







简介
通常,使用Java来开发一个简单的并发应用程序时,会创建一些Runnable对象,然后创建对应的Thread 对象来控制程序中这些线程的创建、执行以及线程的状态。自从Java 5开始引入了Executor和ExecutorService接口以及实现这两个接口的类(比如ThreadPoolExecutor)之后,使得Java在并发支持上得到了进一步的提升。
执行器框架(Executor Framework)将任务的创建和执行进行了分离,通过这个框架,只需要实现Runnable接口的对象和使用Executor对象,然后将Runnable对象发送给执行器。执行器再负责运行这些任务所需要的线程,包括线程的创建,线程的管理以及线程的结束。
Java 7则又更进了一步,它包括了ExecutorService接口的另一种实现,用来解决特殊类型的问题,它就是Fork/Join框架,有时也称分解/合并框架。
Fork/Join框架是用来解决能够通过分治技术(Divide and Conquer Technique)将问题拆分成小任务的问题。在一个任务中,先检查将要解决的问题的大小,如果大于一个设定的大小,那就将问题拆分成可以通过框架来执行的小任务。如果问题的大小比设定的大小要小,就可以直接在任务里解决这个问题,然后,根据需要返回任务的结果。下面的图形总结了这个原理。
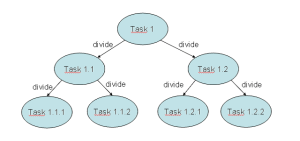
没有固定的公式来决定问题的参考大小(Reference Size),从而决定一个任务是需要进行拆分或不需要拆分,拆分与否仍是依赖于任务本身的特性。可以使用在任务中将要处理的元素的数目和任务执行所需要的时间来决定参考大小。测试不同的参考大小来决定解决问题最好的一个方案,将ForkJoinPool类看作一个特殊的 Executor 执行器类型。这个框架基于以下两种操作。
- 分解(Fork)操作:当需要将一个任务拆分成更小的多个任务时,在框架中执行这些任务;
- 合并(Join)操作:当一个主任务等待其创建的多个子任务的完成执行。
Fork/Join框架和执行器框架(Executor Framework)主要的区别在于工作窃取算法(Work-Stealing Algorithm)。与执行器框架不同,使用Join操作让一个主任务等待它所创建的子任务的完成,执行这个任务的线程称之为工作者线程(Worker Thread)。工作者线程寻找其他仍未被执行的任务,然后开始执行。通过这种方式,这些线程在运行时拥有所有的优点,进而提升应用程序的性能。
为了达到这个目标,通过Fork/Join框架执行的任务有以下限制。
- 任务只能使用fork()和join()操作当作同步机制。如果使用其他的同步机制,工作者线程就不能执行其他任务,当然这些任务是在同步操作里时。比如,如果在Fork/Join框架中将一个任务休眠,正在执行这个任务的工作者线程在休眠期内不能执行另一个任务。
- 任务不能执行I/O操作,比如文件数据的读取与写入。
- 任务不能抛出非运行时异常(Checked Exception),必须在代码中处理掉这些异常。
Fork/Join框架的核心是由下列两个类组成的。
- ForkJoinPool:这个类实现了ExecutorService接口和工作窃取算法(Work-Stealing Algorithm)。它管理工作者线程,并提供任务的状态信息,以及任务的执行信息。
- ForkJoinTask:这个类是一个将在ForkJoinPool中执行的任务的基类。
Fork/Join框架提供了在一个任务里执行fork()和join()操作的机制和控制任务状态的方法。通常,为了实现Fork/Join任务,需要实现一个以下两个类之一的子类。
- RecursiveAction:用于任务没有返回结果的场景。
- RecursiveTask:用于任务有返回结果的场景。
本章接下来将展示如何利用Fork/Join框架高效地工作。
创建Fork/Join线程池
在本节,我们将学习如何使用Fork/Join框架的基本元素。它包括:
- 创建用来执行任务的ForkJoinPool对象;
- 创建即将在线程池中被执行的任务ForkJoinTask子类。
本范例中即将使用的Fork/Join框架的主要特性如下:
- 采用默认的构造器创建ForkJoinPool对象;
- 在任务中将使用JavaAPI文档推荐的结构。
if (problem size > default size){
tasks=divide(task);
execute(tasks);
} else {
resolve problem using another algorithm;
}
- 我们将以同步的方式执行任务。当一个主任务执行两个或更多的子任务时,这个主任务将等待子任务的完成。用这种方法,执行主任务的线程,称之为工作者线程(Worker Thread),它将寻找其他的子任务来执行,并在子任务执行的时间里利用所有的线程优势。
- 如果将要实现的任务没有返回任何结果,那么,采用RecursiveAction类作为实现任务的基类。
准备工作
本节的范例是在EclipseIDE里完成的。无论你使用Eclipse还是其他的IDE(比如NetBeans),都可以打开这个IDE并且创建一个新的Java工程。
范例实现
在本节,我们将实现一项更新产品价格的任务。最初的任务将负责更新列表中的所有元素。我们使用10来作为参考大小(ReferenceSize),如果一个任务需要更新大于10个元素,它会将这个列表分解成为两部分,然后分别创建两个任务用来更新各自部分的产品价格。
按照接下来的步骤实现本节的范例。
1.创建一个名为Product的类,用来存储产品的名称和价格。
public class Product {
2.声明一个名为name的私有String属性,一个名为price的私有double属性。
private String name;
private double price;
3.实现两个属性各自的设值与取值方法。
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
4.创建一个名为ProductListGenerator的类,用来生成一个随机产品列表。
public class ProductListGenerator {
5.实现generate()方法。接收一个表示列表大小的int参数,并返回一个生成产品的List列表。
public List<Product> generate (int size) {
6.创建返回产品列表的对象ret。
List<Product> ret=new ArrayList<Product>();
7.生成产品列表,给所有的产品分配相同的价格,比如可以检查程序是否运行良好的数字10。
for (int i=0; i<size; i++){
Product product=new Product();
product.setName("Product "+i);
product.setPrice(10);
ret.add(product);
}
return ret;
}
8.创建一个名为Task的类,并继承RecursiveAction类。
public class Task extends RecursiveAction {
9.声明这个类的serialVersionUID属性。这个元素是必需的,因为RecursiveAction的父类ForkJoinTask实现了Serializable接口。
private static final long serialVersionUID = 1L;
10.声明一个名为products私有的List属性。
private List<Product> products;
11.声明两个私有的int属性,分别命名为first和last。这两个属性将决定任务执行时对产品的分块。
private int first;
private int last;
12.声明一个名为increment的私有double属性,用来存储产品价格的增加额。
private double increment;
13.实现类的构造器,用来初始化类的这些属性。
public Task (List<Product> products, int first, int last, double
increment) {
this.products=products;
this.first=first;
