






引 言
随着LLama-3在4月19日的空降,瞬间吸引了业界与学界的广泛关注。360人工智能研究院的多模态团队也立即跻身关注的行列,迅速展开了对LLama3的深入研究与探索,探讨其在推动通用多模态大模型(LMM )领域发展中的潜力与应用前景,并于近期开源了搭载LLama3-70B的多模态大模型360VL(360VL是SEEChat的新一代版本https://github.com/360CVGroup/SEEChat),其中基于LLama3的模型包含了8B与70B两个版本,也是业界首个开源的基于LLama3-70B的多模态大模型。除了应用Llama3语言模型外,360VL模型还设计了全局感知的多分支projector架构,使得模型同时具备了更充分的图像理解能力。360VL超越一众如 LLaVA1.6、MM1、Yi-VL等模型,在众多主流 Benchmark 上表现良好。
GitHub 地址:https://github.com/360CVGroup/360VL
Huggingface 地址:https://huggingface.co/qihoo360/360VL-70B
模型架构
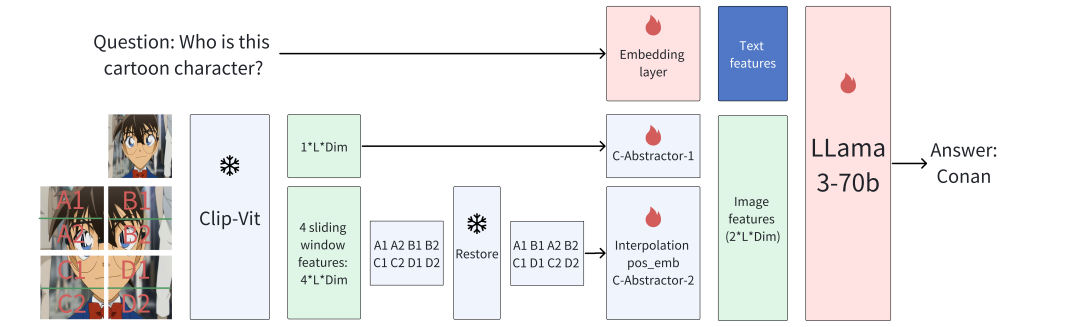
360VL作为一个视觉多模态大语言模型,能够支持多层次的视觉任务。在模型结构上,360VL遵循视觉编码器-桥接层-大语言模型的设计,通过语言模型对视觉token进行充分的理解。除了使用更强大的基座模型外,研究人员将重点放在了桥接层的改进上。
