







HPA(Horizontal Pod Autoscaler)是Kubernetes的一种资源对象,能根据某些指标对在statefulset、replicaSet、deployment等集合中的pod数量进行横向动态伸缩。HPV对资源的计算本身又依赖于Metrics-Server,所以,我们首先来了解下Metrics-Server。Metrics Server是Kubernetes内置自动伸缩管道的容器资源度量的可伸缩、高效的来源。Metrics Server从Kubelets收集资源指标,并通过Metrics API在Kubernetes apiserver中公开它们,供水平Pod自动缩放器和垂直Pod自动缩放器使用。度量API也可以通过kubectl top访问,这使得调试自动缩放管道更加容易。需要注意一点,Metrics Server不是用于非自动伸缩目的的。例如,不要使用它将指标转发给监视解决方案,也不要将其作为监视解决方案指标的来源。在这种情况下,请直接从Kubelet /metrics/资源端点收集指标。另外Metrics-server只存储最新的指标数据(CPU/Memory)。
接下来就通过实际例子看看Metrics server如何工作,首先是安装metrics-server,安装完成后,可以看到创建了clusterrole和rolebinding的对象,另外还创建了service/deployment/apiservice对象。
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml

查看apiservice对象,可以看到很多apiservice对象的Service是Local,而v1beta1.metrics.k8s.io这个apiservice的Service是部署在kube-system namespace下的metrics-server。这里的含义是如果API-Server接收到Local的请求时,直接处理即可,如果接受到v1beta1.metrics.k8s.io的请求时,转发到metrics-server去处理。

下面是创建v1beta1.metrics.k8s.io APIService对象的yaml定义文体局。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100创建完成后,可以通过kubectl一些命令查看pod/node的CPU/Memory使用情况,查询结果如下所示,查看节点下所有pod的资源使用情况。
