







By云深作者:Adam/Schubert/SeymourZ 2008年8月
转载请注明出处
1 Introduction
随着互联网技术的发展,尤其是云计算平台的出现,分布式应用程序需要处理大量的数据(PB级)。在一个或多个云计算平台中(成千上万的计算主机),如何保证数据的有效存储和组织,为应用提供高效和可靠的访问接口,并且保持良好的伸缩性和可扩展性,成为云计算平台需要解决的关键问题之一。分布式并行文件系统,为云计算平台解决了海量数据存储问题,并且提供了统一的文件系统命令空间,如GFS、Hadoop HDFS、KFS等,在此基础上, Hypertable实现了分布式结构化的数据组织,Hypertable可以对海量的结构化的数据(PB级)提供面向表形式的组织方式,并向应用提供类似表访问的接口(如SQL接口)。
2 Structured Data and Tablet Location
2.1 数据模型(Data Model)
Hypertable采用类似表的形式组织数据,但目前Hypertable并不支持关系数据库中丰富的关系属性。Hypertable将数据组织成一个多维稀疏矩阵。该矩阵中的所有行信息可以基于主键(Primary Key)进行排序。在该多维矩阵中第一维称为行(Row),行键值(Row Key)即为Primary Key;第二维即列族(Column Family),一个列族包含多个列(Column Qualifier)的集合,它们一般具有相同的类型属性,系统在存储和访问表时,都是以Column Family为单元组织;第三维即列(Column Qualifier),理论上,一个列族中列的个数不受限制,列的命名方式通常采用family:qualifier的方式;最后一维就是时间戳(Timetstamp),它通常是系统在插入一项数据时自动赋予。如果我们把行和列族看成三维矩阵的行和列,那么我们可以将“时间戳”看成是纵向深度坐标。如图2-1所示,Tn就是每项值(Value)的“深度”标签。
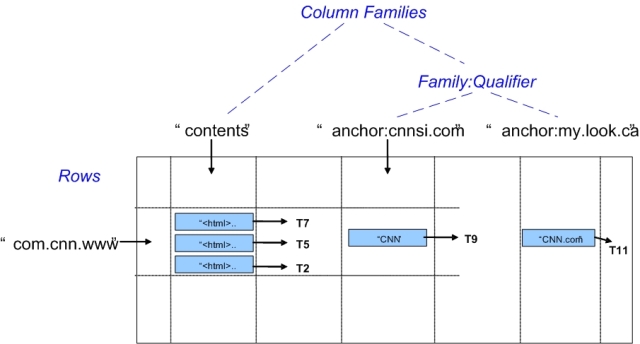
Figure 2-1 A Multi-Dimensional Table
2.1.1 行键(Row Key)
Hypertable中Row Key定义为任意的字符序列(长度不超过64Kbyte,通常的应用也就百个字节左右),所有行以Row key为主键进行字典排序。在Hypertable中队行的操作保持原子性,对行的插入(Insert)、更新(Update)、删除(Delete)等都保持整行的原子操作,无论行操作涉及到的列的个数。在Hypertable中保持行操作的原子性,对应用程序来说显然具有积极的意义,它使得Hypertable对应用程序来说,行的一致性得到保证。
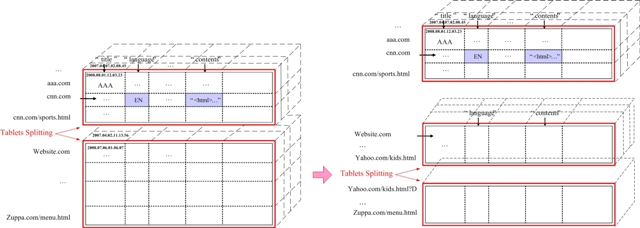
在Hypertable中,所有的行数据按照Row Key的字典序排列,如图2-1,随着数据量的不断增长(不断的有新的数据插入),该多维数据表会不断增长,在一个并行的云计算平台中,当该表增长到一定大小时,系统会将该表一分为二,分别由平台中不同的主机维护,分裂后的表可以独立增长,再进行分裂,由此反复,最终一个多维的Hypertable表实际上是以大量的“小表(Tablet)”的形式存在于云计算平台中,它们具有完全对等的属性,分别维护表中的部分数据;一个小表(Tablet)由一台主机维护,一台主机可以维护多个小表。在Hypertable中,表的分裂沿行区间(Row Range)切分,如图2-2所示,一张表在生长过程中,在一定的行区间被分裂为多个行区间(Row Range),每一个行区间成文一个新的小表(Tablet)。在Hypertable中缺省是一个Tablet增长到200M左右分裂,同时由于系统在并行处理平台上运行,会根据负载均衡原则进行调解。在云计算平台中,分裂出来的Tablet基于Load Balance原则被分布在不同的主机上维护,从而,对表的操作演化成对各小表(Tablet)的操作,处理效率显然高于对整个大表的操作。用户在使用Hypertable时合理的选择Row Key,可以得到更好的数据处理效率。例如在处理大量网页数据时(网页crawler获取的网页数据),通常把网页URL作为Row Key,其中URL的主机域名被反序处理(如maps.google.com/index.html被反置为com.google.maps/index.html),如此具有相同域的网页被尽可能的组织在相同或相邻的Tablet中,因此应用程序在处理这些数据时能得到更好的效率。
