






背景
由于业务场景需求,在生产环境服务器(32core64G)搭建了基于golang开发的influx时序数据库v1.8版本 ,经过持续一周的运行之后(每天写入约100G数据),发现服务器内存消耗95%以上,并偶现SWAP报警
01
问题现象
(swap使用率)[交换内存使用率][79.10744][server_alarm]
使用top命令查看当前服务器状态:
top - 16:06:48 up 31 days, 1:03, 4 users, load average: 0.01,0.11, 0.30
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 45.0 us, 3.0 sy, 0.0 ni, 37.9 id, 43.1 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 65433636 total, 274968 free, 63048048 used, 2110620 buff/cache
KiB Swap: 32833532 total, 30839420 free, 1994112 used. 1776336 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32309 root 20 0 0.411t 0.058t 177080 S 1534 95.3 6926:00 influxd
influx进程物理内存占用58G, 内存使用率95.3%;且当前wa为43.1,说明磁盘IO非常繁忙。于是便思考:
为什么进程内存消耗那么高?
为什么磁盘io那么忙?
02
原因分析
2.1 内存高消耗分析
(1) 使用influx客户端, 查看influx服务的 runtime 状态:
> ./influx -host 10.x.xx.xx -port xx -username 'x' -password 'x' execute "show stats"
name: runtime
Alloc Frees HeapAlloc HeapIdle HeapInUse HeapObjects HeapReleased HeapSys Lookups Mallocs NumGC NumGoroutine PauseTotalNs Sys TotalAlloc
----- ----- --------- -------- --------- ----------- ------------ ------- ------- ------- ----- ------------ ------------ --- ----------
16389315856 363815829 16389315856 51905806336 16609361920 254434947 44391612416 68515168256 0 618250776 2336 24 15652952340 71222090601 45846325521880
name: database
tags: database=iot_cloud
numMeasurements numSeries
--------------- ---------
3 20927158
发现当前influxd进程 HeapIdle 约51G, HeapInUse 约16G, HeapReleased 约44G, 当前series数量为2092万左右.随之而来的疑惑:
为什么进程RES实际占用58G, 而当前进程runtime堆占用内存仅有23G ???
influxdb_v1.8基于go1.13编译,参考runtime相关参数的注释
(https://github.com/golang/go/blob/release-branch.go1.13/src/runtime/mstats.go#L245),
按照go的内存分配空间布局规则,可以根据如下计算方式估计go的当前堆内存:
(HeapIdle)51-(HeapReleased)44+(HeapInUse)16 = 23 G
(2) 为了确认是否存在内存泄漏,进一步查看进程的内存块详细数据:
#当前influxd进程id为32309
#1.pmap命令查看进程内存块分配
> pmap -x 32309 | less
32309: /etc/influxdb/usr/bin/influxd -config /etc/influxdb/influxdb.conf
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 14928 2284 0 r-x-- influxd
0000000001294000 31092 3664 0 r---- influxd
00000000030f1000 4668 4360 368 rw--- influxd
0000000003580000 180 96 96 rw--- [ 0000000004ead000 132 0 0 rw--- [ anon ]
000000c000000000 66912256 59789960 51476676 rw--- [ anon ] #堆内存
00007f80e6469000 4232 1440 1440 rw--- [ anon ]
00007f80e6913000 1886000 1872676 1872672 rw--- [ anon ]
00007f8159ae5000 232264 230124 230124 rw--- [ anon ]
00007f8167dc3000 172360 168804 168804 rw--- [ anon ]
00007f817261c000 111564 107452 107452 rw--- [ anon ]
#2.查看更详细的每一块内存分配
#命令:cat /proc/pid/smaps
#如下发现进程堆内存地址空间为:c000000000-cff4000000
> cat /proc/32309/smaps | less
c000000000-cff4000000 rw-p 00000000 00:00 0
Size: 66912256 kB
Rss: 59789960 kB