在LMM中,桥接层起到了承上启下的核心作用。通过对齐训练阶段,桥接层负责将视觉编码器的特征进行变换,使得大语言模型能够理解图像的深层含义。目前多数多模态大语言模型主要使用简单的线形层或resampler结构作为桥接层,但它们处理高分辨率图像都存在一定的限制。受限于目前通用视觉编码器能够处理的图像分辨率大小,面对高分辨率图像通常需要进行滑窗切分,然而显而易见的是,当面对高分辨率图像产生的多图像块时,线形层或者resampler结构都会成倍增加图像产生的token数量,这对LMM的训练与推理带来了一定的负担。研究人员通过对目前通用的桥接层结构进行调研,最终确定基于C-abs结构进行了各类实验。相较于MLP,C-abs添加了额外的卷积模块,对视觉特征进一步提取的同时,也能通过一定的参数量去承载更多的训练数据。
针对不同分辨率的图像,我们首先对图像的尺寸进行调整,使得图像能够通过滑窗得到4个336*336大小的图像块,同时也将原始图像调整到336*336的分辨率。在模型的训练与推理中,4个图像块与1张原图分别通过视觉编码器得到4*L*Dim和1*L*Dim的特征。其中前4组特征进行维度转换,来维持大分辨率图像的原始空间状态,得到1*4L*Dim的特征。在C-abs内部,我们引入了对不同序列长度自适应的插值编码模块来拓展位置编码特征的维度,进而保证对大分辨率图像的空间理解能力。最终C-abs将1*4L*Dim采用AdaptivePooling操作转换为1*L*Dim。将滑窗和原图的视觉特征进行拼接,得到2*L*Dim视觉特征送入LLM中。