2.1.2 列族与列(Column Family & Column Qualifier)
Hypertable表的列键(Column Key)被分组为不同的列族(Column Family),列族(Column Family)是Hypertable系统中数据存储和访问控制的基本单元。在一个Column Family中的所有列通常具有相同的类型。在表的生长过程中,新的Column可以被动态创建,在创建Column前,相应的Column Family必须存在。Hypertable系统中,一个表的Column Family个数不大于256,而且一旦Column Family被创建,很少会被修改。
在Hypertable中,Column的个数基本上没有限制。一个Column Key的命名采用 Column Family:Qualifier形式,其中Column Family是可显示字符串,代表该Column所属的Column Family,而Qualifier可以是任意的字符串。如图2-1所示,该表至少包括两个Column Family,其中一个Column Family只有一个Qualifier:“contents”,用于存储网页的内容;另一个Column Family是“anchor”,用于表示该网页被其它网页引用的情况。对于表中的每一行,该Column Family包含有不定数目的列,也即qualifier的个数不定,因此该表在逻辑上会形成一个稀疏矩阵。图中,www.cnn.com 主页被www.cnnsi.com 和 www.my.look.ca 分别用“CNN”和“CNN.com”命名的链接引用。
在Hypertable中,数据的存储以Access Group为单位组织,一个Access Group可以包括一个或多个Column Family。因此数据存储组织的最小单位是Column Family. 在定义Hypertable表的机构时可以定义Access Group包含的Column Family。
2.1.3 时间戳(Timestamp)
如图2-1,在Hypertable的表中,任意的格子(cell)都可以保存不同版本数据,用时间戳进行(timestamp)排序,从而形成表的时间维度。在Hypertable系统中,时间戳是由64-bit整数表示,他们值可以有系统自动赋予,也可以在由客户端应用程序指定。Timestamp在表中以降序排列,最新版本的数据会被最先读取。客户端在操作数据时,必须保证数据在时间序的逻辑性。如,当前数据的Timestamp为T0,新的操作时间戳被指定(客户端或系统指定)T1,则必须保证T1>T0,操作才能被系统接受。
Hypertable在维护数据版本时,不能无限制的维护版本个数,系统提供了两种手段维护有限个数的数据版本(Timestamp),一种是系统设置最多能维护的版本个数,当数据版本超出最大版本数时,系统的数据维护模块会清理版本相对较老的数据;另一种手段是系统动态设置最老版本的时间点,当该参数被更改后,系统数据维护模块会将旧改时间点的数据版本删除。
2.1.4 表的扁平化(Flattening)
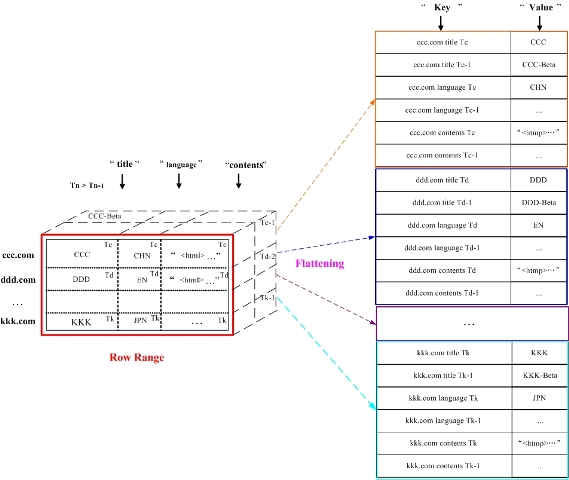
