






一、背景
图像压缩解决的是减少描述数字图像处理所需要数据量的问题。压缩是通过去除一个或三个基本的数据冗余来实现的:(1)编码冗余,当所用的码字少于最佳编码长度(即最小长度)时出现编码冗余;(2)空间或时间冗余,即图像像素间或图像序列中相邻图像的像素间的相关造成的冗余;(3)不相关信息,即视觉上不重要的信息。
图像压缩系统是由两个截然不同的结构框架组成的:一个编码器和一个解码器。
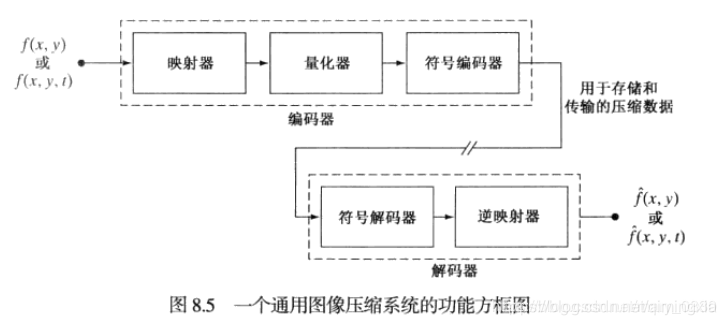
图像f(x,y)被送入编码器,编辑器由输入数据创建一组符号,并用这组符号来描述图像。若令n1和n2分别表示原始图像和已编码图像中信息携带单元的数量,则可实现的压缩可以通过压缩比来量化;
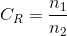
在MATLAB中,用于表示两幅图像文件或变量的比特数的比率,可以定义M函数计算;
function cr = imratio(f1, f2)
%IMRATIO Computes the ratio of the bytes in two images/variables.
% CR = IMRATIO(F1, F2) returns the ratio of the number of bytes in
% variables/files F1 and F2. If F1 and F2 are an original and
% compressed image, respectively, CR is the compression ratio.
% Copyright 2002-2004 R. C. Gonzalez, R. E. Woods, & S. L. Eddins
% Digital Image Processing Using MATLAB, Prentice-Hall, 2004
% $Revision: 1.4 $ $Date: 2003/11/21 13:11:15 $
error(nargchk(2, 2, nargin)); % Check input arguments
cr = bytes(f1) / bytes(f2); % Compute the ratio
%-------------------------------------------------------------------%
function b = bytes(f)
% Return the number of bytes in input f. If f is a string, assume
% that it is an image filename; if not, it is an image variable.
if ischar(f)
info = dir(f); b = info.bytes;
elseif isstruct(f)
% MATLAB's whos function reports an extra 124 bytes of memory
% per structure field because of the way MATLAB stores
% structures in memory. Don't count this extra memory; instead,
% add up the memory associated with each field.
