







本文仅为学习 Python 过程中的个人笔记,旨在记录学习过程,方便自我复习与参考。
声明:内容仅供个人学习使用,未用于任何商业目的。如需引用或传播,请注明来源。
原视频:Bilibili—韩顺平老师
代码获取:https://github.com/qingxuly/hsp_python_course
关注公众号软工星球,回复Python可免费获取PDF完整版。
Python 语言描述
Python 转义字符
- Python 常用的转义字符
| 转义字符 | 说明 |
|---|---|
\t | 制表符,实现对齐的功能 |
\n | 换行符, |
\\ | 一个\ |
\" | 一个 " |
\' | 一个’ |
\r | 一个回车 |
- 代码演示
# \t制表符
print("jack\t20")
# \n换行
print("Hello,jack\nhello,tom")
# \\输出\
print("D:\\Pycharm\\chapter02")
# \"输出" \'输出'
print("郭靖说:\"hello\"")
print("郭靖说:\'hello\'") # 单引号也可以不适用转义 \
# \r回车
print("嘻嘻哈哈, \r咚咚锵锵")
"""
输出如下文案
姓名 年龄 籍贯 住址
tom 12 河北 北京
"""
print("姓名\t年龄\t籍贯\t住址\ntom\t12\t河北\t北京")
注释(comment)
-
基本介绍
-
用于注解说明程序的文字就是注释。
- 被注释的语句,就不会再执行。
- 注释提高了代码的可读性。
- 注释是一个程序员必须要具有的良好编程习惯,将自己的思想通过注释先整理出来,再用代码去体现。
-
单行注释
# 这是一个注释 -
多行注释
- 格式:三个单引号 ‘’’ 注释文字 ‘’’ 或者 三个双引号 “” " 注释文字 " “”
""" print("hello world 4") print("hello world 5") print("hello world 6") """ ''' print("hello world 1") print("hello world 2") print("hello world 3") ''' -
文件编码声明注释
- 格式:# coding: 编码,在文件开头加上编码声明,用以指定文件的编码格式。
# coding:utf-8 -
使用细节
- 对于单行和多行的注释,被注释的文字,不会被解释器执行。
- 多行注释里面不要有多行注释嵌套,容易混淆。
# 错误演示 """ print("hello") """print("world")""" """
Python 代码规范
-
正确的注释和注释风格
- 使用多行注释来注释多行说明。
- 如果注释函数或者其中的某个步骤,使用单行注释。
-
正确的缩进和空白
- 使用一次 Tab 操作,实现缩进,默认整体向右移动,使用 Shift+Tab 整体向左移动。
- = 两边习惯各加一个空格比较规范。
- 变量之间使用逗号间隔比较清晰。
# 代码参考演示 def test_circular_linked_list() -> None: """ Test cases for the CircularLinkedList class. >>> test_circular_linked_list() """ circular_linked_list = CircularLinkedList() assert len(circular_linked_list) == 0 assert circular_linked_list.is_empty() is True assert str(circular_linked_list) == "" try: circular_linked_list.delete_front() raise AssertionError # This should not happen except IndexError: assert True # This should happen
Python 文档
-
使用说明:Python 语言提供了函数、模块、数值、字符串,也给出了相应的文档,用于告诉开发者如何使用。
-
演示:查看如何使用 Python 的内置函数
abs。
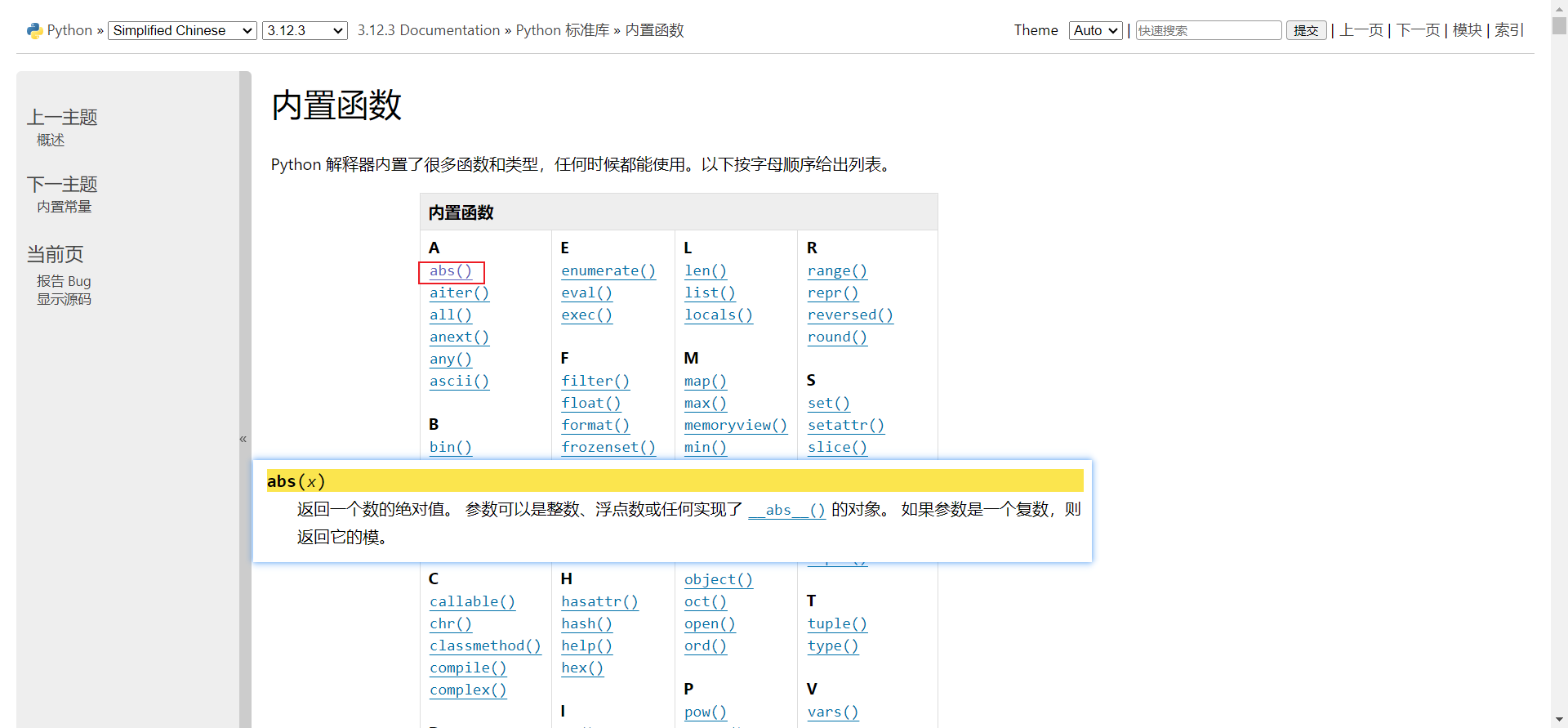
# 演示内置函数 abs 的使用
print("-100的绝对值", abs(-100))
print("-100.45的绝对值", abs(-100.45))
print("200的绝对值", abs(-200))
本章作业
- 环境变量 path 配置的作用是什么?
