标签:
mahout学习mahout | 发表时间:2014-04-27 10:56 | 作者:wl101yjx
分享到:
出处:http://blog.csdn.net
一、Mahout简介
查了Mahout的中文意思——驭象的人,再看看Mahout的logo,好吧,想和小黄象happy地玩耍,得顺便陪陪这位驭象人耍耍了...
附logo:
步入正文啦:
Mahout 是一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等。Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能。
在Mahout实现的机器学习算法:
算法类
算法名
中文名
分类算法
Logistic Regression
逻辑回归
Bayesian
贝叶斯
SVM
支持向量机
Perceptron
感知器算法
Neural Network
神经网络
Random Forests
随机森林
Restricted Boltzmann Machines
有限波尔兹曼机
聚类算法
Canopy Clustering
Canopy聚类
K-means Clustering
K均值算法
Fuzzy K-means
模糊K均值
Expectation Maximization
EM聚类(期望最大化聚类)
Mean Shift Clustering
均值漂移聚类
Hierarchical Clustering
层次聚类
Dirichlet Process Clustering
狄里克雷过程聚类
Latent Dirichlet Allocation
LDA聚类
Spectral Clustering
谱聚类
关联规则挖掘
Parallel FP Growth Algorithm
并行FP Growth算法
回归
Locally Weighted Linear Regression
局部加权线性回归
降维/维约简
Singular Value Decomposition
奇异值分解
Principal Components Analysis
主成分分析
Independent Component Analysis
独立成分分析
Gaussian Discriminative Analysis
高斯判别分析
进化算法
并行化了Watchmaker框架
推荐/协同过滤
Non-distributed recommenders
Taste(UserCF, ItemCF, SlopeOne)
Distributed Recommenders
ItemCF
向量相似度计算
RowSimilarityJob
计算列间相似度
VectorDistanceJob
计算向量间距离
非Map-Reduce算法
Hidden Markov Models
隐马尔科夫模型
集合方法扩展
Collections
扩展了java的Collections类
二、Mahout安装、配置
http://archive.apache.org/dist/mahout/
二、解压
tar -zxvf mahout-distribution-0.9.tar.gz
三、配置环境变量
3.1、配置Mahout环境变量
# set mahout environment
export MAHOUT_HOME=/home/yujianxin/mahout/mahout-distribution-0.9
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
3.2、配置Mahout所需的Hadoop环境变量
# set hadoop environment
export HADOOP_HOME=/home/yujianxin/hadoop/hadoop-1.1.2
export HADOOP_CONF_DIR=$HADOOP_HOME/conf
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=not_null