b = 0;
fields = fieldnames(f);
for k = 1:length(fields)
b = b + bytes(f.(fields{k}));
end
else
info = whos('f'); b = info.bytes;
end
在函数iimratio中,内部函数b=bytes(f)设计用于返回一个文件,或者一个结构,或者一个非结构变量中的字节数。
图中的编码器负责减少输入图像的代码,像素间及心理视觉冗余。在编码处理的第一阶段,映射器将输入图像变换成一种(通常不可见的)格式,以减少像素间冗余。第二阶段,量化器根据预定义的保真度准则,降低映射器输出的精度。这一操作时不可逆的。在处理的第三阶段,符号编码器根据所用的码字对量化器输出和映射输出创建码字。
图中解码器仅包含两部分:一个符号解码器和一个反映射器,执行编码器的逆操作。由于量化是不可逆的,因此未包含反量化方框。
二、编码冗余
令具有概率Pr(rk)的离散随机变量rk,k=1,2,……,L表示一个L级灰度图像的灰度级。r1对应于灰度级0,(因为MATLAB数组索引不能为零)且
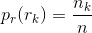
k=1,2,…L
式中,
nk 是第k个灰度级在图像中出现的次数,n是图像 中的像素总数。
如果用于表示每个rk 值的比特数为l(r ), 则表达每个像素所需的平均比特数为:
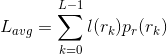
也就是说,赋给各个灰度级的码字的平均长度,是通过对用于表示每个灰度级的比特数和该灰度级出现的概率的乘积求和来得到的。这样,编码一幅M*N图像所需要的总比特数就是MNLavg。
信息量:概率为P的一个随机事件E包含
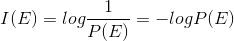
如果P=1,即该事件肯定会发生,则 I=0,对于它没有信息。在离散的可能事件集中,每个信源输出的平均信息称为熵,即
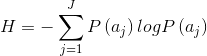
如果一幅图像被视为一个发出它的“灰度级信息源”的样本,那么使用被观测图像的灰度直方图来对信源的符号概率建模,并生成信源的熵。定义一个M函数实现上述功能;
function h = ntrop(x,n)
error(nargchk(1,2,nargin));
if nargin < 2
n = 256;
end
x = double(x);
xh = hist(x(:),n);
xh = xh /sum(xh(:));
i = find(xh);
h = -sum(xh(i)).*log2(xh(i));
考虑一幅简单的4*4的图像,其直方图模拟某一符号概率:
f=[119 123 168 119;123 119 168 168];
>> f=[f;119 119 107 119;107 107 119 119]
f =
119 123 168 119
123 119 168 168
119 119 107 119
107 107 119 119
>> p=hist(f(:),8);
>> p=p/sum(p)
p =
0.1875 0.5000 0.1250 0 0 0 0 0.1875
>> h=ntrop(f)
h =
1.7806
最后得到的结果就是计算的信息熵。其中符号分布直方图

霍夫曼码
当对一幅图像的灰度级或一个灰度级映射操作编码时,在满足一次编码一个信源符号的条件下,霍夫曼码包含了对每个信源符号的最小可能的编码符号数。
霍夫曼方法的第一步是,通过按符号的概率排序建立一个信源递减序列,然后将最低概率符号组合为一个符号,以便在下次信源约简中代替他们。


如图,在最左侧,初始信源符号集合他们的概率按照概率值降序由高到低排序。为形成第一次信源约简,底部两个概率值被合并,形成合并符号,而后再合并,重复过程,直到只有两个符号的简约信源,位于最右侧。
霍夫曼过程的第二步,给每个约简信源编码,编码从最小的信源开始到原始信源。当然,对于两符号信源的最短二进制编码由 0 和 1 组成。这些符号被分配给右边的两个符号(分配是任意的,颠倒 0 和 1 的顺序也是可以的)。概率为 0.5的约简 信源符号通过合并两个约简信源左侧的符号生成,用来编码的 0现在被分配给这些符号,并且 0 和 1 被任意分给每个符号以便区分它们。然后, 这个操作对每个约简信源重复,直到到达原始信源。