配置环境变量后,我们可以在任意目录去执行path指定的目录下的程序或指令,比如python.exe。
变量
为什么需要变量
- 一个程序就是一个世界
- 变量是程序的基本组成单位
- 不论是使用哪种高级程序语言编写程序,变量都是其程序的基本组成单位。
- 变量有三个基本要素(类型 + 名称 + 值)。
# 变量的实例
# 定义了一个变量,变量的名称是a,变量的值是1,1是int类型(整数类型)
a = 1
# 变量a的值修改为2,变量a的值是2,2是int类型
a = 2
# 输出变量的值
print("a的值是", a, "类型是", type(a))
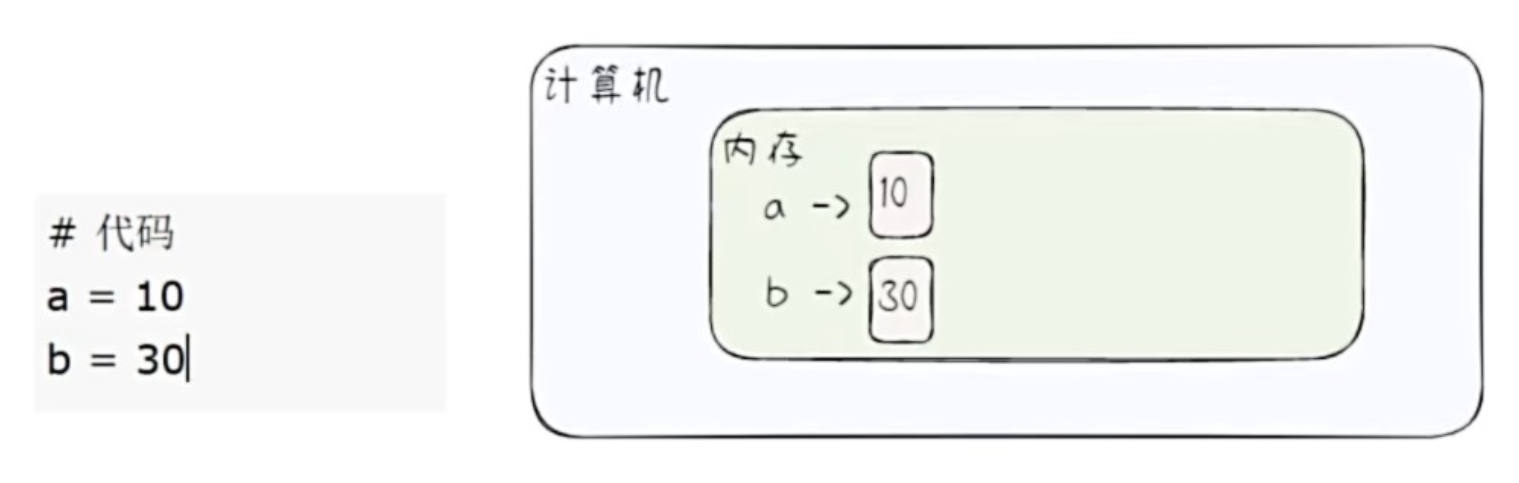
- 简单的原理示意图
- 当程序/代码执行后,变量的值是存在计算机内存的。
- 计算机内存介绍
- 内存(Memory)是计算机的重要部件,它用于暂时存放 CPU 中的运算数据,以及与硬盘等外部存储交换的数据。它是外存于 CPU 进行沟通的桥梁,计算机中所有程序的运行都在内存中进行。
变量的介绍
- 变量的概念
- 变量相当于内存中一个数据存储空间的表示。
- 你可以把变量看做是一个房间的门牌号,通过门牌号我看可以找到房间,而通过变量名可以访问到变量(值)。
- 变量的定义
- 定义变量:
a = 60。 - 使用:
print(a)。
- 定义变量:
- 注意:需要先定义变量,才能使用,否则会提示
not defined。 - 代码演示
# 变量使用的错误形式
# print(c)
# c = 10
变量快速入门
- 演示记录人的信息并输出的程序。
# 演示记录人的信息并输出的程序
name = "tom" # 字符串
age = 20 # 整形
score = 90.4 # 浮点型(小数)
gender = "男" # 字符串
# 输出信息
print("个人信息如下:")
print(name)
print(age)
print(score)
print(gender)
# 输出信息
print("个人信息如下:", name, age, score, gender)
格式化输出
- %操作符
- 在 Python 中,使用
%操作符进行格式化输出时,需要在字符串中使用占位符来表示需要替换的值。占位符由一个百分号%和一个格式说明符组成,格式说明符用于指定变量的类型和格式。 - 除了基本的占位符外,还可以使用一些修饰符来控制输出格式。例如,我们可以使用
:来指定宽度和对齐方式,使用.来指定小数点后的位数等。
| %操作符 | 说明 | 备注 |
|---|---|---|
| %s | 输出字符串 | |
| %d | 输出整数 | %03d 表示宽度为 3,右对齐,不足的部分用 0 填充 |
| %f | 输出浮点数 | %.2f 表示小数点后保留两位有效数字 |
| %% | 输出% |
# 定义变量
age = 80
score = 77.5
gender = '男'
name = "贾宝玉"
# %操作符输出
print("个人信息:%s %d %.1f %s" % (name, age, score, gender))
- format()函数
- 除了使用
%操作符进行格式化输出外,Python 还提供了format()函数来进行字符串格式化。format()函数通过花括号{}作为占位符,并通过位置、关键字或属性来指定替换的值。
# format()函数
print("个人信息:{} {} {} {}".format(name, age, score, gender))
- f-strings [推荐]
- f-strings 是 Python 3.6 及更高版本中引入的一种新的字符串格式化方法。它们使用花括号 {} 包围变量名或表达式,并在字符串前加上字母 “f” 或 “F”。在花括号内,可以直接插入变量名或表达式,而不需要使用占位符和格式说明符。这使得字符串格式化更加简洁和易读。
# f-strings
print(f"个人信息:{name} {age} {score} {gender}")
程序中 +号的使用
- 当左右两边都是数值型时,则做加法运算。
- 当左右两边都是字符串,则做拼接运算。
# +号的使用案例
name = "king"
score = 50.8
print(score + 90) # 140.8
print(name + "hi") # kinghi
print("100" + "98") # 10098
print(34.5 + 100) # 134.5
# print("100" + 100) # TypeError: can only concatenate str (not "int") to str
数据类型
基本数据类型
- 基本数据类型
| 类型 | 描述 |
|---|---|
| 整型 int | 整数:如 1, -1, 200 |
| 浮点型 float | 小数:如 1.1, -4.5, 900.9 |
| 布尔值 bool | 布尔值就是我们常说的逻辑,可以理解为对(True)或错(False) |
| 字符串 (string) | 字符串就是字符组成的一串内容,python 中用成对的单引号或双引号括起来,如“hello world” |
-
基本介绍
- Python 中的变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
- 我们所说的“类型”是变量所指的内存数据的类型。
-
案例说明:
a = 100- a 是变量,它是没有类型的。
- a 变量指向的/代表的数据 100 是有类型的。
- 100 有些地方也称为
字面量。
-
type()函数查看数据类型。
-
-
语法:type(object)。
-
object 就是你要查看类型的数据,可以是一个具体的数据(即:字面量),也可以是变量(也就是查看该变量指向的数据的类型)。
-
# 演示type() 使用
age = 80
score = 77.5
gender = '男'
name = "贾宝玉"
is_pass = True
# 查看变量的类型(本质是查看变量指向的数据的类型)
print(type(age))
print(type(score))
print(type(gender))
print(type(name))
print(type(is_pass))
# type() 可以直接查看具体的值(字面量) 的类型
print(f"hello 的类型是{type('hello')}")
print(f"1.1 的类型是{type(1.1)}")
整数类型
基本介绍
- Python 整数就是用于存放整数值的,比如:12,30,3456,-1。
整数使用的使用细节
- Python 中的整型,可以表示很大的数(官方:the limit (4300 digits) for integer)。
# 讲解int类型的细节
import sys
n3 = 9 ** 8888
# print(n3) # ValueError: Exceeds the limit (4300 digits) for integer string conversion;
# use sys.set_int_max_str_digits() to increase the limit
sys.set_int_max_str_digits(0) # maxdigits must be 0 or larger than 640
print(n3)
- Python 的整数有十进制、十六进制、八进制、二进制
- 十进制就是我们最常见的写法,比如:1,66,123。
- 十六进制写法:加前缀 0x,由 0-9 和 A-F 的数字和字母结合。
- 八进制写法:加前缀 0o,由 0-7 数字组合。
- 二进制写法:加前缀 0b,只有 0 和 1 数字结合。
- 运行时,会自动转化为十进制输出。
print(10) # 十进制
print(0x10) # 十六进制
print(0o10) # 八进制
print(0b10) # 二进制
字节(byte):计算机中基本存储单元
位(bit):计算机中的最小存储单位
1 byte = 8 bit
- 字节数是随着数字增大而增大(即:Python 整型是变长的)。
- 每次的增量是 4 个字节。
n1 = 0
n2 = 1
n3 = 2
n4 = 2 ** 15
n5 = 2 ** 30
n6 = 2 ** 128
# 在Python中,可以通过sys.getsizeof 返回对象(数据)的大小(按照字节单位返回)
print(n1, sys.getsizeof(n1), "类型", type(n1))
print(n2, sys.getsizeof(n2), "类型", type(n2))
print(n3, sys.getsizeof(n3), "类型", type(n3))
print(n4, sys.getsizeof(n4), "类型", type(n4))
print(n5, sys.getsizeof(n5), "类型", type(n5))
print(n6, sys.getsizeof(n6), "类型", type(n6))
print(sys.getsizeof(10)) # 28个字节
浮点类型
基本介绍
- Python 的浮点类型可以表示一个小数,比如:123.4,7.8,-0.12。
浮点型使用细节
- 浮点数表示形式如下
- 十进制数形式,如:5.12,.512(必须有小数点)。
- 科学计数法形式,如:5.12e,5.12e-2。
- 浮点数有大小限制 边界值为:
- max = 1.7976931348623157e+308。
- min = 2.2250738585072014e-308。
- 浮点类型计算后,存在精度的缺失,可以使用 Decimal 类进行精确计算。
import sys
n3 = 5.12
n4 = .512
print("n4 = ", n4)
n5 = 5.12e2 # 5.12乘以10的2次方
print("n5 = ", n5)
n6 = 5.12e-2 # 5.12除以10的2次方
print("n6 = ", n6)
# float_info 是一个具名元组,存有浮点型的相关信息
print(sys.float_info.max)
print(sys.float_info.min)
# 浮点类型计算后,存在精度的缺失,可以使用 Decimal 类进行精确计算
# 1. 为了避免浮点数的精度问题,可以使用Decimal类进行精确计算
# 2. 如果使用Decimal类,需要导入Decimal类
# b = 8.1 / 3 # b = 2.6999999999999997
from decimal import Decimal
b = Decimal("8.1") / Decimal("3")
print("b = ", b) # b = 2.7
布尔类型 bool
基本介绍
- 布尔类型也叫 bool 类型,取值 True 和 False。
- True 和 False 都是关键字,表示布尔值。
- bool 类型适用于逻辑运算,一般用于程序流程控制:条件控制语句、循环控制语句。
- 比如判断某个条件是否成立,或者在某个条件满足时执行某些代码。
布尔类型使用细节
- 布尔类型只有 2 个值:True 和 False。
- 布尔类型可以和其他数据类型进行比较,比如数字、字符串等。在比较时,Python 会将 True 视为 1,False 视为 0。
- 在 Python 中,非 0 被视为真值,0 被视为假值。
# bool类型的基本使用‘
num1 = 100
num2 = 200
if num1 > num2:
print("num1 > num2")
if num1 < num2:
print("num1 < num2")
# 表示把 num1 > num2 的结果赋给result变量
result = num1 > num2
print("result =", result)
# 查看result的类型
print("result的类型:", type(result))
print(type(1 > -1))
# 布尔类型可以和其他数据类型进行比较,比如数字、字符串等。在比较时,Python会将True视为1,False视为0。
b1 = False
b2 = True
print(b1 + 10)
print(b2 + 10)
# b1 = 0:表示赋值,把0赋给b1
# b1 == 0:表示判断b1是否和0相等
if b1 == 0:
print("ok")
if b2 == 1:
print("Hi")
# 在Python中,非0被视为真值,0被视为假值
if 0:
print("哈哈")
if -1:
print("嘻嘻")
if 1.1:
print("呵呵")
if "哈哈":
print("啧啧")
if None:
print("滴滴")
字符串 str
基本介绍
- 字符串是 Python 中很常用的数据类型,通俗来说,字符串就是字符组成的一串内容。
- 使用引号
'或"包括起来,创建字符串。 - str 就是 string 的缩写,在使用 type() 查看数据类型时,字符串类型显示的是 str。
- 通过加号可以连接字符串。
字符串使用注意事项
- Python 中不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
- 用三个单引号
'''内容'''或三个双引号"""内容"""可以使字符串内容保持原样输出,在输出格式复杂的内容是比较有用的。 - 在字符串前面加
r可以使整个字符串不会被转义。
# 字符串使用注意事项
# 使用引号`'`或`"`包括起来,创建字符串
str1 = "tom说:\"hello\""
str2 = 'jack说:"hello"'
print(str1)
print(str2)
print(f"st2的类型:{type(str2)}")
# 通过加号可以连接字符串
print("hi" + " tom")
# Python中不支持单字符类型,单字符在Python中也是作为一个字符串使用
str3 = "A"
print("str3类型", type(str3))
# 用三个单引号'''内容'''或三个双引号"""内容"""可以使字符串内容保持原样输出,在输出格式复杂的内容是比较有用的。
content = """ Hi,我是你的百度翻译AI助手,我可以提供一站式翻译服务,'''f''
目前仅支持中文和英语,其它语种正在努力学习中;
所有内容均由AI提供,仅供参考,如有错误请反馈,我们将持续改进!"""