kubectl get --raw "/api/v1/nodes/nodeName/proxy/metrics/resource",通过调用get请求获取资源指标值。从这可以看到Metrics-server的本质是:将从kubelet中收集到数据转换成metrices.k8s.io的api返回值。故上面通过调用get请求就获取到结果
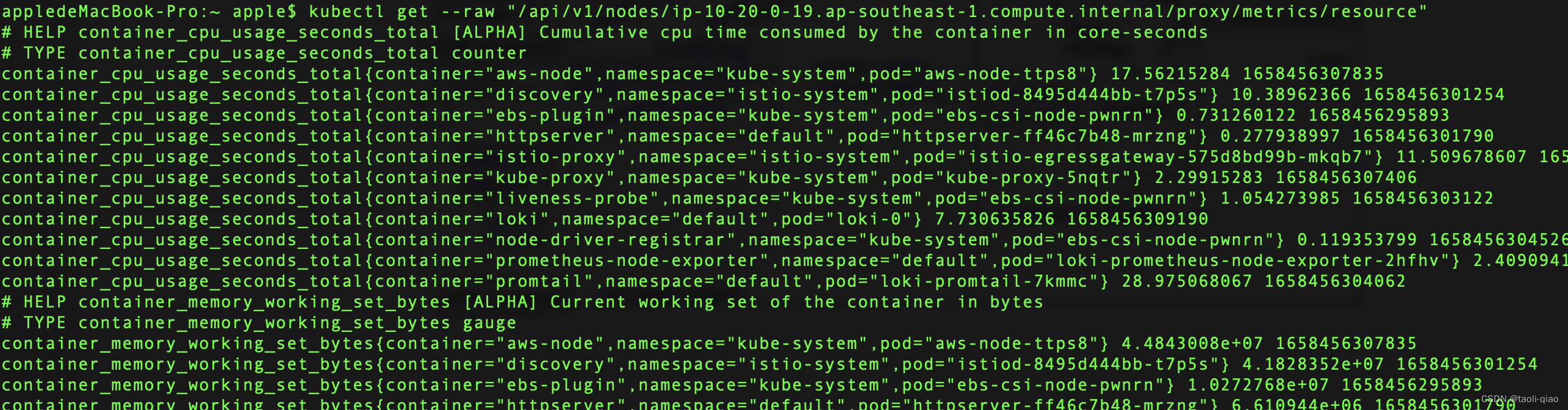
查看某个节点或者pod的资源使用情况,kubectl top node/pod
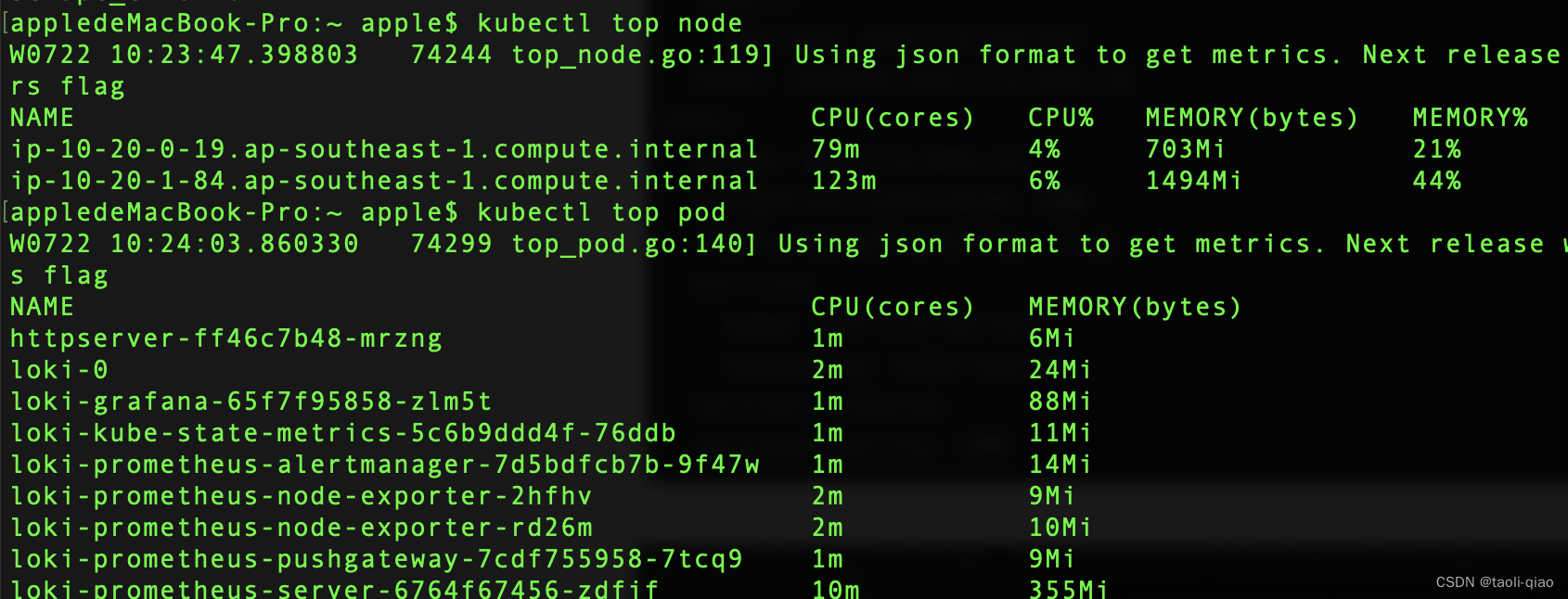
上面介绍了metrics-server,接下来继续看HPA对象。HPA对象定义指标时,分两个类型,Resource类型指标和Pods类型指标。Resource指标从使用占比上进行定义,Pods类型指标从平均使用情况进行定义。资源类的指标直接在HPA对象中指定即可,Pod类型的指标一般用于自定义指标,如果完整的指定和收集自定义指标值以及基于自定义指标值进行横向扩展,可参考这个例子。
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
-----
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: httpserver
namespace: httpserver
spec:
minReplicas: 1
maxReplicas: 1000
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: httpserver
metrics:
- type: Pods
pods:
metric:
name: httpserver_requests_qps
target:
averageValue: 50
type: AverageValue下面通过实际例子演示如果通过定义HPA实现横向扩缩容。下面这个例子创建了一个php的应用,然后定义了HPA对象,然后对应用不断请求,消耗cpu,观察pod是否自动进行的横向扩展。具体的yaml文件内容如下所示:php应用的部署文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: cncamp/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apacheHPA对象定义文件,这里定义如果CPU使用率大于50%,那么就进行扩容。