霍夫曼码是瞬时的、唯一可译码的块编码。之所以是块编码,是因为每个信源符号均映射到固定的码字符号序列。之所以是瞬时的,是因为码字符号字符串 的每个码字可以不参照随后的符号而被译码。也就是说,在任意给定的霍夫曼码中,没有码字是其他码字的前缀。之所以是唯一可译码的,是因为代码符号字符串仅有唯一的译码方法。 这样,任意霍夫曼码符号字符串都可以通过从左到右的方式考察单独字符串而被译码。
上述过程,定义M函数 huffman 实现;
function CODE=huffman(p)
error(nargchk(1,1,nargin));
if (ndims(p)~=2)||(min(size(p))>1)||~isreal(p)||~isnumeric(p)
error('P must be a real numeric vector');
end
global CODE
CODE=cell(length(p),1);
if length(p)>1
p=p/sum(p);
s=reduce(p);
makecode(s,[]);
else
CODE={'1'};
end;
function s=reduce(p)
s=cell(length(p),1);
for i=1:length(p)
s{i}=i;
end
while numel(s)>2
[p,i]=sort(p);
p(2)=p(1)+p(2);
p(1)=[];
s=s(i);
s{2}={s{1},s{2}};
s(1)=[];
end
function makecode(sc,codeword)
global CODE
if isa(sc,'cell')
makecode(sc{1},[codeword 0]);
makecode(sc{2},[codeword 1]);
else
CODE{sc}=char('0'+codeword);
end
举例说明实现哈夫曼方法
p=[0.1875 0.5 0.125 0.1875]
p =
0.1875 0.5000 0.1250 0.1875
>> c=huffman(p)
c =
4×1 cell 数组
{'011'}
{'1' }
{'010'}
{'00' }
输出是一个变长字符数组,其中的每一行是由0和1组成的字符串,即为相应符号的编码。
霍夫曼编码
霍夫曼码的生成并不压缩。为了实现构建霍夫曼码的压缩,创建码字的符号,不管是灰度级,行程长度或其它灰度映射操作,都必须根据生成的码字来变换或映射(即编码)。
霍夫曼编码过程:
1,将每个事件的概率从大到小依次排序
2,把最后两个出现概率最小的消息合并成一个消息,从而使信源的消息数减少一个,并同时再次将信源中的消息概率从大到小排列一次。
3,重复上述步骤,直到信息源最后为两个信息源 为止。
4,对最后的信息源赋予1和0或0和1,并逐步向前编码。

MATLAB中的变长编码映射,考虑简单的16字节图像;
f2=uint8([2 3 4 2;3 2 4 4;2 2 1 2;1 1 1 2])
f2 =
4×4 uint8 矩阵
2 3 4 2
3 2 4 4
2 2 1 2
1 1 1 2
>> whos('f2')
Name Size Bytes Class Attributes
f2 4x4 16 uint8
f2中每个像素都是一个8比特字节;16字节用来表示整个图像。因为f2的灰度级不是等概率的,所以一个变长码会减少用于表示该图像的存储数量。函数huffman计算这样一个码字:
c=huffman(hist(double(f2(:)),4))
c =
4×1 cell 数组
{'00' }
{'1' }
{'010'}
{'011'}
因为霍夫曼码与被编码的信源符号出现的频率有关,所以此处的编码和上例相同。
基于码字c对f2编码的一种简单方法是,执行一个简单的查表操作:
h1f2=c(f2(:))'
h1f2 =
1×16 cell 数组
1 至 9 列
{'1'} {'010'} {'1'} {'00'} {'010'} {'1'} {'1'} {'00'} {'011'}
10 至 16 列
