







来源:《数据挖掘概念与技术:第六章》
关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。随着大量数据不停地收集和存储,许多业界人士对于从他们的数据库中挖掘关联规则越来越感兴趣。从大量商务事务记录中发现有趣的关联关系,可以帮助许多商务决策的制定,如分类设计、交叉购物和贱卖分析。
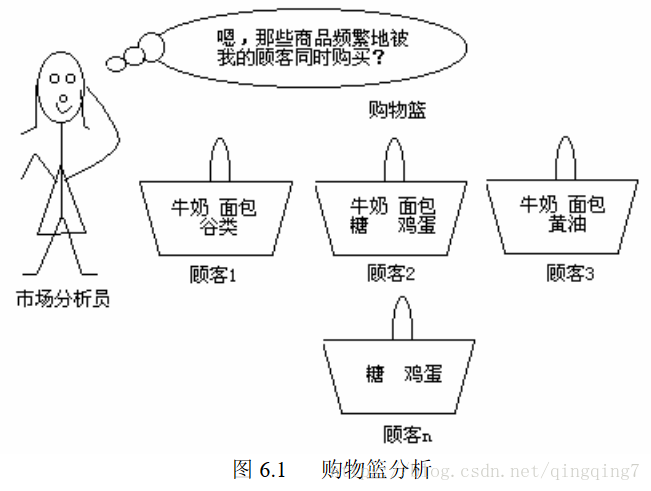
关联规则挖掘的一个典型例子是购物篮分析。该过程通过发现顾客放入其购物篮中不同商品(图6.1)之间联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。例如,在同一次去超级市场,如果顾客购买牛奶,他也购买面包(和什么类型的面包)的可能性有多大?通过帮助零售商有选择地经销和安排货架,这种信息可以引导销售。例如,将牛奶和面包尽可能放近一些,可以进一步刺激一次去商店同时购买这些商品。
数据是事务的或关系的,如何由大量的数据中发现关联规则?什么样的关联规则最有趣?我们如何帮助或指导挖掘过程发现有趣的关联规则?对于关联规则挖掘,什么样的语言结构对于定义关联挖掘查询是有用的?本章我们将深入研究这些问题。
关联规则挖掘
关联规则挖掘寻找给定数据集中项之间的有趣联系。本节简要介绍关联规则挖掘。6.1.1小节给出一个购物篮分析的例子,这是关联规则挖掘的最初形式。挖掘关联规则的基本概念在6.1.2小节给出。6.1.3小节给出一个路线图,指向可挖掘的各种不同类型关联规则。
购物篮分析:一个引发关联规则挖掘的例子
假定作为 AllElectronics 的分店经理,你想更加了解你的顾客的购物习惯。例如,你想知道“什么商品组或集合顾客多半会在一次购物时同时购买?”为回答你的问题,你可以在你的商店顾客事务零售数据上运行购物篮分析。分析结果可以用于市场规划、广告策划、分类设计。例如,购物篮分析可以帮助经理设计不同的商店布局。一种策略是:经常一块购买的商品可以放近一些,以便进一步刺激这些商品一起销售。例如,如果顾客购买计算机也倾向于同时购买财务软件,将硬件摆放离软件陈列近一点,可能有助于增加二者的销售。另一种策略是:将硬件和软件放在商店的两端,可能诱发买这些商品的顾客一路挑选其它商品。例如,在决定购买一台很贵的计算机之后,去看软件陈列,购买财务软件,路上可能看到安全系统,可能会决定也买家庭安全系统。购物篮分析也可以帮助零售商规划什么商品降价出售。如果顾客趋向于同时购买计算机和打印机,打印机降价出售可能既促使购买打印机,又促使购买计算机。
如果我们想象全域是商店中可利用的商品的集合,则每种商品有一个布尔变量,表示该商品的有无。每个篮子则可用一个布尔向量表示。可以分析布尔向量,得到反映商品频繁关联或同时购买的购买模式。这些模式可以用关联规则的形式表示。例如,购买计算机也趋向于同时购买财务管理软件可以用以下关联规则表示:
规则的支持度和置信度是两个规则兴趣度度量,已在前面4.1.4小节介绍。它们分别反映发现规则的有用性和确定性。关联规则(6.1)的支持度2%意味分析事务的2%同时购买计算机和财务管理软件。置信度60%意味购买计算机的顾客60%也购买财务管理软件。关联规则是有趣的,如果它满足最小支持度阈值和最小置信度阈值。这些阈值可以由用户或领域专家设定。
基本概念
设
I={i1,i2,…,im}
I
=
{
i
1
,
i
2
,
…
,
i
m
}
是项的集合;设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得
T⊆I
T
⊆
I
; 每一个事务有一个标识符,称作TID。设A是一个项集,事务T包含A当且仅当
A⊆T
A
⊆
T
。关联规则是形如”
A⇒B
A
⇒
B
”形式的蕴含式;其中有
A⊂I
A
⊂
I
,
B⊂I
B
⊂
I
且
A∩B=∅
A
∩
B
=
∅
。规则
A⇒B
A
⇒
B
在事务集D中成立,具有支持度s,其中s是D中事务包含
A∪B
A
∪
B
(即,A和B二者)的百分比。它是概率
P(A∪B)
P
(
A
∪
B
)
。规则
A⇒B
A
⇒
B
在事务集D中具有置信度c,如果D中包含A的事务同时也包含B的百分比是c。这是条件概率
P(B|A)
P
(
B
|
A
)
。即
同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称作 强规则。为方便计,我们用0%和100%之间的值,而不是用0到1之间的值表示支持度和置信度。
项的集合称为 项集15 项 集 15 。包含k个项的项集称为 k-项集。集合
{computer, financial_management_ software}是一个2-项集。项集的
出现频率是包含项集的事务数,简称为项集的
频率、
支持计数或
计数。如果项集的出现频率大于或等于min_sup与D中事务总数的乘积,项集满足