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50创建上面的对象,并模拟对服务进行cpu消耗,并观察pod的资源情况,这里需要注意在模拟cpu消耗时,访问创建php-apache服务是通过域名访问的,所以需要在etc/hosts文件里面配置php-apache service的clusterIP php-apache信息,否则域名访问不通。
kubectl run podname --image=y --command 用于通过命令方式创建pod。
kubectl create -f php-apache.yaml
kubectl create -f hpav.yaml
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
watch kubectl top pods可以看到执行脚本后,一直在访问php-apache服务消耗CPU。

观察php-apache服务的资源使用情况,pod的cpu使用率达到500m,即已经打到resource.limit的量。如果继续消耗cpu,会自动扩容。
![]()
可看到pod数量由一个变成了多个。

关闭消耗cpu资源的pod后,php-apache应用的pod数量从多个重新变回成一个。 上面通过例子演示了pod的自动增加和减少,那么增加和减少的pod个数是如何计算的呢?通过官网查看可以知道具体计算公式是:期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
例如,如果当前指标值为 200m,而期望值为 100m,则副本数将加倍, 因为 200.0 / 100.0 == 2.0 如果当前值为 50m,则副本数将减半, 因为 50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1), 则控制平面会跳过扩缩操作。另外,为了阔缩容更加平滑,还可以指定阔缩容的策略,例如阔缩容时间,增加或者减少的最大pod个数等。
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60为了减少指标波动带来了频繁增减pod,还可以指定稳定时间窗口,如下所示,当显示目标应该缩容时,会考虑过去5分钟所有的期望状态值。
behavior:
scaleDown:
stabilizationWindowSeconds: 300 上面介绍了HPA的理论,以及通过实际例子演示了HPV工作过程。实际项目中,还需要考虑的点是:基于指标的横向扩展有滞后效应,如果是对于会发生突发流量的应用(例如支持秒杀的应用),还需要在HPA的基础能力上增加其他能力才行。滞后的原因主要有以下几方面,如果应用启动时间很长是制约因素,那么可以优化应用启动时间来降低滞后时间
- HPA采用定期执行策略收集资源使用指标
- HPA控制Deployment进行扩容的时间
- Pod调度,运行时启动挂载存储和网络的时间
- 应用启动到服务就绪的时间
前面介绍了HPV,接着再来看看纵向扩展VPA[Vertical Pod Autoscaler].因为VPA还不是成熟的方案,在生产上很少使用,故这里只做简要介绍。以下是VPA的架构图
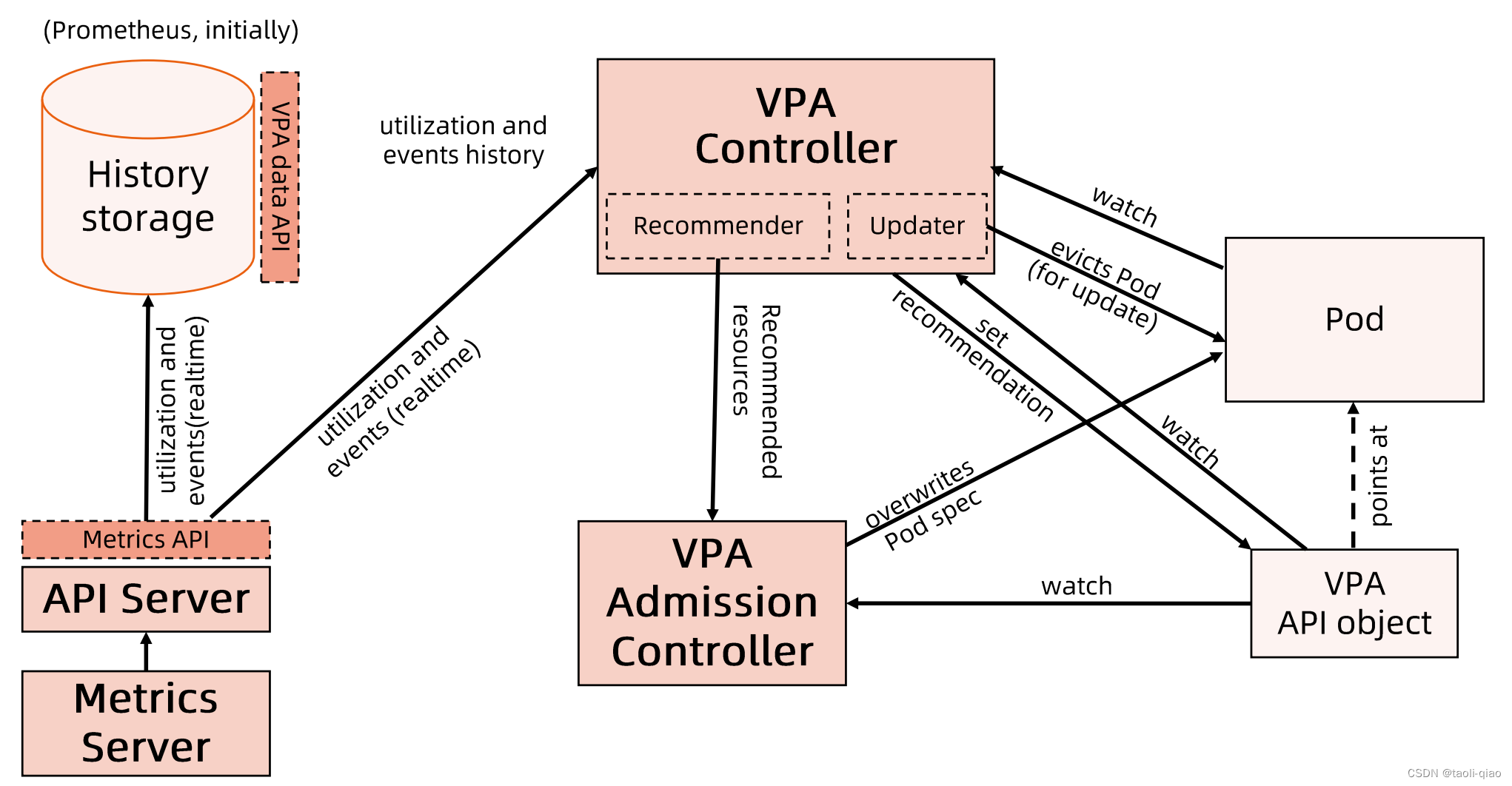
VPA Recommender:监视所有Pod,不断为他们计算新的推荐资源,并将推进值存储到VPA对象中。
VPA Adminssion Controller:所有Pod创建请求都通过VPA Adminssion Controller。
VPA Updater:负责Pod实时更新组件,如果Pod在“Auto”模式下使用VPA,则Updater可以决定使用推荐器资源对其进行更新。
History Storage:是一个存储组件(如Prometheus),存储资源使用情况数据信息。
以下是VPA工作原理图,当需要纵向扩展时,会删除旧的pod,创建新的pod。
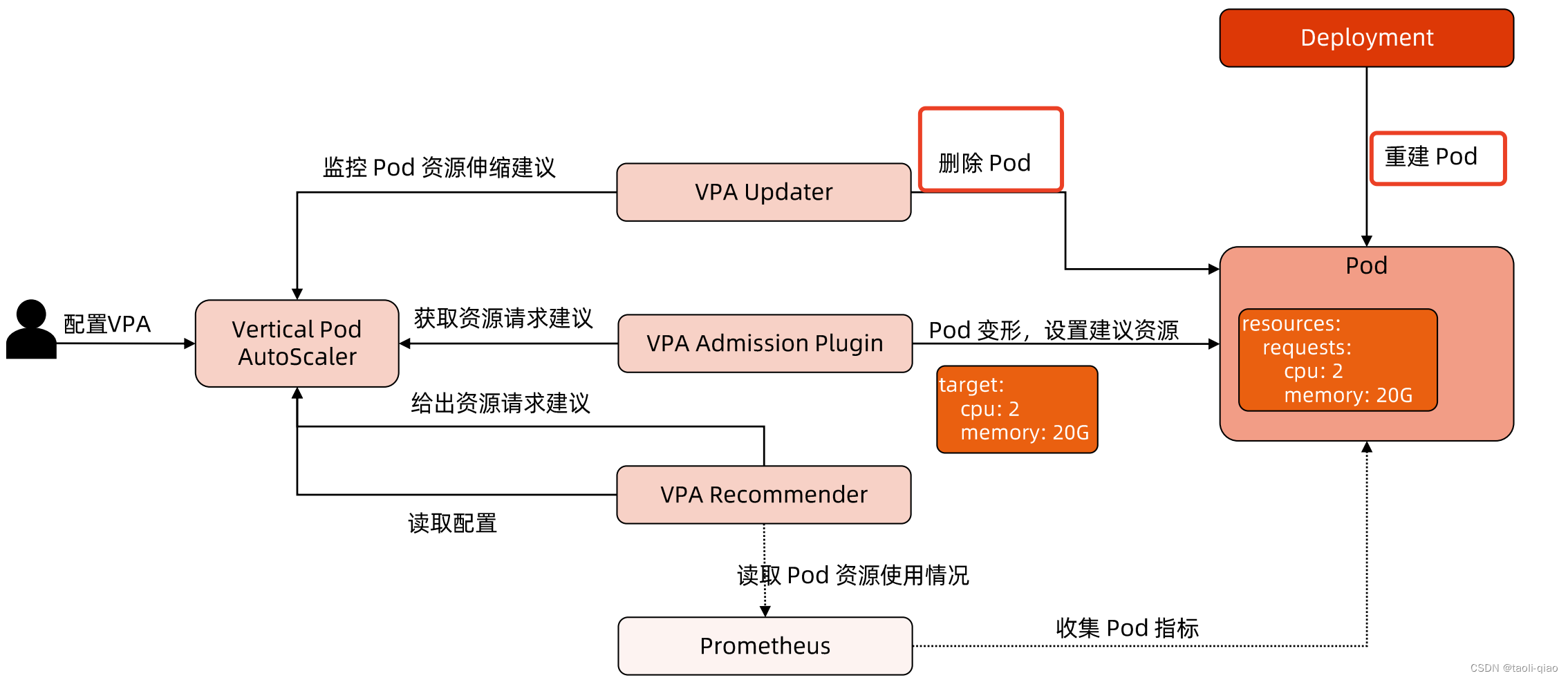
下面通过一个实际例子来演示VPA工作过程,首先安装VPA。
```sh
git clone https://github.com/kubernetes/autoscaler.git
```
### Install vpa
```sh
cd autoscaler/vertical-pod-autoscaler
./hack/vpa-up.sh
```创建Pod,Pod里面启动while循环,不断消耗资源,创建VPA对象,查看Pod对象信息,看看Pod是否被纵向扩展。
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:
name: hamster-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: hamster