Pss: 59789960 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 8313284 kB
Private_Dirty: 51476676 kB
Referenced: 51368732 kB
Anonymous: 59789960 kB
AnonHugePages: 5994496 kB
Swap: 1055452 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
VmFlags: rd wr mr mp me ac sd
#3.使用gdb打印堆栈
#输入程序地址空间0xc000000000 0xcff4000000
> gdb -p 32309
>>> dump binary memory ./meminfo.log 0xc000000000 0xcff4000000
>>> bt #查看内存调用栈backtrace
>>> q #退出
#4.查看内存内容meminfo.log
hexdump -C ./meminfo.log | less #查看内存块数据
通过内存块调用栈 bt 命令及导出的 meminfo.log 文件,并没有发现内存泄漏的导向。
(3) 使用go pprof查看进程累计内存分配 alloc-space:
> go tool pprof -alloc_space http://x.x.x.x:xx/debug/pprof/heap
Fetching profile over HTTP from http://x.x.x.x:xx/debug/pprof/heap
Saved profile in /home/yushaolong/pprof/pprof.influxd.alloc_objects.alloc_space.inuse_objects.inuse_space.004.pb.gz
File: influxd
Type: alloc_space
Time: Oct 9, 2020 at 3:59pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 42527GB, 99.59% of 42700.66GB total
Dropped 443 nodes (cum <= 213.50GB)
flat flat% sum% cum cum%
42527GB 99.59% 99.59% 42527GB 99.59% github.com/influxdata/influxdb/tsdb/index/inmem.(*Index).DropSeriesGlobal /go/src/github.com/influxdata/influxdb/tsdb/index/inmem/inmem.go
0 0% 99.59% 42528.02GB 99.60% github.com/influxdata/influxdb/services/retention.(*Service).Open.func1 /go/src/github.com/influxdata/influxdb/services/retention/service.go
0 0% 99.59% 42527.94GB 99.60% github.com/influxdata/influxdb/tsdb.(*Store).DeleteShard.func3 /go/src/github.com/influxdata/influxdb/tsdb/store.go
(pprof) list DropSeriesGlobal
Total: 42700.66GB
ROUTINE ======================== github.com/influxdata/influxdb/tsdb/index/inmem.(*Index).DropSeriesGlobal in /go/src/github.com/influxdata/influxdb/tsdb/index/inmem/inmem.go
42527GB 42527GB (flat, cum) 99.59% of Total
. . 792: }
. . 793:
. . 794: i.mu.Lock()
. . 795: defer i.mu.Unlock()
. . 796:
42527GB 42527GB 797: k := string(key)
. . 798: series := i.series[k]
. . 799: if series == nil {
. . 800: return nil
. . 801: }
. . 802:
(pprof)
发现进程在删除series(influx索引)时, 累计消耗了42T的内存空间。说明进程在series删除时消耗了大量的内存堆(
https://github.com/influxdata/influxdb/issues/10453),所以占用内存会在此时持续飙高,但这些内存应该会被GC掉?重新看一下runtime及系统内存分配,发现了一些端倪:
进程RES | HeapIdle | HeapReleased | HeapInUse |
58G | 51G | 44G | 16G |
目前influxd进程持有的有效内存为 51-44+16=23G, 而系统进程RES为58G。猜想存在58-23=35g的内存,进程标记不再使用,当然系统也没有进行回收。
(4) 使用 memtester 工具验证猜想:
# 内存测试工具 memtester
# 使用文档:https://www.cnblogs.com/xiayi/p/9640619.html
# 向操作系统申请 30G内存
> /usr/local/bin/memtester 30G 1
memtester version 4.5.0 (64-bit)
Copyright (C) 2001-2020 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 20480MB (21474836480 bytes)
got 20480MB (21474836480 bytes), trying mlock ...locked.