在Hypertable中,四维(Row Key、Column Family、Column Qualifier、Timestamp)表最终被扁平化处理成(Key、Value)对的形式存储,其中Key的表示形式为Row Key,Column Family(处理时使用系统编号),Column Qualifier和Timestamp组成的字符串。Value为相应的值。如图2-3所示一个row range的扁平化方式。Row Key保持字典升序排列,Column保持schema定义的顺序,Timetamp保持降序排列。
2.2 表的寻址和存储
Hypertable主要解决的是数据的组织和存储策略问题,数据的物理存储由分布式并行文件系统完成。分布式并行文件系统作为云计算平台的基础组件,为Hypertable提供统一的文件系统命名空间(namespace)。
在Hypertable中,数据在存储前经过了排序和压缩,表中的数据类型都被串行化为字符数据。一张表,在它的生长过程中,会分裂为许多小表(tablet),新产生的tablet可以被指定到云计算平台中的任意物理主机维护。在Hypertable系统中维护着一个全局Tablet索引表Metadata Table,Metadata Table本身是一张Hypertable表,它负责保存和维护系统中所有小表(Tablet)的索引。
2.2.1 Tablet索引
在Hypertable中,采用三级层次建立tablet的索引。如前所述,表是按row range分裂为许多的tablet,所有在tablet的集合组成完整的Table。系统中为了维护每张表的tablet位置信息(tablet分布在云计算平台的主机中),会创建一个特殊的表:Metadata table。Metadata表具备一般用户表的属性,也有它的特殊性,根据不同索引级别,分为两类tablet:metadata0 tablet和metadata1 tablet,其中:
Metadata 0的位置信息称为一级索引,通常是一个位置指针存放在系统中,系统初始化时,读取该指针获得metadata0的位置信息;
Metadata 0 tablet作为二级索引,它是一个不会分裂的tablet,运行时,系统在内存中维护它,同时该tablet被定义为metadata表的第一个tablet,在初始化时被创建。Metadata 0中保存Metadata 1 tablets的位置信息;
第三级索引为metadata 1 tablets,这一级的metadata1 tablets具备和用户tablet相同的属性,系统初始化时,会创建第一个metdata1 tablet。Metadata tablet中保存用户表的tablets位置信息。
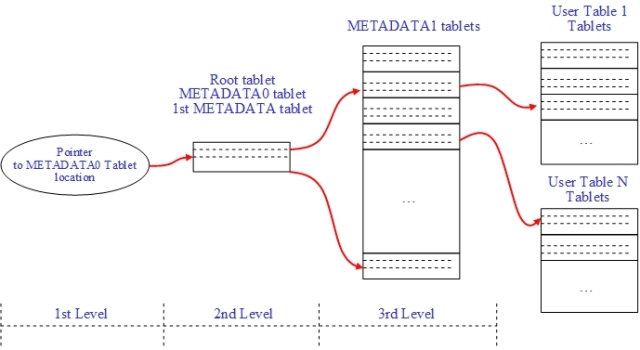
Figure 2-4 Tablet location hierarchy
Metadata schema的XML文件描述形式为:
<Schema>
<AccessGroup name="default">
<ColumnFamily>
<Name>LogDir</Name>
</ColumnFamily>
<ColumnFamily>
<Name>Files</Name>
</ColumnFamily>
</AccessGroup>
<AccessGroup name="location" inMemory="true">
<ColumnFamily>
<Name>StartRow</Name>
</ColumnFamily>
<ColumnFamily>
<Name>Location</Name>
</ColumnFamily>
</AccessGroup>
<AccessGroup name="logging">
<ColumnFamily>
<Name>Event</Name>
</ColumnFamily>
</AccessGroup>
</Schema>
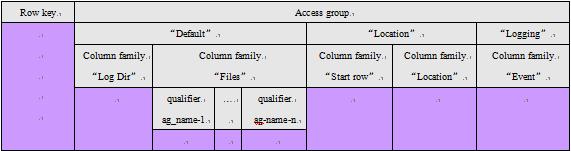
表2-1列出了Metadata的表结构。其中最底下彩色区域就是一行metadata的各项值区域。其中:
l Row key:是table_id:end_row_key表示,table id是表在创建时,系统赋予的唯一表标识号,0号码保留给metadata table用。end_row_key是一个任意字符串,表示该记录指向的tablet的最后一行的row key。