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 50Mi
maxAllowed:
cpu: 1
memory: 500Mi
controlledResources: ["cpu", "memory"]
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hamster
spec:
selector:
matchLabels:
app: hamster
replicas: 2
template:
metadata:
labels:
app: hamster
spec:
securityContext:
runAsNonRoot: true
runAsUser: 65534 # nobody
containers:
- name: hamster
image: k8s.gcr.io/ubuntu-slim:0.1
resources:
requests:
cpu: 100m
memory: 50Mi
command: ["/bin/sh"]
args:
- "-c"
- "while true; do timeout 0.5s yes >/dev/null; sleep 0.5s; done" 前面提到VPA还处于实验阶段,成熟度不足,具体不足如下所示:
1.更新正在运行的Pod资源配置是VPA的一项实验性功能,会导致Pod的重建的重启,而且Pod可能被调度到其他节点上。
2.VPA不会驱逐没有在副本控制器管理下的Pod。
3.目前VPA不能和监控CPU和内存度量的Horizontal Pod Autoscaler(HPA)同时运行,除非HPA只监控其他定制化的外部资源度量
4.VPA使用admission webhook作为其准入控制器,如果集群中有其他admission webhook,需要确保他们不会和VPA发生冲突。
5.VPA会处理出现的绝大多数OOM事件,但不保证所有场景都有效
6.VPA的性能还没有在大型集群中测试过
7.VPA对Pod资源requests的修改值可能超过实际资源的上限,例如节点资源上限,从而造成Pod处于Pending状态无法被调度。
以上就是对HPA和VPA的理解和演示。
















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











