






目录
实验环境介绍
阿里云服务器
阿里云服务器 ECS(Elastic Compute Service) 是一种简单高效、处理能力可弹性伸缩的计算服务。帮助您构建更稳定、安全的应用,提升运维效率,降低 IT 成本,使您更专注于核心业务创新。是阿里云提供的性能卓越、稳定可靠、弹性扩展的 laaS(lnfrastructure as a Service) 级别云计算服务。
Mahout
机器学习指研究和构建可以从输人数据中学习的算法。使用机器学习算法基于给定的输人构建模型,用于顶测和决策,而不是仅仅遵照显式的指令或规则执行。机器学习是计算机科学与统计学的一个子领域,与人工智能及优化密切相关。经典的机器学习算法包括决策树学习、关联规则学习、人工神经网络、逻辑规划、支持向量机、聚类、贝叶斯网络、增强学习等。在人们的日常生活中,垃圾邮件过法、光学字符识别、语音识别、搜素引擎以及计算机视觉领城中都离不开机器学习算法的支持。当面临大数据时,经典的机器学习算法无疑需要进行分布式的改进。
Apache Software Foundation 旗下的开源项 目Mahout 是机器学习算法在Hadoop 平台上的开源安现,目前已经包括了经典的机器学习算法的 Hadoop 实现,如分类、聚类、进化算法以及协同过谁等,特别是对协同过滤的支持上,不仅有传统的基于用户和基于项目的推荐算法,还有近来广泛研究和使用的基于矩阵因子分解的推荐算法。使用 Mahout 可以实现通过可伸缩、商业友好的机器学习来构建智能应用程序。Mahout 是机器学习和数据挖掘的一个分布式框架,区别于其他的开源数据挖掘软件,它是基于 Hadoop之上的。
Ubuntu介绍
Ubuntu Linux是由南非人马克·沙特尔沃思(Mark Shuttleworth)创办的基于Debian Linux的操作系统,于2004年10月公布Ubuntu的第一个版本(Ubuntu 4.10“Warty Warthog”)。Ubuntu适用于笔记本电脑、桌面电脑和服务器,特别是为桌面用户提供尽善尽美的使用体验。Ubuntu几乎包含了所有常用的应用软件:文字处理、电子邮件、软件开发工具和Web服务等。用户下载、使用、分享未修改的原版Ubuntu系统,以及到社区获得技术支持,无需支付任何许可费用。
Hadoop
Hadoop 是一个开源的、可运行于大规模集群上的分布式计算平台,它主要包含分布式并行编程模型 MapReduce 和分布式文件系统 HDFS等功能,已经在业内得到广泛的应用借助于 Hadoop,程序员可以轻松地编写分布式并行程序,将其运行于计算机集群上,完成海量数据的存储与处理分析。
Xshell
Xshell 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。除此之外,其还有丰富的外观配色方案以及样式选择。
Winscp
WinSCP是一个Windows环境下使用SSH的开源图形化SFTP客户端。同时支持SCP协议。它的主要功能就是在本地与远程计算机间安全的复制文件。
实验目的
本文基于阿里云服务器搭建分布式Hadoop集群,并运用Hadoop计算Π值。在此基础上安装Mahout数据挖掘平台,并在Mahout 平台上运用K-Means聚类算法。
实验环境
1. 阿里云服务器
2. Ubuntu 22.04
3. Mahout 0.9
Hadoop集群搭建机器配置及局域网IP地址如表1所示:
| 机器 | 配置 | 局域网IP地址 |
|---|---|---|
| master | 1核(vCPU) 2 GiB | ------------------- |
