







目录
本节讲解伙伴系统,即buddy。
3.5 物理内存的管理
系统初始化完毕后,bootmem分配器停用,伙伴系统运行并负责内存分配。
伙伴系统,即buddy。
特点:速率快,效率高。
3.5.1 伙伴系统的结构
内存按4K大小分为一个物理页,每个页对应一个struct page实例。
每个内存区zone都管理着一个伙伴系统数据,如:
struct zone {
struct free_area free_area[MAX_ORDER];
}
阶:即order,分配内存页的数量。
最大阶为MAX_ORDER,值为11。所以最多可分配2^11 * 4K=8M。
每个zone的每个分配阶都有一个该实例
struct free_area free_area {
struct list_head free_list[MIGRATE_TYPES];
链表,连接该阶的所有空闲页,并按迁移属性放在不同链表。
unsigned long nr_free;
该阶大小的空闲页有多少
}
页按迁移类型分类,作用是减少内存碎片
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_TYPES
};
所以可实现,举例:
1. 分配一个8K(order=3)的可迁移页。
2. 分配一个4K(order=2)的不可迁移页。


查看每个node的每个zone,不同order大小剩余空闲页数量
# cat /proc/buddyinfo
Node 0, zone Normal 50 52 39 16 4 1 1 1 1 1 2 12
3.5.2 避免碎片
一个普通页大小为4K,一个巨型页 (Huge Page)大小可为4M。
巨型页
优点:
内存使用密集的应用程序,使用巨型页,可减少TLB表项,减少TLB cache miss。
缺点:
要求有大块连续空闲物理内存。
所以需要尽量减少内存碎片。
防止碎片的方法:
anti-fragmentation反碎片,即从一开始就尽量避免碎片。
反碎片原理:
内核将页划分三类:
1. 不可移动页:
该页不可移动。如内核核心代码、设备映射、DMA缓冲区。
2. 可移动页:
该页可移动。如应用程序使用的页,可修改页表来实现。
3. 可回收页:
不能移动,但可删除,如文件缓存页,tmpfs文件系统页,slab缓存页。
内存回收方式:
1. kswapd:内核kswapd进程周期回收频繁访问的页。
2. 直接回收:分配内存失败时直接回收,再尝试分配。
如果不可移动页位于可移动页中间,内核将无法分配较大连续内存。
所以将页按迁移类型组织在不同链表。如PCP(冷热页)和伙伴系统都是如此。
struct free_area free_area {
struct list_head free_list[MIGRATE_TYPES];
//用于连接该阶大小的空闲页,并按迁移属性不同链表。
unsigned long nr_free;
//该阶大小的空闲页有多少。
}
#define for_each_migratetype_order(order, type) \
for (order = 0; order < MAX_ORDER; order++) \
for (type = 0; type < MIGRATE_TYPES; type++)
遍历可分配指定阶的所有迁移类型。
如果指定迁移类型的空闲内存无法满足分配请求。可依次尝试从备用列表中的其他迁移类型分配。
备用列表如下:
int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },
[MIGRATE_RESERVE] = { MIGRATE_RESERVE },
};
如RECLAIMABLE页不够时,可依次尝试UNMOVABLE,MOVABLE,RESERVE类型页。
如果某体系结构的HUGETLB_PAGE_ORDER为10,则它的巨型页大小为4MB。
分配内存时,将分配掩码gfp_flags,转换为内存迁移类型。
int migratetype = allocflags_to_migratetype(gfp_t gfp_flags);
返回值可作zone->free_area->free_list[migratetype]数组索引,来分配内存
释放内存时,需要将页放回对应迁移链表中。
查看不同迁移类型的不同阶的页使用情况
# cat /proc/pagetypeinfo
Page block order: 11 巨型页的order
Pages per block: 2048 一个巨型页包含页数
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 11
Node 0, zone Normal, type Unmovable 19 17 10 3 0 1 0 0 0 1 1 0
Node 0, zone Normal, type Reclaimable 0 0 0 0 0 0 1 0 1 1 1 0
Node 0, zone Normal, type Movable 134 53 27 5 1 1 2 1 0 1 1 11
Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 0 1
void set_pageblock_migratetype(struct page *page, int migratetype);
设置page为首的巨型页的迁移类型。
内存子系统初始化时,将所有页设置为可移动页,这样即使分配不可移动页也可从可移动页中分配。
启动期间很少分配可移动页,因为大部分为内核核心使用,使用不可移动页更好。
防止内存碎片方法:
1. 根据可移动性组织内存页(前面所讲)
2. 新增虚拟内存域ZONE_MOVABLE(下面将讲)
ZONE_MOVABLE:
即虚拟可移动内存域。
原理:
可用物理内存划分为两个内存域zone:可移动,不可移动。
如何启用ZONE_MOVABLE?