print(content)
# 在字符串前面加`r`可以使整个字符串不会被转义
str4 = "jack\ntom\tking"
print(str4)
str5 = r"jack\ntom\tking"
print(str5)
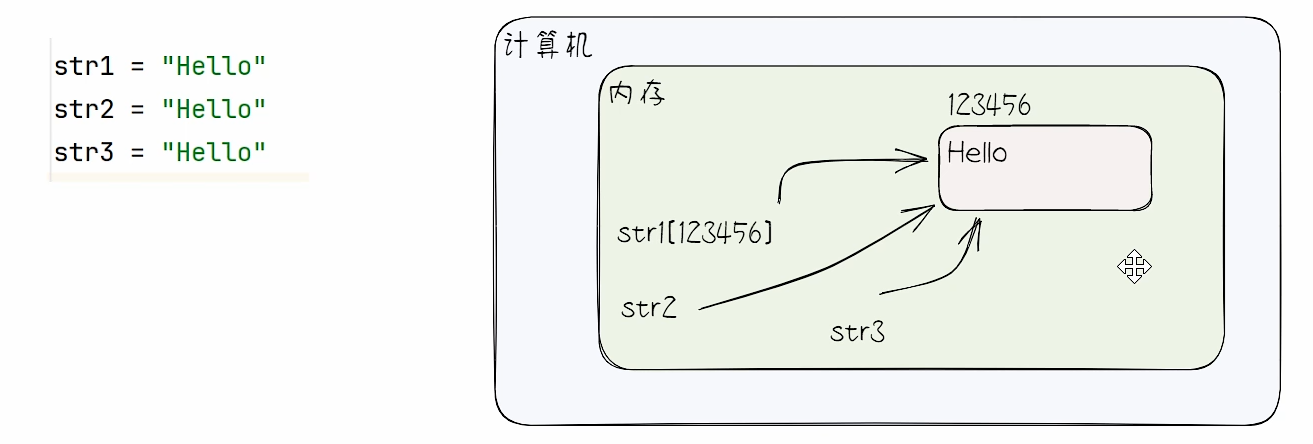
扩展知识:字符串驻留机制
说明:Python 仅保存一份相同且不可变字符串,不同的值被存放在字符串的驻留池中,Python 的驻留机制对相同的字符串只保存一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
# 字符串驻留机制
str1 = "hello"
str2 = "hello"
str3 = "hello"
# id()函数是可以返回对象/数据的内存地址
print("str1的地址:", id(str1))
print("str2的地址:", id(str2))
print("str3的地址:", id(str3))
- 驻留机制几种情况讨论(注意:需要在交互模式下
win+r+cmd进入交互模式,输入python。- 字符串是由 26 个英文字母大小写,0-9,_组成。
- 字符串长度为 0 或 1 时。
- 字符串在编译时进行驻留,而非运行时。
- [-5,256] 的整数数字。
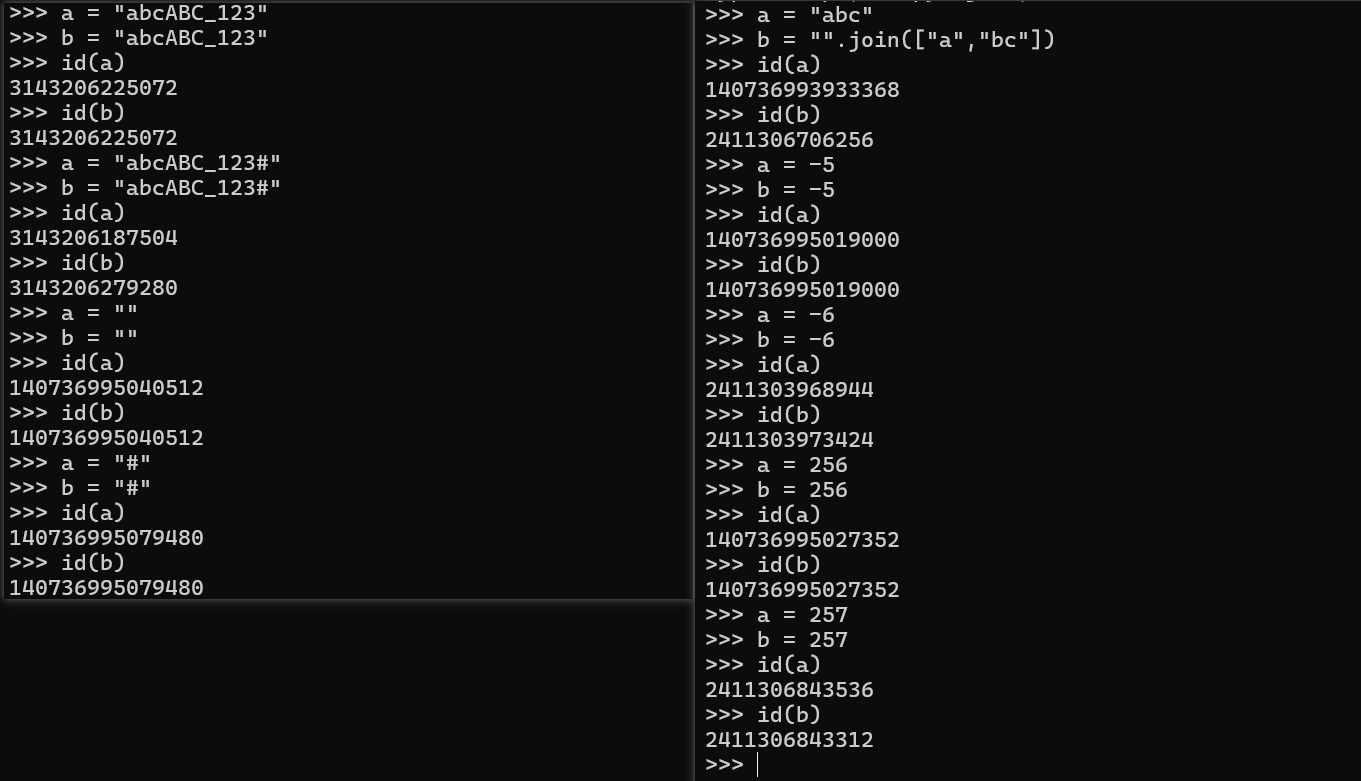
sys中的intern方法可以强制 2 个字符串指向同一个对象。
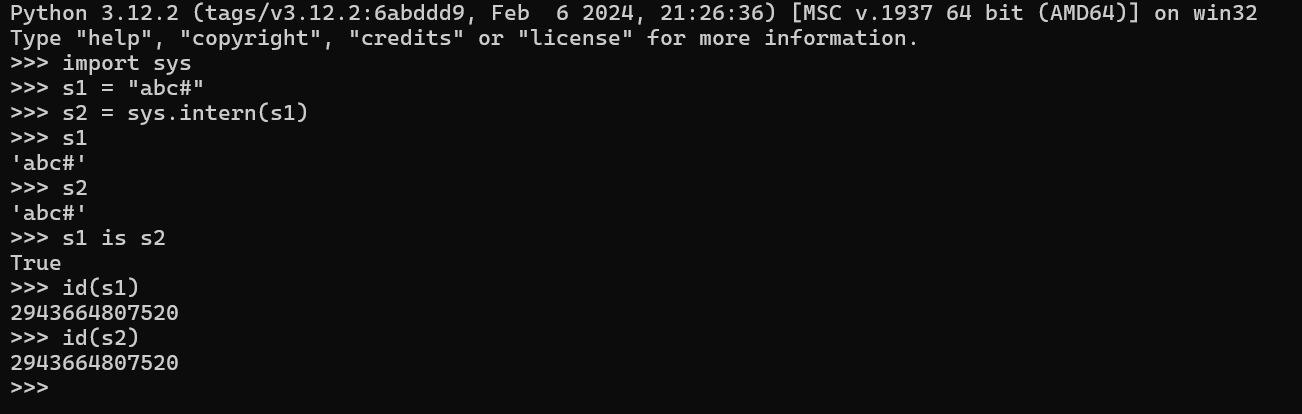
- Pycharm 对字符串进行了优化处理。
# pycharm进行了优化处理
str6 = "abc123#"
str7 = "abc123#"
print(id(str6), id(str7))
num1 = -100
num2 = -100
print(id(num1), id(num2))
- 字符串驻留机制的好处。
当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存。
数据类型转换
隐式类型转换
- Python 变量的类型不是固定的,会根据变量当前值在运行时决定的,可以通过内置函数
type(变量)来查看其类型,这种方式就是隐式转换,有的书也称为自动转换 。 - 在运算的时候,数据类型会向高精度自动转换。
# python 根据该变量使用的上下文在运行时决定的
var1 = 10 # int类型
print(type(var1))
var1 = 1.1 # float类型
print(type(var1))
var1 = 'hello' # string类型
print(type(var1))
# 在运算的时候,数据类型会向高精度自动转换,float的精度高于int
var2 = 10
var3 = 1.2
var4 = var2 + var3
print("var4=", var4, "var4的类型:", type(var4))
var2 = var2 + 0.1
print("var2=", var2, "var2的类型:", type(var2))
显式类型转换
- 如果需要对变量数据类型进行转换,只需要将数据类型作为函数名即可,这种方式就是显示转换/强制转换。
- 以下几个内置的函数可以完成数据类型之间的转换。函数会 返回一个新的对象/值,就是强制转换的后果。
| 函数 | 描述 |
|---|---|
| int(x [, base]) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换到一个浮点数 |
| complex(real [, imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效 Python 表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个(key, value)元组序列 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
# 显示转换案例
i = 10
j = float(i)
print("j的类型:", type(j), "j =", j)
k = str(i)
print("k的类型:", type(k), "k =", k)
显示类型转换注意事项
- 不管什么值的
int、float都可以转为str,str(x)将对象 x 转为字符串。 int转为float时,会增加小数部分,比如 123-> 123.0,float转为int时,会去掉小数部分,比如 123,65-> 123。str转int、float,使用int(x)、float(x)将对象x转换为int / float。- 在将
str类型转为基本数据类型时,要确保str值能够转成有效的数据,比如我们可以把“123”转为一个整数,但是不能把“hello”转成一个整数,如果格式不正确,程序会报ValueError,程序就会终止。 - 对一个变量进行强制转换,会返回一个数据/值,注意:强制转换后,并不会影响原变量的数据类型(即:不会影响原变量指向的数据/值的数据类型)。
# 显示类型转换注意事项
n1 = 100
n2 = 123.65
print(str(n1))
print(str(n2))
print(float(n1))
print(int(n2))
n3 = "12.56"
print(float(n3))
# print(int(n3)) # ValueError: invalid literal for int() with base 10: '12.56'
n4 = "hello" # ValueError: could not convert string to float: 'hello'
# print(float(n4))
# print(int(n4))
i = 10
j = float(i)
print("i的值:", i, "i的类型:", type(i))
print("j的值:", j, "j的类型:", type(j))
k = str(i)
print("i的值:", i, "i的类型:", type(i))
print("k的值:", k, "k的类型:", type(k))
# 练习
i = 10
j = float(i)
print(type(i)) # int
print(type(j)) # float
i = j + 1
print(type(i)) # float
print(type(j)) # float
print(i) # 11.0
print(int(i)) # 11
print(type(i)) # float
运算符
运算符介绍
-
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。
-
算术运算符、赋值运算符、比较运算符、逻辑运算符、位运算符 [需要二进制基础]。
算术运算符
基本介绍
- 算符运算符是对数值类型的变量进行运算的,在程序中使用的非常多。
算术运算符一览
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| + | 加 | 5+5 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 3* 4 | 12 |
| / | 除 | 5/5 | 1 |
| % | 取模(取余) | 7%5 | 2 |
| // | 取整除-返回商的整数部分(向下取整) | 9//2,-9//2 | 4,-5 |
| ** | 返回 x 的 y 次幂 | 2** 4 | 16 |
使用细节
- 对于除号 /,返回结果是小数。
- 对于取整除 //,返回商的整数部分(并且是向下取整)。
- 当对一个数取模时,对应的运算公式:
a % b = a - a // b * b。
# 演示算术运算符的使用
# /, //, %, **
# 对于除号 /,返回结果是小数
print(10 / 3)