this.last=last;
this.increment=increment;
}
14.实现compute()方法,实现任务的执行逻辑。
@Override
protected void compute() {
15.如果last和first属性值的差异小于10(一个任务只能更新少于10件产品的价格),则调用updatePrices()方法增加这些产品的价格。
if (last-first<10) {
updatePrices();
16.如果last和first属性值的差异大于或等于10,就创建两个新的Task对象,一个处理前一半的产品,另一个处理后一半的产品,然后调用ForkJoinPool的invokeAll()方法来执行这两个新的任务。
} else {
int middle=(last+first)/2;
System.out.printf("Task: Pending tasks:
%s\n",getQueuedTaskCount());
Task t1=new Task(products, first,middle+1, increment);
Task t2=new Task(products, middle+1,last, increment);
invokeAll(t1, t2);
}
17.实现updatePrices()方法。这个方法用来更新在产品列表中处于first和last属性之间的产品。
private void updatePrices() {
for (int i=first; i<last; i++){
Product product=products.get(i);
product.setPrice(product.getPrice()*(1+increment));
}
}
18.实现范例的主类,创建Main主类,并实现main()方法。
public class Main {
public static void main(String[] args) {
19.使用ProductListGenerator类创建一个有10,000个产品的列表
ProductListGenerator generator=new ProductListGenerator();
List<Product> products=generator.generate(10000);
20.创建一个新的Task对象用来更新列表中的所有产品。参数first为0,参数last为产品列表的大小,即10,000。
Task task=new Task(products, 0, products.size(), 0.20);
21.通过无参的类构造器创建一个ForkJoinPool对象。
ForkJoinPool pool=new ForkJoinPool();
22.调用execute()方法执行任务。
pool.execute(task);
23.实现代码块,显示关于线程池演变的信息,每5毫秒在控制台上输出线程池的一些参数值,直到任务执行结束。
do {
System.out.printf("Main: Thread Count: %d\n",pool.
getActiveThreadCount());
System.out.printf("Main: Thread Steal: %d\n",pool.
getStealCount());
System.out.printf("Main: Parallelism: %d\n",pool.
getParallelism());
try {
TimeUnit.MILLISECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!task.isDone());
24.调用shutdown()方法关闭线程池。
pool.shutdown();
25.调用isCompletedNormally()方法,检查任务是否已经完成并且没有错误,在这个示例中,在控制台输出信息表示任务已经处理结束。
if (task.isCompletedNormally()){
System.out.printf("Main: The process has completed
normally.\n");
}
26.在增加之后,所有产品的期望价格是12元。在控制台输出所有产品的名称和价格,如果产品的价格不是12元,就将产品信息打印出来,以便确认所有的产品价格都正确地增加了。
for (int i=0; i<products.size(); i++){
Product product=products.get(i);
if (product.getPrice()!=12) {
System.out.printf("Product %s: %f\n",product.
getName(),product.getPrice());
}
}
27.在控制台输出信息表示程序执行结束。
System.out.println("Main: End of the program.\n");工作原理
在这个范例中,我们创建了ForkJoinPool对象,和一个将在线程池中执行的ForkJoinTask的子类。使用了无参的类构造器创建了ForkJoinPool对象,因此它将执行默认的配置。创建一个线程数等于计算机CPU数目的线程池,创建好ForkJoinPool对象之后,那些线程也创建就绪了,在线程池中等待任务的到达,然后开始执行。
由于Task类继承了RecursiveAction类,因此不返回结果。在本节,我们使用了推荐的结构来实现任务。如果任务需要更新大于10个产品,它将拆分这些元素为两部分,创建两个任务,并将拆分的部分相应地分配给新创建的任务。通过使用Task类的first和last属性,来获知任务将要更新的产品列表所在的位置范围。我们已经使用first和last属性,来操作产品列表中仅有的一份副本,而没有为每一个任务去创建不同的产品列表。
调用invokeAll()方法来执行一个主任务所创建的多个子任务。这是一个同步调用,这个任务将等待子任务完成,然后继续执行(也可能是结束)。当一个主任务等待它的子任务时,执行这个主任务的工作者线程接收另一个等待执行的任务并开始执行。正因为有了这个行为,所以说Fork/Join框架提供了一种比Runnable和Callable对象更加高效的任务管理机制。
ForkJoinTask类的invokeAll()方法是执行器框架(ExecutorFramework)和Fork/Join框架之间的主要差异之一。在执行器框架中,所有的任务必须发送给执行器,然而,在这个示例中,线程池中包含了待执行方法的任务,任务的控制也是在线程池中进行的。我们在Task类中使用了invokeAll()方法,Task类继承了RecursiveAction类,而RecursiveAction类则继承了ForkJoinTask类。
我们已经发送一个唯一的任务到线程池中,通过使用execute()方法来更新所有产品的列表。在这个示例中,它是一个同步调用,主线程一直等待调用的执行。
我们已经使用了ForkJoinPool类的一些方法,来检查正在运行的任务的状态和演变情况。这个类包含更多的方法,可以用于任务状态的检测。参见8.5节介绍的这些方法的完整列表。
最后,像执行器框架一样,必须调用shutdown()方法来结束ForkJoinPool的执行。
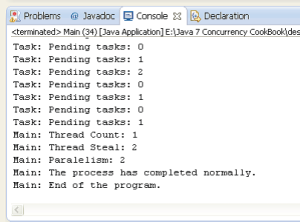
下面的截图展示了这个范例执行的部分结果。
可以看到,任务执行结束,并且产品的价格已经更新了。
更多信息
ForkJoinPool类还提供了以下方法用于执行任务。
- execute (Runnabletask):这是本范例中使用的execute()方法的另一种版本。这个方法发送一个Runnable任务给ForkJoinPool类。需要注意的是,使用Runnable对象时ForkJoinPool类就不采用工作窃取算法(Work-StealingAlgorithm),ForkJoinPool类仅在使用ForkJoinTask类时才采用工作窃取算法。
- invoke(ForkJoinTasktask):正如范例所示,ForkJoinPool类的execute()方法是异步调用的,而ForkJoinPool类的invoke()方法则是同步调用的。这个方法直到传递进来的任务执行结束后才会返回。