l Access group:metadata table包括三个access group,分别是:default、Location、Logging。
l Column Family:metadata table包含五个column families,分别是:LogDir、Files、Start row、Location、Event。其中Start row记录该行指向的tablet的第一行的row key;Location记录的是该tablet是由云计算平台中哪一台主机维护,以ip:port方式记录。
l “Files” Column Family:该column family下可能包含多个qualifier项,每一项qualifier指示该记录对应tablet(表号为table_id)的一个access group所保存的文件名列表,一个table的access group的个数在table schema中定义,文件名之间用分号隔开。
Table 1: Hypertable metadata table structure
在Hypertable中,metadata表的一条记录大小约为1K,如果定一个tablet的大小为128M,那么这样一个三级索引的架构,可以索引的最大Hypertable容量(压缩后)为:(128M/1K)* (128M/1K)*128M,约为2^61bytes。
2.2.2 Tablet存储
Hypertable为用户规划表数据存储提供了一定灵活度,从hypertable的扁平化过程可以看出,它采用面向列的存储模式。Hypertable采用access group方式组织数据存储(在表schema中定义),一个access group包含一个或多个column family。对于一个row range,属于一个access group的所有数据被组织在一起存储,access group是hypertable面向存储的最小访问单位。这样,对于有应用相关性的列,被组织存储在一起,可以有效地提高数据的读写效率。
一个Tablet包含一个表中特定row range的数据,它由系统中一台主机(range server)维护,系统中一台主机可以维护多个表的多个tablet。Tablet在存储前都被扁平化处理,以(key,value)对的形式存储在文件中,实际存储中,(key,value)对中加入了该数据的操作类型,如插入、更新、删除等。Tablet以文件形式存储。如图2-5所示,为一个典型的tablet存储目录结构。
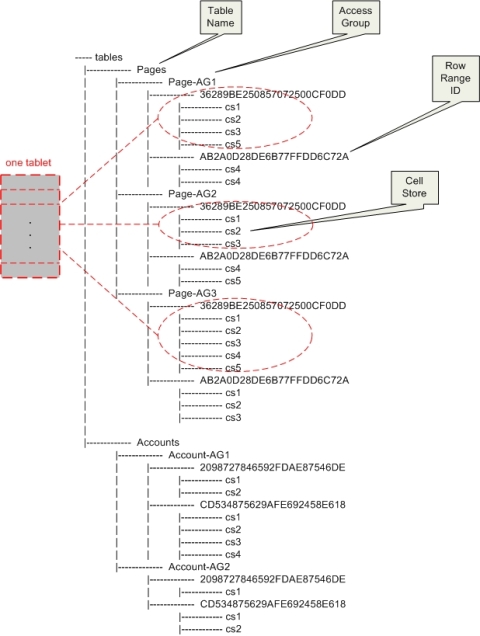
Figure 2-5 An example of table directory in range server
在主机在维护tablet时,会在文件系统的table目录下创建对应的表目录,目录用表名命名。如上图所示,该主机维护了Pages,Accounts两个表的tablet。在每个table目录下会根据表的schema创建相应的access group目录,如Pages有三个access group,Accounts有两个access group。在access group目录下,系统会为每一个tablet创建一个目录,由系统生成的随机数(row range 系统编号)字符串命名。当前状态下,该主机维护了Pages表的两个tablets。由此可见,一个完整的row range(tablet)数据是指该表目录下,所有access group目录中,在相同row range目录下的文件集合。
如图2-5所示,表是以cs(CellStore)文件形式存储。CellStore文件存储Access Group中的(Key,Value)列表(带操作类型),文件中的数据经过排序,压缩,并且不会被修改。在CellStore文件内部包含多个64K(可配置)大小的块,为了便于索引CellStore中的数据,在CellStore文件的结尾处保存了这些块的索引数据,以便系统能迅速定位到数据在文件中的哪个64K块中。Cell store的索引主要有三个部分:
l Bloom Filter:该索引部分采用Bloom Filter技术,用于64k块内索引,目前保留,未实现;
l 块索引:该索引部分记录每64k块的索引,用于快速定位块,它的格式为 row key + 块在文件内的偏移;
l Trailer:用于定位Bloom Filter块,块索引部分的定位。系统读取这部分,获取Bloom Filter和块索引的位置。
随着数据的增长,在一个row range(tablet)中,一个access group可以动态产生多个CellStore文件,这些文件由Range Server动态维护,参照Range Server描述。
2.3 一个示例
如图2-6所示的逻辑模型,示例crawldb table用于存储从internet抓取的网页信息,其中:Row Key为网页的URL,出于排序效率考虑,URL中主机域名字符顺序往往被反置,如www.facebook.com被处理为com.facebook.www;Column Family包括title、content、anchor,其中tile保存网页的标题,content保存网页html内容,anchor保存网页被其它网页引用的链接,qualifier就是其它网页的URL,内容为其它网页中该链接的页面显示字符,同样anchor链接的URL主机域字符串被反置。对于不同时间获取的同一网页的有关内容被打上不同的时间戳,如图纵向座标可以看到不同的版本。
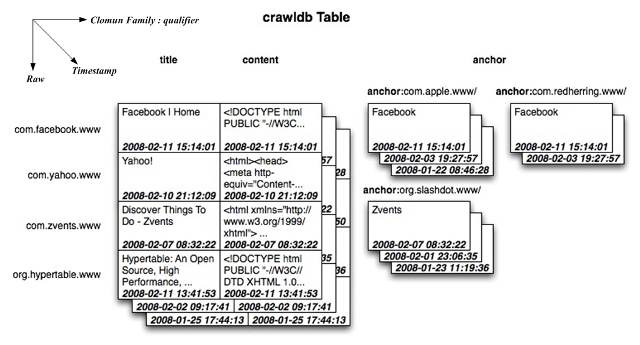
Figure 2-6 Crawldb Table Logical Model
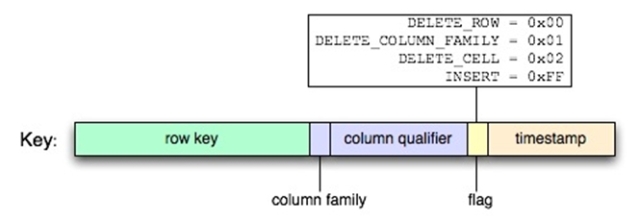
在实际的存储中,图2-6所示的多维逻辑结构会被二维平面化为(Key, Value)对,并且进行排序。在(Key,Value)中,Key由四维键值组成,包括:Row Key, Column Family(处理时使用8比特编码), Column Qualifier和Timestamp,如图2-7所示,为Key的实际结构,在对Key进行排序过程中,有最新Timestamp的Key会被排在最前面,flag项用于标明系统需要对该(Key,Value)记录进行的操作符,如增加、删除、更新等。
如图2-8是crawldb二维平面化后经过排序的格式。图中Key列中的信息由Row Key(页面的URL)、Column Family、Column Qualifer和Timestamp组成,其中并未显示Key flag项,flag项主要用于表项处理。
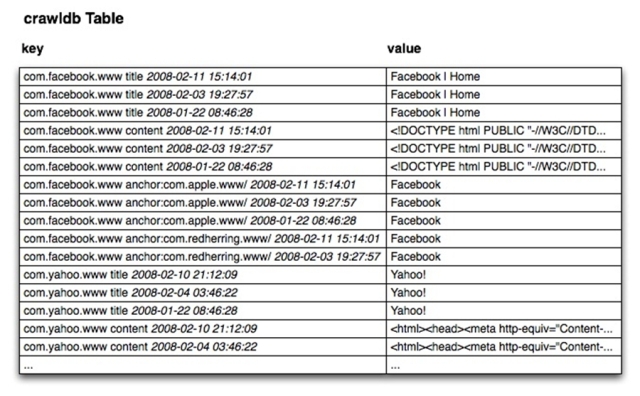
Figure 2-8 Sorted Key/Value list
图2-9显示了crawldb table的CellStore文件格式。CellStore文件中存储了经过排序后的Key,Value对,物理上,这些数据都被压缩后存储,以大约64k大小的块为单位组织;在文件结尾处,保留有三个索引部分:Bloom Filter、块索引(row key + 块在文件内的偏移)、Trailer。

3 Architecture
Hypertable的实现主要包括以下5个部分:
l 应用API Library
l Hyperspace Server
l Master Server
l Range Server
l DFS Broker
如图3-1所示Hypertable系统侧的主要架构。整个系统构建在分布式并行文件系统之上(本地文件系统也支持)。用户应用程序通过Hypertable提供的API编程接口库,使用Hypertable(参见第6章)。
3.1 DFS Broker