# 对于取整数 //,返回商的整数部分(并且是向下取整)
print(10 // 3)
print(-10 // 3)
# 当对一个数取模时,对应的运算公式: a % b = a - a // b * b
print(10 % 3)
# 分析:-10 - (-10) // 3 * 3 = -10 - (-4) * 3 = -10 - (-12) = 2
print(-10 % 3)
# 分析: 10 - 10 // (-3) * (-3) = 10 - (-4) * (-3) = 10 - 12 = -2
print(10 % -3)
# 分析: -10 - (-10) // (-3) * (-3) = -10 - 3 * (-3)= -10 + 9 = -1
print(-10 % -3)
print(2 ** 5)
# 练习
# 假如还有97天放假,问:合xx个星期 零xx天
days = 97
week = days // 7
left_day = days % 7
print(f"假如还有{days}天放假,则:合{week}个星期 零{left_day}天")
# 定义一个变量保存华氏温度,华氏温度转换摄氏温度的公式为:5/9*(华氏温度-100),请求出华氏温度对应的摄氏温度
hua_shi = 234.5
she_shi = 5 / 9 * (hua_shi - 100)
print(f"华氏温度 {hua_shi} 对应的摄氏温度 {she_shi}")
print("华氏温度 %.2f 对应的摄氏温度 %.2f" % (hua_shi, she_shi))
比较运算符
基本介绍
- 比较运算符的结果要么是 True,要么是 False。
- 比较表达式 经常用在 if 结构的条件,为 True 就执行相应的语句,为 False 就不执行。
n1 = 1
if n1 > -10:
print("hi...")
比较运算符一览
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| == | 等于 | 4 == 3 | False |
| != | 不等于 | 4 != 3 | True |
| < | 小于 | 4 < 3 | False |
| > | 大于 | 4 > 3 | True |
| <= | 小于等于 | 4 <= 3 | False |
| >= | 大于等于 | 4 >= 3 | True |
| is | 判断两个变量引用对象是否为同一个 | ||
| is not | 判断两个对象引用对象是否不同 |
使用细节
- 比较运算符组成的表达式,我们称为比较表达式,比如:a > b。
- 比较运算符
==不能误写成=。
# 比较运算符的使用
a = 9
b = 8
print(a > b)
print(a >= b)
print(a <= b)
print(a < b)
print(a == b)
print(a != b)
flag = a > b
print("flag =", flag)
print(a is b)
print(a is not b)
str1 = "abc#"
str2 = "abc#"
print(str1 == str2)
print(str1 is str2) # 交互模式下为False
逻辑/布尔运算符
基本介绍
- 逻辑运算也被称为布尔运算。
逻辑/布尔运算符一览
- 以下假设变量 a = 10,b = 20。
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔“与”:如果 x 为 False,返回 x 的值,否则返回 y 的计算值。 | (a and b) 返回 20 |
| or | x or y | 布尔“或”:如果 x 为 True,返回 x 的值,否则返回 y 的计算值。 | (a or b) 返回 10 |
| not | not a | 布尔“非“:如果 x 为 True,返回 False。如果 x 为 False,它返回 True。 | not (a and b) 返回 False |
a = 10
b = 20
print(a and b)
print(a or b)
print(not (a and b))
使用细节
短路运算符是一种特殊的逻辑运算符,它们在执行过程中会根据操作数的值提前终止运算。
and是“短路运算符”,只有当第一个为 True 时,才去验证第二个。or是“短路运算符”,只有当第一个为 False 时才去验证第二个(换言之,如果第一个为 True,就直接返回第一个的值)。
# and 使用细节
score = 70
if (score >= 60 and score <= 80):
print("成绩还不错~")
a = 1
b = 99
print(a and b)
print((a > b) and b)
print((a < b) and b)
# or 使用细节
score = 70
if score <= 60 or score >= 80:
print("hi~")
a = 1
b = 99
print(a or b)
print((a > b) or b)
print((a < b) or b)
# not 使用细节
a = 3
b = not (a > 3)
print(b)
print(not False)
print(not True)
print(not 0)
print(not "jack")
print(not 1.88)
print(not a)
赋值运算符
基本介绍
- 赋值运算符就是将某个运算后的值,赋给指定的变量。
赋值运算符一览
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 复合加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 复合减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 复合乘法赋值运算符 | c * = a 等效于 c = c * a |
| /= | 复合除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 复合取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 复合幂赋值运算符 | c **= a 等效于 c = c **a |
| //= | 复合取整除赋值运算符 | c //= a 等效于 c = c // a |
使用细节
- 运算顺序从右往左,num = a + b +c
- 赋值运算符的左边是变量,右边可以是变量、表达式、字面量。
- 如:num1 = 20、num2 = 78 * 34 - 10、num3 = a、num4 = a * b。
# 赋值运算符
num1 = 10
i = 100
i += 100 # => i = i + 100
print("i =", i)
i -= 100 # => i = i - 100
print("i =", i)
i *= 3 # i = i * 3
print("i =", i)
# 有两个变量,a 和 b,要求将其进行交换,最终打印结果
# 方法1
a = 30
b = 40
print(f"没有交换前 a={a} b={b}")
temp = a
a = b
b = temp
print(f"交换后 a={a} b={b}")
# 方法2
a = 30
b = 40
print(f"没有交换前 a={a} b={b}")
a, b = b, a
print(f"交换后 a={a} b={b}")
# 方法3
a = 30
b = 40
print(f"没有交换前 a={a} b={b}")
a = a + b
b = a - b
a = a - b
print(f"交换后 a={a} b={b}")
三元运算符
基本语法
