






Apache Pulsar是一个开源的云原生分布式消息流平台,它采用了存储和计算分离的架构设计,能够实现对存储和计算节点平滑扩缩容,这对于线上运维有很大的灵活性。360 中间件团队在 2023 年 5 月份上线了 Pulsar 服务,使用了 Pulsar v3.0.3 版本,我们的 Pulsar 服务都运行在 K8s 集群上,接入了公司的日志采集、大数据分析、监控、告警、域名服务等内部平台。
在 Pulsar 系统的部署及上线过程中,我们发现并解决了 Pulsar 的一些问题,旨在确保服务的线上环境的高可用性、稳定性和可观测性。
希望我们的实践经验,可以给使用 Pulsar 的技术同行们提供一些借鉴价值。
1、架构设计
1.1 集群部署
我们的 Pulsar 服务平台已稳健运行在 K8s 集群之上,旨在最大化资源利用效率,全面提升消息服务的灵活性与运维效率,并方便用户快速接入。
为了适配内部的服务体系,我们在部署 Puslar 集群的时候,进行了如下本地化改进:
1.集成日志管理系统:实现了日志的自动化收集机制,无缝对接公司大数据分析平台,为日志分析、业务洞察及智能告警提供数据。
2.监控与告警一体化:自动化接入公司监控告警体系,使 Pulsar 集群的运行状态实时可视化,保障线上服务的稳定性和响应速度。
3.存储适配与优化:选用了 open-local 作为持久卷(PVC)插件,适配公司的存储策略,提升数据存储的灵活性和性能,确保资源使用的高效与合规。
4.权限管理体系整合:统一了集群的的权限管理,简化了用户访问控制流程,确保集群操作的安全性同时,也极大提升了用户体验。
5.负载均衡与服务接入:紧密集成公司负载均衡平台,为全公司范围内的业务提供稳定可靠的消息服务,对服务流量进行整流,保证服务的高可用性和低延迟。
未来,我们还将积极探索 Pulsar Operator 的应用,进一步提升集群管理的自动化水平和精细化控制能力,以适应更加复杂多变的业务需求。
1.2 磁盘选型
压测结果显示,同样在 1GB/s 的吞吐下,NVMe 盘的端到端延时(E2E 延时)保持在 8 毫秒以内,普通 SSD 盘的端到端延时保持在 40 毫秒以内。考虑到成本效益与满足多数业务场景需求的能力,我们决定采用 SSD 本地盘作为主存储解决方案,而针对那些对延时有严格要求的关键服务,我们将提供高性能 NVMe 盘作为存储选项。
为进一步在存储成本与性能之间达成平衡,我们正着手测试异构混合存储架构,以结合 HDD 与 NVMe 盘的优势。
该方案设想利用 HDD 的大容量特性存储 Pulsar 的 Ledger 数据,因为 Ledger 数据是在内存中累积并预先排序然后落盘,Ledger 数据落盘动作和用户生产消息过程是异步进行的,因此使用 HDD 盘来存储 Ledger 数据能有效降低存储成本而不牺牲写入效率。
同时,NVMe 盘因其高速随机读写能力,主要用来存储 Journal 日志与 RocksDB 索引数据,确保快速检索与低延时访问。这种方式能有效降低 Pulsar 的存储成本,给客户提供性价比更高的长期存储解决方案。
1.3 集群模式
为了适应公司不同的业务场景对稳定性和灵活性的差异化需求,我们提供了 Pulsar 单机群、跨可用区多活和跨地域多活等多种使用方案。随着安全性和可靠性级别的提升,相应的资源投入及运维成本亦将相应增加。