| slave1 | 1核(vCPU) 512 MB | ------------------- |
| slave2 | 1核(vCPU) 512 MB | ------------------- |
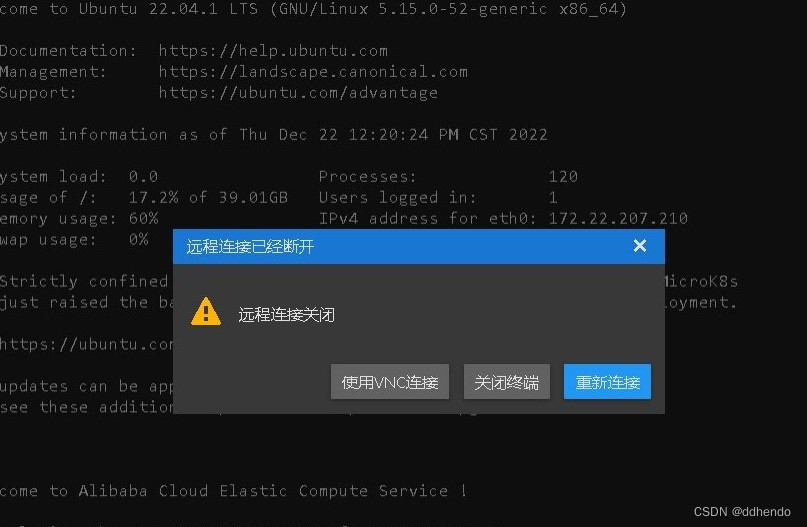
这里需要注意的是尽管阿里云服务器的网页提供远程连接,但如所需要的任务需要花费大量时间时,不建议直接在网页直接远程登陆,在网页上长时间不进行操作时,会强制登出,需要重新输入阿里云服务器的账号密码,强制登出如图2所示,因此可以使用Xshell来连接云服务器,需要注意的是在填写id地址填写的是公网IP地址,具体位置为图1 红色框所示。
Hadoop分布式模式配置
Hadoop拥有多种模式,当 Hadoop 采用分布式模式部署和运行时,存储采用分布式文件系统 HDFS,HDFS 的名称节点和数据节点位于不同机器上。这时,数据就可以分布到多个节点上,不同数据节点上的数据计算可以并行执行,这时的 MapReduce 分布式计算能力才能真正发挥作用。
网络配置
$sudo vim /etc/hostname 执行上面命令后,修改主机名为master。重启系统后,打开终端后
会显示如下内容:
root@master:~#在执行重命名后使用上面相同的命令在另外两个节点修改名字为slave1,slave2,便于区分,不会产生混淆。
执行如下命令打开并修改master节点的/etc/hosts/文件:
$sudo vim /etc/hosts
在host文件中增加如下两条IP地址和主机映射关系,里需要注意的是使用阿里云服务器时,填写主机映射关系时 master 填写的是内网IP 地址.
修改完成后,使用以下命令节点若能互通,则配置成功。
$ssh slave1
$ssh slave2为配置SSH无密码节点登录,在master节点上将master公匙传输到slave1和slave2, 执行如下命令,
$scp ~/.ssh/id_rsa.pub root@cluster1:~/
$scp ~/.ssh/id_rsa.pub root@cluster2:~/Java及Hadoop安装
JDK下载链接 https://www.oracle.com/java/technologies/downloads/
Hadoop下载链接 https://dlcdn.apache.org/hadoop/common/
在本地下载好JDK和Hadoop后分别通过WinSCP上传到云服务器并解压,
解压后需要配置环境变量:
$vim /etc/profile将下面的代码加到后面
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
MAHOUT_JAVA_HOME=/usr/local/jdk
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopEsc回车后按:wq保存,接着使我们的配置生效的话使用如下命令
source /etc/profile执行以下命令,如图6所示则环境变量生效。
java -version
进入/usr/local/hadoop/etc/hadoop目录,查看所包含的文件
在/usr/local/hadoop/etc/hadoop下修改core-site.xml、hdfs-site.xml、mapred-stie.xml、yarn-site.xml文件,具体代码可参考《大数据基础编程、实验和案例教程》72页。
上述文件配置完成后,将master节点的/usr/local/hadoop文件夹复制到各节点上。