{'011'} {'00'} {'00'} {'1'} {'011'} {'1'} {'1'}
这里,f2(一个uint8类二维数组)被变换为一个单元数组h1f2。h1f2的元素是变长字符串,并对应于f2中从上到下,从左到右的扫描。编码后的图像使用了1018个字节的存储空间,是f2所需要的60多倍。
通过把h1f2变换为一个传统的二维字符数组可以消除跟踪这些变长元素所要求的存储开销;
h2f2=char(h1f2)'
h2f2 =
3×16 char 数组
'1010011000001011'
' 1 01 01100 1 '
' 0 0 11 1 '
>> whos('h2f2')
Name Size Bytes Class Attributes
h2f2 3x16 96 char
其中,单元数组h1f2被变换成一个3*16的字符数组h2f2。h2f2的每一列按从上到下,从左到右的扫描方式对应于f2中的一个像素。为了使数组大小合适,其中插入了空白,因为对于每一个码字的每个0,1,都要求有两个字节,所以h2f2使用的存储总量是96字节,仍比f2所需要的原始16字节大6倍。下面消除空白
h2f2=h2f2(:);
>> h2f2(h2f2==' ')=[];
>> whos('h2f2')
Name Size Bytes Class Attributes
h2f2 30x1 60 char
但是仍然比f2的原始16字节大。
要压缩f2,码字c必须按比特级应用,将几个编码后的像素打包为单个字节:
h3f2=mat2huff(f2)
h3f2 =
包含以下字段的 struct:
size: [4 4]
min: 32769
hist: [4 7 2 3]
code: [43185 45244]
whos('h3f2')
Name Size Bytes Class Attributes
h3f2 1x1 726 struct
虽然函数mat2huff返回一个要求有726字节存储的结构h3f2,但它大部分与结构变化开销,产生用来解码的信息相关,考虑实际的图像时,它是可以忽略的。
霍夫曼解码
霍夫曼编码的图像几乎没什么用,除非能被解码并重新构建为原始图像。
前面一节的输出 y = mat2huff (x) ,解码器必须首先计算用来编码 x 的霍夫曼码(基于 x 的直方图 和 y 中有关的信息),然后反映射已编码的数据(还是从 y 中提取)来重建 x。
正如在下面列出的函数 x=huff2mat (y) 中看到的那样,上述处理可以分为 5 个基本步骤:
(1) 从输入结构 y 中提取维数 m 和 n,以及最小值 xmin(最后的输出 x)。
(2) 重新创建霍夫曼码,通过将它的直方图传递到 huffman 函数来对 x 进行编码。在列 表中产生的编码将被map 调用。
(3) 建立数据结构(转换和输出表 link), 以便在 y.code 中通过一系列有效的二进制搜索 对编码数据解码。
(4) 传递数据结构和已编码数据(比如 link 和 y.code)到 C 函数 unravel。这个函数最 小化为执行二进制搜索要求的时间,产生已解码的 double 类的输出向量 X。
(5) 把xmin添加到x的每个元素中,并加以改造以匹配原始x的维数(也就是m行和n列)。
huff2mat 的唯一特点是对 MATLAB 可调用C 函数 unravel 的结合(见步骤(4)),这使得对大多数标准分辨率的图像的解码几乎都是瞬时的。
三、空间冗余
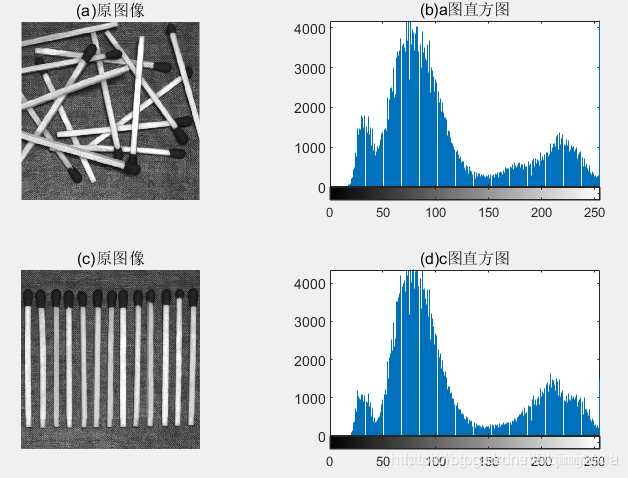
两个图像有着相同的直方图,直方图有三个形态,这表明存在灰度级值得三个主要范围。因为图像得灰度级不是等概率的,所以可用变长编码来减少由像素的自然二进制编码导致的编码冗余。
注意,这两幅图像的一阶熵估计大致相同(分别为7.4253和 7.3505 比特/像素);它们同样由 mat2huff 压缩(压缩比为 1.0704 和 1.0821)。这些明显强调了如下事实:变长编码的设计不是为了利用图中排成一排的火柴之间的明显结构关系的优点。虽然在图像中,像素与像素之间的相关性更明显,但这一现象在图中也存在。因为任何一幅图中的像素都可以合理地从 它们的相邻像素值预测,这些单独像素携带的信息相对较少。单一像素的视觉贡献对一幅图像 来说大部分是多余的;它们应该能够在相邻像素值的基础上推测出来。这些相关性是像素间冗余的潜在基础。
