






目录
适用问题:多类分类
模型特点:特征条件下类别的条件概率分布;对数线性模型
模型类型:判别模型
损失函数:逻辑斯蒂损失
学习策略:极大似然估计,或者正则化的极大似然估计
学习算法:梯度下降法、拟牛顿法
一、理解逻辑斯蒂回归的原理
1.模型函数
逻辑斯蒂回归是解决分类任务的。逻辑斯蒂回归模型属于“对数线性模型”
先看看逻辑斯蒂回归与线性回归的联系。首先想到的是线性回归+阈值,可以转化为一个分类任务,以阈值划分区间,落到不同范围则分成不同的类,例如使用“单位阶跃函数”:

单位阶跃函数缺点 :不连续
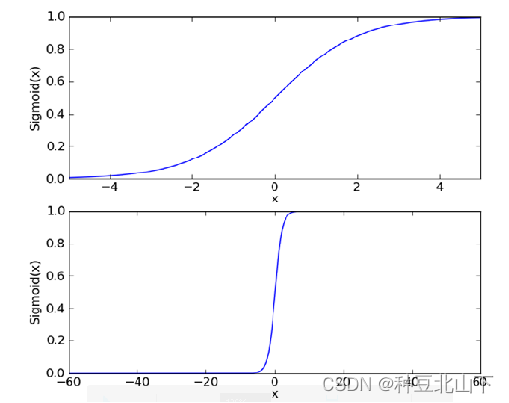
1.1 替代函数——逻辑斯蒂函数(logistic/sigmoid function): 单调可微、任意阶可导
 ----------------->
----------------->
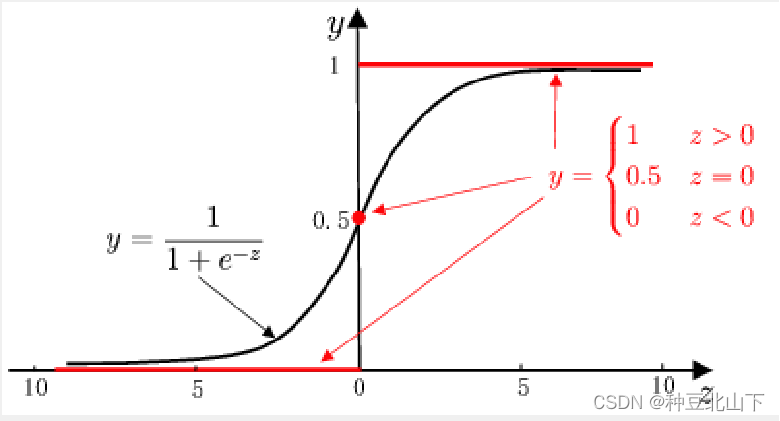
单位阶跃函数与sigmoid函数的比较
1.2 sigmoid函数
def sigmoid(z):
return 1./(1+np.exp(-z))
使用“sigmoid”函数代替“单位阶跃函数”,即使用“sigmoid”函数作为联系函数g ( ⋅ ) ,并令z = x θ,则得到了二元逻辑斯蒂回归模型的一般形式:

x作为样本输入,h θ (x)作为模型输出,并将其视作后验概率p ( y = 1 ∣ x , θ ) p(y=1|x,\theta)p(y=1∣x,θ)。
(1)当x θ > 0 时,h θ > 0.5 ,y预测为1,且当h θ → 1 时,y预测分类为1的概率就越大
(2)当x θ <0 时,h θ < 0.5 ,y预测为0,且当h θ → 0 时,y预测分类为0的概率就越大
(3)当x θ =0 时,h θ = 0.5时,无法做出预测
2.损失函数
平方损失在逻辑斯蒂回归分类问题中是非凸的,逻辑回归不是连续的,所以这里不再使用平方损失,而是使用极大似然来推导损失函数
把p ( y = 1 ∣ x , θ ) 和p ( y = 0 ∣ x , θ ) 的式子结合起来,写成一个式子:

即为一个样本属于其真实label y的概率分布表达式.
似然函数的目标是:令每个样本属于其真实label的概率越大越好,即“极大似然法”。
似然函数为:
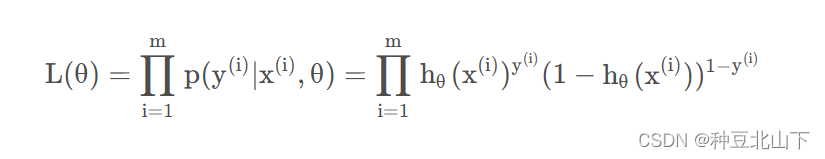
令L ( θ ) 越大越好,即求L ( θ ) 的极大值,作为优化目标,求解对应的参数,即使用“极大似然估计”.
3. 学习算法
逻辑斯蒂回归学习常采用梯度下降法以及拟牛顿法。这里给出使用梯度下降法对损失函数的优化过程。