Loop 1/1:
Stuck Address : setting 1
向操作系统申请30G内存后,使用{{top}}命令查看内存状态:
top - 16:24:13 up 31 days, 1:21, 5 users, load average: 1.28,1.21, 0.70
Tasks: 386 total, 2 running, 384 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.1 us, 0.0 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 65433636 total, 820012 free, 63739976 used, 873648 buff/cache
KiB Swap: 32833532 total, 30837852 free, 1995680 used. 1174164 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32309 root 20 0 0.411t 0.029t 8764 S 0.0 48.1 6946:31 influxd
14921 root 20 0 30.004g 0.029t 464 R 99.7 48.1 3:25.59 memtester
此时,influxd占用29G内存,memtester占用29G内存。
果然influxd释放的内存,此时才被系统重新回收, 翻阅了go的资料,找到了原因
(https://colobu.com/2019/08/28/go-memory-leak-i-dont-think-so/):
一直以来 go 的 runtime 在释放内存返回到内核时,在 Linux 上使用的是 MADV_DONTNEED,虽然效率比较低,但是会让 RSS(resident set size 常驻内存集)数量下降得很快。不过在 go 1.12 里专门针对这个做了优化,runtime 在释放内存时,使用了更加高效的 MADV_FREE 而不是之前的 MADV_DONTNEED。这样带来的好处是,一次 GC 后的内存分配延迟得以改善,runtime 也会更加积极地将释放的内存归还给操作系统,以应对大块内存分配无法重用已存在的堆空间的问题。不过也会带来一个副作用:RSS 不会立刻下降,而是要等到系统有内存压力了,才会延迟下降。为了避免像这样一些靠判断 RSS 大小的自动化测试因此出问题,也提供了一个 GODEBUG=madvdontneed=1 参数可以强制 runtime 继续使用 MADV_DONTNEED。
原来是由于go内部优化而使进程内存没有立即释放,至此解答了内存高消耗的疑惑。
2.2 磁盘io消耗分析
使用 iostat 命令查看磁盘io状态:
#系统命令iostat
> iostat -x 1 3 #每秒打印1次,打印3次磁盘状态
#示例第二次状态
avg-cpu: %user %nice %system %iowait %steal %idle
7.98 0.00 3.80 10.33 0.00 77.89
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 26.00 1480.00 2544.00 1692.00 28800.0033576.00 29.45 4.18 0.98 1.59 0.06 0.23 98.70
dm-0 0.00 0.00 316.00 0.00 1384.00 0.00 8.76 0.42 1.36 1.36 0.00 0.88 27.90
dm-4 0.00 0.00 2198.00 3163.0027192.00 33576.00 22.67 3.48 0.64 1.48 0.06 0.18 97.50
按照 linux进程io磁盘性能分析 ,得知influxd进程写盘的Device为 dm-4 ,指标分析如下:
当前磁盘iops为5361/s (r + w)
每秒io读取约27M/s, 写入约33M/s
io队列中,有3.48个堆积 (avgqu-sz)
每次io等待 0.47ms (await), 处理耗时0.17ms (svctm)