最小支持度
min_sup。如果项集满足最小支持度,则称它为频
繁项集16
繁
项
集
16
。频繁k -项集的集合通常记作
Lk
L
k
17
17
。
“如何由大型数据库挖掘关联规则?”关联规则的挖掘是一个两步的过程:
- 1.找出所有频繁项集:根据定义,这些项集出现的频繁性至少和预定义的最小支持计数一样。
- 2.由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度。
如果愿意,也可以使用附加的兴趣度度量。这两步中,第二步最容易。挖掘关联规则的总体性能由第一步决定。
关联规则挖掘:一个路线图
购物篮分析只是关联规则挖掘的一种形式。事实上,有许多种关联规则。根据下面的标准,关联规则有多种分类方法:
- 根据规则中所处理的值类型:
- 如果规则考虑的关联是项的在与不在,则它是布尔关联规则。例如,上面的规则(6.1)是由购物篮分析得到的布尔关联规则。
- 如果规则描述的是量化的项或属性之间的关联,则它是量化关联规则。在这种规则中,项或属性的量化值划分为区间。下面的规则(6.4)是量化关联规则的一个例子,其中,X是代表顾客的变量。
age(X,"30−39")income(X,"42K−48K")⇒buys(X,"highresolutionTV")(6.4) a g e ( X , " 30 − 39 " ) i n c o m e ( X , " 42 K − 48 K " ) ⇒ b u y s ( X , " h i g h r e s o l u t i o n T V " ) ( 6.4 )
注意,量化属性age 和income已离散化。
- 根据规则中涉及的数据维:
如果关联规则中的项或属性每个只涉及一个维,则它是单维关联规则。注意,(6.1)式可以写作
buys(X,"computer")⇒buys(X,"finacialmanagementsoft")(6.5) b u y s ( X , " c o m p u t e r " ) ⇒ b u y s ( X , " f i n a c i a l m a n a g e m e n t s o f t " ) ( 6.5 )
规则(6.1)是单维关联规则,因为它只涉及一个维buys。如果规则涉及两个或多个维,如维buys, time_of_transaction和customer_category,则它是多维关联规则。上面的规则(6.4)是一个多维关联规则,因为它涉及三个维age, income和buys。 - 根据规则集所涉及的抽象层:
有些挖掘关联规则的方法可以在不同的抽象层发现规则。例如,假定挖掘的关联规则集包含下面规则:
age(X,"30−39")⇒buys(X,"laptop computer")(6.6)age(X,"30−39")⇒buys(X,"computer")(6.7) a g e ( X , " 30 − 39 " ) ⇒ b u y s ( X , " l a p t o p c o m p u t e r " ) ( 6.6 ) a g e ( X , " 30 − 39 " ) ⇒ b u y s ( X , " c o m p u t e r " ) ( 6.7 )
在规则(6.6)和(6.7)中,购买的商品涉及不同的抽象层(即,”computer”在比”laptop computer”高的抽象层)。我们称所挖掘的规则集由多层关联规则组成。反之,如果在给定的规则集中,规则不涉及不同抽象层的项或属性,则该集合包含单层关联规则。 - 根据关联挖掘的各种扩充:
关联挖掘可以扩充到相关分析,那里,可以识别项是否相关。还可以扩充到挖掘最大模式(即,最大的频繁模式)和频繁闭项集。最大模式是频繁模式p,使得p的任何真超模式都不是频繁的。频繁闭项集是一个频繁的、闭的项集;其中,项集c是闭的,如果不存在c的真超集c’,使得每个包含c的事务也包含c’。使用最大模式和频繁闭项集可以显著地压缩挖掘所产生的频繁项集数。
本章的其余部分,你将学习上述每种关联规则的挖掘方法。
由事务数据库挖掘单维布尔关联规则
本节,你将学习挖掘最简单形式的关联规则的方法。这种关联规则是单维、单层、布尔关联规则,如6.1.1小节所讨论的购物篮分析中的那些。我们以提供Apriori算法开始(6.2.1小节)。Apriori算法是一种找频繁项集的基本算法。由频繁项集产生强关联规则的过程在6.2.2小节给出。6.2.3小节介绍Apriori算法的一些变形,用于提高效率和可规模性。6.2.4小节提出一些挖掘关联规则方法,不象Apriori,它们不涉及“候选”频繁项集的产生。6.2.5小节介绍如何将Apriori的原则用于提高冰山查询的效率。冰山查询在购物篮分析中是常见的。
Apriori算法:使用候选项集找频繁项集