Hypertable设计运行在分布式并行文件系统之上,也不局限于此,还可以运行在本地文件系统之上,尤其是在用户单机调试和试用的时候。同时,由于分布式并行文件系统的类型有很多,为了使Hypertabe的系统模块能很好在不同的文件系统上运行,Hypertable提供了一个文件系统访问抽象层:DFS Broker。
DFS Broker的API接口层,为Hypertable提供了统一的文件系统访问接口,Hypertable系统进程调用DFS Broker的文件操作API后,DFS Broker API会将相应的文件操作以消息的形式发送给DFS Broker,DFS Broker根据具体的文件系统类型,调用相应的操作接口,完成文件系统的访问。目前,Hypertable DFS Broker实现了Hadoop DFS, KFS以及本地(Local)文件系统接口,用户可以根据自己的需要,在现有的DFS Broker框架下,实现其它分布式文件系统的接口,将Hypertable扩展到更多的DFS之上。
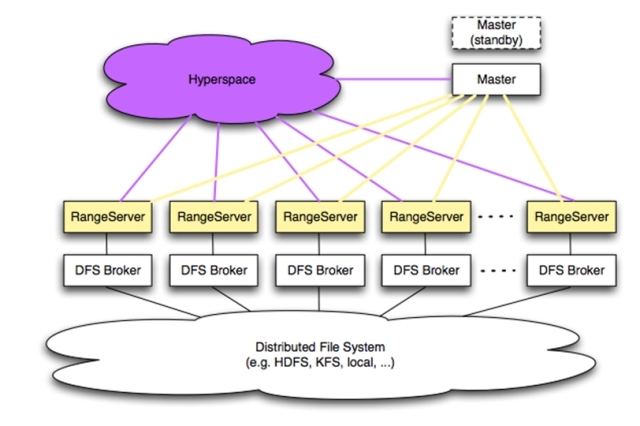
Figure 3-1 Hypertable System Architecture
3.2 Hyperspace
Hyperspace是类似Google Bigtable系统中的Chubby 功能。Chubby在Google Bigtable系统中主要实现两个功能,一是为Bigtable提供一个粗粒度锁服务;其次是提供高效,可靠的主机选举服务。由于Bigtable的粗粒度锁服务往往构建在具有统一namespace的文件系统上(早期在Database上),因此它同时具备轻量级的存储功能,可以存储一些元数据信息。如图3-1所示,Hyperspace作为一个服务器族存在,通常情况下,一个Hyperspace Server族一般由5或11台服务器组成,他们基于Paxos选举算法,在服务器中选举出一个Active Server,其它的服务器作为Standby Servers存在,在系统运行过程中,Active Server和Standby Servers之间会同步状态和数据(数据经常由文件系统或数据库自己完成)。截至本文档发布之前,Hyperspace还未发布Active/Standby功能。从实现的角度来看,实现1+1的备份方式,也可以作为Hyperspace HA 的一种实现方法,但显然可靠性要低于Chubby的实现方式。
目前,Hyperspace基于BSD DB构建它的锁服务,通过BSD DB API,Hyperspace构建一个namespace,该namespace中包含目录和文件节点,每一个目录或文件可以赋予许多的属性,如锁的属性。Hyperspace Client是访问Hyperspace的客户端模块。Hypertable中的其它系统模块通过该Client与Hyperspace Server建立Session链接,通过该链接完成Hyperspace中目录和文件的操作(如读,写,锁操作等)。Session链接采用租约机制,客户端必须定期更新租约期限,如果到期未更新,Hyperspace认为客户端out of service,随机释放客户端所占用的文件和锁资源。Hyperspace Client为客户端应用提供了callback方式的事件通知机制,客户端应用可以通过Session链接,向Hyperspace注册自己关注的对象(目录或文件)的有关事件,也可以向Session本身注册时间callback。如文件,或目录的删除时间,锁操作事件,Session的终止事件等。
由于Hyperspace的设计满足高可靠性要求,因此它除了提供粗粒度锁服务以外,还承担着部分的小数据量的存储任务。如2.2.1中提到的Metadata0 tablet location就存储在Hyperspace,作为整个Hypertable tablets索引的根节点。另外,Hyperspace也会存储Metadata schema,access control list(目前未实现);同时,由于Hypersapce提供了Hypertable系统中所有主机节点的锁服务,所有节点会在Hyperspace的namespace中创建自己的主机节点,并获取相应的锁,因此Hyperspace同时充当了记录Hypertable系统中主机状态的任务,并且根据客户端注册的callback信息分发相应的状态改变事件。
