






以下为官方活动的学习笔记兼打卡记录,大部分内容来自活动资料,稍有删改,内含跳转至MindSpore文档的超链接,可作为字典查询。
一、函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter
1.1 函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
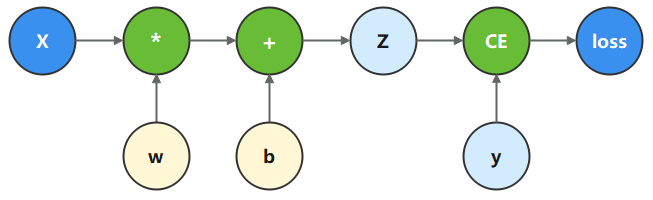
在这个模型中,
x
x
x为输入,
y
y
y为正确值,
w
w
w和
b
b
b是我们需要优化的参数,CE为交叉熵函数,binary_cross_entropy_with_logits 。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y)
return loss
loss = function(x, y, w, b)
1.2 微分函数与自动计算
为了优化模型参数,需要求参数对loss的导数:
∂
loss
∂
w
\frac{\partial \operatorname{loss}}{\partial w}
∂w∂loss和
∂
loss
∂
b
\frac{\partial \operatorname{loss}}{\partial b}
∂b∂loss,此时我们调用mindspore.grad函数,来获得function的微分函数。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数,以下代码输出grad_fn()函数。
grad_fn = mindspore.grad(function, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
grad_fn()函数可以计算
∂
loss
∂
w
\frac{\partial \operatorname{loss}}{\partial w}
∂w∂loss和
∂
loss
∂
b
\frac{\partial \operatorname{loss}}{\partial b}
∂b∂loss。
> (Tensor(shape=[5, 3], dtype=Float32, value=
[[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]))
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。- 由于我们对
w
w
w和
b
b
b求导,因此配置其在
function入参对应的位置(2, 3)。
1.3 Stop Gradient
当计算loss的函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y)
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
> (Tensor(shape=[5, 3], dtype=Float32, value=
[[ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00],
[ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00],
[ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00],
[ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00],
[ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00]]), Tensor(shape=[3], dtype=Float32, value= [ 1.12023902e+00, 1.02320218e+00, 1.11367810e+00]))
可以看到求得
w
w
w、
b
b
b对应的梯度值发生了变化。此时如果想要屏蔽掉z对梯度的影响,即仍只求参数对loss的导数,可以使用ops.stop_gradient接口,将梯度在此处截断。我们将function实现加入stop_gradient,并执行。
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y)
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
> (Tensor(shape=[5, 3], dtype=Float32, value=
[[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]))
可以看到,求得 𝑤、 𝑏对应的梯度值与初始function求得的梯度值一致。
1.4 神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的
w
w
w、
b
b
b作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()
# Define forward function
'''
由于需要使用函数式自动微分,需要将神经网络和损失函数的调用封装为一个前向计算函数。
'''
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
完成后,我们使用value_and_grad接口获得微分函数,用于计算梯度。
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
> (Tensor(shape=[5, 3], dtype=Float32, value=
[[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01],
[ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]]), Tensor(shape=[3], dtype=Float32, value= [ 1.20238990e-01, 2.32021883e-02, 1.13678105e-01]))
执行微分函数,可以看到梯度值和前文function求得的梯度值一致。
二、模型训练
模型训练一般分为四个步骤:
- 构建数据集。
- 定义神经网络模型。
- 定义超参、损失函数及优化器。
- 输入数据集进行训练与评估。
现在我们有了数据集和模型后,可以进行模型的训练与评估。
2.1 构建数据集
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
def datapipe(path, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = MnistDataset(path)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)
2.2 定义模型结构
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
2.3 定义超参数、损失函数、优化器
epochs = 3
batch_size = 64
learning_rate = 1e-2
loss_fn = nn.CrossEntropyLoss()
'''
我们通过model.trainable_params()方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
'''
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
2.4 训练与评估
每轮执行训练时包括两个步骤:
- 训练:迭代训练数据集,并尝试收敛到最佳参数。
- 验证/测试:迭代测试数据集,以检查模型性能是否提升。
接下来我们定义用于训练的train_loop函数和用于测试的test_loop函数。
使用函数式自动微分,需先定义正向函数forward_fn,使用value_and_grad获得微分函数grad_fn。然后,我们将微分函数和优化器的执行封装为train_step函数,接下来循环迭代数据集进行训练即可。
# Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# Get gradient function
'''
has_aux参数控制logits返回值不影响微分计算,同时可以返回logits
'''
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
'''
grad_fn()返回的参数如下:
1、给定函数的返回值,此处为forward_fn的返回值loss,logits
2、给定函数的梯度
优化器根据梯度选择学习率,需要传入梯度。
'''
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_loop(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
def test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(model, train_dataset)
test_loop(model, test_dataset, loss_fn)
print("Done!")