在多活部署模式下,Pulsar 集群间采用全连接(Full-mesh)的架构来确保消息与消费进度跨集群实时高效同步,以此构建起一个强健的数据一致性网络。全连接架构的 Pulsar 集群一旦遭遇单个集群故障,系统能够无缝切换至备用集群,由于多活集群之间的数据同步机制,终端用户及业务逻辑层将体验到几乎无中断的服务连续性,确保业务平稳运行,实现真正的高可用。多活架构如下图:
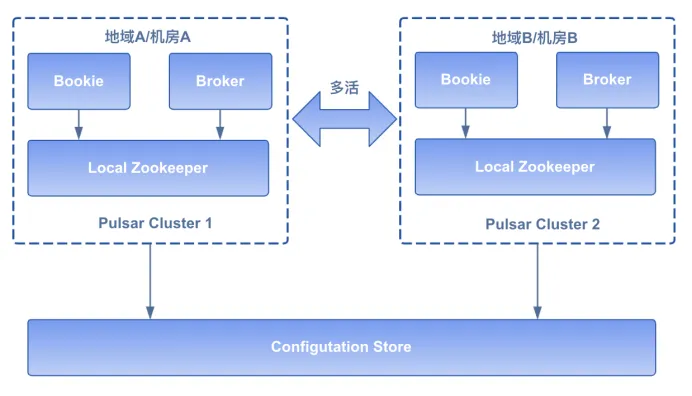
在测试中我们观察到,如果同时跨两个集群进行消息生产与消费操作,存在数据被重复消费的风险。我们建议用户遵循最佳实践,在任一时刻仅选择一个集群进行消息发布(生产)操作,并在该集群或其镜像集群上执行消息订阅(消费)操作,以防止数据重复消费。简而言之,采取 “单一集群生产 - 消费” 策略,无论是选择集群 A 负责生产与消费,或是集群 B,都能有效维护数据的一致性与完整性。
2、Pulsar 服务发现
我们的 Pulsar 服务部署在 K8s 集群环境中,而使用 Pulsar 的用户的应用则部署在多样化的环境中,包括裸金属服务器、虚拟机环境,以及其他独立的 K8s 集群。为了确保这些外部应用能够顺利访问到 Pulsar Broker 服务,需要将 Broker 服务对外部暴露。
我们通过环境变量动态捕获每个 Broker Pod 的 IP,然后在 Broker 配置文件中用 advertisedAddress 的方式将 Pod IP 对外进行暴露,Broker 启动时动态地将实际的 Pod IP 注册到 Zookeeper 中,实现 Broker 地址的自动更新与外部可达,确保公司内部各个环境中的业务都能访问到 Pulsar Broker。
env:
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
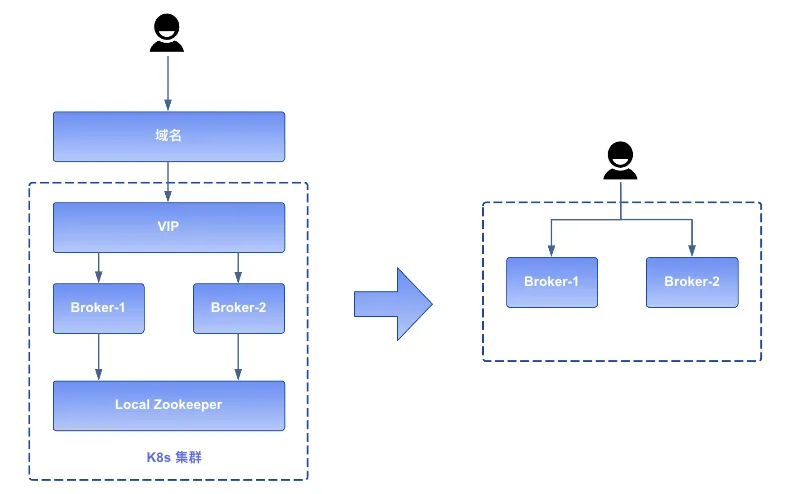
fieldPath: status.podIP由于 Pod IP 是不稳定的,因此我们用内部的 LoadBalancer 功能代理所有的 Broker,对外暴露稳定的 Broker 地址。由于 LoadBalancer 分配的 VIP 与特定机房绑定,考虑未来可能的机房迁移等运维变动,最终方案是集群中所有 Broker 通过同一个域名对用户提供服务,这样可以极大减轻未来机房迁移对上层业务用户的影响,提高了消息服务的灵活性和稳定性。
简而言之,Pulsar 在线服务的交互流程调整为:用户首先借助域名解析获得目标 Topic 对应的 Broker 地址信息,随后直接与这些 Broker 的 Pod IP 建立连接进行消息的生产与消费活动,具体流程如下图所示:
3、性能优化
在线上部署 Pulsar 之前,需要依据目标运行环境的具体硬件配置对 Puslar 的参数进行调整,确保 Pulsar 的性能达到最佳。
3.1 挑战
在进行性能测试时,我们采用了开源的压测工具 OpenMessagingBenchmark(OMB)对 Puslar 集群进行压力测试,发现了如下一些问题:
Journal 创建延时高,P999 延时达到秒级别
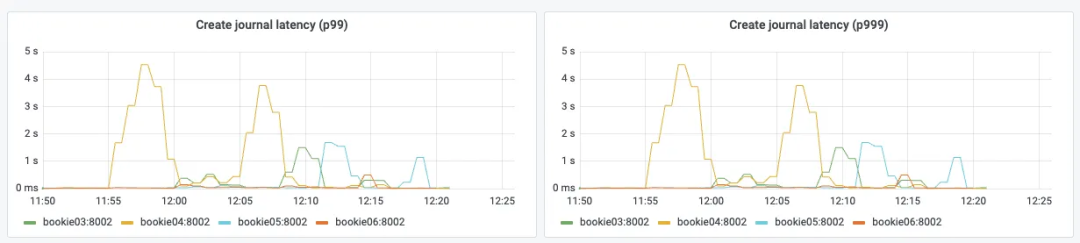
生产延时高,P999 延时达到秒级别
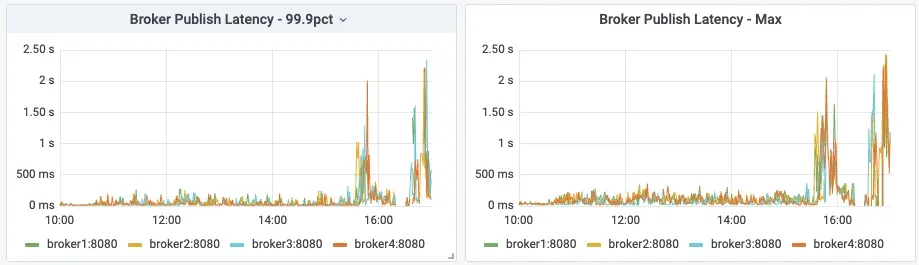
消费延时高,P999 读取数据延时达到秒级别
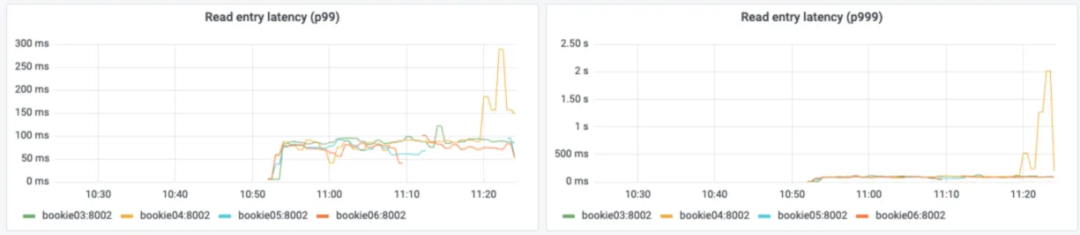
Bookie 节点和 Broker 节点的流量不均匀等等问题。
3.2 解决方案