由此可见,Hyperspace作为一个需要设计成具有高可用性的子系统,如果Hyperspace停止工作,Hypertable也就对外不能提供服务了。
3.3 Range Server
在Hypertable系统中,表按row range分割为许多tablet,这些tablet由range server维护,一个range server主机可以维护多个tablet。Range server负责处理所有的该row range的读写操作。
如图3-2,range server处理写数据(如insert、update、delete等数据操作)时,range server将检查它的格式是否合法以及该操作的访问权限(目前还未实现access control);检查成功后,先将数据(和操作)写入Commit Log文件,随后将数据按顺序缓存在Cell Cache中,随着Cell Cache不断增长,达到Cell Cache的容量门限,range server将新建一个Cell Cache,将旧的Cell Cache写入DFS cell store文件,此过程也称作为Minor Compaction(次级紧置化)。Minor compaction起到主要作用有两个,一是通过将Cell Cache写入DFS,回收Cell Cache内存,使得range server不会因为cell cache的无限增长而消耗完内存资源;其次,由于range server将写数据首先保存在commit log文件中,以备系统崩溃后,能读取commit log恢复到崩溃前的数据状态;因此,在旧的cell cache被写入cell store文件后,commit log中相应的log就可以被清除,从而有效地回收了commit log文件空间。
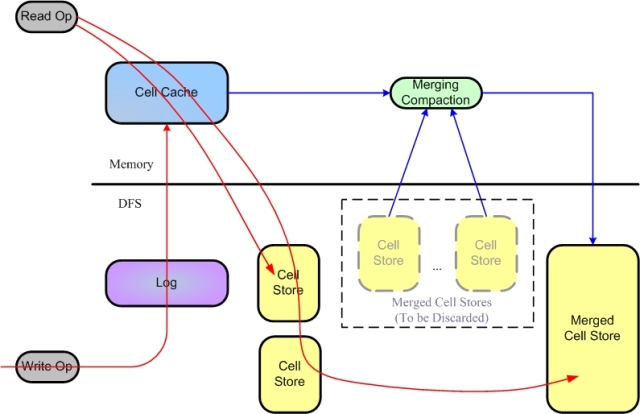
Figure 3-2 A Tablet in Tablet Server
随着数据操作的不断增加,Cell Store文件也不断增多,当文件个数达到门限时,range server将执行merging compaction操作,该操作将选择部分cell store文件与cell cache合并为一个较大的cell store文件。此时的merging compaction操作中,所有文件和cache的数据被重新排序到新的cell store文件中,并不执行数据的计算合并操作,因此所有的delete数据仍然存在于新的cell store文件中。
有一种特殊的merging compaction操作,发生在tablet分裂前,range server会将该tablet的所有cell store文件和cell cache合并为一个大的cell store文件,该操作称为Major Compaction(当前hypertable并未实现定时major compaction)。Major compaction在合并文件和cache过程中会对计算数据进行合并计算,所产生的新cell store文件不再包含delete操作的数据。Major compaction可以有效地回收存储空间,其次,由于新产生的cell store文件已经完成数据操作的合并运算,使得数据的读写操作性能更高。
如图3-2所示,数据读取操作需要访问多个cell store文件和cell cache,如2.2.2所述,cell store文件中包含有多个索引块,这些索引块运行时缓存在内存中,当一个读取操作来到range server时,range server将检查它的格式是否合法以及该操作的访问权限(目前还未实现access control);检查成功后,range server将定位该row key可能存在的所有cell store文件,包括cell cache,扫描相关cell store和cell cache,为该次读操作在内存执行merging操作,并返回结果。由于所有key,value数据对在cell store和cache中已经按字典序排列,因此扫描和merging操作的效率较高。