二、代码实例
2.1 导入所需的库
import torch
from torch import nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
2.2 定义假数据
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
2.3 创建模型类
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.lr = nn.Linear(2, 1)
self.sm = nn.Sigmoid()
def forward(self, x):
x = self.lr(x)
x = self.sm(x)
return x
2.4 创建模型实例
logistic_model = LogisticRegression()
if torch.cuda.is_available():
logistic_model.cuda()
2.5 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(logistic_model.parameters(), lr=1e-3, momentum=0.9)
2.6 开始训练
for epoch in range(10000):
if torch.cuda.is_available():
x_data = Variable(x).cuda()
y_data = Variable(y).cuda()
else:
x_data = Variable(x)
y_data = Variable(y)
out = logistic_model(x_data)
loss = criterion(out, y_data)
mask = out.ge(0.5).float()
correct = (mask == y_data).sum()
acc = correct.item() / x_data.size(0)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print('*'*10)
print('epoch {}'.format(epoch+1))
print('loss is {:.4f}'.format(print_loss))
print('acc is {:.4f}'.format(acc))
2.7 结果可视化
w0, w1 = logistic_model.lr.weight[0]
w0 = float(w0.item())
w1 = float(w1.item())
b = float(logistic_model.lr.bias.item())
plot_x = np.arange(-7, 7, 0.1)
plot_y = (-w0 * plot_x - b) / w1
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
plt.plot(plot_x, plot_y)
plt.show()
结果展示

三、实验思路
-
生成假数据:生成两类数据,每类包含100个样本,分别用
x0和y0表示类型0的数据,用x1和y1表示类型1的数据。 -
定义逻辑回归模型:使用PyTorch定义一个逻辑回归模型
LogisticRegression,其中包括一个线性层和一个Sigmoid函数。 -
定义损失函数和优化器:选择二分类交叉熵损失函数
BCELoss作为模型的损失函数,选择随机梯度下降优化器SGD进行参数优化。 -
开始训练:通过迭代训练过程,对模型进行训练。在每个训练轮次中,计算模型输出与真实标签之间的损失,并根据损失值更新模型的参数。同时,计算分类精度并打印出当前的误差和精度。
-
结果可视化:从训练好的模型中获取权重和偏置参数,并根据决策边界的公式计算决策边界上的点坐标。然后使用Matplotlib库将生成的数据点和决策边界进行可视化展示。
四、代码讲解
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1)
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
这段代码生成了两个类别的假数据。x0和x1是输入特征,它们基于n_data进行了正态分布采样得到,而y0和y1则是对应的标签,分别表示第一个类别和第二个类别。这样的数据可以用于训练和测试分类模型。
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.lr = nn.Linear(2, 1)
self.sm = nn.Sigmoid()def forward(self, x):
x = self.lr(x)
x = self.sm(x)
return x
这段代码定义了一个简单的逻辑回归模型。模型的输入是一个2维的特征向量,通过一个线性层映射到一个标量输出。然后,通过Sigmoid激活函数对输出进行非线性变换,得到一个表示概率的值。
logistic_model = LogisticRegression()
if torch.cuda.is_available():
logistic_model.cuda()
这段代码创建了一个逻辑回归模型的实例,并将模型移到GPU上
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(logistic_model.parameters(), lr=1e-3, momentum=0.9)
这段代码定义了二分类交叉熵损失函数(nn.BCELoss)和随机梯度下降优化器(torch.optim.SGD)。
x_data = Variable(x)
y_data = Variable(y)
如果支持CUDA,则将输入数据x和标签数据y转换为CUDA张量,并用Variable进行包装。
mask = out.ge(0.5).float()
根据模型输出out是否大于等于0.5,创建一个掩码张量mask,将大于等于0.5的位置标记为1,小于0.5的位置标记为0。
correct = (mask == y_data).sum()
统计预测正确的样本数量,即模型输出与标签相匹配的数量。
acc = correct.item() / x_data.size(0)
根据预测正确的数量计算准确率acc,即预测正确的样本数量占总样本数量的比例。
w0, w1 = logistic_model.lr.weight[0]
从逻辑回归模型logistic_model中获取权重参数w0和w1,这里假设模型只有一层线性层。
plot_x = np.arange(-7, 7, 0.1)
plot_y = (-w0 * plot_x - b) / w1
创建一个numpy数组plot_x,用于绘制模型的决策边界,根据权重参数w0、w1和偏置参数b计算决策边界上的所有点的纵坐标,并保存在plot_y中。
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')
绘制散点图,其中横坐标为输入数据x的第一列特征,纵坐标为输入数据x的第二列特征,颜色为标签数据y。这里使用了data.numpy()将张量转换为numpy数组,并设置了点的大小、线宽和颜色映射。
五、实验总结
1.实验中遇到的问题
(1)生成假数据时,需要确保数据的生成方式与实际情况相符。在这个实验中,通过使用torch.normal函数生成服从正态分布的数据,但需要注意数据的均值和方差是否与实际情况匹配。
(2)将数据输入模型之前,需要确保数据的类型正确。在实验中,需将数据类型转换为FloatTensor,并使用.type(torch.FloatTensor)进行转换。
(3)在训练过程中,需要确保在每个训练轮次中都对参数进行更新。在实验中,使用优化器SGD来更新模型的参数,并使用optimizer.zero_grad()方法清零梯度。
(4)在将结果可视化时,需要确保图表绘制正确。在这个实验中,使用plt.scatter绘制数据点,使用plt.plot绘制决策边界。
2.Logistic回归优点
(1)无需事先假设数据分布
(2)可得到“类别”的近似概率预测(概率值还可用于后续应用)
(3)可直接应用现有数值优化算法(如牛顿法)求取最优解,具有快速、高效的特点
【本篇博客理论知识借鉴逻辑斯蒂回归(logistic regression)原理小结_mixed logit regression accuracy-CSDN博客】














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