格式化NameNode,执行以下命令启动集群:
cd /usr/local/hadoop
bin/hdfs namenode-format
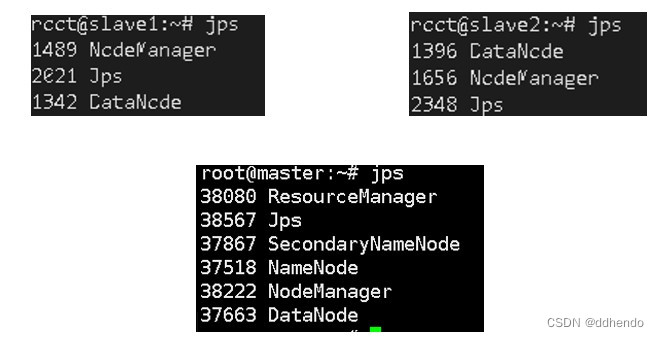
sbin/start-all.sh此时Hadoop集群已经启动完毕,在master、slave1、slave2三个节点运行命令jps查看运行结果,如图8所示:
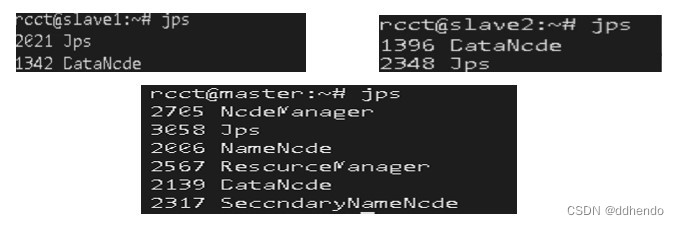
NodeManger缺失解决
此时发现slave1和slave2节点缺少NodeManager,通过上网搜索相关解决方法,浏览大多数出现这种情况都是系统的内存太小所引起,且在后文使用Hadoop集群执行Π值计算时,节点的CPU使用率接近100%,如图9所示:
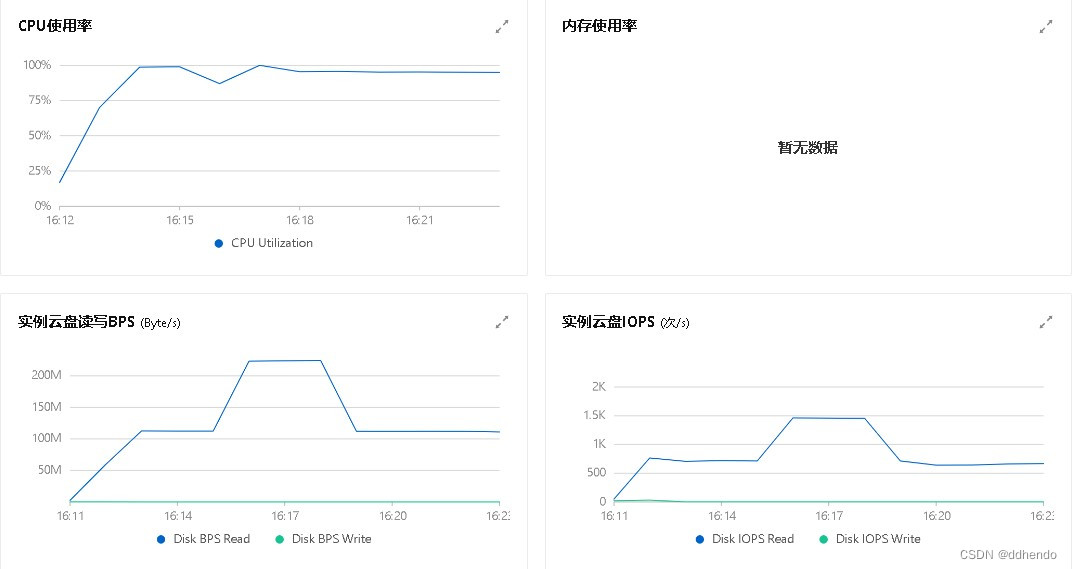
服务器配置升级
为解决NodeManager缺失及实例运行过慢的问题,本文决定升级slave1及slave2的配置,升级后的配置如表2所示,升级过后,重启三台机器并打开集群,如图10所示,发现jps进程显示正常。
| 机器 | 配置 | 局域网IP地址 |
|---|---|---|
| master | 1核(vCPU) 2 GiB | --------------- |
| slave1 | 1核(vCPU) 2 GiB | --------------- |
| slave2 | 1核(vCPU) 2 GiB | --------------- |
Hadoop集群执行Π值计算
蒙特卡洛法简介
蒙特卡罗法也称统计模拟法、统计试验法。是把概率现象作为研究对象的数值模拟方法。是按抽样调查法求取统计值来推定未知特性量的计算方法。蒙特卡罗是摩纳哥的著名赌城,该法为表明其随机抽样的本质而命名。故适用于对离散系统进行计算仿真试验。在计算仿真中,通过构造一个和系统性能相近似的概率模型,并在数字计算机上进行随机试验,可以模拟系统的随机特性。
模拟Π值计算实例
本学期在不同课程上我们学习了模拟Π值的计算,在Hadoop Examples中是采用 Quasi-Monte Carlo (蒙特卡洛)法来估算PI的值。可以简单理解为我们取一个单位的正方形 里面做一个内切圆(单位圆),则 单位正方形面积 : 内切单位圆面积 = 单位正方形内的飞镖数 : 内切单位圆内的飞镖数 ,通过计算飞镖个数就可以把单位圆面积算出来, 通过面积,在把圆周率计算出来。
计算操作前首先确保hadoop集群启动正常,并执行以下命令到相应目录
cd /usr/local/hadoop/share/hadoop/mapredcue如图11所示该目录含有多个jar包,
本次计算所需要的hadoop-mapreduce-example-3.1.3.jar,执行如下命令完成计算
hadoop jar hadoop-mapreduce-example-3.1.3.jar pi 3 100其中pi后面2个参数的含义:
(1)第一个3指的是要运行3次map任务
(2)第2个数字100指的是每个map任务,要投掷100次
本文所配置的机器性能较低,若要算出更为精准的Π值可以适当调大参数,最终运算结果如图12所示,花销时间为635.061秒,模拟计算的pi值为3.16。

Mahout数据挖掘平台
Mahout安装
Mahout 下载链接 https://mahout.apache.org/
执行如下命令将Mahout压缩包放到Hadoop目录里,并解压压缩包,解压成功如图13所示:
tar -zxvf mahout-distribution-0.9.tar.gz
Mahout环境变量设置,执行以下命令。
sudo vi /etc/profile将以下Mahout环境变量代码加入到文件中,执行以下命令。
export MAHOUT_HOME=/usr/local/hadoop/mahout-distribution-0.9
export MAHOUT_CONF_DIR=/usr/local/hadoop/mahout-distribution-0.9/conf
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$MAHOUT_HOME/bin
应用环境变量,查询是否安装成功,执行以下命令。
source /etc/profile
mahout若出现如图14所示信息,则安装成功。
K-Means算法实例
K-Means算法简介
k 均值聚类算法 (K-Means Clustering Algorithm) 是一种选代求解的聚类分析算法其步骤是,预将数据分为K 组,则随机选取 K 个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有 (或最小数目) 对象被重新分配给不同的聚类,没有 (或最小数目)聚类中心再发生变化,误差平方和局部最小。
测试数据下载
下载一个文件synthetic\_control.data,
下载地址:http://archive.ics.uci.edu/ml/databases/synthetic\_control/synthetic\_control.data
将该下载文件通过WinSCP上传到Mahout的目录下,在确保Hadoop集群启动下创建分布式testdata目录并将synthetic\_control.data 放置该目录下,如图15 所示:

使用K-Means算法测试
执行以下命令完成使用K-Means算法的运算
mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job运算的结果会在根目录建立output新文件夹,在运算前需先删除原有的output新文件夹,K-Means算法运行结果如图17所示:
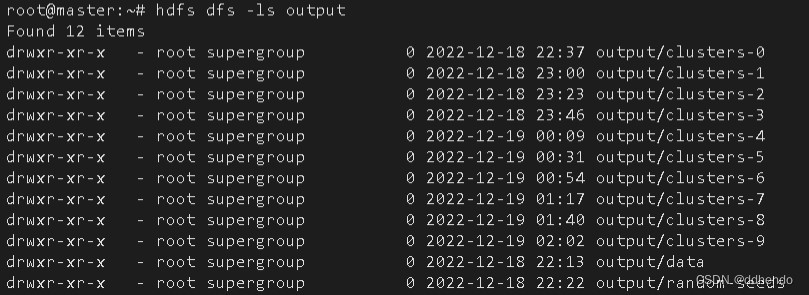
运行结果保存在output文件夹里,output文件夹有clusters-N,data目录,要想查看data里的数据,使用cat会报错,需要用命令mahout seqdumper查看,执行命令如下:
mahout seqdumper -i output/data/part-m-00000 其中clusters-N是第N次聚类的结果,data存放的是原始数据,原始数据是向量形式的,能用mahout seqdumper来读取。
为探究mahout seqdumper可以读任何SequenceFiles文件,本文查看了其源文件,是因为代码用的reader.getValueClass().newInstance()去读取的。
总结
本文完成了在阿里云服务器上搭建了Hadoop集群,解决了服务器远程连接中断,NodeManager缺失等问题,并通过蒙特卡洛法模拟Π 值的计算。另外,本文还在Hadoop分布式下搭建了数据挖掘平台Mahout,并利用Mahout平台完成了K-Means算法的运用。















 3899
3899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









