









为什么要加锁?加锁是为了防止不同的线程访问同一共享资源造成混乱。
打个比方:人是不同的线程,卫生间是共享资源
你在上洗手间的时候肯定要把门锁上吧,这就是加锁,只要你在里面,这个卫生间就被锁了,只有你出来之后别人才能用。想象一下如果卫生间的门没有锁会是什么样?
什么是加锁粒度呢?所谓加锁粒度就是你要锁住的范围是多大。
比如你在家上卫生间,你只要锁住卫生间就可以了吧,不需要将整个家都锁起来不让家人进门吧,卫生间就是你的加锁粒度。
怎样才算合理的加锁粒度呢?
其实卫生间并不只是用来上厕所的,还可以洗澡,洗手。这里就涉及到优化加锁粒度的问题。
你在卫生间里洗澡,其实别人也可以同时去里面洗手,只要做到隔离起来就可以,如果马桶,浴缸,洗漱台都是隔开相对独立的,实际上卫生间可以同时给三个人使用,
当然三个人做的事儿不能一样。这样就细化了加锁粒度,你在洗澡的时候只要关上浴室的门,别人还是可以进去洗手的。如果当初设计卫生间的时候没有将不同的功能区域划分
隔离开,就不能实现卫生间资源的最大化使用。这就是设计架构的重要性。在高负载多线程应用中性能是非常重要的。为了达到更好的性能,开发者必须意识到并发的重要性。当我们需要使用并发时, 常常有一个资源必须被两个或多个线程共享。
在这种情况下,就存在一个竞争条件,也就是其中一个线程可以得到锁(锁与特定资源绑定),其他想要得到锁的线程会被阻塞。这个同步机制的实现是有代价的,为了向你提供一个好用的同步模型,JVM和操作系统都要消耗资源。有三个最重要的因素使并发的实现会消耗大量资源,它们是:
- 上下文切换
- 内存同步
- 阻塞
为了写出针对同步的优化代码,你必须认识到这三个因素以及如何减少它们。在写这样的代码时你需要注意很多东西。在本文中,我会向你介绍一种通过降低锁粒度的技术来减少这些因素。
让我们从一个基本原则开始:不要长时间持有不必要的锁。
在获得锁之前做完所有需要做的事,只把锁用在需要同步的资源上,用完之后立即释放它。我们来看一个简单的例子:
public class HelloSync {
private Map dictionary = new HashMap();
public synchronized void borringDeveloper(String key, String value) {
long startTime = (new java.util.Date()).getTime();
value = value + "_"+startTime;
dictionary.put(key, value);
System.out.println("I did this in "+
((new java.util.Date()).getTime() - startTime)+" miliseconds");
}
}在这个例子中,我们违反了基本原则,因为我们创建了两个Date对象,调用了System.out.println(),还做了很多次String连接操作,但唯一需要做同步的操作是“dictionary.put(key, value);”。让我们来修改代码,把同步方法变成只包含这句的同步块,得到下面更优化的代码:
public class HelloSync {
private Map dictionary = new HashMap();
public void borringDeveloper(String key, String value) {
long startTime = (new java.util.Date()).getTime();
value = value + "_"+startTime;
synchronized (dictionary) {
dictionary.put(key, value);
}
System.out.println("I did this in "+
((new java.util.Date()).getTime() - startTime)+" miliseconds");
}
}上面的代码可以进一步优化,但这里只想传达出这种想法。如果你对如何进一步优化感兴趣,请参考java.util.concurrent.ConcurrentHashMap.
那么,我们怎么降低锁粒度呢?简单来说,就是通过尽可能少的请求锁。基本的想法是,分别用不同的锁来保护同一个类中多个独立的状态变量,而不是对整个类域只使用一个锁。我们来看下面这个我在很多应用中见到过的简单例子:
public class Grocery {
private final ArrayList fruits = new ArrayList();
private final ArrayList vegetables = new ArrayList();
public synchronized void addFruit(int index, String fruit) {
fruits.add(index, fruit);
}
public synchronized void removeFruit(int index) {
fruits.remove(index);
}
public synchronized void addVegetable(int index, String vegetable) {
vegetables.add(index, vegetable);
}
public synchronized void removeVegetable(int index) {
vegetables.remove(index);
}