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。算法的名字基于这样的事实:算法使用频繁项集性质的先验知识,正如我们将看到的。Apriori使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出频繁1-项集的集合。该集合记作
L1
L
1
。
L1
L
1
用于找频繁2-项集的集合
L2
L
2
,而
L2
L
2
用于找
L3
L
3
,如此下去,直到不能找到频繁k-项集。找每个
Lk
L
k
需要一次数据库扫描。
为提高频繁项集逐层产生的效率,一种称作Apriori性质的重要性质用于压缩搜索空间。我们先介绍该性质,然后用一个例子解释它的使用。
Apriori性质:频繁项集的所有非空子集都必须也是频繁的。Apriori性质基于如下观察:根据定义,如果项集I不满足最小支持度阈值s,则I不是频繁的,即
P(I)<s
P
(
I
)
<
s
。如果项A添加到I,则结果项集(即,
I∪A
I
∪
A
)不可能比I更频繁出现。因此,
I∪A
I
∪
A
也不是频繁的,即
P(I∪A)<s
P
(
I
∪
A
)
<
s
。
该性质属于一种特殊的分类,称作反单调,意指如果一个集合不能通过测试,则它的所有超集也都不能通过相同的测试。称它为反单调的,因为在通不过测试的意义下,该性质是单调的。
“如何将Apriori性质用于算法?”为理解这一点,我们必须看看如何用
Lk−1
L
k
−
1
找
Lk
L
k
。下面的两步过程由连接和剪枝组成。
- 连接步: 为找
Lk
L
k
,通过
Lk−1
L
k
−
1
与自己连接产生候选k-项集的集合。该候选项集的集合记作
Ck
C
k
。设
l1
l
1
和
l2
l
2
是
Lk−1
L
k
−
1
中的项集。记号
li[j]
l
i
[
j
]
表示
li
l
i
的第
j
j
项(例如,表示
l1
l
1
的倒数第3项)。为方便计,假定事务或项集中的项按字典次序排序。执行连接
Lk−1
L
k
−
1
Lk−1
L
k
−
1
;其中,
Lk−1
L
k
−
1
的元素是可连接的,如果它们前(k-2)个项相同;即,
Lk−1
L
k
−
1
的元素
l1
l
1
和
l2
l
2
是可连接的,如果
(l1[1]=l2[1])∧(l1[2]=l2[2])∧⋯∧(l1[k−2]=l2[k−2])∧(l1[k−1]<l2[k−1])
(
l
1
[
1
]
=
l
2
[
1
]
)
∧
(
l
1
[
2
]
=
l
2
[
2
]
)
∧
⋯
∧
(
l
1
[
k
−
2
]
=
l
2
[
k
−
2
]
)
∧
(
l
1
[
k
−
1
]
<
l
2
[
k
−
1
]
)
条件 (l1[k−1]<l2[k−1]) ( l 1 [ k − 1 ] < l 2 [ k − 1 ] ) 是简单地保证不产生重复。连接 l1 l 1 和 l2 l 2 产生的结果项集是 l1[1]l1[2]…l1[k−1]l2[k−1] l 1 [ 1 ] l 1 [ 2 ] … l 1 [ k − 1 ] l 2 [ k − 1 ] 。 - 剪枝步: Ck C k 是 Lk L k 的超集;即,它的成员可以是,也可以不是频繁的,但所有的频繁k-项集都包含在 Ck C k 中。扫描数据库,确定 Ck C k 中每个候选的计数,从而确定 Lk L k (即,根据定义,计数值不小于最小支持度计数的所有候选是频繁的,从而属于 Lk L k )。然而, Ck C k 可能很大,这样所涉及的计算量就很大。为压缩 Ck C k ,可以用以下办法使用Apriori性质:任何非频繁的(k-1)-项集都不是可能是频繁k-项集的子集。因此,如果一个候选k-项集的(k-1)-子集不在 Lk−1 L k − 1 中,则该候选也不可能是频繁的,从而可以由 Ck C k 中删除。这种子集测试可以使用所有频繁项集的散列树快速完成。
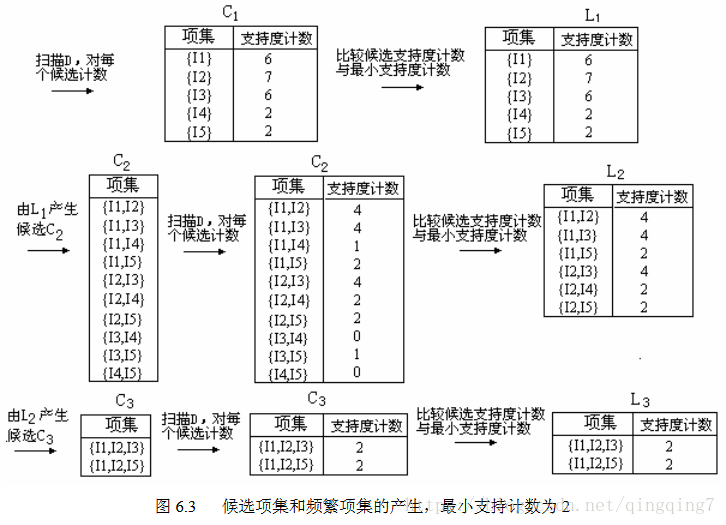
例6.1让我们看一个Apriori的具体例子。该例基于图6.2的AllElectronics的事务数据库。数据库中有9个事务,即|D| = 9。Apriori假定事务中的项按字典次序存放。我们使用图6.3解释Apriori算法发现D中的频繁项集。
| TID | List of item_ID’s |
|---|---|
| T100 | I1,I2,I5 |
| T200 | I2,I4 |
| T300 | I2,I3 |
| T400 | I1,I2,I4 |
| T500 | I1,I3 |
| T600 | I2,I3 |
| T700 | I1,I3 |
| T800 | I1,I2,I3,I5 |
| T900 | I1,I2,I3 |
- 在算法的第一次迭代,每个项都是候选1-项集的集合 C1 C 1 的成员。算法简单地扫描所有的事务,对每个项的出现次数计数。
