







机器学习01学习 – 使用简单线性回归根据年龄预测医疗费用
最近学习了一些机器学习的内容;我获取到了一些数据可以用来进行训练,对于在这方面几乎毫无涉猎的我,便直接开始了这次的代码编写
环境准备
语言:Python
IDE: Pycharm
首先这次我们用的编程语言是python
JetBrains家的产品,用过都说香,无论是我们之前Java web用的IDEA 、写Harmony OS用的DevEco Studio还是写Android app用的Android Studio,都是JetBrains家的产品,所以在这之前学习python语法的时候我就下载了Pycharm,借此契机也升级Pycharm到达最新版本
需要注意的是,这个项目我们需要用到一些科学计算的东西,所以我们还需要安装anaconda。
anaconda的安装大概就是下载安装包然后安装,需要注意的是如何在pycharm中配置anaconda
项目新建
我们点击 文件->新建项目

点击创建

可恶居然报错了?没关系,我们先确认
然后点击文件->设置->项目:使用简单线性回归根据年龄预测医疗费用->python 解释器

显然我们现在没有解释器,python作为解释语言没有解释器就没办法运行
第一次敲anaconda代码的我们需要新建,点击下拉列表右边的小齿轮后点击全部显示,看一下有没有我们要用的anaconda,如果没有,就点击左上角的加号,左侧选择系统解释器,修改解释器的位置,选泽anaconda文件夹下的python.exe,并按下确定,选择新增的Anaconda的解释器并确定
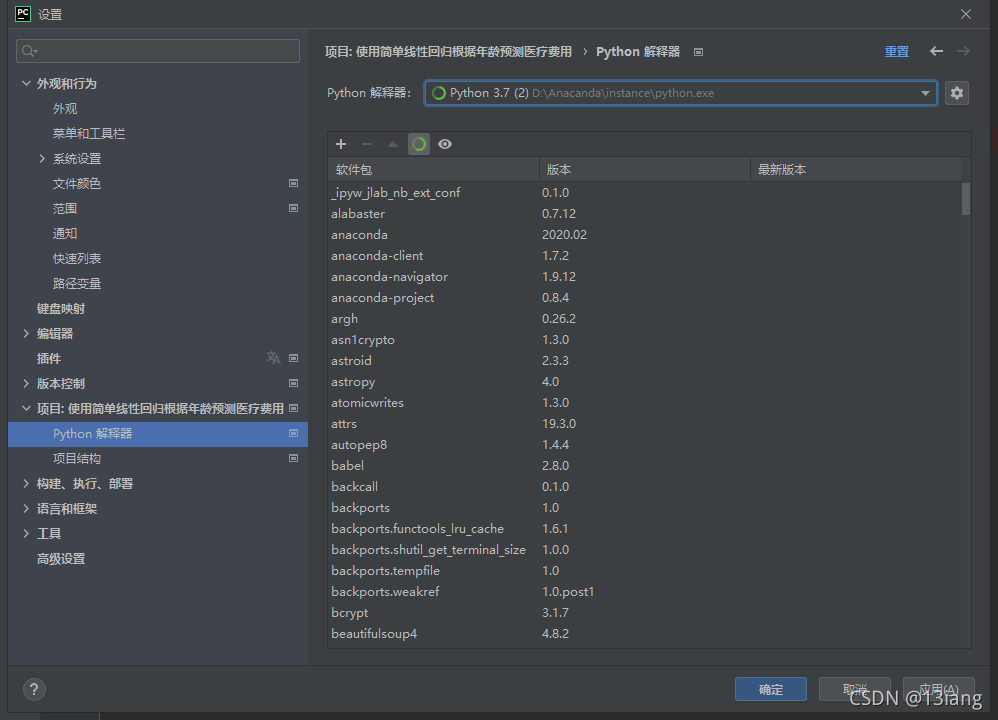
再次基础上按下软件包表上方的小绿圈,一顿加载后,点击 应用,再点击 确定
这时我们就已经可以运行它自动生成的代码了,可喜可贺
知识储备
在做这个项目之前,有一些内容是我们需要知道的,当然我在这篇博客中不会讲原理,我只会讲代码
-
pandas.read_csv(path)读取csv文件,path是文件路径,
-
LabelEncoder().fit_transform(columnName)将列的数据转化为整数数值,比方说 address=[‘广州’,‘上海’,‘北京’,‘广州’],就可以转化为['0,1,2,0]
-
numpy.newaxis用于将数组升维,位于中括号里前方是将整个数组由[A,B,C]变为[[A,B,C]],位于中括号里后方就是将整个数组由[A,B,C]变成[[A],[B],[C]]
-
x_train, x_test, y_train, y_test = train_test_split(features,targets,test_size,random_state)features 所要划分的样本特征集
targets 所要划分的样本结果
test_size 划分的数量,整数为个数,小于1的小数则为百分比
random_state 随机数种子
分割测试集和训练集,训练集用来训练;而测试集不参与训练;只用来验证其正确性
-
LinearRegression().fit(x_train, y_train)训练模型 x_train是训练特征集,y_train是训练结果集
值得注意的是在sklearn新版本中,所有的数据都应该是二维矩阵,所以x_train和y_train都需要是二维矩阵,要是x_train或者y_train是一维数组,那么就可以用到前面讲到的
numpy.newaxis -
LinearRegression().predict(x_test)根据训练好的模型,给与测试特征集的值让其返回模型预测结果的值
-
r2_score(y_test, y_pred)y_pred 是指预测的结果值
与
linear_model.score(x_test, y_test)功能一致获取R方值,用于判断回归模型的好坏程度
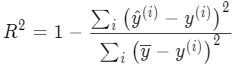
-
matplotlib.pyplot.scatter(x_axis, y_axis, c, s)在图上撒点
x_axis x轴的数据
y_axis y轴的数据
c 点的颜色
s 点的大小
-
matplotlib.pyplot.plot(x_axis, y_axis, color, linewidth)在图上画线
color 线的颜色
linewidth 线的粗细
-
matplotlib.pyplot.show()显示线
代码实战
除了结果集全部作为特征集预测结果
-
首先我们肯定想着,要训练一个东西,自然需要将他进行读取
import pandas as pd data = pd.read_csv("insurance.csv") -
然后我们使用
LabelEncoder().fit_transform(columnName)将他进行数据处理from sklearn.preprocessing import LabelEncoder le = LabelEncoder() for col in data.columns: data[col] = le.fit_transform(data[col]) -
我们将除了结果集的全部作为特征集
feature = data.iloc[:, :-1] # 全部行 除了最后一列的全部列 target = data.iloc[:, -1] -
划分训练集,测试集
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=216)这里我们选择将数据的20%作为测试集
-
训练模型
from sklearn.linear_model import LinearRegression linear_model = LinearRegression() linear_model.fit(x_train, y_train) -
将测试集的特征集和结果集带入,获取R方值
print("R方值:" + str(linear_model.score(x_test, y_test)))输出了结果
R方值:0.7773044847048564颇为满意(就这也满意?)
-
预测数据
user_feature = [[42, 1, 224, 0, 0, 3]] user_target = linear_model.predict(user_feature) print("预测花费大约为"+str(user_target[0]))输出了结果