使用如下两个内核参数kernelcore或movablecore
1. kernelcore:
指定不可移动内存页数目,既不能回收也不能迁移。
剩余内存是可移动。
2. movablecore:
指定可移动内存页数目。
剩余是不可移动。
enum zone_type {
ZONE_DMA,
ZONE_NORMAL,
ZONE_HIGHMEM,
ZONE_MOVABLE,
}
ZONE_MOVABLE是一个虚拟的内存区域,内存通常来自NORMAL或HIGHMEM内存域。
find_zone_movable_pfns_for_nodes函数:
作用:计算ZONE_MOVEABLE域中内存数量。
如果cmdline中没有指定kernelcore或movablecore参数,则ZONE_MOVABLE为空。
分配ZONE_MOVABLE域的页须指定分配标志:
__GFP_HIGHMEM和__GFP_MOVABLE
3.5.3 初始化内存域和节点
pfn=page frame number,物理页帧号。
体系架构的初始化中进行:
计算各个内存域的页帧边界。
计算各节点页帧分配情况。
并将上述信息传给内存子系统free_area_init_nodes函数。
free_area_init_nodes函数的工作:
设置各个内存域页帧范围,包括ZONE_MOVABLE虚拟域。
调用free_area_init_node。遍历节点,建立节点的数据结构pg_data_t。
free_area_init_node:
calculate_node_totalpages:
统计该节点的页总数,各个内存域页数。
alloc_node_mem_map:
为该节点所有页创建struct page实例。并保存在pgdat->node_mem_map指针中。
free_are_init_core:
初始化该内存域的per-CPU缓存,即PCP冷热页。
初始化伙伴系统的free_area。
内核全局变量:
nr_all_pages:所有页数,还包括高端内存页。
nr_kernel_pages:所有一致映射页(不含高端内存页)
3.5.4 分配器API
伙伴系统:只能分配2的整数幂个整页,即分配阶oder。
slab:按size字节的细粒度分配。
slab基于伙伴系统实现。slab从伙伴系统按页分配后,又按字节对外提供内存。
如kmalloc。kmalloc基于slab。
vmalloc不基于slab。
分配掩码
gfp:get free page
一个分配掩码(gfp_t)的不同位包含不同信息。可分为两类:
1. 内存域修饰符:
__GFP_DMA:
从ZONE_DMA分配内存。
__GFP_HIGHMEM:
如果ZONE_HIGHMEM无法满足分配,也可尝试ZONE_NORMAL和ZONE_DMA域
__GFP_MOVABLE:
2. 操作修饰符:
__GFP_IO 分配过程可IO操作,换出页
__GFP_NOFAIL 一直尝试,直到成功
__GFP_REPEAT 若失败,尝试若干次后停止
__GFP_ZERO 分配页后填充为0
__GFP_COLD 分配冷页,即不在CPU缓存的页
__GFP_WAIT 分配期间可中断
__GFP_HIGH 分配请求非常重要,失败可能系统奔溃
__GFP_RECLAIMABLE 分配可回收的页
__GFP_MOVABLE 分配可移动的页
__GFP_THISNODE NUMA中,不允许从其他节点分配
上面两类标志需要组合使用。常见组合有:
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
GFP_KERNEL:内核代码最常用
给用户空间分配可用:__GFP_MOVABLE
可文件页分配可用:__GFP_RECLAIMABLE
内存分配宏
按返回page还是地址分为两类
1. 返回struct page:
alloc_pages(gfp_mask, order);
分配多个页。
若order=0则分配单页,此时等于alloc_page(gfp_mask)
2. 返回虚拟地址:
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask, order);
return (unsigned long) page_address(page); 将page转换为虚拟地址
}
释放页
free_page(addr)

virt_to_page:将虚拟地址转为为struct page指针。
3.5.5 分配页

所有分配函数都调用alloc_pages。