- 假定最小事务支持计数为2(即,min_sup = 2/9 = 22%)。可以确定频繁1-项集的集合 L1 L 1 。它由具有最小支持度的候选1-项集组成。
- 为发现频繁2-项集的集合 L2 L 2 ,算法使用 L1 L 1 L1 L 1 产生候选2-项集的集合 C2 C 2 。 C2 C 2 由 C2|L1|=|L1|∗|L1−1|2 C | L 1 | 2 = | L 1 | ∗ | L 1 − 1 | 2 个2-项集组成。
- 下一步,扫描D中事务,计算 C2 C 2 中每个候选项集的支持计数,如图6.3的第二行的中间表所示。
- 确定频繁2-项集的集合
L2
L
2
,它由具有最小支持度的
C2
C
2
中的候选2-项集组成。
图6.3 候选项集和频繁项集的产生,最小支持计数为2
| 1.连接:C3=L2 L2={{I1,I2},{I1,I3},{I1,I5},{I2,I3},{I2,I4},{I2,I5}}{{I1,I2},{I1,I3},{I1,I5},{I2,I3},{I2,I4},{I2,I5}} = {{I1,I2,I3},{I1,I2,I5},{I1,I3,I5},{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}} |
| 2.使用Apriori性质剪枝:频繁项集的所有子集必须是频繁的。存在候选项集,其子集不是频繁的吗? |
| {I1,I2,I3}的2-项子集是{I1,I2},{I1,I3}和{I2,I3}。{I1,I2,I3}的所有2-项子集都是L2的元素。因此,保留{I1,I2,I3}在C3中。 |
| {I1,I2,I5}的2-项子集是{I1,I2},{I1,I5}和{I2,I5}。{I1,I2,I5}的所有2-项子集都是L2的元素。因此,保留{I1,I2,I5}在C3中。 |
| {I1,I3,I5}的2-项子集是{I1,I3},{I1,I5}和{I3,I5}。{I3,I5}不是L2的元素,因而不是频繁的。这样,由C3中删除{I1,I3,I5}。 |
| {I2,I3,I4}的2-项子集是{I2,I3},{I2,I4}和{I3,I4}。{I3,I4}不是L2的元素,因而不是频繁的。这样,由C3中删除{I2,I3,I4}。 |
| {I2,I3,I5}的2-项子集是{I2,I3},{I2,I5}和{I3,I5}。{I3,I5}不是L2的元素,因而不是频繁的。这样,由C3中删除{I2,I3,I5}。 |
| {I2,I4,I5}的2-项子集是{I2,I4},{I2,I5}和{I4,I5}。{I4,I5}不是L2的元素,因而不是频繁的。这样,由C3中删除{I2,I3,I5}。 |
| 这样,剪枝后C3 = {{I1,I2,I3},{I1,I2,I5}}。 |
- 候选3-项集的集合C3的产生详细地列在图6.4中。首先,令
C3=L2 L2={{I1,I2,I3},{I1,I2,I5},{I1,I3,I5},{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}} C 3 = L 2 L 2 = { { I 1 , I 2 , I 3 } , { I 1 , I 2 , I 5 } , { I 1 , I 3 , I 5 } , { I 2 , I 3 , I 4 } , { I 2 , I 3 , I 5 } , { I 2 , I 4 , I 5 } }
根据Apriori性质,频繁项集的所有子集必须是频繁的,我们可以确定后4个候选不可能是频繁的。因此,我们把它们由C3删除,这样,在此后扫描D确定L3时就不必再求它们的计数值。注意,Apriori算法使用逐层搜索技术,给定k-项集,我们只需要检查它们的(k-1)-子集是否频繁。 - 扫描D中事务,以确定 L3 L 3 ,它由具有最小支持度的 C3 C 3 中的候选3-项集组成(图6.3)。
- 算法使用 L3 L3 L 3 L 3 产生候选4-项集的集合 C4 C 4 。尽管连接产生结果 {{I1,I2,I3,I5}} { { I 1 , I 2 , I 3 , I 5 } } ,这个项集被剪去,因为它的子集 {I1,I3,I5} { I 1 , I 3 , I 5 } 不是频繁的。这样, C4=∅ C 4 = ∅ ,因此算法终止,找出了所有的频繁项集。
图6.5给出Apriori算法和它的相关过程的伪代码。Apriori的第1步找出频繁1-项集的集合 L1 L 1 。在2-10步, Lk−1 L k − 1 用于产生候选 Ck C k ,以找出 Lk L k 。Apriori_gen过程产生候选,然后使用Apriori性质删除那些具有非频繁子集的候选(步骤3)。该过程在下面描述。一旦产生了所有的候选,就扫描数据库(步骤4)。对于每个事务,使用subset函数找出事务中是候选的所有子集(步骤5),并对每个这样的候选累加计数(步骤6和7)。最后,所有满足最小支持度的候选形成频繁项集L。然后,调用一个过程,由频繁项集产生关联规则。该过程在6.2.2小节介绍。