%util为97.5%,接近100%,说明I/O请求太多,I/O系统已经满负荷
发现influx进程对磁盘的io消耗过大。
03
性能优化
通过以上分析,可以得到:
influx使用 inmem 引擎时(默认),在retention policy时会消耗过高的内存
使用 GODEBUG=madvdontneed=1 可以让go程序尽快释放内存
influx磁盘的iops过高,应该从(增大内存buffer/增加批量写落盘)方面进行优化
因此对配置文件influxdb.conf做了如下优化:
# 详细配置说明见官方文档
# https://docs.influxdata.com/influxdb/v1.8/administration/config/#data-settings
[data]
#说明: wal预写日志log,用于事务一致性
#默认为0,每次写入都落盘。
#修改为1s, 根据业务场景,不保证强一致性,可采用异步刷盘
#[优化点]:用于减轻磁盘io压力
wal-fsync-delay = "1s"
#说明: influx索引
#默认为inmem,创建内存型索引,在delete retention会消耗过高内存
#修改为tsi1, 注意重建tsi1索引(https://blog.csdn.net/wzy_168/article/details/107043840)
#[优化点]:降低删除保留策略时的内存消耗
index-version = "tsi1"
#说明: 压缩TSM数据,一次落盘的吞吐量
#默认48m
#修改为64m
#[优化点]:增大写入量,减轻io压力
compact-throughput = "64m"
修改配置之后,执行如下命令启动influx进程:
env GODEBUG=madvdontneed=1 /usr/bin/influxd -config /usr/bin/influxdb.conf
04
线上验证
influxd进程重新运行一周之后,再次观察系统状态:
(1) 内存消耗约占55%左右:
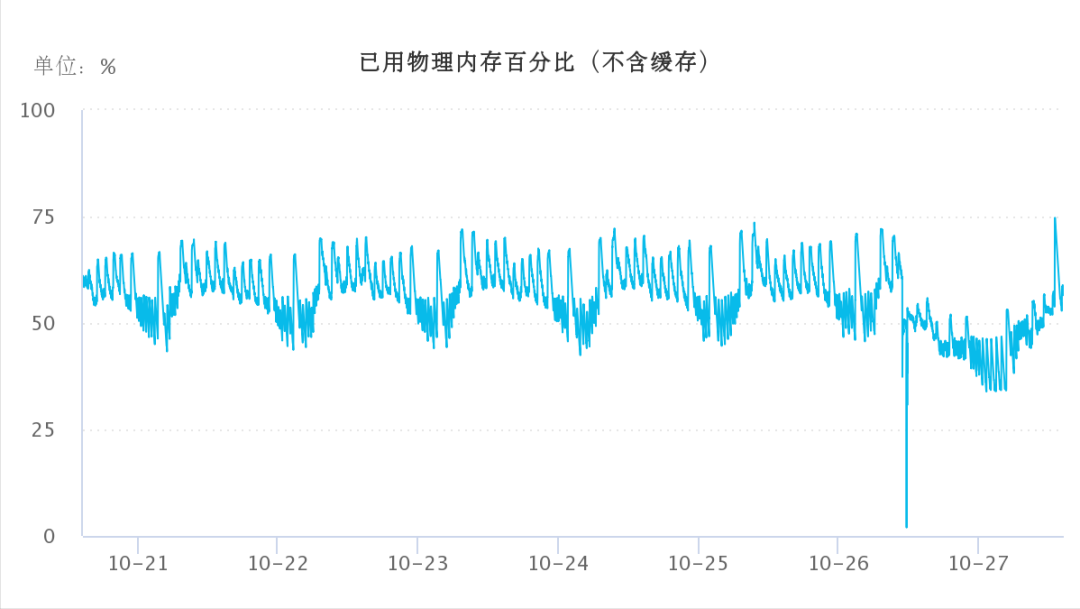
(2) 磁盘iops约为200左右,util占用6.2%。
avg-cpu: %user %nice %system %iowait %steal %idle
7.21 0.00 1.00 0.16 0.00 91.64
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 39.00 5.00 161.00 20.00 28036.00 338.02 0.25 1.51 10.40 1.24 0.37 6.10
dm-4 0.00 0.00 5.00 189.00 20.00 28036.00 289.24 0.26 1.32 10.60 1.07 0.32 6.20
发现进程运行符合预期,问题得到初步解决。
05
参考
理解virt res shr之间的关系:
https://www.orchome.com/298
服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA):
https://cloud.tencent.com/developer/article/1372348
SWAP的罪与罚:
https://blog.huoding.com/2012/11/08/198
go调度器:
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/
NUMA-aware scheduler for Go:
https://docs.google.com/document/u/0/d/1d3iI2QWURgDIsSR6G2275vMeQ_X7w-qxM2Vp7iGwwuM/pub

END
查看历史文章
Kubevirt在360的探索之路(K8S接管虚拟化)
如何提高大规模正则匹配的效能
360Stack裸金属服务器部署实践


360技术公众号
技术干货|一手资讯|精彩活动
扫码关注我们















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