- Python 是一种极简主义的编程语言,它没有引入 ?: 这个运算符,而是使用
if else关键字来实现相同的功能。 - 语法: max = a if a > b else b。
- 如果 a > b 成立,就把 a 作为整个表达式的值,并赋给变量 max。
- 如果 a > b 不成立,就把 b 作为整个表达式的值,并赋给变量 max。
代码演示
# 三元运算符
# 获取两个数的最大值
a = 10
b = 80
max = a if a > b else b
print(f"max={max}")
# 获取三个数的最大值
a = 10
b = 30
c = 20
max1 = a if a > b else b
max2 = max1 if max1 > c else c
print(f"max2={max2}")
# 可以支持嵌套使用,但是可读性差,不推荐
max = (a if a > b else b) if (a if a > b else b) > c else c
print(f"max={max}")
运算符优先级
基本语法
- 运算符有不同的优先级,所谓优先级就是表达式的运算顺序。
| 分类 | 运算符 | 描述 |
|---|---|---|
| 算术运算符 | (expressions) | 添加圆括号的表达式 |
| ** | 乘方 | |
| *,@,/,//,% | 乘,矩阵乘,除,整除,取余 | |
| + - | 加法减法 | |
| 位运算 | >>,<< | 右移,左移运算符(移位) |
| & | 按位与 | |
| ^ | 按位异或 | |
| | | 按位或 | |
| 比较运算 | in,not in,is,is not,<,<=,>,>=,!=,== | 比较运算,包括成员检测和标识号检测 |
| 逻辑运算 | not x | 布尔逻辑非 NOT |
| and | 布尔逻辑与 AND | |
| or | 布尔逻辑或 OR | |
| 赋值运算 | =,%=,/=,//=,-=,+=,*=,**= | 赋值运算符 |
标识符的命名规则和规范
标识符概念
- Python 对各种变量、函数、和类等命名时使用的字符序列称为标识符。
- 凡是自己可以起名字的地方都叫标识符,num1 = 90。
# 代码演示
def sum(seq):
total = 0
for x in seq:
if x is not None:
total += x
return total
标识符的命名规则
- 由 26 个英文字母大小写,0-9,_组成。
- 数字不可以开头。
- 不可以使用关键字,但能包含关键字。
- Python 区分大小写。
- 标识符不能包含空格。
# 1. 由26个英文字母大小写,0-9,_组成。
num9_N = 100
# 2. 数字不可以开头。
# 1num = 100
# 3. 不可以使用关键字,但能包含关键字。
# if = 100
my_if = 100
# 4. Python区分大小写。
n = 100
N = 200
print("n =", n, "N =", N)
# 5. 标识符不能包含空格。
my_name = "hi"
# my name = "hi"
# 练习:判断变量名是否正确
hello = 1
hello12 = 2
# 1hello = 1 # 不能以数字开头
# h-b = 1 # 不能包含-
# x h = 1 # 不能包含空格
# h$4 = 1 # 不能包含$
# class = 1 # 不能以关键字作为变量
int = 1
# or = 1 # 不能以关键字作为变量
# and = 1 # 不能以关键字作为变量
# if = 1 # 不能以关键字作为变量
_if = 600
stu_name = 1
标识符命名规范
- 变量名:变量要小写,若有多个单词,使用下划线分开。常亮全部大写。
num = 20
my_friend_age = 21
PI = 3.1415926
- 函数名:函数名一律小写,如果有多个单词,用下划线隔开。另外,私有函数以双下划线开头。
def my_func(var1, var2):
pass
def __private_func(var1, var2):
pass
- 类名:使用大驼峰命名。
驼峰命名法有两种,大驼峰命名和小驼峰命名。
大驼峰命名,多个单子的首字母用大写开头,比如:MyName。
小驼峰命名,第一个单词的首字母用小写,后面的单词首字母都大写,例如:myName。
class SheetParser:
pass
class Foo:
pass
关键字
关键字的定义和特点
- 定义:被 Python 语言赋予了特殊含义,用做专门用途的字符串(单词)。
如何查看关键字
- 官方文档—语言参考—2.3 标识符和关键字—2.3.1 关键字。

- Python 的交互模式中输入
help(),再输入keywords即可。
键盘输入语句
基本介绍
- 在编程中,需要接收用户输入的数据,就可以使用键盘语句来获取。
- input() 介绍:

应用实例演示
# 可以从控制台接收用户信息,【姓名,年龄,薪水】
name = input("请输入姓名:")
age = input("请输入年龄:")
score = input("请输入成绩:")
print("\n输入的信息如下:")
print("name:", name)
print("age:", age)
print("score:", score)
# 注意:接收到的数据类型是str。
# print(10 + score) # TypeError: unsupported operand type(s) for +: 'int' and 'str'
# 如果我们希望对接收到的数据进行算术运算,则需要进行类型转换。
print(10 + float(score))
# 当然,我们也可以在接收数据的时候,直接转成需要的类型
age = int(input("请输入年龄:"))
print("age的类型是:", type(age))
扩展知识:进制
进制
进制介绍
- 对于整数,有如下表示方式
- 2 进制:0,1,满 2 进 1,以 0b 或 0B 开头。
- 8 进制:0-7,满 8 进 1,以数字 0o 或 0O 开头。
- 10 进制,0-9,满 10 进 1。
- 16 进制,0-9 以及 A(10)-F(15),满 16 进 1,以 0x 或 0X 开头。此处的 A-F 不区分大小写。
# 2进制
print(0b111) # 7
print(0B111)
# 8进制
print(0o111) # 73
print(0O111)
# 10进制
print(111) # 111
print(0x111) # 273
print(0X111)
进制的图示
| 十进制 | 十六进制 | 八进制 | 二进制 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | 10 |
| 3 | 3 | 3 | 11 |
| 4 | 4 | 4 | 100 |
| 5 | 5 | 5 | 101 |
| 6 | 6 | 6 | 110 |
| 7 | 7 | 7 | 111 |
| 8 | 8 | 10 | 1000 |
| 9 | 9 | 11 | 1001 |
| 10 | A | 12 | 1010 |
| 11 | B | 13 | 1011 |
| 12 | C | 14 | 1100 |
| 13 | D | 15 | 1101 |
| 14 | E | 16 | 1110 |
| 15 | F | 17 | 1111 |
| 16 | 10 | 20 | 10000 |
| 17 | 11 | 21 | 10001 |
进制的转换
其它进制转十进制
- 二进制转成十进制(加权法/按权展开法)
-
规则:从最低位(右边)开始,将每个位上的数提取出来,乘以 2 的(位数-1)次方,然后求和。
-
案例:将 0b1011 转成十进制的数。
0b1011 =