算法6.2.1 (Apriori) 使用逐层迭代找出频繁项集
输入:事务数据库D;最小支持度阈值。
输出:D中的频繁项集L。
方法:
1)L1 = find_frequent_1_itemsets(D);
2)for (k = 2; Lk-1 ≠∅; k++) {
3)Ck = aproiri_gen(Lk-1,min_sup);
4)for each transaction t∈D{ //scan D for count
5)Ct = subset(Ck,t); //get subsets of t that are candidates
6)for each candidate c∈Ct
7)c.count++;
8)}
9)Lk={c∈Ck | c.count ≥ min_sup}
10)}
11)return L = ∪kLk;
procedure apriori_gen(Lk-1: frequent (k-1)-itemset; min_sup: support)
1)for each itemset l1∈Lk-1
2)for each itemset l2∈Lk-1
3)if (l1[1]=l2[1])∧...∧(l1[k-2]=l2[k-2])∧(l1[k-1]<l2[k-2]) then {
4)c = l1l2; //join step: generate candidates
5)if has_infrequent_subset(c,Lk-1) then
6)delete c; // prune step: remove unfrequent cadidate
7)else add c to Ck;
8)}
9)return Ck;
procedure has_infrequent_subset(c:candidate k-itemset; L k-1:frequent (k-1)-itemset)
// use priori knowledge
1)for each (k-1)-subset s of c
2)if c∉Lk-1 then
3)return TRUE;
4)return FALSE;
如上所述,Apriori_gen做两个动作:连接和剪枝。在连接部分,
Lk−1
L
k
−
1
与
Lk−1
L
k
−
1
连接产生可能的候选(步骤1-4)。剪枝部分(步骤5-7)使用Apriori性质删除具有非频繁子集的候选。非频繁子集的测试在过程has_infrequent_subset中。
由频繁项集产生关联规则
一旦由数据库D中的事务找出频繁项集,由它们产生强关联规则是直接了当的(强关联规则满足最小支持度和最小置信度)。对于置信度,可以用下式,其中条件概率用项集支持度计数表示。
其中, support_count(A∪B) s u p p o r t _ c o u n t ( A ∪ B ) 是包含项集 A∪B A ∪ B 的事务数, support_count(A) s u p p o r t _ c o u n t ( A ) 是包含项集A的事务数。根据该式,关联规则可以产生如下:
- 对于每个频繁项集l,产生l的所有非空子集。
- 对于l的每个非空子集s,如果 support_count(l)support_count(s)≥min_conf s u p p o r t _ c o u n t ( l ) s u p p o r t _ c o u n t ( s ) ≥ m i n _ c o n f ,则输出规则“s ⇒ (l-s)”。其中,min_conf是最小置信度阈值。
由于规则由频繁项集产生,每个规则都自动满足最小支持度。频繁项集连同它们的支持度预先存放在hash表中,使得它们可以快速被访问。
例6.2 让我们试一个例子,它基于图6.2中 AllElectronics事务数据库。假定数据包含频繁项集 l={I1,I2,I5} l = { I 1 , I 2 , I 5 } ,可以由l产生哪些关联规则?l的非空子集有 {I1,I2},{I1,I5},{I2,I5},{I1},{I2} { I 1 , I 2 } , { I 1 , I 5 } , { I 2 , I 5 } , { I 1 } , { I 2 } 和 {I5} { I 5 } 。结果关联规则如下,每个都列出置信度。
| I1,I2⇒I5 I 1 , I 2 ⇒ I 5 , | confidence = 2/4 = 50% |
|---|---|
| I1,I5⇒I2 I 1 , I 5 ⇒ I 2 , | confidence = 2/2 = 100% |
| I2,I5⇒I1 I 2 , I 5 ⇒ I 1 , | confidence = 2/2 = 100% |
| I1⇒I2,I5 I 1 ⇒ I 2 , I 5 , | confidence = 2/6 = 33% |