面临这些问题,经过多次压测后,我们发现 OpenMessagingBenchmark(OMB)工具的参数配置对压测结果的影响非常大,我们首先改进了压测工具的使用方式。
3.2.1 压测工具优化
根据实际需求对 OMB 进行了定制,以达到最好的压测结果:
1.版本同步调整:更新 pulsar-client-all 依赖的版本号,确保其与部署的 Pulsar 集群版本相匹配,消除由版本兼容性差异可能导致的性能损失。
2.数据管理优化:新增了 Time-To-Live(TTL)和 Retention 策略配置,以便自动清理压测生成的数据,防止磁盘空间耗尽中断测试流程。
3.持久化参数定制:允许自定义持久化参数(如 EnsembleSize、WriteQuorum、AckQuorum),推荐与生产环境配置保持一致。
4.优化发布延迟:调整了 batchingMaxPublishDelayMs 参数,这对于衡量延迟敏感型场景尤为重要。
5.参数精细化调整:依据硬件规格细化调整了诸如 ioThreads、connectionsPerBroker、batchingMaxBytes 等参数,通过反复调试以求达到最优性能表现。错误的配置可能导致消费者速率落后于生产者,显著影响端到端延迟(E2E)评估。
6.指定 Topic 测试支持:增强了对指定 Topic 进行测试的能力,便于模拟追赶读(Catch-up read)的实战情景。
7.资源管理强化:由于 OMB 在完成一轮测试后存在进程挂起、内存占用持续高位的问题,通过优化让测试结束后自动退出进程,避免了因多次测试导致的内存溢出问题。
3.2.2 Pulsar 优化
在改进 OMB 的使用方式后,我们不断打磨 Pulsar 线上服务,有如下预备举措:
1.构建全面监控体系:首要任务是建立健全的监控机制,通过 Grafana 的图表展示 Pulsar 服务内部的指标状态,如果发现指标缺失,需要手动进行完善。
2.深入理解核心流程:深入剖析 Broker 与 Bookie 的数据处理逻辑,包括读写流程,这有助于快速定位性能瓶颈大问题(详情参考文档[1]与[2])。
3.优化存储配置:确保 Zookeeper 数据盘、 Ledger 与 Journal 目录分置于不同磁盘上,推荐使用 SSD 或 NVMe 硬盘以加速 I/O。特别地,启用 Journal 同步写入( journalSyncData 配置为 true) 时,必须保证 Journal 盘的写入性能,以缩减消息发布时延。
4.磁盘与目录策略调整:每个磁盘,特别是承载 Journal 的磁盘,目录数量 (journalDirectories) 不宜太多,以保证全局视角下的磁盘顺序写入。
3.2.2.1 Journal 写入优化
做完预备措施后,通过如下措施对 Pulsar 服务端进行调参可以优化 Journal 写入性能:
1. 确认 Namespace 的 persistence 参数(EnsembleSize,WriteQuorum,AckQuorum)设置是否合理。
2. 如果 Journal 添加延时(监控指标为 bookie_journal_JOURNAL_ADD_ENTRY)较大,可以观察 Journal 创建延时(监控指标为 bookie_journal_JOURNAL_CREATION_LATENCY)是否合理,再观察 Journal 落盘延时(监控指标为 bookie_journal_JOURNAL_SYNC)是否合理,如果 Journal 盘的 io util 较高,Journal 数据来不及落盘,会导致 Journal 无法及时创建而阻塞生产动作。