预测花费大约为756.8992005547243 -
完整代码
import pandas as pd from sklearn.preprocessing import LabelEncoder from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score data = pd.read_csv("insurance.csv") le = LabelEncoder() # 将数据转化为整数数值并赋值 for col in data.columns: data[col] = le.fit_transform(data[col]) feature = data.iloc[:, :-1] # 全部行 除了最后一列的全部列 target = data.iloc[:, -1] x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=216) # X 所要划分的样本特征集 # y 所要划分的样本结果 # 分割测试集和训练集,训练集用来训练;而测试集不参与训练;只用来验证其正确性 linear_model = LinearRegression() linear_model.fit(x_train, y_train) # 与测试样本结果比较,获取得分 y_pred = linear_model.predict(x_test) # 以下两句效果一致 print("R方值:" + str(r2_score(y_test, y_pred))) print("R方值:" + str(linear_model.score(x_test, y_test))) # 输入测试特征集,在模型中获取预测结果 user_feature = [[42, 1, 224, 0, 0, 3]] user_target = linear_model.predict(user_feature) print("预测花费大约为"+str(user_target[0]))
单项特征集与结果集训练绘出图像
-
前面的操作是大致一致的
import pandas as pd from sklearn.preprocessing import LabelEncoder from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import r2_score data = pd.read_csv("insurance.csv") le = LabelEncoder() # 将数据转化为整数数值并赋值 for col in data.columns: data[col] = le.fit_transform(data[col]) -
切割训练测试集
# 升维 feature = data.iloc[:, 0] feature_2d = feature[:, np.newaxis] target = data.iloc[:, -1] x_train, x_test, y_train, y_test = train_test_split(feature_2d, target, test_size=0.2, random_state=216) -
训练模型的代码也是一样的
from sklearn.linear_model import LinearRegression linear_model = LinearRegression() linear_model.fit(x_train, y_train) -
绘图
import matplotlib.pyplot as plt plt.scatter(x_train, y_train, c='b', s=10) # s 点的大小 前两个参数是横纵坐标,大小需要一样 plt.plot(x_test, y_pred, color='red', linewidth=1.0) plt.show()效果如图

-
完整代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
data = pd.read_csv("insurance.csv")
le = LabelEncoder()
# 将数据转化为整数数值并赋值
for col in data.columns:
if col == 'sex' or col == 'smoker' or col == 'region':
data[col] = le.fit_transform(data[col])
# 升维
feature = data.iloc[:, 0]
print(feature)
feature_2d = feature[:, np.newaxis]
target = data.iloc[:, -1]
x_train, x_test, y_train, y_test = train_test_split(feature_2d, target, test_size=0.2, random_state=216)
# X 所要划分的样本特征集
# y 所要划分的样本结果
# 分割测试集和训练集,训练集用来训练;而测试集不参与训练;只用来验证其正确性
linear_model = LinearRegression()
linear_model.fit(x_train, y_train)
# 与测试样本结果比较,获取得分
y_pred = linear_model.predict(x_test)
# 以下两句效果一致
print("R方值:" + str(r2_score(y_test, y_pred)))
print("R方值:" + str(linear_model.score(x_test, y_test)))
plt.scatter(x_train, y_train, c='b', s=10)
# s 点的大小 前两个参数是横纵坐标,大小需要一样
plt.plot(x_test, y_pred, color='red', linewidth=1.0)
plt.show()














 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









