







需求
现在我们有一组从2006年到2016年1000部最流行的电影数据,需要进行分析
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
分析方向为:
问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
问题4:如果我们希望统计评分最高的前10名导演,应该如何处理数据?
问题5:计算出每个导演票房最高的5部电影的总票房
# 导包
import pandas as pd
import numpy as np
# 读取数据
movies=pd.read_csv("IMDB-Movie-Data.csv")
movies.head()

问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
# 分析:评分的平均分:对评分列(Rating)进行分析,聚合函数mean()求平均数
movies.Rating.mean()
# 分析:导演的人数:对导演列(Director)进行分析,去重.unique()后,求数量
# 注意:movies.Director返回值为pandas.core.series.Series,无count方法,需要使用shape[0]求数量;导演的戏不止一部,一定要去重
movies.Director.unique().shape[0] #正确方法
movies.Director.count() #错误方法
问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
分析:想看分布情况,画图最好,可以使用直方图,pandas封装了matplotlib,可以直接画图,但是想画好看的,还是需要导入matplotlib
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6),dpi=100) #创建画布
plt.hist(movies.Rating,bins=20) #确定使用直方图,划分为20个柱子
plt.grid() #设置网格线
xticks=np.linspace(movies.Rating.min(),movies.Rating.max(),21)
plt.xticks(xticks) #自定义设置x轴的刻度(因为网格线是默认按照刻度划分的)
plt.show()

问题3:对于这一组电影数据,如果我们希望统计电影分类(Genre)的情况,应该如何处理数据?
分析:对电影分类列(Genre)进行分析,每部电影不是只属于一类,所以需要先对每部电影的类别进行单一化,以类别为列索引,以电影索引为行索引,只要属于该类电影,位置则为1,否则为0
需要先创建一个DateFrame,所有位置都为0,shape(电影数据.shape[0],类别.shape[0])
# 1. 获取所有电影的不重复类别列表
# 方法一:
tmp = []
for genres in movies.Genre:
#print(genres.split(',')) #genres 为每一部电影的所有类别,(.spilt()返回值为:‘,’分割的字符串组成的列表)
tmp.extend(genres.split(',')) # 循环结束后的tmp为所有的类别,但是由重复的(.extend() 指在原列表添加新元素)
print(set(tmp)) #set() 是集合,目的是可以获得去重后的列表
# 方法二:列表生成式
tmp=[j for genres in movies.Genre for j in genres.split(',')]
genres = np.unique(tmp) #将所有类别去重,返回array
#2.生成值都是0的数组
zeros=np.zeros(shape=(movies.shape[0],genres.shape[0]))
zeros

# 3.将数组转为DateFrame(行索引为电影的索引, 列索引为的不重复类别列表)
df=pd.DataFrame(zeros,index=movies.index,columns=genres)
df

# 4.遍历所有电影, 如果这部电影, 属于那个类别, 就在对应位置标记为1
for i in movies.index:
movie=movies.loc[i]
genre=movie.Genre.split(',') #返回的是每一部电影的类别列表
df.loc[i, genre] = 1 #只要是坐标为(i,genre)的位置都为1
df

#5.计算每一列的和,即为该类型电影的数量
df.sum()
问题4:如果我们希望统计评分最高的前10名导演,应该如何处理数据?
分析:按照导演进行分组movies.groupby(by=‘Director’),对每一组中的评分(Rating)求平均值(.mean()),对结果按照评分(Rating)进行排序(.sort_values(by=‘Rating’,ascending=False)),取前10(.head(10))
movies.groupby(by='Director')[['Rating']].mean().sort_values(by='Rating',ascending=False).head(10)

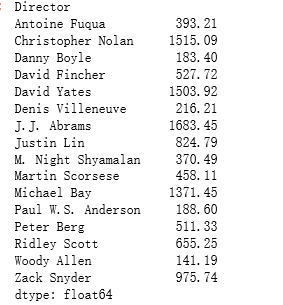
问题5:计算出每个导演票房最高的5部电影的总票房
分析:每个导演(按照导演Director进行分组),对每个组进行排序,选出每组前5不电影,对5部电影进行求和
注意:因为是想对每个组进行一次操作,需要提前定义函数,避免重复代码
坑:票房列(Revenue (Millions))有空值
movies.info()

# 1.去掉空值
data=movies.dropna()
# 2.定义函数,传入2个参数(每个分组数据的df;选取的电影部数(本需求为n=5,方便后续进行更改部数))
def topn(df,n=5):
if df.shape[0]<n: #如该分组少于5,返回None
return None
else:
#对每个组按票房降序排序,取出前n行的票房,找出'Revenue (Millions)'列,进行求和
return df.sort_values(by='Revenue (Millions)',ascending=False)[:n]['Revenue (Millions)'].sum()
#调用函数:按照导演分组,然后对每组数据应用函数topn函数,最终结果去除nan(即除去电影部数少于5的数据)
data.groupby('Director').apply(topn).dropna()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