Epoch 1
loss: 2.302806 [ 0/938]
loss: 2.285086 [100/938]
loss: 2.264712 [200/938]
loss: 2.174010 [300/938]
loss: 1.931853 [400/938]
loss: 1.340721 [500/938]
loss: 0.953515 [600/938]
loss: 0.756860 [700/938]
loss: 0.756263 [800/938]
loss: 0.463846 [900/938]
Test:
Accuracy: 84.7%, Avg loss: 0.527155
Epoch 2
loss: 0.479126 [ 0/938]
loss: 0.437443 [100/938]
loss: 0.685504 [200/938]
loss: 0.395121 [300/938]
loss: 0.550566 [400/938]
loss: 0.459457 [500/938]
loss: 0.293049 [600/938]
loss: 0.422102 [700/938]
loss: 0.333153 [800/938]
loss: 0.412182 [900/938]
Test:
Accuracy: 90.5%, Avg loss: 0.335083
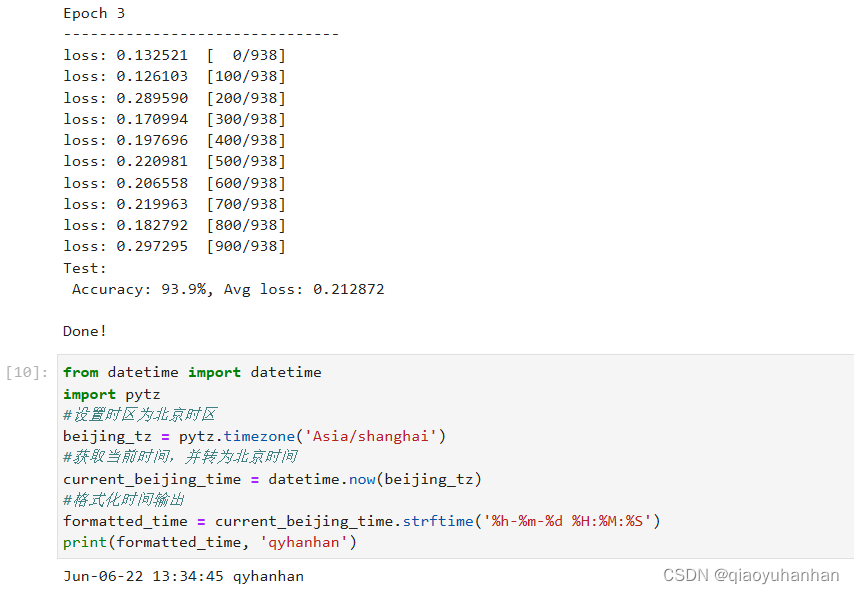
Epoch 3
loss: 0.207366 [ 0/938]
loss: 0.343559 [100/938]
loss: 0.391145 [200/938]
loss: 0.317566 [300/938]
loss: 0.200746 [400/938]
loss: 0.445798 [500/938]
loss: 0.603720 [600/938]
loss: 0.170811 [700/938]
loss: 0.411954 [800/938]
loss: 0.315902 [900/938]
Test:
Accuracy: 91.9%, Avg loss: 0.279034
Done!
学习记录
1 函数式自动微分打卡
2 模型训练















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