为了减少像素间的冗余,通常必须把由人观察和解释的二维像素数组变换为更有效的格式 (但通常是“不可视的”) 。例如,邻近像素点之间的差值可以用来表示一幅图像。这种类型(也就是说,移走像素间的冗余)的变换被称为映射。如果原始图像可以从变换的数据集重建,它们就被称为可逆映射。 图 8-7 展示了简单的映射过程。这种被称为无损预测编码的处理方法可以通过对每个像素中新的信息进行提取和编码来消除相近像素间的冗余。像素的新信息被定义为实际值和预测值 的差值。由此可见,系统由编码器和解码器组成,每个都含有相同的预测器。当每个输入图像 中相继的像素表示为fn时,fn被送进编码器,预测器以过去某些输入为基础产生像素的预测值。 预测器的输出被四舍五入成最接近的整数。表示为f^n; 并用来产生差或预测误差:
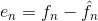
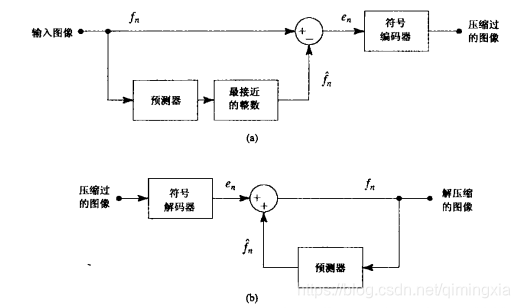
预测误差用变长编码(通过符号编码器)产生压缩数据流的下一个元素。解码器用收到的变长码字执行相反的操作以重建en:
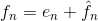
各种本地的、全局的和自适应方法可以用来产生f^n。然而对于大部分情况,预测由前面的 几个像素的线性结合而形成,也就是:
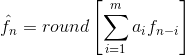
这里, m是线性预测器的阶, “ round”是用来表示四舍五入或接近整数的函数(就像 MATLAB 中的 round 函数)。并且对于 i=l, 2⋯,m 是预测参数。对于一维线性预测编码,这个等式可以写作:
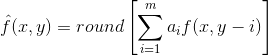
这里,每个带下标的变量已明确作为空间坐标(xy)的函数来表示。注意预测f^(x,y)是当前的扫描行上前一些像素的函数。
M函数mat21pc和 lpc2ma执行刚才讨论的预测编码和解码处理(负符号编码和解码的步骤)。
编码函数mat2lpc采用一个for循环来同时建立输入x中每个像素的预测。在每一步迭代中,开始作为x的副本xs向右移动一列,乘以一个适当的预测系数,并加到预测和p中。
解码函数lpc2mat执行与编码函数mat2plc相反的操作。
function y=mat2lpc(x,f)
error(nargchk(1,2,nargin));
if nargin<2
f=1;
end
x=double(x);
[m,n]=size(x);
p=zeros(m,n);
xs=x;
zc=zeros(m,1);
for j=1:length(f)
xs=[zc xs(:,1:end-1)];
p=p+f(j)*xs;
end
y=x-round(p);
function x=lpc2mat(y,f)
error(nargchk(1,2,nargin));
if nargin<2
f=1;
end
f=f(end:-1:1);
[m,n]=size(y);
order=length(f);
f=repmat(f,m,1);
x=zeros(m,n+order);
for j=1:n
jj=j+order;
x(:,jj)=y(:,j)+round(sum(f(:,order:-1:1).*x(:,(jj-1):-1:(jj-order)),2));
end
x=x(:,order+1:end);
预测误差的熵 e 显著地比原始图像 f 的墒要小。尽管 m比特图像需要(m+1)个比特 以准确表示造成的误差序列,但是熵已从 7.3505比特/像素减少到 5.9727比特/像素。熵的减少意味着预测误差图像可以比原始图像更有效地进行编码,当然这是映射的目标。压缩率从 1,0821(当直接对灰度级进行霍夫曼编码时)增大到 1.3311。0周围的峰值很高,与输入图像的灰度级务布相比有相对较小的方差。 这反映出正如前面计算的熵值那样,由预测和微分处理移去了大量的像素间冗余。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









