







现在网上很多教程都在讲MongoDB分片配置,但大多都没有经过实战,胡乱转载。而且用的MongoDB版本不同各种配置眼花寮乱,让入门者莫衷一是。
最近我也做了MongoDB分片,贴出自己的配置。并且把需要注意的问题和大伙聊聊,不恰当的地方希望大家指正。 也同时希望让后来者能绕过这些问题。
正式环境为了保证数据安全都要进行备份的,关于分片复制请见alibaba教程:http://www.taobaodba.com/html/525_525.html
我配置的集群是测试用的,没有复制。只是简单的分片存储数据进行测试。在测试的时候又分片,又复制,那么多机器也麻烦。这一点网上的很多例子都是错误的,为此我也花了很多时间。
我配置完成后的结构图为:
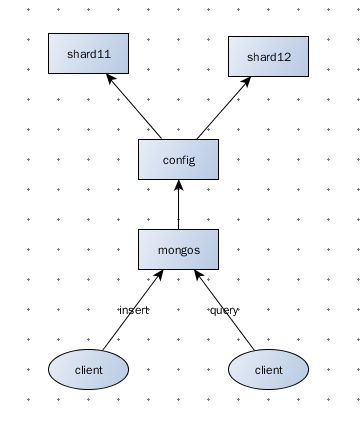
我的Mongo版本为:mongodb-linux-x86_64-2.0.8,计算机为普通Pc。
在这里我要特别说明:
| 1.大数据情况下最好是64位机器,32位机器不能创建大于2GB的单个文件。 小数据量无所谓 2.集群中的每台计算机的系统最好都是一样的,不要32位,64位搭配 -- 我在开始做测试就是这样,2台64,2台32.当注入300W左右的数据,索引大于3-4G时32位机器出错了,32位系统上不能创建大于2GB的单个文件。整个集群瘫痪,我为此找了很长时间的原因 |
让我们开始吧!
mongo从下载后解压后的目录结构如下:我们视安装目录为:${MONGO_INSTALL}

先在第一台计算机上在${MONGO_INSTALL}下分别执行:
1 | mkdir -p /data/shard11 |
1 | bin/mongod -shardsvr -port 27017 -dbpath=/data/shard11/ -logpath=/data/shard11.log --fork |
1 | mkdir -p /data/shard12 |
1 | bin/mongod -shardsvr -port 27017 -dbpath=/data/shard12/ -logpath=/data/shard12.log --fork |
在Ubuntu系统下你需要root权限:
1 | sudo mkdir /data/shard11 |
2 | sudo chmod -R 777 /data/shard11 |
1 | ps -ef |grep mongod |
OK,现在我们成功的分别在2太计算机上启动了1个mongod实例,mongod是真正存储数据的进程。进群中还需要一个配置服务器,用来存储在各个节点中共享的配置信息,存储数据的元信息[METADATA],也如上面我结构图中config.
config不会占用太多资源的。我们在其中任何一台上面启动Mono的Config,shell如:
1 | #config也是存储少量数据的,不要忘了给它创建存储数据的文件夹 |
2 | mkdir /data/config |
1 | bin/mongod -configsvr -dbpath=/data/config -port 20000 -logpath=/data/config.log --fork |
也许你已经注意到,在2台shard的启动参数中加了-shardsvr,在配置实例中加了-configsvr。 mongo就是这样进行区分的。当然复制的配置应该是: -replSet setName。 setName就是复制集群的别名。
当以上都启动成功,我们可以开启mongos服务了。在任何一台机器上执行:
1 | #mongos进程不需要dbpath,但是需要logpath |
2 | #mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB |
3 | bin/mongos -configdb ip:20000 -port 30000 -chunkSize 512 -logpath=/data/mongos.log --fork |
请注意上面的IP,这个IP应该是你启动config的那台机器ip和port。,执行命令时使用具体的ip。
如果顺利的话,你也应该能轻松的启动mongos进程的。可以执行查看:ps -ef |grep mongos现在就剩下配置了。让mongos进程知道哪些机器是需要加入到分片的。在任何一台机器上执行[mongosip为启动mongos服务的机器IP]:
1 | bin/mongo ip:30000/admin |
1 | db.runCommand({"addshard":"192.168.1.23:27017"}) |
2 | db.runCommand({"addshard":"192.168.1.22:27017"}) |
如果顺利,你应该能看到{ ”ok“ : 1}的字样。这样你就成功的把两个shard加入了分片。现在你还需要制定分片的规则。
1 | db.runCommand({"shardcollection":"dbname.tablename", "key":{"primaryKey":1}}) |
1 | db.runCommand({"enablesharding": "ndmongo"}) |
现在你需要在刚才指定dbname和tablename插入一定数量的数据。测试集群:
1 | db.printShardingStatus() |
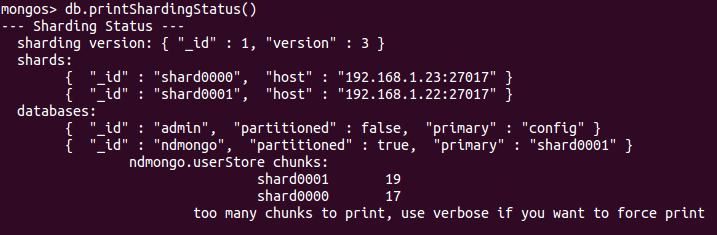
现在你应该能体验自己的分片了。
如果你的机器是64位的,你用我的配置应该很容易的就成功了。如果你用的32位的,你应该还要注意在启动shard的时候加上:
--journal因为64位默认启动开启journal的,32位没有。至于journal什么作用我也不太清楚,读者自己google吧。
因为我开始测试时用的机器32,64都有,出现了这么多烦人的问题。 希望其他跟我一样的人不要重蹈复辙















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