}杂货店主可以对他的杂货铺中的蔬菜和水果进行添加/删除操作。上面对杂货铺的实现,通过基本的Grocery 锁来保护fruits和vegetables,因为同步是在方法域完成的。事实上,我们可以不使用这个大范围的锁,而是针对每个资源(fruits和vegetables)分别使用一个锁。来看一下改进后的代码:
public class Grocery {
private final ArrayList fruits = new ArrayList();
private final ArrayList vegetables = new ArrayList();
public void addFruit(int index, String fruit) {
synchronized(fruits) fruits.add(index, fruit);
}
public void removeFruit(int index) {
synchronized(fruits) {fruits.remove(index);}
}
public void addVegetable(int index, String vegetable) {
synchronized(vegetables) vegetables.add(index, vegetable);
}
public void removeVegetable(int index) {
synchronized(vegetables) vegetables.remove(index);
}
}在使用了两个锁后(把锁分离),我们会发现比起之前用一个整体锁,锁阻塞的情况更少了。当我们把这个技术用在有中度锁争抢的锁上时,优化提升会更明显。如果把该方法应用到轻微锁争抢的锁上,改进虽然比较小,但还是有效果的。但是如果把它用在有重度锁争抢的锁上时,你必须认识到结果并非总是更好。
请有选择性的使用这个技术。如果你怀疑一个锁是重度争抢锁请按下面的方法来确认是否使用上面的技术:
- 确认你的产品会有多少争抢度,将这个争抢度乘以三倍或五倍(甚至10倍,如果你想准备的万无一失)
- 基于这个争抢度做适当的测试
- 比较两种方案的测试结果,然后挑选出最合适的
用于改进同步性能的技术还有很多,但对所有的技术来说最基本的原则只有一个:不要长时间持有不必要的锁。
这条基本原则可以如我之前向你们解释的那样理解成“尽可能少的请求锁”,也可以有其他解释(实现方法),我将在之后的文章中进一步介绍。
两个最重要的建议:
请了解一下 java.util.concurrent包里的类(及其子包),因为其中有很多聪明而且有用的实现
并发代码大多数都可以通过使用好的设计模式来简化。请将 Enterprise Integration Patterns熟记于心,它们可以让你不必熬夜。
转载自:http://ifeve.com/concurrency-optimization-reduce-lock/
http://blog.chinaunix.net/uid-20758579-id-1876916.html
参考:http://www-01.ibm.com/support/knowledgecenter/ssw_aix_71/com.ibm.aix.performance/lock_granularity.htm?lang=zh
根据排队理论,一个资源闲置得越少,要得到它的平均等待时间就越长。这种关系是非线性的;如果锁的个数翻倍,平均等待这个锁的时间就比原来的两倍还要多。
减少对锁的等待时间的最有效方法是减少这个锁所保护的范围大小。下面是一些准则:
- 减少对任何锁的请求频率。
- 只锁定访问共享数据的代码,而不是一个组件的所有代码(这将减少锁的持有时间)。
- 只锁定特定的数据项或结构,而不是整个例程。
- 始终将锁和特定的数据项或结构关联起来,而不是和例程关联。
- 对于大的数据结构,为结构的每一元素选择一个锁,而不是为整个结构选择一个锁。
- 当持有一个锁时,从不执行同步 I/O 或者任何其他阻塞活动。
- 如果您对您组件中的同一数据有多个访问,请试着将它们移到一起,以便它们可以包含在一个锁定 - 解锁操作中。
- 避免双唤醒的情况。如果您在一个锁下修改了一些数据,并且不得不通知某人您做了这件事,那么在公布唤醒之前请释放该锁。
- 如果必须同时持有两个锁,那么最后请求那个最忙的锁。
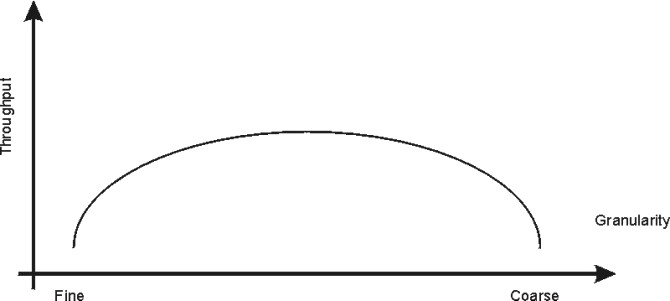
另一方面,过细粒度将增加对锁的请求和释放的频率,因而会增加额外的指令。您必须在过细和过粗粒度之间找到平衡。最佳粒度不得不通过试验和错误找到,这也是一个 MP 系统中的最大挑战之一。下图显示了锁的吞吐量和粒度之间的关系。
图 2. 吞吐量与粒度之间的关系. 这个图是一个简单的双坐标轴图表。垂直轴或 y 轴表示吞吐量。水平轴或 x 轴表示粒度,沿着坐标标尺向外移动时粒度从精细到粗糙而变化。一条延长的贝尔曲线表明了粒度对吞吐量的关系。随着粒度从精细到粗糙,吞吐量逐渐增加到一个最大水平,然后开始慢慢下降。这表明为了达到最大吞吐量,必须在粒度上折衷。
java相关锁粒度注意点:
1.读写分开(CopyOnWrite)
2.将锁打散(ConcurrentHashMap分解Segment)
3.通过synchronized或Lock来锁定一段代码区域时,除了考虑它们锁定的对象是什么以外,还需要考虑是否可以将范围缩小一些。
4.定义多个对象,然后让不同的方法锁住不同的对象。
5.拆分子方法,对某个必要的子方法加锁;通过锁块来隔离部分代码段。
6.JVM对锁的优化有一个粗粒度的动作,我们自己写代码时尽量不依赖于JVM这种优化机制。
7.用乐观替代悲观,如同步之前先做某些条件判断。
8….















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