Range server在处理读写请求时,仍然可以进行其它的处理操作。在进行minor compaction前,由于range server会新建一个cell cache,因此,在进行minor compaction时不会阻塞读写请求。其它的如执行tablet split,merging compaction,以及major compaction时,range server会在cell cache中给新来的写数据置时间标记,以便和正在参与操作的cache数据区别开来。
Tablet的永久存储模式是DFS上的cell store文件、log文件以及Hyperspace上的schema,tablet的索引在2.2.1所述的metadata table中。如果一个range server停止服务,hypertable系统(通常是Master调度)将选择另一个的range server(该range server可能已经维护了其它的tablet)去恢复(Recover)该tablet。Range server在恢复tablet过程中,首先从metadata table中读取该tablet的metadata,该metadata中包含有cell store文件列表(参见2.2.1),以及一组Redo指针(??),这些指针指向Commit Log中需要Redo的操作记录。Range server根据这些信息重构一个tablet,包括为该tablet创建cell cache,缓存所有cell store的索引,执行Redo操作等。
3.4 Master
如图3-1所示,master主要负责Hypertable 系统中的调度工作,主要包括:
u 处理元数据操作,如表的创建、和删除;
u 管理range server池,指派range server所维护的range server,并实现range server的load balance调度(目前使用round robin算法,还为基于服务器负荷调度);
u 检测range server加入/离开Hypertable系统;
u 回收DFS的discarded文件
u 处理表schema变化,如创建新的column family操作(目前为实现)
Master并不直接处理hypertable client提交的数据,由于metadata表数据作为一个普通的table由系统中的range server维护,而且metadata0的location存储在hyperspace中;因此在hypertable系统中出现master server的短暂OOS(out of service)是可以容忍的,在master server短暂的OOS期间,hypertable系统不能处理新表的创建,和range server的调度,但并不妨碍hypertable client对已经存在的表的读写操作。
3.5 Chubby or HA
如图3-1所示,hypertable系统中对于range server而言,它的调度主要由master负责,整个系统的业务逻辑已经包含了range server的高可用性(HA)功能。然而hyperspace和master的高可用性并不包含在hypertable的业务逻辑中。当前的hypertable版本(0.9.x.x)中,hyperspace和master都只实现了单点服务器的模式,从图3-1所示,hypertable将在近期的版本中规划这两个子系统的HA实现,其中hyperspace采用类似Chubby的服务器集群方式,而master采用1+1的active/standby方式。
注:部分图片来源于 http://www.hypertable.org/















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