1 * 2的(1-1)次方 + 1 * 2的(2-1)次方 + 0 * 2的(3-1)次方 + 1 * 2的(4-1)次方 =
1 + 2 + 0 + 8 = 11
print(0b1011) # 11
- 八进制转成十进制
- 规则:从最低位(右边)开始,将每个位上的数提取出来,乘以 8 的(位数-1)次方,然后求和。
- 案例:请将 0o234 转成十进制的数。
0o234 =
4 * 8的(1-1)次方 + 3 * 8的(2-1)次方 + 2 * 8的(3-1)次方 =
4 + 24 + 128 = 156
print(0o234) # 156
- 十六进制转成十进制
- 规则:从最低位(右边)开始,将每个位上的数提取出来,乘以 16 的(位数-1)次方,然后求和。
- 案例:请将 0x23A 转成十进制的数。
0x23A =
10 * 16的(1-1)次方 + 3 * 16的(2-1)次方 + 2 * 16的(3-1)次方 =
10 + 48 + 512 = 570
print(0x23A) # 570
- 练习
1、0b110001100 转成 十进制
= 0 + 0 + 1 * 2**2 + 1 * 2**3 + 0 + 0 + 0 + 1 * 2**7 + 1 * 2**8
= 4 + 8 + 128 + 256
= 396
print(0b110001100) # 396
2、0o2356 转成 十进制
= 6 * 8^0 + 5 * 8**1 + 3 * 8**2 + 2 * 8**3
= 6 + 40 + 192 + 1024
= 1262
print(0o2356) # 1262
3、0xA45 转成 十进制
= 5 * 16**0 + 4 * 16**1 + 10 * 16**2
= 5 + 64 + 2560
= 2629
print(0xA45) # 2629
十进制转其它进制
- 十进制转成二进制(短除法)
- 规则:将该数不断除以 2,直到商为 0 为止,然后将每步得到的余数倒过来,就是对应的二进制。
- 案例:请将 34 转成二进制的数。
34 = 0b100010
34
17 0
8 1
4 0
2 0
1 0
1
print(bin(34)) # 0b100010
- 十进制转成八进制
- 规则:将该数不断除以 8,直到商为 0 为止,然后将每步得到的余数倒过来,就是对应的八进制。
- 案例:请将 131 转成八进制的数。
131 = 0o203
16 3
2 0
2
print(oct(131)) # 0o203
- 十进制转成十六进制
- 规则:将该数不断除以 16,直到商为 0 为止,然后将每步得到的余数倒过来,就是对应的十六进制。
- 案例:请将 237 转成十六进制的数。
237 = 0xED
14 13
14
print(hex(237)) # 0xed
- 练习
1、123 转成 二进制
123 = 0b1111011
61 1
30 1
15 0
7 1
3 1
1 1
1
print(bin(123)) # 0b1111011
2、678 转成 八进制
678 = 0o1246
84 6
10 4
1 2
1
print(oct(678)) # 0o1246
3、8912 转成 十六进制
8912 = 0x22D0
557 0
34 13
2 2
2
print(hex(8912)) # 0x22d0
二进制转成八进制、十六进制
- 二进制转换成八进制
- 规则:从低位开始,将二进制数每三位一组,转成对应的八进制数。
- 案例:请将 0b11010101 转成八进制。
0b11010101 = 0o325
101 = 1 * 2**0 + 0 + 1 * 2**2 = 5
010 = 0 + 1 * 2**1 + 0 = 2
11 = 1 * 2**0 + 1 * 2**1 = 3
print(oct(0b11010101)) # 0o325
- 二进制转换成十六进制
-
规则:从低位开始,将二进制数每四位一组,转成对应的十六进制数。
-
案例:请将 0b11010101 转成十六进制。
0b11010101 = 0xD5
0101 = 1 * 2**0 + 0 + 1 * 2**2 + 0 = 5
1101 = 1 * 2**0 + 0 + 1 * 2**2 + 1 * 2**3 = 13
print(hex(0b11010101)) # 0xd5
- 练习
1、0b11100101 转成 八进制
0b11100101 = 0o345
101 = 1 + 0 + 1 * 2**2 = 5
100 = 1 * 2**2 = 4
11 = 1 + 1 * 2**1 = 3
print(oct(0b11100101)) # 0o345
2、0b1110010110 转成 十六进制
0b1110010110 = 0x396
0110 = 0 + 1 * 2**1 + 1 * 2**2 + 0 = 6
1001 = 1 + 0 + 0 + 1 * 2**3 = 9
11 = 1 + 1 * 2**1 = 3
print(hex(0b1110010110)) # 0x396
八进制、十六进制转成二进制
- 八进制转成二进制
- 规则:将八进制数每 1 位,转成对应的 3 位的二进制数。
- 案例:请将 0o237 转成二进制。
0o237 = 0b10011111
7 = 111
3 = 011
2 = 010
print(bin(0o237)) # 0b10011111
- 十六进制转成二进制
- 规则:将十六进制数每 1 位,转成对应的 4 位的二进制。
- 案例:请将 0x23B 转成二进制。
0x23B = 0b1000111011
B = 1011
3 = 0011
2 = 0010
print(bin(0x23B)) # 0b1000111011
- 练习
1、0o1230 转成 二进制
0o1230 = 0b1010011000
0 = 000
3 = 011
2 = 010
1 = 001
print(bin(0o1230)) # 0b1010011000
2、0xAB29 转成 二进制
0xAB29 = 0b1010101100101001
9 = 1001
2 = 0010
B = 1011
A = 1010
print(bin(0xAB29)) # 0b1010101100101001
二进制在运算中的说明
基本介绍
- 二进制是逢 2 进位的进位制,0、1 是基本数字符号。
- 现代的电子计算机技术全部采用的是二进制,因为它只使用 0、1 两个数字符号,非常简单方便,易于电子方式实现。
- 计算机内部处理的信息,都是采用二进制数来表示的。二进制(Binary)数用 0 和 1 两个数字及其组合来表示任何数。进位规则是“逢 2 进 1”,数字 1 在不同的位上代表不同的值。
原码、反码、补码
基本介绍
- 二进制的最高位是符号位:0 表示整数,1 表示负数。
print(sys.getsizeof(3)) # 3用28个字节表示
# 我们假定用一个字节来表示
3 => 0000 0011
-3 => 1000 0011
- 正数的原码、反码、补码都一样(三码合一)。
3 => 原码:0000 0011
反码:0000 0011
补码:0000 0011
-
负数的反码 = 它的原码符号位不变,其它位取反(0-> 1,1-> 0)。
负数的补码 = 它的反码 + 1,负数的反码 = 负数的补码 - 1。
-3 => 原码:1000 0011
反码:1111 1100
补码:1111 1101
-
0 的反码,补码都是 0
-
在计算机运算的时候,都是以补码的方式来运算的;当我们看运算结果的时候,要看它的原码。
1 + 3 =>
1 => 补码:0000 0001
3 => 补码:0000 0011
1 + 3 =>补码:0000 0100 => 原码 0000 0100 => 4
1 - 3 => 1 + (-3)
1 => 补码:0000 0001
-3 => 原码:1000 0011 => 反码 1111 1100 => 补码 1111 1101
1的补码:0000 0001
-3的补码:1111 1101