alloc_pages -> alloc_pages_node -> __alloc_pages -> __alloc_pages_nodemask
本节讲解__alloc_pages_nodemask,即伙伴系统中内存分配的核心函数。
关键词:分配标志 水位检测 快路径 慢路径
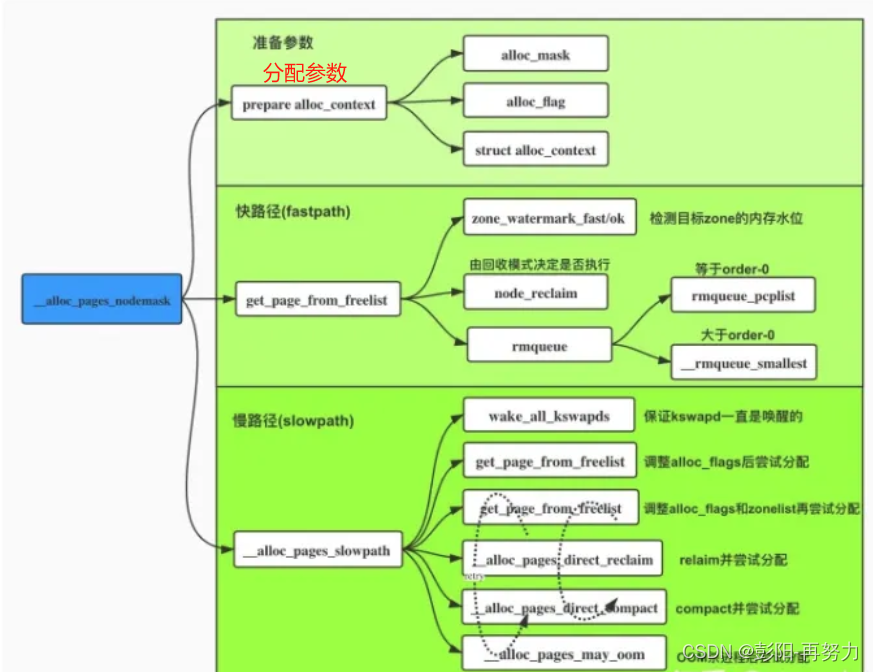
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
int migratetype = allocflags_to_migratetype(gfp_mask);
int alloc_flags = ALLOC_WMARK_LOW|ALLOC_CPUSET; 以low水位分配
开始快速路径分配(以low水位判断是否满足分配)
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, alloc_flags, preferred_zone, migratetype);
快速路径分配失败后,使用慢路径分配
if (unlikely(!page)) {
page = __alloc_pages_slowpath(gfp_mask, order,zonelist, high_zoneidx, nodemask, preferred_zone, migratetype);
}
}
分析:
1 准备工作
1.1 检查参数order是否小于MAX_ORDER。
1.2 int alloc_flags = ALLOC_WMARK_LOW|ALLOC_CPUSET;
先使用LOW水位尝试分配
1.3 准备migratetype,zonelist
migratetype:通过allocflags_to_migratetype()将gfp_mask转换为迁移类型。
zonelist链表:生成备用zonelist,按顺序尝试在zone内分配
2 快速路径分配(get_page_from_freelist):
struct page *get_page_from_freelist()
{
遍历zonelist,逐一尝试分配
for_each_zone_zonelist_nodemask(zone, z, zonelist, high_zoneidx, nodemask) {
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
检查水位,判断内存是否足够。
if (zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags)) {
goto try_this_zone;
}
page = buffered_rmqueue(preferred_zone, zone, order, gfp_mask, migratetype);
}
}struct page *buffered_rmqueue()
{
int cold = !!(gfp_flags & __GFP_COLD);
if (likely(order == 0)) { 单页会从PCP中分配
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list = &pcp->lists[migratetype];
pcp->count += rmqueue_bulk(zone, 0,pcp->batch, list,migratetype, cold);
if (cold)
page = list_entry(list->prev, struct page, lru); 分配冷页
else
page = list_entry(list->next, struct page, lru); 分配热页
list_del(&page->lru);
} else {
分配多页
page = __rmqueue(zone, order, migratetype);
}struct page *__rmqueue(struct zone *zone, unsigned int order, int migratetype)
{
struct page *page;
page = __rmqueue_smallest(zone, order, migratetype); 从伙伴系统中分配
if (unlikely(!page)) {
分配失败,则从fallbacks[MIGRATE_TYPES][4]其他可用迁移类型中分配
page = __rmqueue_fallback(zone, order, migratetype);