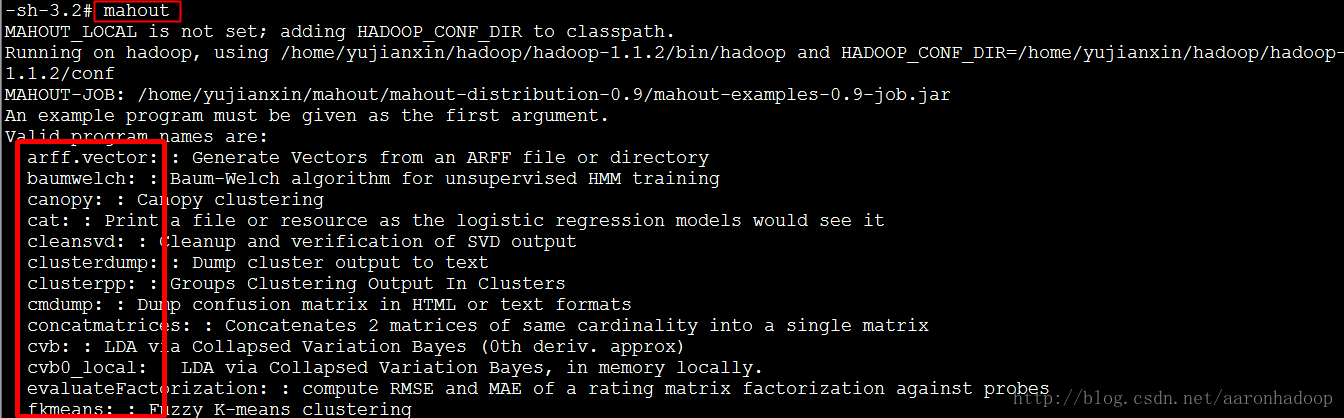
四、验证Mahout是否安装成功
执行命令mahout。若列出一些算法,则成功,如图:
五、使用Mahout 之入门级使用
5.1、启动Hadoop
5.2、下载测试数据
5.3、上传测试数据
hadoop fs -put synthetic_control.data /user/root/testdata
5.4 使用Mahout中的kmeans聚类算法,执行命令:
mahout -core org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
花费9分钟左右完成聚类 。
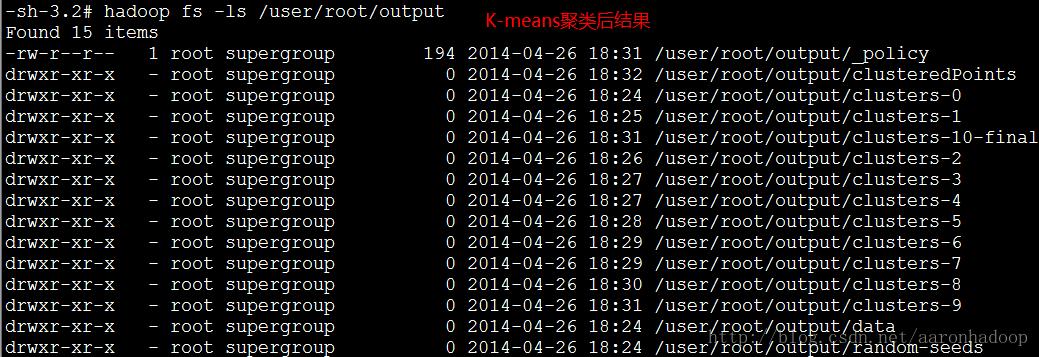
5.5 查看聚类结果
执行hadoop fs -ls /user/root/output,查看聚类结果。
齐活,收工。Mahout继续学习中......
作者:wl101yjx 发表于2014-4-27 10:56:05
原文链接
相关 [mahout 学习 mahout] 推荐:
- - ITeye博客
使用命令:mahout -h. 在Mahout实现的机器学习算法见下表:. EM聚类(期望最大化聚类). 并行FP Growth算法. 并行化了Watchmaker框架. 非Map-Reduce算法. 扩展了java的Collections类. Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能. 已有 0 人发表留言,猛击->> 这里<<-参与讨论. —软件人才免语言低担保 赴美带薪读研.
- - 开源中国社区最新新闻
Apache Mahout 0.8 发布了,Apache Mahout 是 Apache Software Foundation (ASF) 开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在 Apache 在许可下免费使用. 该项目已经发展到了它的最二个年头,目前只有一个公共发行版. Mahout 包含许多实现,包括集群、分类、CP 和进化程序. 此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中. 该版本主要是 1.0 版本发布之前的代码清理. - Numerous performance improvements to Vector and Matrix implementations, API's and their iterators (see also MAHOUT-1192, MAHOUT-1202).
- - CSDN博客云计算推荐文章
查了Mahout的中文意思——驭象的人,再看看Mahout的logo,好吧,想和小黄象happy地玩耍,得顺便陪陪这位驭象人耍耍了.... (就是他,骑在象头上的那个Mahout). Mahout 是一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等. Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能. 在Mahout实现的机器学习算法:. 并行化了Watchmaker框架. 非Map-Reduce算法. 扩展了java的Collections类.
- - ITeye博客
Apache Mahout 是 ApacheSoftware Foundation (ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序,并且,在 Mahout 的最近版本中还加入了对Apache Hadoop 的支持,使这些算法可以更高效的运行在云计算环境中. 在Mahout实现的机器学习算法见下表:. 并行化了Watchmaker框架. 扩展了java的Collections类. 已有 0 人发表留言,猛击->> 这里<<-参与讨论. —软件人才免语言低担保 赴美带薪读研.
