性或非线性,更常用的是线性特征。
语言学特征(linguistics) 声学特征(acoustics)
- 已用于AD检测的语言特征
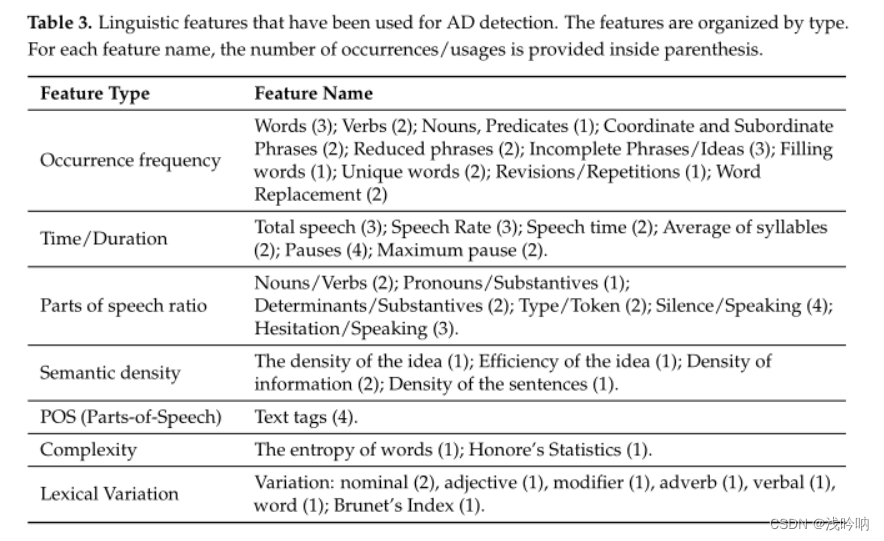
第一列为类型,第二列为具体的某个方面的特征(括号内为使用次数)
- 已用于AD检测的声学特征
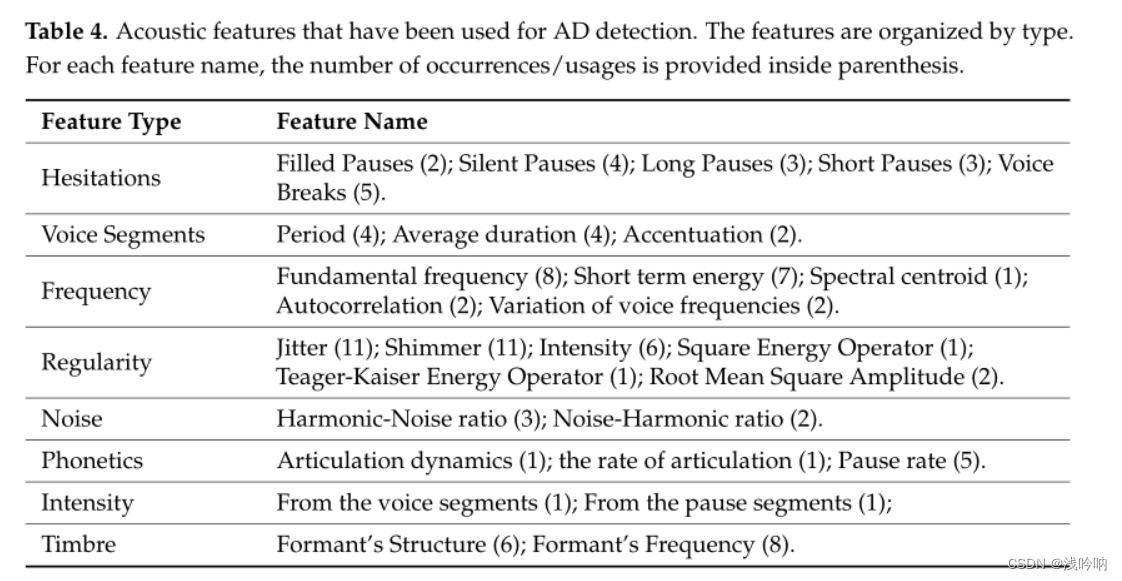
成果
-
Rentoumi等人开发了对阿兹海默症患者进行计算语言分析( computational linguistic analysis)的研究,最高准确率为88%。
-
Toledo等人用葡萄牙语进行了一项研究,其中Cinderella的历史被用作主要分析任务。以同样的方式使用语言特征,可以区分不同程度的痴呆症
-
Hernández-Domínguez等人提出了一种新的方法来描述患者,然后将他们归类为阿尔茨海默病患者或非阿尔茨海默病患者。这种分类使用语言特征达到了 94% 的准确率
-
Fraser等人开展了两项研究,提取的特征都是语言特征。
- 第一个是双语,它允许创建适用于两种语言(英语和瑞典语)的检测系统,还允许评估语言对该检测准确性的影响。
- 第二种采用级联方法结合来自多种语言任务的数据来区分 CCL 患者和健康患者,准确率达到 83%
-
Martínez-Sánchez等人提出了一项研究,以验证一个原型,自动执行老年痴呆症患者的语音分析。该设备基于声学特征,提供了可以解释为识别语音流畅性、声学和韵律的特定变化的数值参数,并能够正确地对92.4%的研究对象进行分类。