在训练流程上,采用了2-stage的训练策略。考虑到训练时长等因素,研究人员并未使用大量的训练数据,在预训练数据上以llava1.5的预训练数据为主,进行了少量额外训练数据的添加。SFT数据上,研究人员采用开源数据llava_v1_5_mix665k进行了实验,并额外挖掘了多类型的中英文数据,帮助模型对视觉相关任务达到更好的指令遵循能力,尤其是在中文任务上,通过中文多模态数据改善了原有llama3的中文理解能力。在有限的数据量下,360VL对视觉内容达到了很好的理解能力。可以预见的是,更大量级的训练数据的引入会激发模型潜力进而达到更好的表现。
实验结果
360VL 在各种 Zero-shot 的榜单上进行了评测,在多种指标维度都取得了不错的效果。目前大数据量级下的模型也开始进行训练,后续也会计划开源。
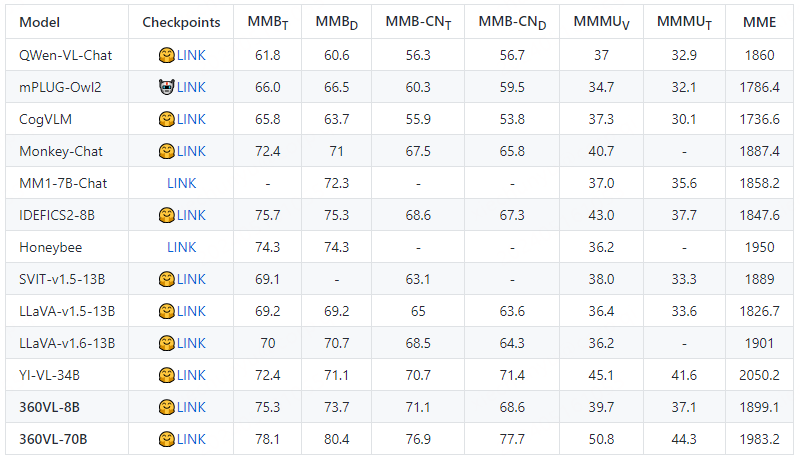
针对不同的基座模型,研究人员在相同数据下进行了对比实验。视觉模型这里分别选取了CLIP-ViT-L、siglip-so400m、DFN5B-CLIP-ViT。语言模型分别选取了Vicuna1.5-7B、Vicuna1.5-13B、Llama3-8B、Llama3-70B。