3. journalPageCacheFlushIntervalMSec 参数负责控制 PageCache 刷盘的时机,默认为 5 秒,可以调整此参数使磁盘 IO 更均匀。
4. numJournalCallbackThreads 参数控制了用于处理 journal(日志)写操作回调的线程数量,在高负载场景下增加这个参数的值可以提升 BookKeeper 处理写操作回调的并发能力,从而可能提高整体的写入性能。
5. 压测时如果发现有磁盘的 io_util 指标一直很大,还要确认下磁盘硬件是否正常,我们压测时出现过因为磁盘过保性能不好导致生产延时很大的问题。
3.2.2.2 Ledger 写入优化
通过如下措施对 Pulsar 服务端进行调参可以优化 Ledger 写入性能:
1.观察 Ledger 盘的 io util 监控是否达到阈值或分布是否均匀。
2.设置 dbStorage_writeCacheMaxSizeMb 参数修改 WriteCache 的大小以控制刷盘的频率。
3.RocksDB 调参:WriteCache 中的索引数据会写入到 RocksDB 中,通过控制 RocksDB 的 写缓存大小(dbStorage_rocksDB_writeBufferSizeMB 参数)、 sst 文件大小(dbStorage_rocksDB_sstSizeInMB 参数)、LSM tree 的层数及大小(dbStorage_rocksDB_numLevels、dbStorage_rocksDB_maxSizeInLevel1MB 参数)可以控制 RocksDB 数据写放大以及 Compression 的时机,来提高 RocksDB 的写入速度。
3.2.2.3 读优化
通过 Grafana 的 bookkeeper_server_READ_ENTRY 指标可以观测读延时,通过如下措施可优化读性能:
1.读取数据时,会优先从 Ledger 的读缓存(即上面说的 writeCache)获取数据,所以适当增加 writeCache 大小有助于缓存更多的数据。
2.如果缓存没有命中,则会从磁盘批量预加载数据到 ReadCache 中,预加载的 Entry 数量由参数 dbStorage_readAheadCacheBatchSize 进行控制,读缓存大小的由监控指标 bookie_read_cache_size 展示,监控指标 bookie_read_cache_hits 展示命中读缓存的数量,bookie_read_cache_misses 展示没有命中读缓存的数量。
3.调整参数 dbStorage_rocksDB_blockSize 以控制 RocksDB 的缓存大小,有助于缓存更多的 Entry 的索引信息到内存中。
3.2.3 优化成果
还可以通过细致调节 BookKeeper 的读写线程数量,也能提升 Puslar 的性能。
通过不断的优化,目前压测结果如下:
1.峰值吞吐量高达 2GB/s,即便是在 处理大消息(5MB)及大规模分区(10,000 个以上)的 Topic 时,Pulsar 仍能维持较高的吞吐性能。
2.在持续 1GB/s 的吞吐负载下,Pulsar 的 P99 的发布延时 <=5 毫秒,且随着分区数量增加,延迟波动维持在较低水平。
3.在持续 1GB/s 的吞吐负载下,Pulsar 的平均端到端延迟(E2E延时) <=3.2 毫秒,而 P99 的平均端到端延迟(E2E延时)<=8 毫秒。
4.Pulsar 在 1.8GB/s 的追尾读(Tailing Reads)的场景下,能保持 1GB/s 的稳定追赶读(Catch-up Reads)取吞吐,能满足了多样化消费场景。