- 也可以使用在ExecutorService类中声明的invokeAll()和invokeAny()方法,这些方法接收Callable对象作为参数。使用Callable对象时ForkJoinPool类就不采用工作窃取算法(Work-StealingAlgorithm),因此,最好使用执行器来执行Callable对象。
ForkJoinTask类也包含了在范例中所使用的invokeAll()方法的其他版本,这些版本如下。
- invokeAll(ForkJoinTask< ? >… tasks):这个版本的方法接收一个可变的参数列表,可以传递尽可能多的ForkJoinTask对象给这个方法作为参数。
- invokeAll(Collectiontasks):这个版本的方法接受一个泛型类型T的对象集合(比如,ArrayList对象、LinkedList对象或者TreeSet对象)。这个泛型类型T必须是ForkJoinTask类或者它的子类。
虽然ForkJoinPool类是设计用来执行ForkJoinTask对象的,但也可以直接用来执行Runnable和Callable对象。当然,也可以使用ForkJoinTask类的adapt()方法来接收一个Callable对象或者一个Runnable对象,然后将之转化为一个ForkJoinTask对象,然后再去执行。
合并任务的结果
Fork/Join框架提供了执行任务并返回结果的能力。这些类型的任务都是通过RecursiveTask类来实现的。RecursiveTask类继承了ForkJoinTask类,并且实现了由执行器框架(Executor Framework)提供的Future接口。
在任务中,必须使用Java API文档推荐的如下结构:
if (problem size > size){
tasks=Divide(task);
execute(tasks);
groupResults()
return result;
} else {
resolve problem;
return result;
}
如果任务需要解决的问题大于预先定义的大小,那么就要将这个问题拆分成多个子任务,并使用Fork/Join框架来执行这些子任务。执行完成后,原始任务获取到由所有这些子任务产生的结果,合并这些结果,返回最终的结果。当原始任务在线程池中执行结束后,将高效地获取到整个问题的最终结果。
在本节,我们将学习如何使用Fork/Join框架来解决这种问题,开发一个应用程序,在文档中查找一个词。我们将实现以下两种任务:
- 一个文档任务,它将遍历文档中的每一行来查找这个词;
- 一个行任务,它将在文档的一部分当中查找这个词。
所有这些任务将返回文档或行中所出现这个词的次数。
准备工作
本节的范例是在EclipseIDE里完成的。无论你使用Eclipse还是其他的IDE(比如NetBeans),都可以打开这个IDE并且创建一个新的Java工程。
范例实现
按照接下来的步骤实现本节的范例。
1.创建一个名为DocumentMock的类。它将生成一个字符串矩阵来模拟一个文档。
public class Document {
2.用一些词来创建一个字符串数组。这个数组将被用来生成字符串矩阵。
private String words[]={"the","hello","goodbye","packt", "java","t
hread","pool","random","class","main"};
3.实现generateDocument()方法。它接收3个参数,分别是行数numLines,每一行词的个数numWords,和准备查找的词word。然后返回一个字符串矩阵。
public String[][] generateDocument(int numLines, int numWords,
String word){
4.创建用来生成文档所需要的对象:String矩阵,和用来生成随机数的Random对象。
int counter=0;
String document[][]=new String[numLines][numWords];
Random random=new Random();
5.为字符串矩阵填上字符串。通过随机数取得数组words中的某一字符串,然后存入到字符串矩阵document对应的位置上,同时计算生成的字符串矩阵中将要查找的词出现的次数。这个值可以用来与后续程序运行查找任务时统计的次数相比较,检查两个值是否相同。
for (int i=0; i<numLines; i++){
for (int j=0; j<numWords; j++) {
int index=random.nextInt(words.length);
document[i][j]=words[index];
if (document[i][j].equals(word)){
counter++;
}
}
}
6.在控制台输出这个词出现的次数,并返回生成的矩阵document。
System.out.println("DocumentMock: The word appears "+
counter+" times in the document");
return document;
7.创建名为DocumentTask的类,并继承RecursiveTask类,RecursiveTask类的泛型参数为Integer类型。这个DocumentTask类将实现一个任务,用来计算所要查找的词在行中出现的次数。
public class DocumentTask extends RecursiveTask<Integer> {
8.声明一个名为document的私有String矩阵,以及两个名为start和end的私有int属性,并声明一个名为word的私有String属性。
private String document[][];
private int start, end;
private String word;
9.实现类的构造器,用来初始化类的所有属性。
public DocumentTask (String document[][], int start, int end,
String word){
this.document=document;
this.start=start;
this.end=end;
this.word=word;
}
10.实现compute()方法。如果end和start的差异小于10,则调用processLines()方法,来计算这两个位置之间要查找的词出现的次数。
@Override
protected Integer compute() {
int result;
if (end-start<10){
result=processLines(document, start, end, word);
11.否则,拆分这些行成为两个对象,并创建两个新的DocumentTask对象来处理这两个对象,然后调用invokeAll()方法在线程池里执行它们。
} else {
int mid=(start+end)/2;
DocumentTask task1=new DocumentTask(document,start,mid,word);
DocumentTask task2=new DocumentTask(document,mid,end,word);
invokeAll(task1,task2);
12.采用groupResults()方法将这两个任务返回的值相加。最后,返回任务计算的结果。
try {
result=groupResults(task1.get(),task2.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return result;
13.实现processLines()方法。接收4个参数,一个字符串document矩阵,start属性,end属性和任务将要查找的词word的属性。
private Integer processLines(String[][] document, int start, int
end,String word) {
14.为任务所要处理的每一行,创建一个LineTask对象,然后存储在任务列表里。
List<LineTask> tasks=new ArrayList<LineTask>();
for (int i=start; i<end; i++){
LineTask task=new LineTask(document[i], 0, document[i].