- - 互联网 - ITeye博客
Mahout 是机器学习和数据挖掘的一个分布式框架,区别于其他的开源数据挖掘软件,它是基于hadoop之上的; 所以hadoop的优势就是Mahout的优势. http://mahout.apache.org/ 上说的Scalable就是指hadoop的可扩展性. Mahout用map-reduce实现了部分数据挖掘算法,解决了并行挖掘的问题. 这里说的“解决”是一个初步的概念,很多算法由于各种原因是无法用map-reduce并行实现的. http://www.apache.org/dyn/closer.cgi/mahout/ ), 解压;. 在MAHOUT_HOME/bin目录下,在mahout中添加:.
- - CSDN博客云计算推荐文章
一 下载mahout并解压. JAVA_HOME mahout运行需指定jdk的目录. MAHOUT_JAVA_HOME指定此变量可覆盖JAVA_HOME值. HADOOP_HOME 如果配置,则在hadoop分布式平台上运行,否则单机运行. HADOOP_CONF_DIR指定hadoop的配置文件目录. MAHOUT_LOCAL 如果此变量值丌为空,则单机运行mahout. MAHOUT_CONF_DIR mahout配置文件的路径,默认值是$MAHOUT_HOME/src/conf. MAHOUT_HEAPSIZE mahout运行时可用的最大heap大小. 环境变量的修改,在该文件最后面添加.
- - CSDN博客云计算推荐文章
mahout 实用教程 (一). 本文力求把mahout从使用的角度为读者建立一个框架,为后续的使用打下基础. 本文为原创文章转载请注明原网址 http://blog.csdn.net/comaple,谢谢. 下面首先给出源代码svn地址以及用于测试的公共数据集,大家可以下载并测试. mahout svn仓库地址: http://svn.apache.org/repos/asf/mahout/trunk. movie length 数据地址:http://www.grouplens.org/system/files/ml-100k.zip. 1. mahout简介. 2. 应用于推荐系统(item-based/user-based/slopone).
- - 小鸥的博客
Mahout推荐算法分为以下几大类. 2.相近的用户定义与数量. 2.用户数较少时计算速度快. 1.基于item的相似度. 1.item较少时就算速度更快. 2.当item的外部概念易于理解和获得是非常有用. 1基于SlopeOne算法(打分差异规则). 当item数目十分少了也很有效. 需要限制diffs的存储数目否则内存增长太快. 基于支持向量机(item的特征以向量表示,每个维度的评价值). 类似于GenericUserBasedRecommender 中基于相似用户的实现(基于相似的item). 与GenericItemBasedRecommender 的主要区别是权重方式计算的不同(but, the weights are not the results of some similarity metric.
- - CSDN博客推荐文章
Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序. 经典算法包括聚类、分类、协同过滤、进化编程等等,并且,在 Mahout 中还加入了对Apache Hadoop的支持,使这些算法可以更高效的运行在云计算环境中. 2.1 JDK1.6.0_21的安装. jdk的下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html我所用的版本是jdk-6u21-linux-i586.bin.
- -
Mahout支持2种 M/R 的jobs实现itemBase的协同过滤. 下面我们对RecommenderJob进行分析,版本是mahout-distribution-0.7. 源码包位置:org.apache.mahout.cf.taste.hadoop.item.RecommenderJob. RecommenderJob前几个阶段和ItemSimilarityJob是一样的,不过ItemSimilarityJob 计算出item的相似度矩阵就结束了,而RecommenderJob 会继续使用相似度矩阵,对每个user计算出应该推荐给他的top N 个items. RecommenderJob 的输入也是userID, itemID[, preferencevalue]格式的.








 (就是他,骑在象头上的那个Mahout)
(就是他,骑在象头上的那个Mahout) 















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