-
Khodabakhsh等人使用声学特征检测AD,准确率达到94%。另一个研究包含了更广泛的特征集,其中结合了声学和语言特征,对于一个不同的数据集,准确率为84%。
-
Qiao等人使用声学特征对AD和MCI患者的语言障碍进行表征
-
Alexandra König等人提出使用几个简短的认知语音任务来区分健康对照组、轻度认知障碍和AD患者,其中最好的区分是健康受试者和阿尔茨海默病患者,准确率为87%。
-
Gosztolya分别使用语言和声学特征达到了82%的准确率,结合使用使得准确率达到了86%
-
Beltrami结合语言和声音特征,准确率达到了77%
-
Chien等人通过创建和训练的声学特征序列生成器来选择特征,来分析AD
常用分类模型

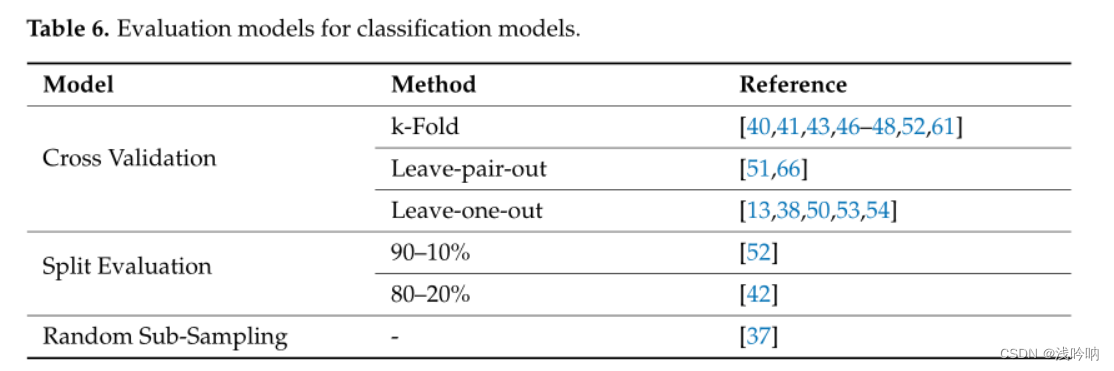
评估方法
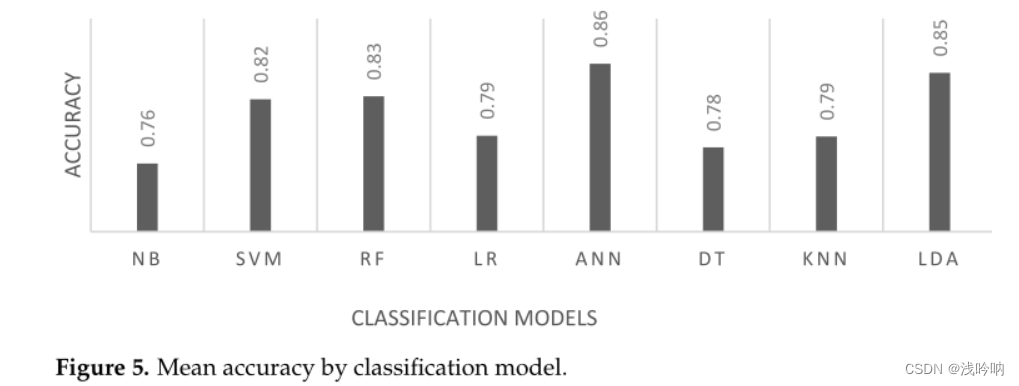
不同模型的准确率
补充
MMSE:简易精神状态量表或称简易精神状态检查表(Mini-Mental State Examination,MMSE)由Folstein等人于1975年编制,是最具影响的标准化智力状态检查工具之一,其作为认知障碍检查方法,可以用于阿尔茨海默病的筛查,简单易行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