length, word);
tasks.add(task);
}
15.调用invokeAll()方法执行列表中所有的任务。
invokeAll(tasks);
16.合计这些任务返回的值,并返回结果。
int result=0;
for (int i=0; i<tasks.size(); i++) {
LineTask task=tasks.get(i);
try {
result=result+task.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return new Integer(result);
17.实现groupResults()方法。它将两个数字相加并返回结果。
private Integer groupResults(Integer number1, Integer number2) {
Integer result;
result=number1+number2;
return result;
}
18.创建名为LineTask的类,并继承RecursiveTask类,RecursiveTask类的泛型参数为Integer类型。这个RecursiveTask类实现了一个任务,用来计算所要查找的词在一行中出现的次数。
public class LineTask extends RecursiveTask<Integer>{
19.声明类的serialVersionUID属性。这个元素是必需的,因为RecursiveTask的父类ForkJoinTask实现了Serializable接口。声明一个名为line的私有String数组属性和两个名为start和end的私有int属性。最后,声明一个名为word的私有String属性。
private static final long serialVersionUID = 1L;
private String line[];
private int start, end;
private String word;
20.实现类的构造器,用来初始化它的属性。
public LineTask(String line[], int start, int end, String word)
{
this.line=line;
this.start=start;
this.end=end;
this.word=word;
}
21.实现compute()方法。如果end和start属性的差异小于100,那么任务将采用count()方法,在由start与end属性所决定的行的片断中查找词。
@Override
protected Integer compute() {
Integer result=null;
if (end-start<100) {
result=count(line, start, end, word);
22.如果end和start属性的差异不小于100,将这一组词拆分成两组,然后创建两个新的LineTask对象来处理这两个组,调用invokeAll()方法在线程池中执行它们。
} else {
int mid=(start+end)/2;
LineTask task1=new LineTask(line, start, mid, word);
LineTask task2=new LineTask(line, mid, end, word);
invokeAll(task1, task2);
23.调用groupResults()方法将两个任务返回的值相加。最后返回任务计算的结果。
try {
result=groupResults(task1.get(),task2.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
return result;
24.实现count()方法。它接收4个参数,一个完整行字符串line数组,start属性,end属性和任务将要查找的词word的属性。
private Integer count(String[] line, int start, int end, String
word) {
25.将存储在start和end属性值之间的词与任务正在查找的word属性相比较。如果相同,那么将计数器counter变量加1。
int counter;
counter=0;
for (int i=start; i<end; i++){
if (line[i].equals(word)){
counter++;
}
}
26.为了延缓范例的执行,将任务休眠10毫秒。
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
27.返回计数器counter变量的值。
return counter;
28.实现groupResults()方法。计算两个数字之和并返回结果。.
private Integer groupResults(Integer number1, Integer number2) {
Integer result;
result=number1+number2;
return result;
}
29.实现范例的主类,创建Main主类,并实现main()方法。
public class Main{
public static void main(String[] args) {
30.创建Document对象,包含100行,每行1,000个词。
DocumentMock mock=new DocumentMock();
String[][] document=mock.generateDocument(100, 1000, "the");
31.创建一个DocumentTask对象,用来更新整个文档。传递数字0给参数start,以及数字100给参数end。
DocumentTask task=new DocumentTask(document, 0, 100, "the");
32.采用无参的构造器创建一个ForkJoinPool对象,然后调用execute()方法在线程池里执行这个任务。
ForkJoinPool pool=new ForkJoinPool();
pool.execute(task);
33.实现代码块,显示线程池的进展信息,每秒钟在控制台输出线程池的一些参数,直到任务执行结束。
do {
System.out.printf("******************************************\n");
System.out.printf("Main: Parallelism: %d\n",pool.getParallelism());
System.out.printf("Main: Active Threads: %d\n",pool.getActiveThreadCount());
System.out.printf("Main: Task Count: %d\n",pool.getQueuedTaskCount());
System.out.printf("Main: Steal Count: %d\n",pool.getStealCount());
System.out.printf("******************************************\n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while (!task.isDone());
34.调用shutdown()方法关闭线程池。
pool.shutdown();
35.调用awaitTermination()等待任务执行结束。
try {
pool.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
36.在控制台输出文档中出现要查找的词的次数。检验这个数字与DocumentMock类输出的数字是否一致。
try {
System.out.printf("Main: The word appears %d in the document",task.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
工作原理
在这个范例中,我们实现了两个不同的任务。
- DocumentTask类:这个类的任务需要处理由start和end属性决定的文档行。如果这些行数小于10,那么,就每行创建一个LineTask对象,然后在任务执行结束后,合计返回的结果,并返回总数。如果任务要处理的行数大于10,那么,将任务拆分成两组,并创建两个DocumentTask对象来处理这两组对象。当这些任务执行结束后,同样合计返回的结果,并返回总数。
- LineTask类:这个类的任务需要处理文档中一行的某一组词。如果一组词的个数小100,那么任务将直接在这一组词里搜索特定词,然后返回查找词在这一组词中出现的次数。否则,任务将拆分这些词为两组,并创建两个LineTask对象来处理这两组词。当这些任务执行完成后,合计返回的结果,并返回总数。
在Main主类中,我们通过默认的构造器创建了ForkJoinPool对象,然后执行DocumentTask类,来处理一个共有100行,每行1,000字的文档。这个任务将问题拆分成DocumentTask对象和LineTask对象,然后当所有的任务执行完成后,使用原始的任务来获取整个文档中所要查找的词出现的次数。由于任务继承了RecursiveTask类,因此能够返回结果。