| I2⇒I1,I5 I 2 ⇒ I 1 , I 5 , | confidence = 2/7 = 29% |
| I5⇒I1,I2 I 5 ⇒ I 1 , I 2 , | confidence = 2/2 = 100% |
如果最小置信度阈值为70%,则只有2、3和最后一个规则可以输出,因为只有这些是强的。
Apriori算法的python实现
来源:https://blog.csdn.net/o1101574955/article/details/51586351
还未校验,先放在这里
也可参考:
Apriori算法介绍(Python实现)
Apriori 算法python实现
#coding=utf8
#python3.5
#http://www.cnblogs.com/90zeng/p/apriori.html
def loadDataSet():
'''创建一个用于测试的简单的数据集'''
return [ [ 1, 3, 4,5 ], [ 2, 3, 5 ], [ 1, 2, 3,4, 5 ], [ 2,3,4, 5 ] ]
def createC1( dataSet ):
'''
构建初始候选项集的列表,即所有候选项集只包含一个元素,
C1是大小为1的所有候选项集的集合
'''
C1 = []
for transaction in dataSet:
for item in transaction:
if [ item ] not in C1:
C1.append( [ item ] )
C1.sort()
#return map( frozenset, C1 )
#return [var for var in map(frozenset,C1)]
return [frozenset(var) for var in C1]
def scanD( D, Ck, minSupport ):
'''
计算Ck中的项集在数据集合D(记录或者transactions)中的支持度,
返回满足最小支持度的项集的集合,和所有项集支持度信息的字典。
'''
ssCnt = {}
for tid in D: # 对于每一条transaction
for can in Ck: # 对于每一个候选项集can,检查是否是transaction的一部分 # 即该候选can是否得到transaction的支持
if can.issubset( tid ):
ssCnt[ can ] = ssCnt.get( can, 0) + 1
numItems = float( len( D ) )
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[ key ] / numItems # 每个项集的支持度
if support >= minSupport: # 将满足最小支持度的项集,加入retList
retList.insert( 0, key )
supportData[ key ] = support # 汇总支持度数据
return retList, supportData
def aprioriGen( Lk, k ): # Aprior算法
'''
由初始候选项集的集合Lk生成新的生成候选项集,
k表示生成的新项集中所含有的元素个数
'''
retList = []
lenLk = len( Lk )
for i in range( lenLk ):
for j in range( i + 1, lenLk ):
L1 = list( Lk[ i ] )[ : k - 2 ];
L2 = list( Lk[ j ] )[ : k - 2 ];
L1.sort();L2.sort()
if L1 == L2:
retList.append( Lk[ i ] | Lk[ j ] )
return retList
def apriori( dataSet, minSupport = 0.5 ):
C1 = createC1( dataSet ) # 构建初始候选项集C1
#D = map( set, dataSet ) # 将dataSet集合化,以满足scanD的格式要求
#D=[var for var in map(set,dataSet)]
D=[set(var) for var in dataSet]
L1, suppData = scanD( D, C1, minSupport ) # 构建初始的频繁项集,即所有项集只有一个元素
L = [ L1 ] # 最初的L1中的每个项集含有一个元素,新生成的
k = 2 # 项集应该含有2个元素,所以 k=2
while ( len( L[ k - 2 ] ) > 0 ):
Ck = aprioriGen( L[ k - 2 ], k )
Lk, supK = scanD( D, Ck, minSupport )
