






青瓷引擎的成长
青瓷引擎自2015年4月项目启动开始,7月首次亮相2015年ChinaJoy,便得到业界的极大关注,随后开启限量测试,收到数百个开发者团队的试用申请及反馈,期间经历了18个内测版本,完成200多个范例和文档,完善了用户手册和API文档,7个团队的深度使用开发,11个完整游戏,实现了主流浏览器和机型适配,并且对性能做了进一步优化。

青瓷引擎是什么?
青瓷引擎是一套开源免费的JavaScript游戏引擎类库,其基于开源免费的Phaser游戏引擎,并提供了一套完全基于浏览器的跨平台集成式HTML5游戏编辑器。

采用青瓷引擎,开发HTML5游戏和传统Web网页开发一样,使用任何你喜欢的编辑器,使用任何你喜欢的浏览器,利用JavaScript语言和所有先进的Web开发工具,让青瓷引擎处理底层技术的复杂性,你只需要关注最重要的事情:做游戏!
青瓷引擎的功能与特点
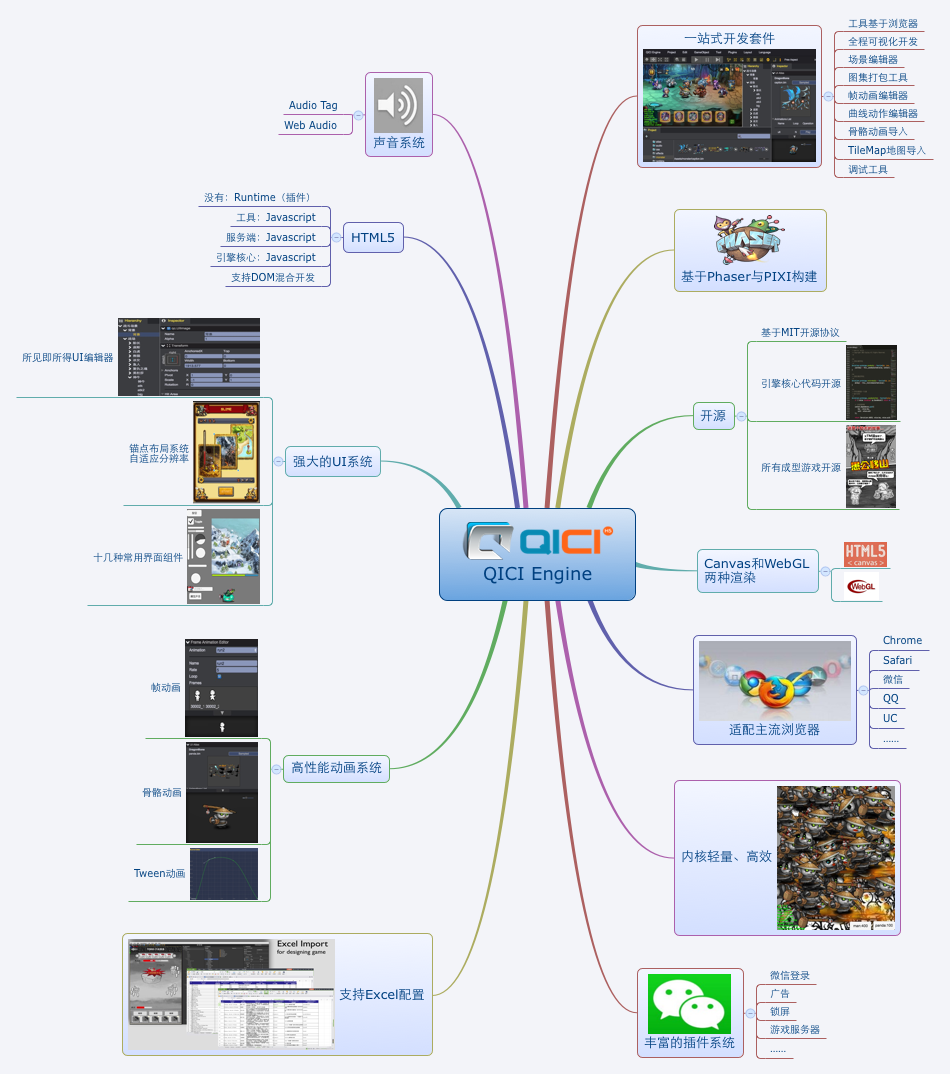
青瓷引擎特点
- 游戏无需浏览器安装额外插件,适应性更广,更利于传播
- 重新定义了HTML5游戏的开发工作流,开发、调试尽在浏览器内
- 面向组件式编程,支持组件热拔插,方便扩展维护
- 强大的可视化编辑功能,让设计不再是凭空想象
- 先进的UI界面布局规则,使得屏幕适配更加简单
- 为国内手机浏览器进行了优化,减少非标准适配的烦恼
- 高效的渲染底层,自适应WebGl和Canvas两种模式
- 丰富的底层核心功能,涵盖绝大部分游戏开发需求
- 不断丰富的插件库,让游戏开发更加便捷、简单
青瓷引擎功能
- 基于浏览器的编辑器
- 所见即所得的实时调试功能
- 网络资源管理,支持预加载、动态加载
- 时间调度系统,可控制帧率,游戏速度等
- 自适应Web Audio和Audio Tag,适配性更高的声音管理功能
- 提供了表格、拉条、滚动视图等丰富的界面控件
- 提供了游戏与HTML元素混合处理模式
- 提供基于Rect Tranform的UI布局套件
- 支持WebFont和BitmapFont等字体系统
- 优化文字对视网膜设备的适配
- 整合图集打包,帧动画编辑功能
- 高性能骨骼动画渲染
- 支持多种Filter着色器渲染
- 支持Excel数据导入功能
- 支持Tilemap的地图导入,并优化刷新性能
- 强大的可视化Tween曲线动画编辑功能
- 编辑器菜单和属性面板支持可自定义扩展功能
- 可扩展插件功能,提供物理、锁屏、微信接口和服务端通讯等内置插件
青瓷引擎的部分游戏(点击图片可体验游戏)
《神奇的六边形》(《神奇的六边形》完整教程)

《蛇精病》

《跳跃的方块》

《2187》

引擎下载与文档
引擎官网:www.zuoyouxi.com
引擎技术讨论Q群:214396286














 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