调用get()方法来获得Task返回的结果。这个方法声明在Future接口里,并由RecursiveTask类实现。
执行程序时,在控制台上,我们可以比较第一行与最后一行的输出信息。第一行是文档生成时被查找的词出现的次数,最后一行则是通过Fork/Join任务计算而来的被查找的词出现的次数,而且这两个数字相同。
更多信息
ForkJoinTask类提供了另一个complete()方法来结束任务的执行并返回结果。这个方法接收一个对象,对象的类型就是RecursiveTask类的泛型参数,然后在任务调用join()方法后返回这个对象作为结果。这一过程采用了推荐的异步任务来返回任务的结果。
由于RecursiveTask类实现了Future接口,因此还有get()方法调用的其他版本:
get(long timeout, TimeUnit unit):这个版本中,如果任务的结果未准备好,将等待指定的时间。如果等待时间超出,而结果仍未准备好,那方法就会返回null值。
TimeUnit是一个枚举类,有如下的常量:DAYS、HOURS、MICROSECONDS、MILLISECONDS、MINUTES、NANOSECONDS和SECONDS。
异步运行任务
在ForkJoinPool中执行 ForkJoinTask时,可以采用同步或异步方式。当采用同步方式执行时,发送任务给Fork/Join线程池的方法直到任务执行完成后才会返回结果。而采用异步方式执行时,发送任务给执行器的方法将立即返回结果,但是任务仍能够继续执行。
需要明白这两种方式在执行任务时的一个很大的区别。当采用同步方式,调用这些方法(比如,invokeAll()方法)时,任务被挂起,直到任务被发送到Fork/Join线程池中执行完成。这种方式允许ForkJoinPool类采用工作窃取算法(Work-StealingAlgorithm)来分配一个新任务给在执行休眠任务的工作者线程(WorkerThread)。相反,当采用异步方法(比如,fork()方法)时,任务将继续执行,因此ForkJoinPool类无法使用工作窃取算法来提升应用程序的性能。在这个示例中,只有调用join()或get()方法来等待任务的结束时,ForkJoinPool类才可以使用工作窃取算法。
本节将学习如何使用ForkJoinPool和ForkJoinTask类所提供的异步方法来管理任务。我们将实现一个程序:在一个文件夹及其子文件夹中来搜索带有指定扩展名的文件。ForkJoinTask类将实现处理这个文件夹的内容。而对于这个文件夹中的每一个子文件,任务将以异步的方式发送一个新的任务给ForkJoinPool类。对于每个文件夹中的文件,任务将检查任务文件的扩展名,如果符合条件就将其增加到结果列表中。
准备工作
本节的范例是在EclipseIDE里完成的。无论你使用Eclipse还是其他的IDE(比如NetBeans),都可以打开这个IDE并且创建一个新的Java工程。
范例实现
按照接下来的步骤实现本节的范例。
1.创建名为FolderProcessor的类,并继承RecursiveTask类,RecursiveTask类的泛型参数为List类型。
public class FolderProcessor extends RecursiveTask<List<String>> {
2.声明类的serialVersionUID属性。这个元素是必需的,因为RecursiveTask类的父类ForkJoinTask实现了Serializable接口。
private static final long serialVersionUID = 1L;
3.声明一个名为path的私有String属性,用来存储任务将要处理的文件夹的完整路径。
private String path;
4.声明一个名为extension的私有String属性,用来存储任务将要查找的文件的扩展名。
private String extension;
5.实现类的构造器,用来初始化这些属性。
public FolderProcessor (String path, String extension) {
this.path=path;
this.extension=extension;
}
6.实现compute()方法。既然指定了RecursiveTask类泛型参数为List类型,那么,这个方法必须返回一个同样类型的对象。
@Override
protected List<String> compute() {
7.声明一个名为list的String对象列表,用来存储文件夹中文件的名称。
List<String> list=new ArrayList<>();
8.声明一个名为tasks的FolderProcessor任务列表,用来存储子任务,这些子任务将处理文件夹中的子文件夹。
List<FolderProcessor> tasks=new ArrayList<>();
9.获取文件夹的内容。
File file=new File(path);
File content[] = file.listFiles();
10.对于文件夹中的每一个元素,如果它是子文件夹,就创建一个新的FolderProcessor对象,然后调用fork()方法采用异步方式来执行它。
if (content != null) {
for (int i = 0; i < content.length; i++) {
if (content[i].isDirectory()) {
FolderProcessor task=new FolderProcessor(content[i].getAbsolutePath(), extension);
task.fork();
tasks.add(task);
11.否则,调用checkFile()方法来比较文件的扩展名。如果文件的扩展名与将要搜索的扩展名相同,就将文件的完整路径存储到第7步声明的列表中。
} else {
if (checkFile(content[i].getName())){
list.add(content[i].getAbsolutePath());
}
}
}
12.如果FolderProcessor子任务列表超过50个元素,那么就在控制台输出一条信息表示这种情景。
if (tasks.size()>50) {
System.out.printf("%s: %d tasks ran.\n",file.
getAbsolutePath(),tasks.size());
}
13.调用addResultsFromTask()辅助方法。它把通过这个任务而启动的子任务返回的结果增加到文件列表中。传递两个参数给这个方法,一个是字符串列表list,一个是FolderProcessor子任务列表tasks。
addResultsFromTasks(list,tasks);
14.返回字符串列表。
return list;
15.实现addResultsFromTasks()方法。遍历任务列表中存储的每一个任务,调用join()方法等待任务执行结束,并且返回任务的结果。然后,调用addAll()方法将任务的结果增加到字符串列表中。
private void addResultsFromTasks(List<String> list,
List<FolderProcessor> tasks) {
for (FolderProcessor item: tasks) {
list.addAll(item.join());
}
}
16.实现checkFile()方法。这个方法检查作为参数而传递进来的文件名,如果是以正在搜索的文件扩展名为结尾,那么方法就返回true,否则就返回false。
private boolean checkFile(String name) {
return name.endsWith(extension);
}
17.实现范例的主类,创建Main主类,并实现main()方法。
public class Main {
public static void main(String[] args) {
18.通过默认的构造器创建ForkJoinPool线程池。
ForkJoinPool pool=new ForkJoinPool();
19.创建3个FolderProcessor任务,并使用不同的文件夹路径来初始化这些任务。
FolderProcessor system=new FolderProcessor("C:\\Windows","log");
FolderProcessor apps=new FolderProcessor("C:\\Program Files","log");
FolderProcessor documents=new FolderProcessor("C:\\Documents And Settings","log");
20.调用execute()方法执行线程池里的3个任务。
pool.execute(system);
pool.execute(apps);
pool.execute(documents);
21.在控制台上每隔1秒钟输出线程池的状态信息,直到这3个任务执行结束。
do {
System.out.printf("*****************************************
*\n");
System.out.printf("Main: Parallelism: %d\n",pool.