1 - 3的补码:1111 1110 => 反码 1111 1101 => 原码 1000 0010 => -2
位运算符
&、|、^、~
~按位与反
- 规则:对数据的每个二进制位取反,即把 1 变成 0,把 0 变成 1。
~-2 = 1
-2的补码:? => -2的原码 1000 0010 => 反码 1111 1101 => 补码 1111 1110
~-2 = 0000 0001(补码) => 原码 0000 0001 => 1
print(~-2) # 1
~2 = -3
2的补码: 0000 0010
~2 => 1111 1101(补码) => 反码 1111 1100 => 原码 1000 0011 => -3
print(~2) # -3
&按位与
- 规则:参与运算的两个值,如果两个相应位都为 1,则该为的结果为 1,否则为 0。
2 & 3 = 2
2的补码:0000 0010
3的补码:0000 0011
2 & 3 => 0000 0010(补码) => 原码 0000 0010 => 2
print(2 & 3) # 2
^按位异或
- 规则:当两个对应的二进制位相异时,结果为 1。
2 ^ -3 = -1
2的补码: 0000 0010
-3的补码:? => 原码 1000 0011 => 反码 1111 1100 => 补码 1111 1101
2 ^ -3 => 1111 1111(补码) => 反码 1111 1110 => 原码 1000 0001 => -1
print(2 ^ -3) # -1
|按位或
- 规则:只要对应的两个二进制位有一个为 1 时,结果位就位 1。
2 | 3 = 3
2的补码: 0000 0010
3的补码: 0000 0011
2 | 3 => 0000 0011(补码) => 原码 0000 0011 => 3
print(2 | 3) # 3
>>、<<
<<左移
- 规则:运算数的各二进制位全部左移若干位,由“<<”右边的数指定移动的位数,符号位不变,高位丢弃,低位补 0。
- 左移一位相当于 * 2 一次。
5 << 1 = 10
5的补码: 0000 0101
5 << 1 => 0000 1010(补码) => 原码 0000 1010 => 10
print(5 << 1) # 10
-5 << 1 = -10
-5的补码:? => 原码 1000 0101 => 反码 1111 1010 => 补码 1111 1011
-5 << 1 => 1111 0110(补码) => 反码 1111 0101 => 原码 1000 1010 => -10
print(-5 << 1) # -10
>>右移
- 规则:把
>>左边的运算数的各二进制位全部右移若干位,>>右边的数指定移动的位数,低位溢出,符号位不变,并用符号位补溢出的高位。 - 右移一位相当于 // 2 一次。
5 >> 1 = 2
5的补码: 0000 0101
5 >> 1 => 0000 0010(补码) => 原码 0000 0010 => 2
print(5 >> 1) # 2
-5 >> 1 = -3
-5的补码:1111 1011
-5 >> 1 => 1111 1101(补码) => 反码 1111 1100 => 原码 1000 0011 => -3
print(-5 >> 1) # -3
程序控制结构
程序流程控制介绍
基本介绍
- 程序流程控制绝对程序是如何执行的,是我们必须掌握的,主要有三大流程控制语句。
- 顺序控制、分支控制、循环控制。
顺序控制
基本介绍
- 顺序控制:程序从上到下逐行地执行,中间没有任何判断和跳转。
# 顺序控制
print("程序开始执行")
print("1.小明去上学")
print("2.小明学习中")
print("3.小明放学了")
print("策划给你续执行结束")
# Python中定义变量时采用合法的前向引用
num1 = 12
num2 = num1 + 2
分支控制 if-else
基本介绍
- 让程序有选择的执行,分支控制有三种:单分支、双分支、多分支。
单分支
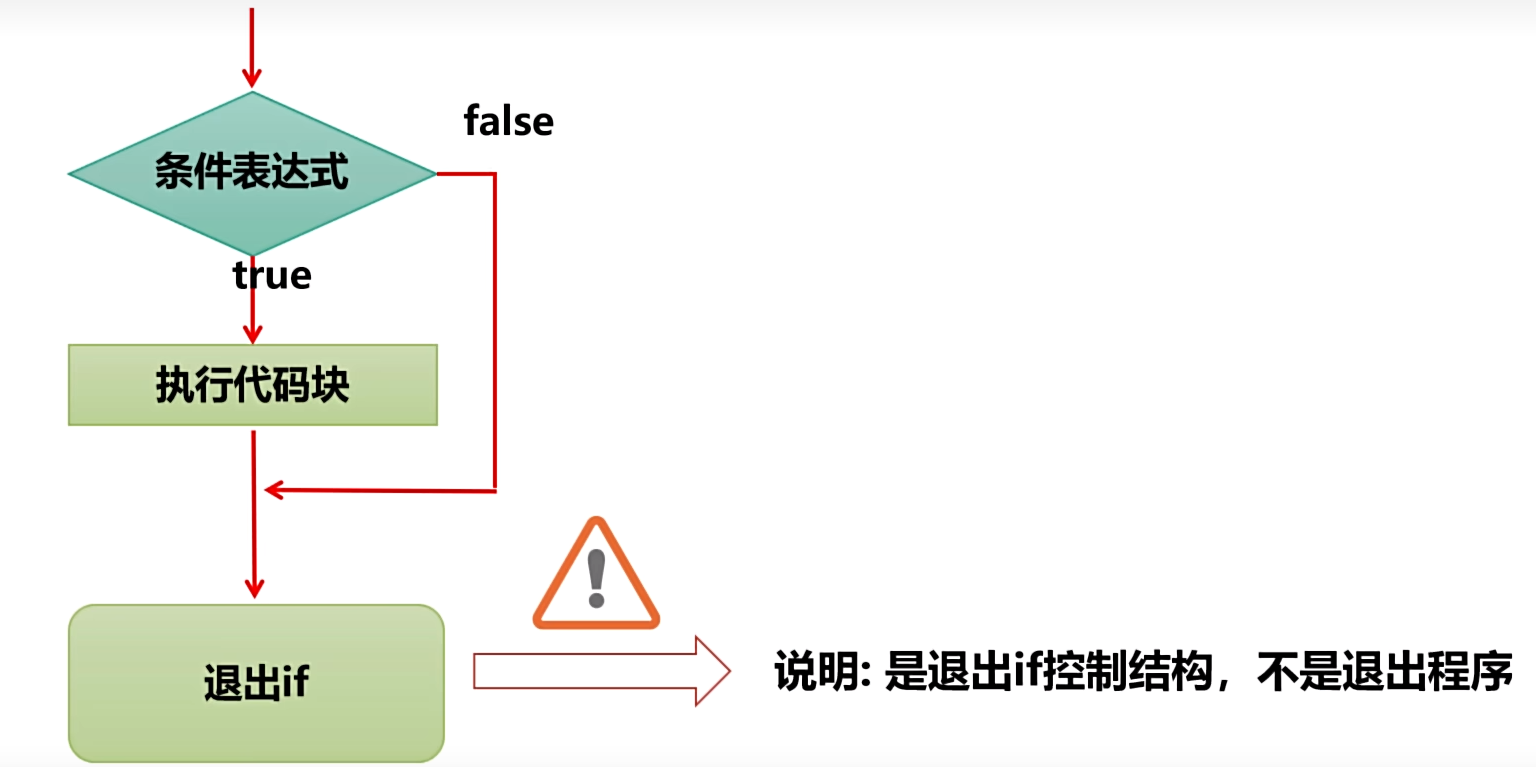
- 基本语法:单分支是通过 if 语句来实现的,if 语句的基本语法如下:
if 条件表达式:
代码块(可以有多条语句)
- if 基本语法说明:
- 当条件表达式为 True 时,就会执行代码块;如果为 False,就不执行。
- Python 缩进非常重要,是用于界定代码块的,相当于其他编程语言中的大括号{}。
- 最短的缩进对较长的有包含关系,缩进前后没有要求,但是每个代码块应具有相同的缩进长度(TAB 或者相同个数的空格)。
- 可以看成,和其它语言相比:其它语言的代码块是用{}表示的,Python 缩进就代替了{}。
# 单分支 if
if 4 < 1:
print("ok1")
print("ok2")
print("ok3")
if 100 > 20:
print("ok4")
print("ok5")
if 8 > 2:
print("ok6")
- 练习
# 请编写一个程序,可以输入人的年龄,如果年龄大于等于18岁,则输出“你年龄大于等于18,要对自己的行为负责”
age = int(input("请输入你的年龄:"))
if age >= 18:
print("你年龄大于等于18,要对自己的行为负责")
- 流程图
双分支
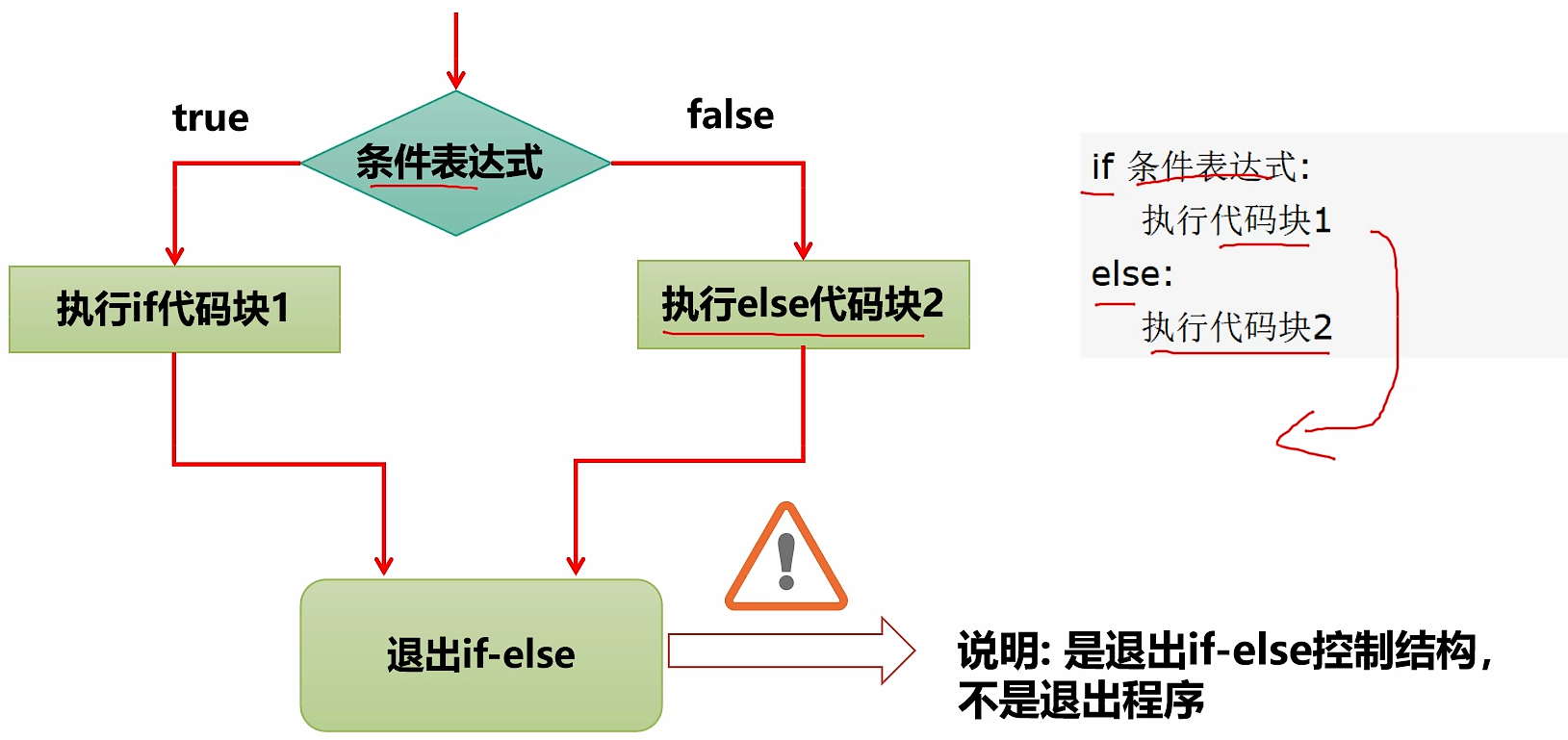
- 基本语法
if 条件表达式:
执行代码块1
else:
执行代码块2
- 基本语法说明
- if、else 是关键字,是规定好的。
- 当条件表达式成立,即执行代码块 1,否则执行代码块 2,注意;不要少写了冒号:。
- 应用实例
# 请编写一个程序,可以输入人的年龄,如果年龄大于等于18岁,则输出“你年龄大于等于18,要对自己的行为负责”。否则,输出“你的年龄不大,这次放过你了”
age = int(input("请输入你的年龄:"))
if age >= 18:
print("你年龄大于等于18,要对自己的行为负责")
else:
print("你的年龄不大,这次放过你了")
- 流程图
- 练习
# 对下列代码,若有输出,指出输出结果
x = 4
y = 1
if x > 2:
if y > 2:
print(x + y)
print("hsp")
else:
print("x is", x)
# 编写程序,定义2个整数变量并赋值,判断两数之和,如果大于等于50,打印“hello world”
num1 = 30
num2 = 20
if num1 + num2 >= 50:
print("hello world")
# 编写程序,定义2个float型变量,若果第1个数大于10.0,且第2个数小于20.0,打印两数之和
num1 = 20.0
num2 = 15.0
if num1 > 10.0 and num2 < 20.0:
print(f"{num1} + {num2} = {num1 + num2}")
# 定义两个变量int类型,判断二者之和,是否能被3又能被5整除,打印提示信息。
num1 = 10
num2 = 5
if (num1 + num2) % 3 == 0 and (num1 + num2) % 5 == 0:
print(f"{num1 + num2} 可以被3又能被5整除")
else:
print(f"{num1 + num2} 不可以被3又能被5整除")
# 判断一个年份是否是闰年,闰年的条件是符合下面二者之一:(1)年份能被4整除,但不能被100整除(2)能被400整除
year = 2024
if (year % 4 == 0 and year % 100 != 0) or year % 400 == 0:
print(f"{year} 是闰年")
else:
print(f"{year} 不是闰年")
多分支
- 基本语法
if 条件表达式1:
执行代码块1
elif 条件表达式2:
执行代码块2
...
