






【1701H1】【穆晨】【180128】第110天总结
网页的user agent反馈访问网页的是代码还是浏览器,如果是代码,有些网页便不给访问了
第一种修改headers方法
在request生成之前,添加head
request有个参数是head可以伪装自己访问为正常访问
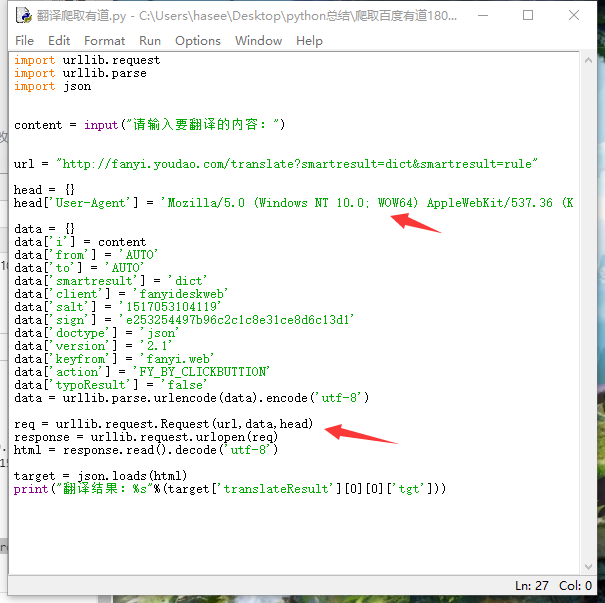
第二种方法在生成request后,add_header(key,val)
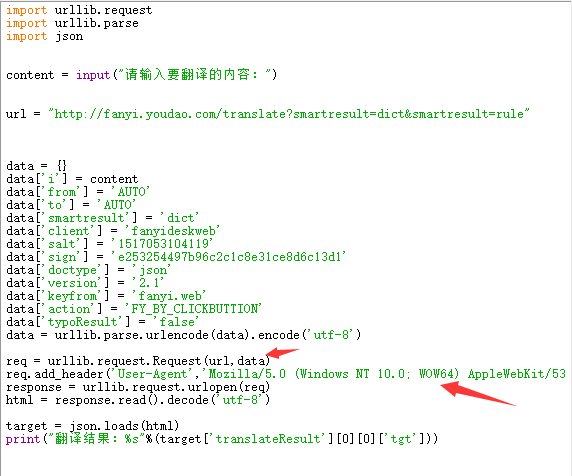
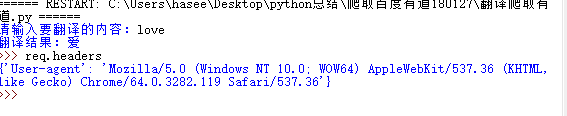
用python爬取网页,假设爬取网页上的美图,正常人是几秒看一张图,但代码会是1秒钟好多张图,
这会添加服务器的负担,那么可能终端不管你的uers-agent是否正常,可能都会封了你的ip
解决方法:
1.设置访问时间间隔

5秒钟访问一次

第二种方法:
有人会觉的这样好慢,有没有方便快捷的方法,有,代理
用别人的ip来工作
步骤
1.参数是一个字典{‘类型’:‘代理ip:端口号’}
proxy_support = urllib.request.ProxyHandler({})
2.定制、创建一个opener
opener = urllib.request.build_opener(proxy_support)
3.a.安装opener
urllib.request.install_opener(opener) (以后就不用再安装 了)
3.b.调用opener
opener.open(url) (不想覆盖已经安装的opener,只是此次需要)

加上user-agent

为了爬取不被阻拦,多放几个ip

(晚上找的免费ip,几乎都不能用)
代理,让网站识别不出来这是代码访问















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