getParallelism());
System.out.printf("Main: Active Threads: %d\n",pool.
getActiveThreadCount());
System.out.printf("Main: Task Count: %d\n",pool.
getQueuedTaskCount());
System.out.printf("Main: Steal Count: %d\n",pool.
getStealCount());
System.out.printf("*****************************************
*\n");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} while ((!system.isDone())||(!apps.isDone())||(!documents.isDone()));
22.调用shutdown()方法关闭ForkJoinPool线程池。
pool.shutdown();
23.在控制台输出每一个任务产生的结果的大小。
List<String> results;
results=system.join();
System.out.printf("System: %d files found.\n",results.size());
results=apps.join();
System.out.printf("Apps: %d files found.\n",results.size());
results=documents.join();
System.out.printf("Documents: %d files found.\n",results.size());
工作原理
下面的截图显示了范例的部分运行结果。
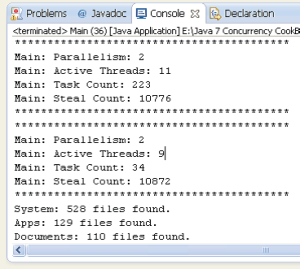
这个范例的重点在于FolderProcessor类。每一个任务处理一个文件夹中的内容。文件夹中的内容有以下两种类型的元素:
- 文件;
- 其他文件夹。
如果主任务发现一个文件夹,它将创建另一个Task对象来处理这个文件夹,调用fork()方法把这个新对象发送到线程池中。fork()方法发送任务到线程池时,如果线程池中有空闲的工作者线程(WorkerThread)或者将创建一个新的线程,那么开始执行这个任务,fork()方法会立即返回,因此,主任务可以继续处理文件夹里的其他内容。对于每一个文件,任务开始比较它的文件扩展名,如果与要搜索的扩展名相同,那么将文件的完整路径增加到结果列表中。
一旦主任务处理完指定文件夹里的所有内容,它将调用join()方法等待发送到线程池中的所有子任务执行完成。join()方法在主任务中被调用,然后等待任务执行结束,并通过compute()方法返回值。主任务将所有的子任务结果进行合并,这些子任务发送到线程池中时带有自己的结果列表,然后通过调用compute()方法返回这个列表并作为主任务的返回值。
ForkJoinPool类也允许以异步的方式执行任务。调用execute()方法发送3个初始任务到线程池中。在Main主类中,调用shutdown()方法结束线程池,并在控制台输出线程池中任务的状态及其变化的过程。ForkJoinPool类包含了多个方法可以实现这个目的。参考8.5节来查阅这些方法的详细列表。
更多信息
本范例使用join()方法来等待任务的结束,然后获取它们的结果。也可以使用get()方法以下的两个版本来完成这个目的。
- get():如果ForkJoinTask类执行结束,或者一直等到结束,那么get()方法的这个版本则返回由compute()方法返回的结果。
- get(long timeout, TimeUnit unit):如果任务的结果未准备好,那么get()方法的这个版本将等待指定的时间。如果超过指定的时间了,任务的结果仍未准备好,那么这 个方法将返回null值。TimeUnit是一个枚举类,有如下的常量:DAYS、HOURS、MICROSECONDS、MILLISECONDS、MINUTES、NANOSECONDS和SECONDS。
get()方法和join()方法还存在两个主要的区别:
- join()方法不能被中断,如果中断调用join()方法的线程,方法将抛出InterruptedException异常;
- 如果任务抛出任何运行时异常,那么get()方法将返回ExecutionException异常,但是join()方法将返回RuntimeException异常。
在任务中抛出异常
Java有两种类型的异常。
- 非运行时异常(Checked
Exception):这些异常必须在方法上通过throws子句抛出,或者在方法体内通过try{…}catch{…}方式进行捕捉处理。比如IOException或ClassNotFoundException异常。 - 运行时异常(Unchecked
Exception):这些异常不需要在方法上通过throws子句抛出,也不需要在方法体内通过try{…}catch{…}方式进行捕捉处理。比如NumberFormatException异常。
不能在ForkJoinTask类的compute()方法中抛出任务非运行时异常,因为这个方法的实现没有包含任何throws声明。因此,需要包含必需的代码来处理相关的异常。另一方面,compute()方法可以抛出运行时异常(它可以是任何方法或者方法内的对象抛出的异常)。ForkJoinTask类和ForkJoinPool类的行为与我们期待的可能不同。在控制台上,程序没有结束执行,不能看到任务异常信息。如果异常不被抛出,那么它只是简单地将异常吞噬掉。然而,我们能够利用ForkJoinTask类的一些方法来获知任务是否有异常抛出,以及抛出哪一种类型的异常。在本节,我们将学习如何获取这些异常信息。
准备工作
本节的范例是在Eclipse IDE里完成的。无论你使用Eclipse还是其他的IDE(比如NetBeans),都可以打开这个IDE并且创建一个新的Java工程。
范例实现
按照接下来的步骤实现本节的范例。
1.创建名为Task的类,并继承RecursiveTask类,RecursiveTask类的泛型参数为Integer 类型。
public class Task extends RecursiveTask<Integer> {2.声明一个名为array的私有int数组。用来模拟在这个范例中即将处理的数据数组。
private int array[];
3.声明两个分别名为start和end的私有int属性。这些属性将决定任务要处理的数组元素。
private int start, end;
4.实现类的构造器,用来初始化类的属性。
public Task(int array[], int start, int end){
this.array=array;
this.start=start;
this.end=end;
}
5.实现任务的compute()方法。由于指定了Integer类型作为RecursiveTask的泛型类型,因此这个方法必须返回一个Integer对象。在控制台输出start和end属性。
@Override
protected Integer compute() {
System.out.printf("Task: Start from %d to %d\n",start,end);
6.如果由start和end属性所决定的元素块规模小于10,那么直接检查元素,当碰到元素块的第4个元素(索引位为3)时,就抛出RuntimeException异常。然后将任务休眠1秒钟。
if (end-start<10) {
if ((3>start)&&(3<end)){
throw new RuntimeException("This task throws an"+"Exception: Task from "+start+" to "+end);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
7.如果要处理的元素块规模大于或等于10,就拆分这个元素块为两部分,并创建 两个Task对象来处理这两部分,然后调用invokeAll()方法在线程池中执行这两个Task对象。
} else {
int mid=(end+start)/2;
Task task1=new Task(array,start,mid);
