







这篇是线性表的终结篇,重点是循环链表和双链表
一、循环链表的存储结构
循环链表是另一种形式的链式存储结构。它的特点是表中最后一个节点的指针域指向头结点。
【循环链表图】
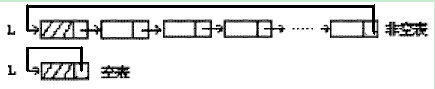
循环链表的操作和线性链表基本一致,差别仅在于算法中的循环条件不是p或p->next是否为空,而是它们是否等于头指针。
二、
双向链表的存储结构
双向链表
也叫双链表,是链表的一种,
它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
【双链表图】
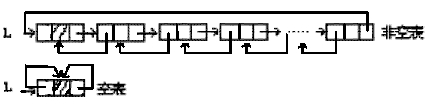
QUE:单向链表,双向链表各有什么优缺点?
ANS:
单向链表:
优点:单向链表增加删除节点简单。遍历时候不会死循环。
缺点:只能从头到尾遍历。只能找到后继,无法找到前驱,也就是只能前进。
双向链表:
优点:可以找到前驱和后继,可进可退。
缺点:增加删除节点复杂。
ANS:
单向链表:
优点:单向链表增加删除节点简单。遍历时候不会死循环。
缺点:只能从头到尾遍历。只能找到后继,无法找到前驱,也就是只能前进。
双向链表:
优点:可以找到前驱和后继,可进可退。
缺点:增加删除节点复杂。
(1)线性表的双向链表存储结构
typedef struct DulNode{
struct DulNode *prior;
ElemType data;
struct DulNode *next;
}DulNode,*DuLinkList;
对指向双向链表任一结点的指针d,有下面的关系:
d->next->priou=d->priou->next=d
即:当前结点后继的前趋是自身,当前结点前趋的后继也是自身。
(2)双向链表的删除操作
【图】
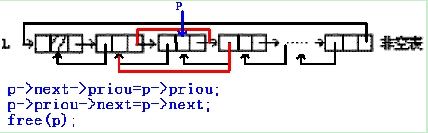
status ListDelete_Dul(DuLinkList &L,int i, ElemType &e)
{
DuLinkList *p;
if(!(p=GetElemP_Dul(L,i))) //GetElemP_Dul(L,i)是在链表中查找第i个结点
return ERROR;
e=p->data;
p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
return OK;
}
(3)双向链表的插入操作
【图】
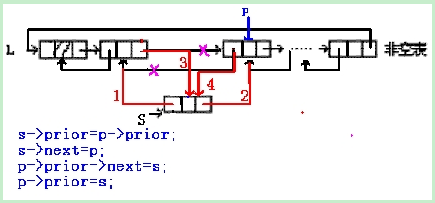
status ListInsert_Dul(DuLinkList &L,int i, ElemType &e)
{
DuLinkList *p;
if(!(p=GetElemP_Dul(L,i)))
return ERROR;
if(!(s=(DulLinkList)malloc(sizeof(DuLNode))))
return ERROR;
s->data=e;
s->prior=p->prior;
p->prior->next=s;
s->next=p;
p->prior=s;
return OK;
}
下一篇介绍“栈”
网络不给力,无法上传图,等网速好的时候我再上传缺失的图。















 1201
1201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