suppData.update( supK ) # 将新的项集的支持度数据加入原来的总支持度字典中
L.append( Lk ) # 将符合最小支持度要求的项集加入L
k += 1 # 新生成的项集中的元素个数应不断增加
return L, suppData # 返回所有满足条件的频繁项集的列表,和所有候选项集的支持度信息
def calcConf( freqSet, H, supportData, brl, minConf=0.7 ): # 规则生成与评价
'''
计算规则的可信度,返回满足最小可信度的规则。
freqSet(frozenset):频繁项集
H(frozenset):频繁项集中所有的元素
supportData(dic):频繁项集中所有元素的支持度
brl(tuple):满足可信度条件的关联规则
minConf(float):最小可信度
'''
prunedH = []
for conseq in H:
conf = supportData[ freqSet ] / supportData[ freqSet - conseq ]
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append( ( freqSet - conseq, conseq, conf ) )
prunedH.append( conseq )
return prunedH
def rulesFromConseq( freqSet, H, supportData, brl, minConf=0.7 ):
'''
对频繁项集中元素超过2的项集进行合并。
freqSet(frozenset):频繁项集
H(frozenset):频繁项集中的所有元素,即可以出现在规则右部的元素
supportData(dict):所有项集的支持度信息
brl(tuple):生成的规则
'''
m = len( H[ 0 ] )
if len( freqSet ) > m + 1: # 查看频繁项集是否足够大,以到于移除大小为 m的子集,否则继续生成m+1大小的频繁项集
Hmp1 = aprioriGen( H, m + 1 )
Hmp1 = calcConf( freqSet, Hmp1, supportData, brl, minConf ) #对于新生成的m+1大小的频繁项集,计算新生成的关联规则的右则的集合
if len( Hmp1 ) > 1: # 如果不止一条规则满足要求(新生成的关联规则的右则的集合的大小大于1),进一步递归合并,
#这样做的结果就是会有“[1|多]->多”(右边只会是“多”,因为合并的本质是频繁子项集变大,
#而calcConf函数的关联结果的右侧就是频繁子项集)的关联结果
rulesFromConseq( freqSet, Hmp1, supportData, brl, minConf )
def generateRules( L, supportData, minConf=0.7 ):
'''
根据频繁项集和最小可信度生成规则。
L(list):存储频繁项集
supportData(dict):存储着所有项集(不仅仅是频繁项集)的支持度
minConf(float):最小可信度
'''
bigRuleList = []
for i in range( 1, len( L ) ):
for freqSet in L[ i ]: # 对于每一个频繁项集的集合freqSet
H1 = [ frozenset( [ item ] ) for item in freqSet ]
if i > 1:# 如果频繁项集中的元素个数大于2,需要进一步合并,这样做的结果就是会有“[1|多]->多”(右边只会是“多”,
#因为合并的本质是频繁子项集变大,而calcConf函数的关联结果的右侧就是频繁子项集),的关联结果
rulesFromConseq( freqSet, H1, supportData, bigRuleList, minConf )
else:
calcConf( freqSet, H1, supportData, bigRuleList, minConf )
return bigRuleList
if __name__ == '__main__':
myDat = loadDataSet() # 导入数据集
#C1 = createC1( myDat ) # 构建第一个候选项集列表C1
#D = map( set, myDat ) # 构建集合表示的数据集 D,python3中的写法,或者下面那种
#D=[var for var in map(set,myDat)]
#D=[set(var) for var in myDat] #D: [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}]