Task task2=new Task(array,mid,end);
invokeAll(task1, task2);
}
8.在控制台输出信息,表示任务结束,并输出start和end属性值。
System.out.printf("Task: End form %d to %d\n",start,end);
9.返回数字0作为任务的结果。
return 0;
10.实现范例的主类,创建Main主类,并实现main()方法。
public class Main {
public static void main(String[] args) {
11.创建一个名为array并能容纳100个整数的int数组。
int array[]=new int[100];
12.创建一个Task对象来处理这个数组。
Task task=new Task(array,0,100);
13.通过默认的构造器创建ForkJoinPool对象。
ForkJoinPool pool=new ForkJoinPool();
14.调用execute()方法在线程池中执行任务。
pool.execute(task);
15.调用shutdown()方法关闭线程池。
pool.shutdown();
16. 调用awaitTermination()方法等待任务执行结束。如果想一直等待到任务执行完成,那就传递值1和TimeUnit.DAYS作为参数给这个方法。
try {
pool.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
17 . 调用isCompletedAbnormally()方法来检查主任务或者它的子任务之一是否抛出了异常。在这个示例中,在控制台输出信息就表示有异常抛出。调用ForkJoinTask类的getException()方法来获取异常信息。
if (task.isCompletedAbnormally()) {
System.out.printf("Main: An exception has ocurred\n");
System.out.printf("Main: %s\n",task.getException());
}
System.out.printf("Main: Result: %d",task.join());
工作原理
在本节,我们实现的Task类用来处理一个数字数组。它检查要处理的数字块规模是否包含有10个或更多个元素。在这个情况下,Task类拆分这个数字块为两部分,然后创建两个新的Task对象用来处理这两部分。否则,它将寻找位于数组中第4个位置(索引位为3)的元素。如果这个元素位于任务处理块中,它将抛出一个RuntimeException异常。
虽然运行这个程序时将抛出异常,但是程序不会停止。在Main主类中,调用原始任务ForkJoinTask类的isCompletedAbnormally()方法,如果主任务或者它的子任务之一抛出了异常,这个方法将返回true。也可以使用getException()方法来获得抛出的Exception对象。
当任务抛出运行时异常时,会影响它的父任务(发送到ForkJoinPool类的任务),以及父任务的父任务,以此类推。查阅程序的输出结果,将会发现有一些任务没有结束的信息。那些任务的开始信息如下:
Task: Starting form 0 to 100
Task: Starting form 0 to 50
Task: Starting form 0 to 25
Task: Starting form 0 to 12
Task: Starting form 0 to 6
这些任务是那些抛出异常的任务和它的父任务。所有这些任务都是异常结束的。记住一点:在用ForkJoinPool对象和ForkJoinTask对象开发一个程序时,它们是会抛出异常的,如果不想要这种行为,就得采用其他方式。
下面的截屏展示了这个范例运行的部分结果。
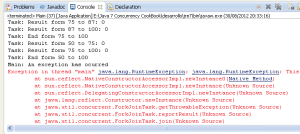
更多信息
在范例中,不采用抛出异常,而调用ForkJoinTask类的completeExceptionally()方法也可以获得同样的结果。代码如下所示:
Exception e=new Exception("This task throws an Exception: "+ "Task from "+start+" to "+end);
completeExceptionally(e);
取消任务
在ForkJoinPool类中执行ForkJoinTask对象时,在任务开始执行前可以取消它。ForkJoinTask类提供了cancel()方法来达到取消任务的目的。在取消一个任务时必须要注意以下两点:
ForkJoinPool类不提供任何方法来取消线程池中正在运行或者等待运行的所有任务;
取消任务时,不能取消已经被执行的任务。
在本节,我们将实现一个取消ForkJoinTask对象的范例。该范例将寻找数组中某个数字所处的位置。第一个任务是寻找可以被取消的剩余任务数。由于Fork/Join框架没有提供取消功能,我们将创建一个辅助类来实现取消任务的操作。
准备工作
本节的范例是在EclipseIDE里完成的。无论你使用Eclipse还是其他的IDE(比如NetBeans),都可以打开这个IDE并且创建一个新的Java工程。
范例实现
按照接下来的步骤实现本节的范例。
1.创建一个名为ArrayGenerator的类。这个类将生成一个指定大小的随机整数数组。实现generateArray()方法,它将生成数字数组,接收一个int参数表示数组的大小。
public class ArrayGenerator {
public int[] generateArray(int size) {
int array[]=new int[size];
Random random=new Random();
for (int i=0; i<size; i++){
array[i]=random.nextInt(10);
}
return array;
}
2.创建一个名为TaskManager的类。本示例将利用这个类来存储在ForkJoinPool中执行的任务。由于ForkJoinPool和ForkJoinTask类的局限性,将利用TaskManager类来取消ForkJoinPool类中所有的任务。
public class TaskManager {
3.声明一个名为tasks的对象列表,带有ForkJoinTask泛型参数,并且ForkJoinTask带有Integer泛型参数。
private List<ForkJoinTask<Integer>> tasks;
4.实现类的构造器,用来初始化任务列表。
public TaskManager(){
tasks=new ArrayList<>();
}
5.实现addTask()方法。增加一个ForkJoinTask对象到任务列表中。
public void addTask(ForkJoinTask<Integer> task){
tasks.add(task);
}
6.实现cancelTasks()方法。遍历存储在列表中的所有ForkJoinTask对象,然后调用cancel()方法取消之。cancelTasks()方法接收一个要取消剩余任务的ForkJoinTask对象作为参数,然后取消所有的任务。
public void cancelTasks(ForkJoinTask<Integer> cancelTask){
for (ForkJoinTask<Integer> task :tasks) {
if (task!=cancelTask) {
task.cancel(true);
((SearchNumberTask)task).writeCancelMessage();
}
}
}
7.实现SearchNumberTask类,并继承RecursiveTask类,RecursiveTask类的泛型参数为Integer类型。这个类将寻找在整数数组元素块中的一个数字。
public class SearchNumberTask extends RecursiveTask<Integer> {
8.声明一个名为array的私有int数组。
private int numbers[];
9.声明两个分别名为start和end的私有int属性。这两个属性将决定任务所要处理的数组的元素。private int start, end;
