






一、项目背景
豆瓣是中国最大的影视评分社区之一,豆瓣电影TOP250收录了用户评价最好的250部电影。本项目使用Python对其进行数据分析与可视化,从而洞察评分、类型、国家等信息的分布特点。
⸻
二、数据来源
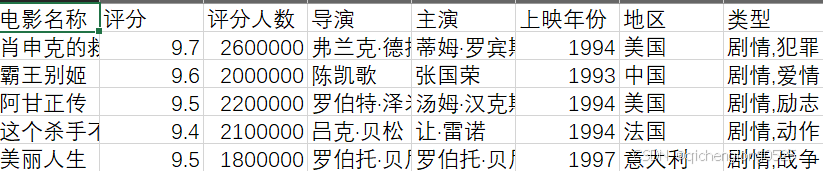
数据来源于网络爬虫采集的豆瓣TOP250信息,包含字段:
• 电影名称、评分、评分人数、导演、主演、上映年份、国家/地区、电影类型等。
(如需要我可提供csv文件)
⸻
三、分析目标
1. 评分分布情况
2. 最常见的电影类型
3. 不同国家/地区的电影数量分布
4. 不同年份的电影数量分布
5. 哪些导演上榜次数最多
6. 可视化图表展示上述信息
四、关键代码与可视化展示
1. 导入库与读取数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('douban_top250.csv') # 假设我们有这个文件2. 评分分布直方图
plt.figure(figsize=(8,5))
sns.histplot(df['评分'], bins=10, kde=True, color='skyblue')
plt.title('豆瓣TOP250评分分布')
plt.xlabel('评分')
plt.ylabel('电影数量')
plt.show()3. 最常见电影类型词云
from wordcloud import WordCloud
all_genres = ','.join(df['类型'].dropna())
wc = WordCloud(font_path='simhei.ttf', background_color='white').generate(all_genres)
plt.figure(figsize=(10,6))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.title('电影类型词云')
plt.show()4. 上榜最多的导演
top_directors = df['导演'].value_counts().head(10)
sns.barplot(x=top_directors.values, y=top_directors.index, palette='Set2')
plt.title('上榜最多的导演 Top 10')
plt.xlabel('电影数量')
plt.show()5. 国家分布饼图
countries = df['地区'].value_counts().head(5)
plt.pie(countries, labels=countries.index, autopct='%1.1f%%', startangle=140)
plt.title('主要国家地区分布')
plt.show()用例
五、AI 工具使用说明
本案例整体分析思路、代码框架、可视化设计均在 ChatGPT 协助下完成。AI 工具主要用于:
• 拟定分析目标
• 代码生成与调试建议
• 可视化图表优化
• 博文内容结构设计
⸻
六、总结与反思
本案例以可视化的方式清晰展现了豆瓣TOP250电影的评分结构、导演集中度、类型和国家的多样性等特征。未来可扩展:
• 增加 IMDb 数据对比
• 分析评分人数与评分的关系
• 建立推荐模型等。

















 5110
5110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