#L, suppData = scanD( D, C1, 0.5 ) # 选择出支持度不小于0.5 的项集作为频繁项集
#print(u"频繁项集L:", L)
#print(u"所有候选项集的支持度信息:", suppData)
#print("myDat",myDat)
L, suppData = apriori( myDat, 0.5 ) # 选择频繁项集
print(u"频繁项集L:", L)
print(u"所有候选项集的支持度信息:", suppData)
rules = generateRules( L, suppData, minConf=0.7 )
print('rules:\n', rules)Apriori算法的并行实现
pyspark实现Apriori算法、循环迭代、并行处理
Aprior并行化算法在Spark上的实现
pyspark.ml.fpm module
提高Apriori的有效性
“怎样能够提高Apriori的有效性?”已经提出了许多Apriori算法的变形,旨在提高原算法的效率。其中一些变形列举如下。
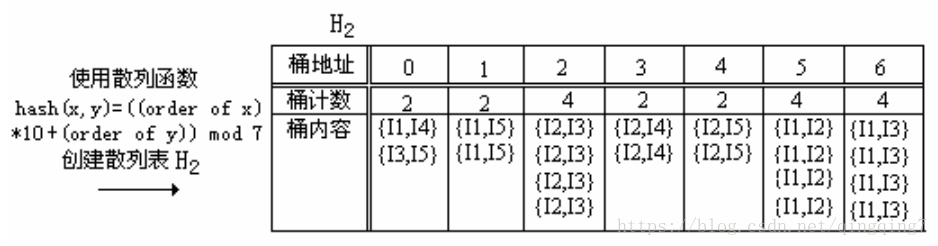
基于散列的技术(散列项集计数):一种基于散列的技术可以用于压缩候选k-项集 Ck(k>1) C k ( k > 1 ) 。例如,当扫描数据库中每个事务,由 C1 C 1 中的候选1-项集产生频繁1-项集 L1 L 1 时,我们可以对每个事务产生所有的2-项集,将它们散列(即,映射)到散列表结构的不同桶中,并增加对应的桶计数(图6.6)。在散列表中对应的桶计数低于支持度阈值的2-项集不可能是频繁2-项集,因而应当由候选项集中删除。这种基于散列的技术可以大大压缩要考察的k-项集(特别是当k = 2时)。
事务压缩(压缩进一步迭代扫描的事务数):不包含任何k-项集的事务不可能包含任何(k+1)-项集。这样,这种事务在其后的考虑时,可以加上标记或删除,因为为产生j-项集(j > k),扫描数据库时不再需要它们。
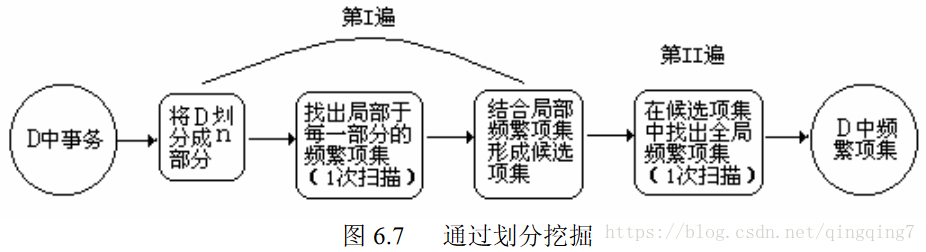
划分(为找候选项集划分数据):可以使用划分技术,它只需要两次数据库扫描,以挖掘频繁项集(图6.7)。它包含两遍。在第1遍,算法将D中的事务划分成n个非重叠的部分。如果D中事务的最小支持度阈值为
min_sup,则每个部分的最小支持度计数为
min_sup×该部分中事务数。对每一部分,找出该部分内的频繁项集。这些称作局部频繁项集。该过程使用一种特殊的数据结构,对于每个项集,记录包含项集中项的事务的TID。这使得对于
k = 1,2,..,找出所有的局部频繁k-项集只需要扫描一次数据库。
局部频繁项集可能不是整个数据库D的频繁项集。D的任何频繁项集必须作为局部频繁项集至少出现在一个部分中。这样,所有的局部频繁项集作为D的候选项集。所有部分的频繁项集的集合形成D的全局候选项集。在第II遍,第二次扫描D,评估每个候选的实际支持度,以确定全局频繁项集。每一部分的大小和划分的数目这样确定,使得每一部分能够放入内存,这样每遍只需要读一次。
选样(在给定数据的一个子集挖掘):选样方法的基本思想是:选取给定数据库D的随机样本S,然后,在S而不是在D中搜索频繁项集。用这种方法,我们牺牲了一些精度换取了有效性。样本S的大小这样选取,使得可以在内存搜索S中频繁项集;这样,总共只需要扫描一次S中的事务。由于我们搜索S中而不是D中的频繁项集,我们可能丢失一些全局频繁项集。为减少这种可能性,我们使用比最小支持度低的支持度阈值来找出局部于S的频繁项集(记作 LS L S )。然后,数据库的其余部分用于计算 LS L S 中每个项集的实际频繁度。有一种机制可以用来确定是否所有的频繁项集都包含在 LS L S 中。如果 LS L S 实际包含了D中的所有频繁项集,只需要扫描一次D。否则,可以做第二次扫描,以找出在第一次扫描时遗漏的频繁项集。当效率最为重要时,如计算密集的应用必须在不同的数据上运行时,选样方法特别合适。
动态项集计数(在扫描的不同点添加候选项集):动态项集计数技术将数据库划分为标记开始点的块。不象Apriori仅在每次完整的数据库扫描之前确定新的候选,在这种变形中,可以在任何开始点添加新的候选项集。该技术动态地评估已被计数的所有项集的支持度,如果一个项集的所有子集已被确定为频繁的,则添加它作为新的候选。结果算法需要的数据库扫描比Apriori少。
其它变形涉及多层和多维关联规则挖掘,在本章的其余部分讨论。涉及空间数据、时间序列数据和多媒体数据的关联挖掘在第 9 章讨论。
不产生候选挖掘频繁项集
正如我们已经看到的,在许多情况下,Apriori 的候选产生-检查方法大幅度压缩了候选项集的大小,并导致很好的性能。然而,它有两种开销可能并非微不足道的。














 4001
4001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