10.声明一个名为number的私有int属性,用来存储将要寻找的数字。
private int number;
11.声明一个名为manager的私有TaskManager属性。利用这个对象来取消所有的任务。
private TaskManager manager;
12.声明一个int常量,并初始化其值为-1。当任务找不到数字时将返回这个常量。
private final static int NOT_FOUND=-1;
13.实现类的构造器,用来初始化它的属性。
public Task (int numbers[], int start, int end, int number,
TaskManager manager){
this.numbers=numbers;
this.start=start;
this.end=end;
this.number=number;
this.manager=manager;
}
14.实现compute()方法。在控制台输出信息表示任务开始,并输出start和end的属性值。
@Override
protected Integer compute() {
System.out.println("Task: "+start+":"+end);
15.如果start和end属性值的差异大于10(任务必须处理大于10个元素的数组),那么,就调用launchTasks()方法将这个任务拆分为两个子任务。
int ret;
if (end-start>10) {
ret=launchTasks();
16.否则,寻找在数组块中的数字,调用lookForNumber()方法处理这个任务。
} else {
ret=lookForNumber();
}
17.返回任务的结果。
return ret;
18.实现lookForNumber()方法。
private int lookForNumber() {
19.遍历任务所要处理的数组块中的所有元素,将元素中存储的数字和将要寻找的数字进行比较。如果它们相等,就在控制台输出信息表示找到了,并用TaskManager对象的cancelTasks()方法取消所有的任务,然后返回已找到的这个元素所在的位置。
for (int i=start; i<end; i++){
if (numbers[i]==number) {
System.out.printf("Task: Number %d found in position %d\n",number,i);
manager.cancelTasks(this);
return i;
}
20.在循环体中,将任务休眠1秒钟。
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
21.返回-1表示没有找到元素。
return NOT_FOUND;
}
22.实现launchTasks()方法。将这个任务要处理的元素块拆分成两部分,然后创建两个Task对象来处理它们。
private int launchTasks() {
int mid=(start+end)/2;
Task task1=new Task(array,start,mid,number,manager);
Task task2=new Task(array,mid,end,number,manager);
23.增加任务到TaskManager对象中。
manager.addTask(task1);
manager.addTask(task2);
24.调用fork()方法采用异步方式执行这两个任务。
task1.fork();
task2.fork();
25.等待任务结束,如果第一个任务返回的结果不为-1,则返回第一个任务的结果;否则返回第二个任务的结果。
int returnValue;
returnValue=task1.join();
if (returnValue!=-1) {
return returnValue;
}
returnValue=task2.join();
return returnValue;
26.实现writeCancelMessage()方法,在控制台输入信息表示任务已经取消了。
public void writeCancelMessage(){
System.out.printf("Task: Cancelled task from %d to %d",start,end);
}
27.实现范例的主类,创建Main主类,并实现main()方法。
public class Main {
public static void main(String[] args) {
28.用ArrayGenerator类创建一个容量为1,000的数字数组。
ArrayGenerator generator=new ArrayGenerator();
int array[]=generator.generateArray(1000);
29.创建一个TaskManager对象。
TaskManager manager=new TaskManager();
30.通过默认的构造器创建一个ForkJoinPool对象。
ForkJoinPool pool=new ForkJoinPool();
31.创建一个Task对象用来处理第28步生成的数组。
Task task=new Task (array,0,1000,5,manager);
32.调用execute()方法采用异步方式执行线程池中的任务。
pool.execute(task);
33.调用shutdown()方法关闭线程池。
pool.shutdown();
34.调用ForkJoinPool类的awaitTermination()方法等待任务执行结束。
try {
pool.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
e.printStackTrace();
}
35.在控制台输出信息表示程序结束。
System.out.printf("Main: The program has finished\n");
工作原理
ForkJoinTask类提供的cancel()方法允许取消一个仍没有被执行的任务,这是非常重要的一点。如果任务已经开始执行,那么调用cancel()方法也无法取消。这个方法接收一个名为mayInterruptIfRunning的boolean值参数。顾名思义,如果传递true值给这个方法,即使任务正在运行也将被取消。JavaAPI文档指出,ForkJoinTask类的默认实现,这个属性没有起作用。如果任务还没有开始执行,那么这些任务将被取消。任务的取消对于已发送到线程池中的任务没有影响,它们将继续执行。
Fork/Join框架的局限性在于,ForkJoinPool线程池中的任务不允许被取消。为了克服这种局限性,我们实现了TaskManager类,它存储发送到线程池中的所有任务,可以用一个方法来取消存储的所有任务。如果任务正在运行或者已经执行结束,那么任务就不能被取消,cancel()方法返回false值,因此可以尝试去取消所有的任务而不用担心可能带来的间接影响。
这个范例实现在数字数组中寻找一个数字。根据Fork/Join框架的推荐,我们将问题拆分为更小的子问题。由于我们仅关心数字的一次出现,因此,当找到它时,就会取消其他的所有任务。
下面的截图展示了范例执行的部分结果。
转载自:http://ifeve.com/java7-concurrency-cookbook-4/
参考:http://ifeve.com/a-java-fork-join-framework/
http://ifeve.com/fork-and-join-java/
http://www.cnblogs.com/wanly3643/p/3951659.html
http://tigerlchen.iteye.com/blog/1807648
http://blog.csdn.net/birthdog/article/details/6849811
http://blog.csdn.net/aesop_wubo/article/details/10305277















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









