







获得一个网页最简单的一行代码是r = requests.get(url),它可获取你想获取的任何一个网页的资源,从而构造一个向服务器请求资源的Requests对象,服务器返回的内容用r来承接,即r是一个Response对象,它包含爬虫从服务器返回的所有内容。Requests库get方法的完整形式为
Requests.get(url,params = None,**kwargs)
它实际采用了requests的方法封装
关于requests库的对象属性
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容的编码方式(备选编码方案) |
| r.content | HTTP响应内容的二进制形式 |
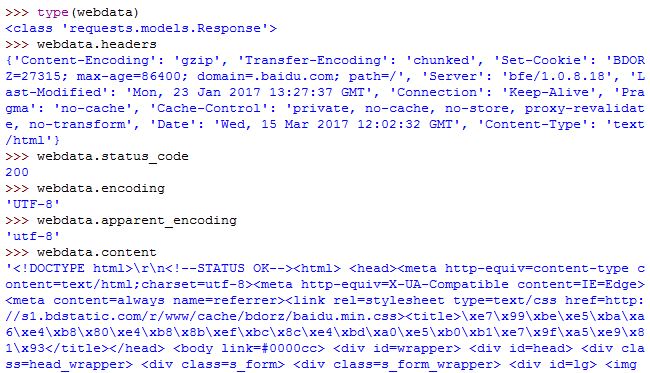
当r.status_code为200时,后面的对象属性才能正确返回,否则说明URL访问出错
原则上说,apparent_encoding的编码比encoding的编码更加准确(前者从内容中分析编码方式,后者从header中分析)
Reques库的框架
















 3937
3937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