}
return page;
}struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype)
{ //从伙伴系统中分配
unsigned int current_order;
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,struct page, lru);
list_del(&page->lru);
expand(zone, page, order, current_order, area, migratetype);
将更高阶的内存分裂成小的order,继续尝试分配
举例:把1个8K页分为2个4K页。
return page;
}
return NULL;
}上述分配失败后,则使用慢路径分配。
3 慢路径分配:
主要任务:回收内存,以满足内存分配。
struct page *__alloc_pages_slowpath(gfp_t gfp_mask, int order,struct zonelist *zonelist,int migratetype)
{
restart:
wake_all_kswapd(order, zonelist, high_zoneidx); 唤醒kswapd进程
alloc_flags = gfp_to_alloc_flags(gfp_mask);
使用MIN水位(之前使用lOW水位分配失败)
page = get_page_from_freelist();函数和快速分配一样,使用的水位不一样。
if (!page)
__alloc_pages_direct_compact() 分配失败,进行内存规整
if (!page)
__alloc_pages_direct_reclaim() 分配失败,进行直接内存回收。
if (!page)
page = __alloc_pages_may_oom() 分配失败,执行oom来killer 某些进程
return page;
}小结:kswapd -> 内存规整compact -> 直接内存回收 -> oom
ALLOC_NO_WATERMARKS分配标志:用于紧急或关键代码的内存分配,此时不检查水位。
移除选择的页
buffered_rmqueue:
分配内存时,找到空闲页后,会从伙伴系统的free_lists中移除页。
内核优化:分配单页,不从伙伴系统获取,而是per-CPU缓存(PCP冷页热页)
有GFP_COLD标志:分配冷页,从PCP链表尾分配。
无GFP_COLD标志:分配热页,从PCP链表头分配。
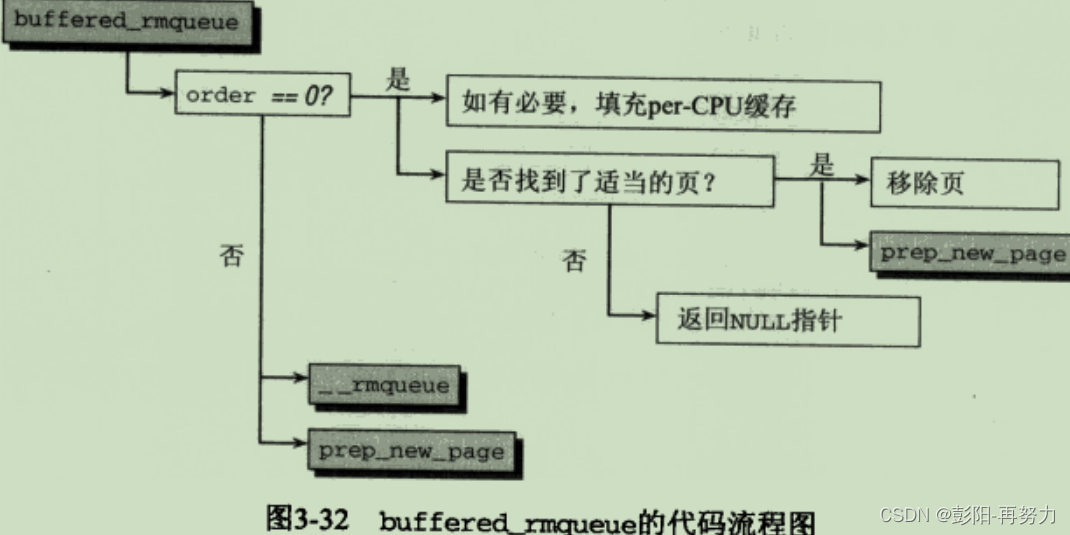
__rmqueue:进入伙伴系统核心。
找到可用内存页后,zone的free_area->nr_free-1,并删除page的PG_buddy标志,表示该页不在伙伴系统了。
复合页:
将一组连续的物理页组合成一个复合页。
复合页是实现大页(Huge Page)的基础。(DPDK需要大页机制)
分配标志:
__GFP_COMP
页标志PG_compound:
标识该页是复合页。复合页成员的所有page->private都指向首页。
作用:
减少页表项,降低TLB cache miss,提高性能。
page->private在不同子系统有不同作用,如:
网络驱动:可private存储sk_buff
文件系统:可private存储inode
3.5.6 释放页
void __free_pages(struct page *page, unsigned int order)

1. 如果释放单页,调用free_hot_cold_page(page, 0);
将页释放到per-CPU的PCP缓存页中对应迁移类型链表中。
如果per-CPU中页数大于pcp->high,将pcp->batch个内存页一起还给伙伴系统,惰性合并)。
2. 如果释放的不是单页,调用__free_one_page
将页释放到free_area->list伙伴系统中,并检测是否可以与相邻页合并为更高阶的free_area中,重复直到不能合并。
int page_is_buddy(struct page *page, struct page *buddy, unsigned int order)
查看page和buddy是否互为伙伴















 2319
2319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