4、监控告警
Pulsar 官方提供的监控,能覆盖 JVM、Broker、Bookie、Zookeeper、Topic 及 K8s 核心组件的大部分指标,能反映线上集群的大部分内部状态。需要注意的是,如果 Grafana 的数据源是 K8s 的 Prometheus Exporter ,需要对 Grafana 的图表进行调整才能正常展示数据,原因是 Grafana 的图表格式和 Prometheus 采集的数据格式不兼容。
基于上述监控数据,我们构建了多层次告警机制,确保快速响应潜在问题,这一机制包括但不限于:
1. 硬件层面的监控告警,例如资源如CPU、内存及磁盘的使用情况。
2. K8s 集群及节点状态监控,保障网络连通性与节点存活。
3. K8s 应用健康监控,涵盖 Pod 运行状况、资源分配和副本检测等。
4. 消息 E2E 延迟监控,在 Pulsar 建立一个专供测试 E2E 使用的数据通道,周期性地在同一个机器上启动一个 mock-client 发送并消费数据以获取准确的 E2E 消息延时。
5.其他 Pulsar 特有指标的监控,如 Bookie 读写状态、写入延迟增高等。
我们还把 Pulsar 的日志信息收集至大数据分析平台,通过对日志进行分析,能发现一些系统潜在的问题,深化了日志分析的实用价值。
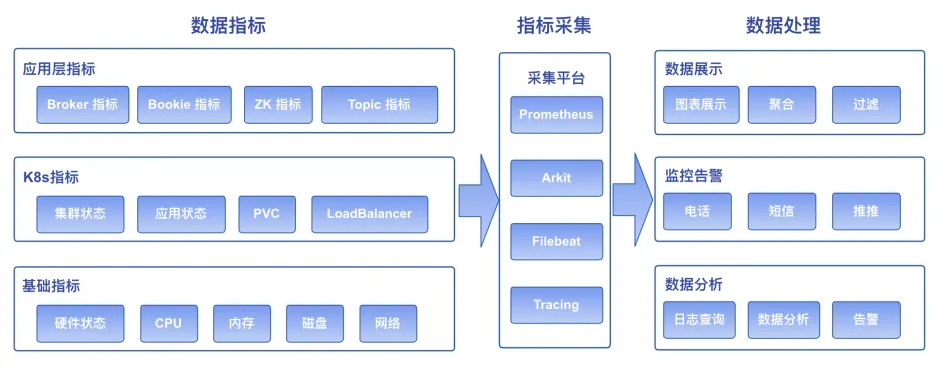
这一套监控与告警机制能够将 Pulsar 无缝集成到公司的内部监控告警与大数据系统中,大幅度减轻了运维人员的工作负担,加速了运维自动化进程。
5、未来规划
当前,Pulsar 消息服务平台已在 360 公司内部上线部署并服务于多个业务团队,未来我们将对 Pulsar 持续优化,以适配更多的线上场景:
S3 集成:探索 Pulsar 与 S3 的深度融合,实现数据的超长时间低成本存储解决方案。
异构存储:针对大容量 SATA HDD 硬盘与高性能 NVMe SSD 混合配置的服务器,优化存储策略,平衡成本与性能。
负载均衡:精进负载均衡算法,确保集群资源分配更高效、更均衡。
自动弹性:开发与实施自动弹性扩缩容机制,以应对流量波动,提高资源利用率。
Operator:推动 Pulsar Operator 的成熟应用,简化 K8s 环境下 Pulsar 集群的管理和运维工作。
此外,我们正在推动 Pulsar 与公司核心平台的合作,比如大数据处理平台、日志管理系统、函数计算平台等,不断丰富 Pulsar 的应用场景,提升其在多元化技术生态中的协同作业能力。
参考资料:
[1] Apache Pulsar 在 BIGO 的性能调优实战(上)
https://mp.weixin.qq.com/s/mJViU-elhBwHMDiius2b8g
[2] Apache Pulsar 在 BIGO 的性能调优实战(下)
https://mp.weixin.qq.com/s/f0vL6gdFJIjNwsfZ3BXePA
[3] Awesome Prometheus alerts
https://samber.github.io/awesome-prometheus-alerts/rules
更多智汇云产品技术,请点击智汇云官网:智汇云-企业数智化核心引擎 (360.cn)
合作请致电:4000052360















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