从实验效果看,siglip-so400m和CLIP-ViT-L表现更优。Llama3系列相对于Vicuna1.5有了全面的提升,Llama3-8B也是超越了Vicuna1.5-13B的效果,Llama3-70B取得了最好的表现。研究人员也是对搭载Llama3和CLIP-ViT-L的版本模型进行了开源。在模型结构上,研究人员也尝试保留原始的4个滑窗,将图像特征维度扩展到6*L*Dim,在模型效果上能获得比较不错的提升,但随着图像序列的变长,计算效率会有比较大的下降,所以并没有保留这种操作。
具体效果
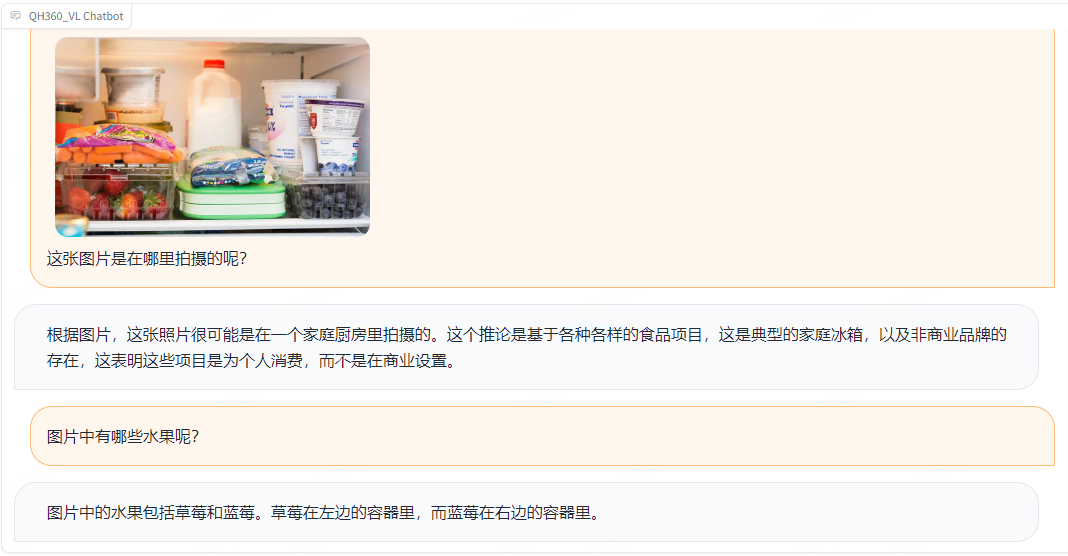
中文能力
OCR
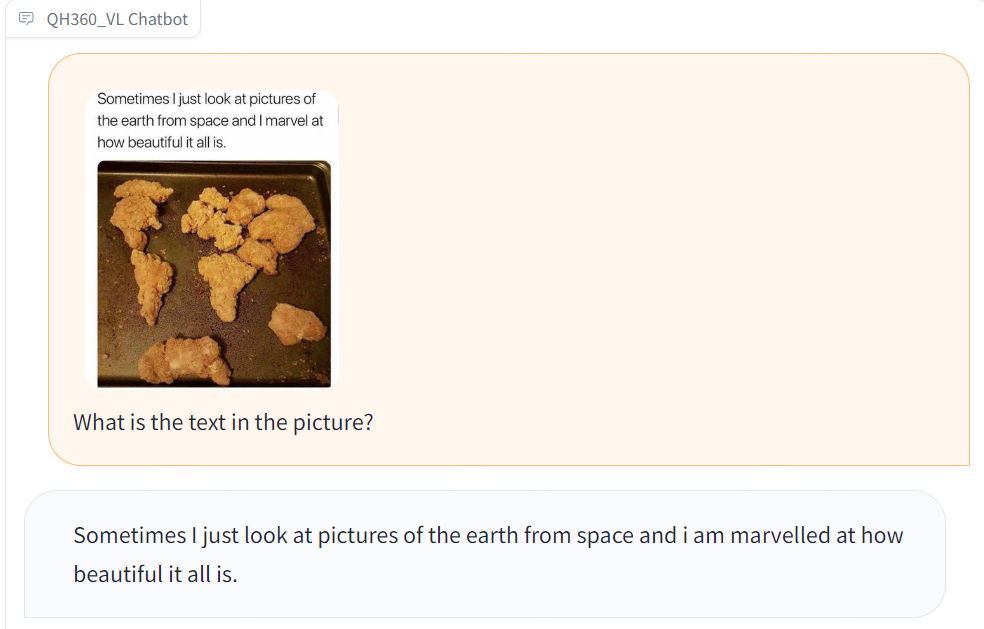
图片理解
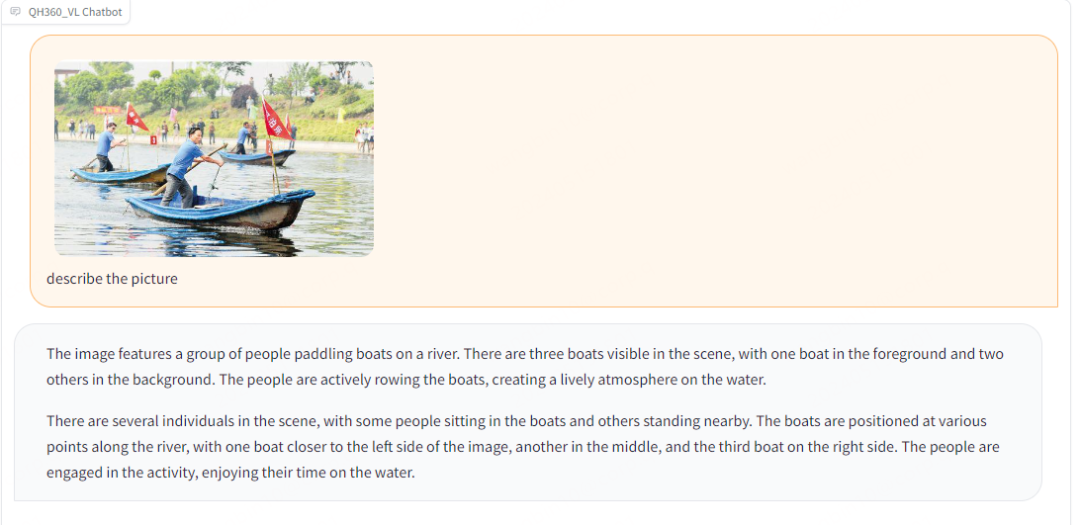
定位能力
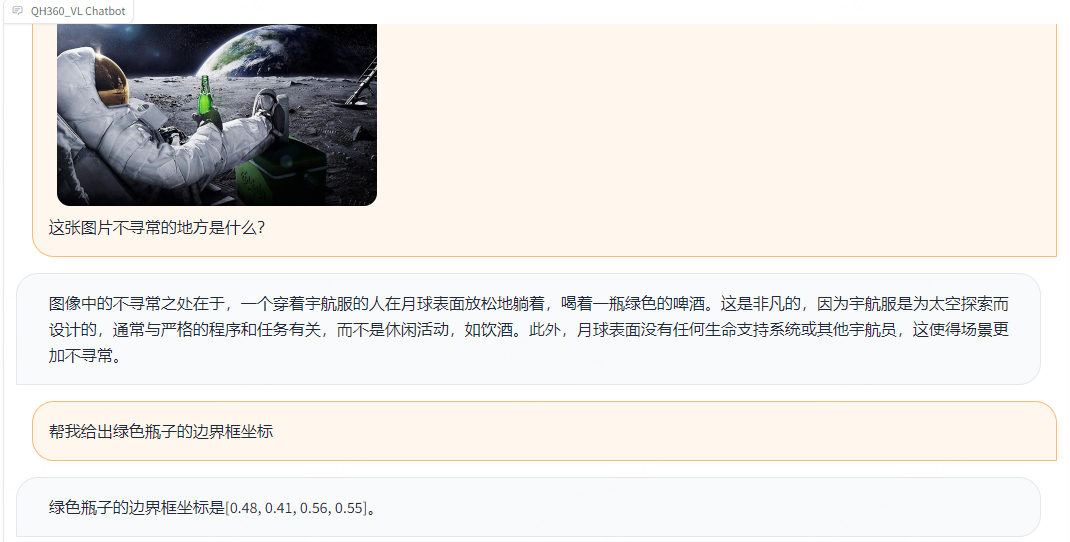
展 望
总的来说,研究人员针对llama3的多模态能力进行了探索,并提供了搭载llama3-70B的360VL模型。作为通用型多模态模型,360VL在处理像视觉问答和内容创造这样的标准任务时展现出卓越的能力,大家可以下载体验。360VL也会保持每一代新版本的开源。















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