else:
执行代码块n+1
- 流程图
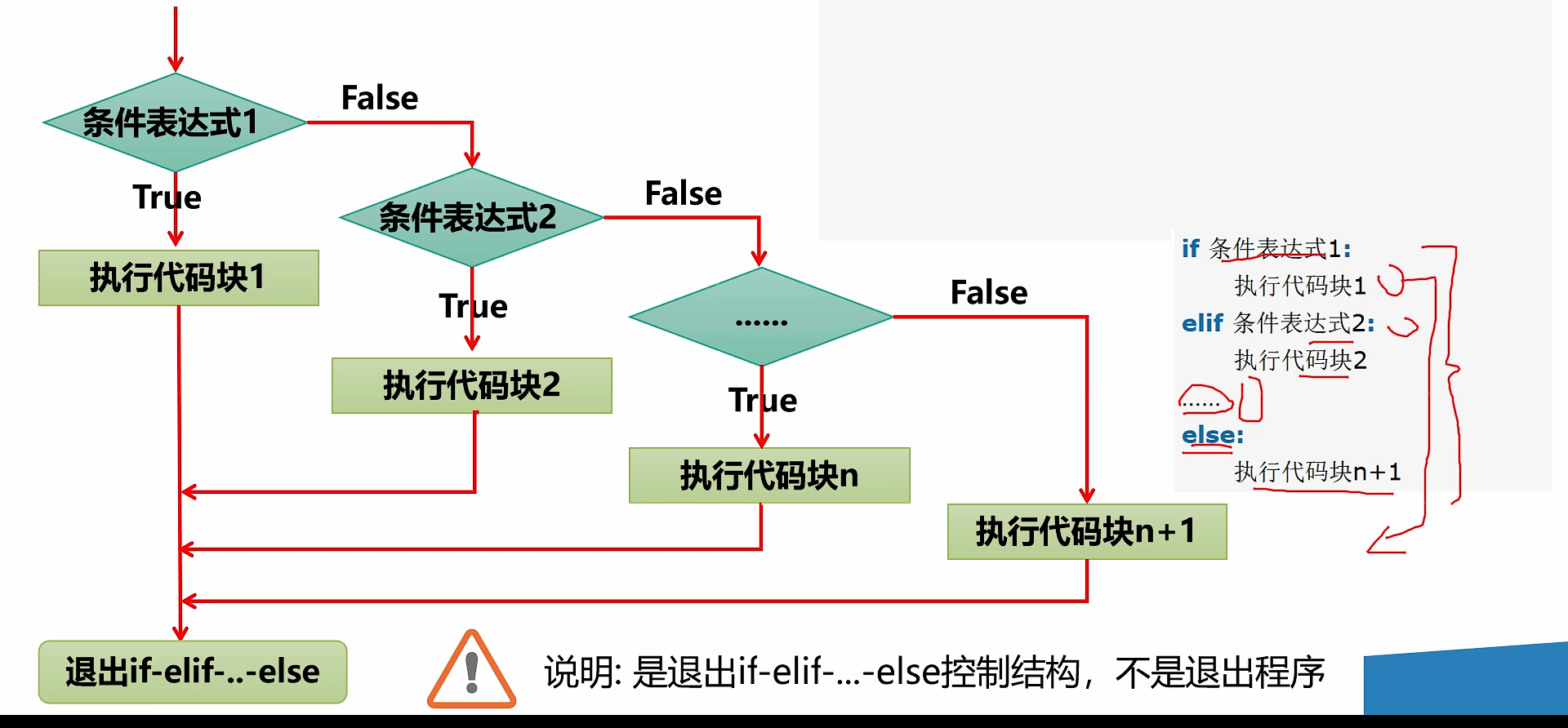
- 执行流程说明
- 当条件表达式 1 成立时,即执行代码 1。如果表达式 1 不成立,才去判断表达式 2 是否成立。
- 如果表达式 2 成立,就执行代码块 2。
- 以此类推,如果所有的表达式都不成立则执行 else 的代码块。
- 只能有一个执行入口。
- 案例演示
# 参加Python考试,根据得分获得对应奖励
score = int(input("请输入成绩[整数]:"))
if score >= 0 and score <= 100:
if score == 100:
print("BWM")
elif score > 80 and score <= 99:
print("iphone13")
elif score >= 60 and score <= 80:
print("ipad")
else:
print("none")
else:
print(score, "不在0~100")
# 分析代码输出结果
b = True
if b == False:
print("a")
elif b:
print("b")
elif not b:
print("c")
else:
print("d")
- 练习
# 婚嫁
height = float(input("请输入身高(cm):"))
money = float(input("请输入财富(万):"))
handsome = (input("请输入颜值(帅,不帅):"))
if height > 180 and money > 1000 and handsome == "帅":
print("我一定要嫁给他")
elif height > 180 or money > 1000 or handsome == "帅":
print("嫁吧,比上不足,比下有余")
else:
print("不嫁")
嵌套分支
基本介绍
- 基本介绍
-
嵌套分支:在一个分支结构中又嵌套了另一个分支结构。
-
里面的分支的结构称为内层分支,外面的分支结构称为外层分支。
-
规范:不要超过 3 层(可读性不好)
- 基本语法
if:
if:
# if-else...
else:
# if-else...
应用案例
# 参加歌手比赛,若果初赛成绩大于8.0进入决赛,否则提示淘汰。并且根据性别提示进入男子组或女子组。输入成绩和性别,进行判断和输出信息。
score = float(input("请输入你的成绩:"))
if score > 8.0:
gender = input("请输入你的性别(男|女):")
if gender == "男":
print("男子组决赛")
else:
print("女子组决赛")
else:
print("淘汰")
# 出票系统:根据淡旺季的月份和年龄,打印票价
month = int(input("请输入当前的月份:"))
age = int(input("请输入你的年龄:"))
if 4 <= month <= 10:
if age > 60:
print("¥20")
elif age >= 18:
print("¥60")
else:
print("¥30")
else:
if 18 <= age <= 60:
print("¥60")
else:
print("¥20")
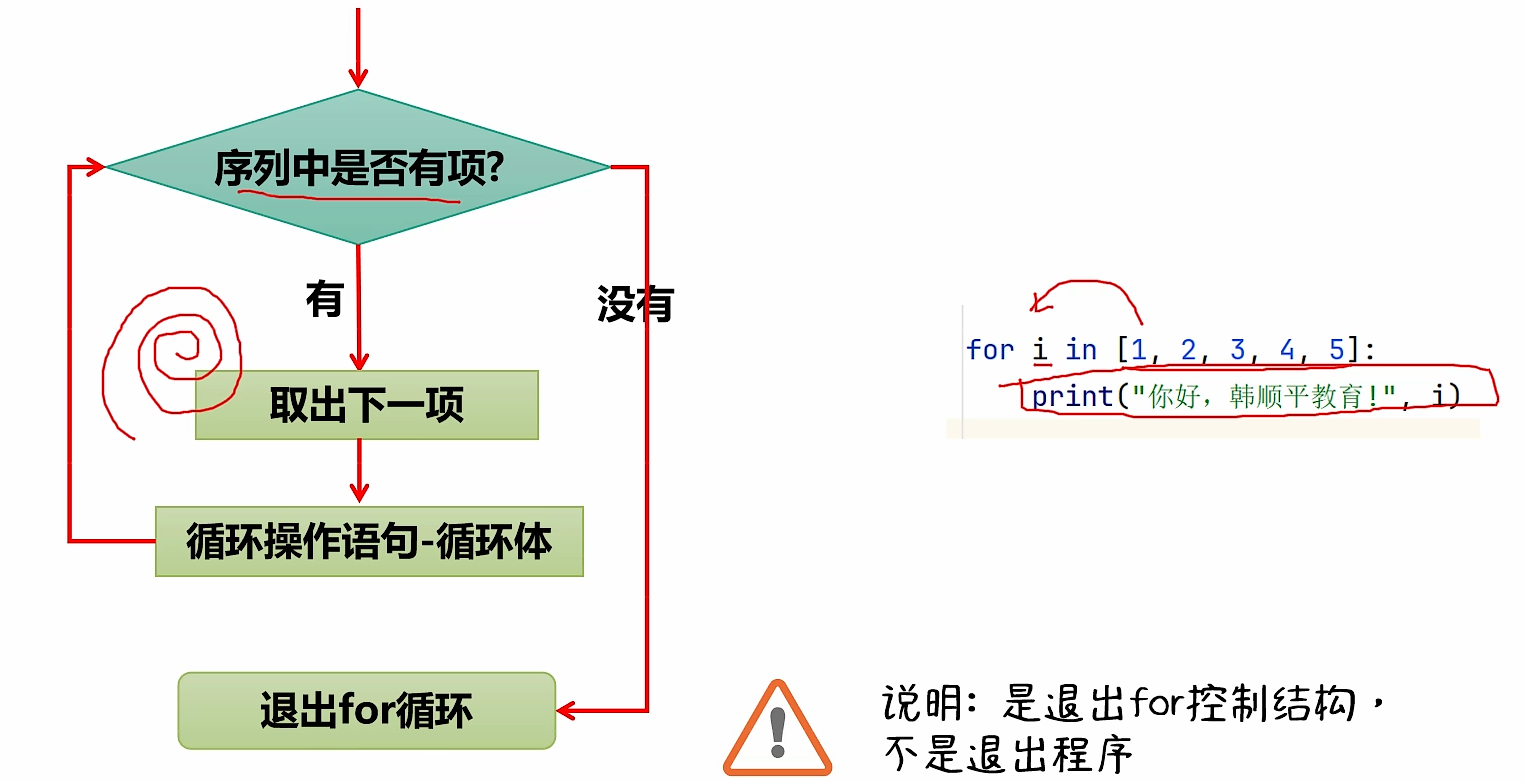
for 循环分支
基本介绍
-
基本介绍:for 循环听其名而知其意,就是让你的代码可以循环的执行,是通过 for 语句来实现的。
-
基本语法
for <变量> in <范围/序列>:
<循环操作语句>
- for 基本语法说明
- for、in 是关键字,是规定好的。
- <范围/序列> 可以理解成要处理的数据集,需要是可迭代对象(比如字符串,列表等…)。
- 循环操作语句,这里可以有多条语句,也就是我们要循环执行的代码,也叫循环体。
- python 的 for 循环是一种“轮询机制”,是对指定的数据集,进行“轮询处理”。
for 循环执行流程分析
- 代码演示
# 编写一个程序,可以打印5句 “hsp” 。
# 定义一个列表(后面详细介绍),可以视为一个数据集
nums = [1, 2, 3, 4, 5]
print(nums, type(nums))
for i in [1, 2, 3, 4, 5]:
print("hsp", i)
for i in nums:
print("hsp", i)
- for 循环控制流程图
- 代码执行内存分析法

注意实现和细节说明
- 循环时,依次将序列中的值取出赋给变量。
- 如需要遍历数字序列,可以使用内置
range()函数,它会生成数列。range()生成的数列是前闭后开。
# range函数解读
class range(stop)
class range(start, stop, step=1)
# 1、虽然被称为函数,但 range 实际上是一个不可变的序列类型。
# 2、range 默认增加的步长 step是1,也可以指定,start 默认是0。
# 3、通过list() 可以查看range() 生成的序列包含的数据。
# 4、range() 生成的数列是前闭后开。
# 1、生成一个 [1, 2, 3, 4, 5]
r1 = range(1, 6, 1)
r1 = range(1, 6)
print("r1 = ", list(r1))
# 2、生成一个 [0, 1, 2, 3, 4, 5]
r2 = range(0, 6, 1)
r2 = range(0, 6)
print("r2 = ", list(r2))
# 3、生成一个 r3 = [1, 3, 5, 7, 9]
r3 = range(1, 10, 2)
print("r3 = ", list(r3))
# 4、输出10句"hello, python"
for i in range(10):
print("hello, python")
3、for 可以和 else 配合使用
- 语法格式
for <variable> in <ssequence>:
<statements>
else:
<statements>
- 解读:什么情况下会进入 else,就是 for 循环正常的完成遍历,在遍历过程中,没有被打断(解释:比如没有执行到 break 语句)。
# for-else案例
nums = [1, 2, 3]
for i in nums:
print("hsp")
# 演示break
# if i == 2:
# break # 中断-提前结束for
else:
print("没有循环数据了...")
练习
# 以下代码输出什么
languages = ["c", "c++", "java", "python"]
for language in languages:
print(language)
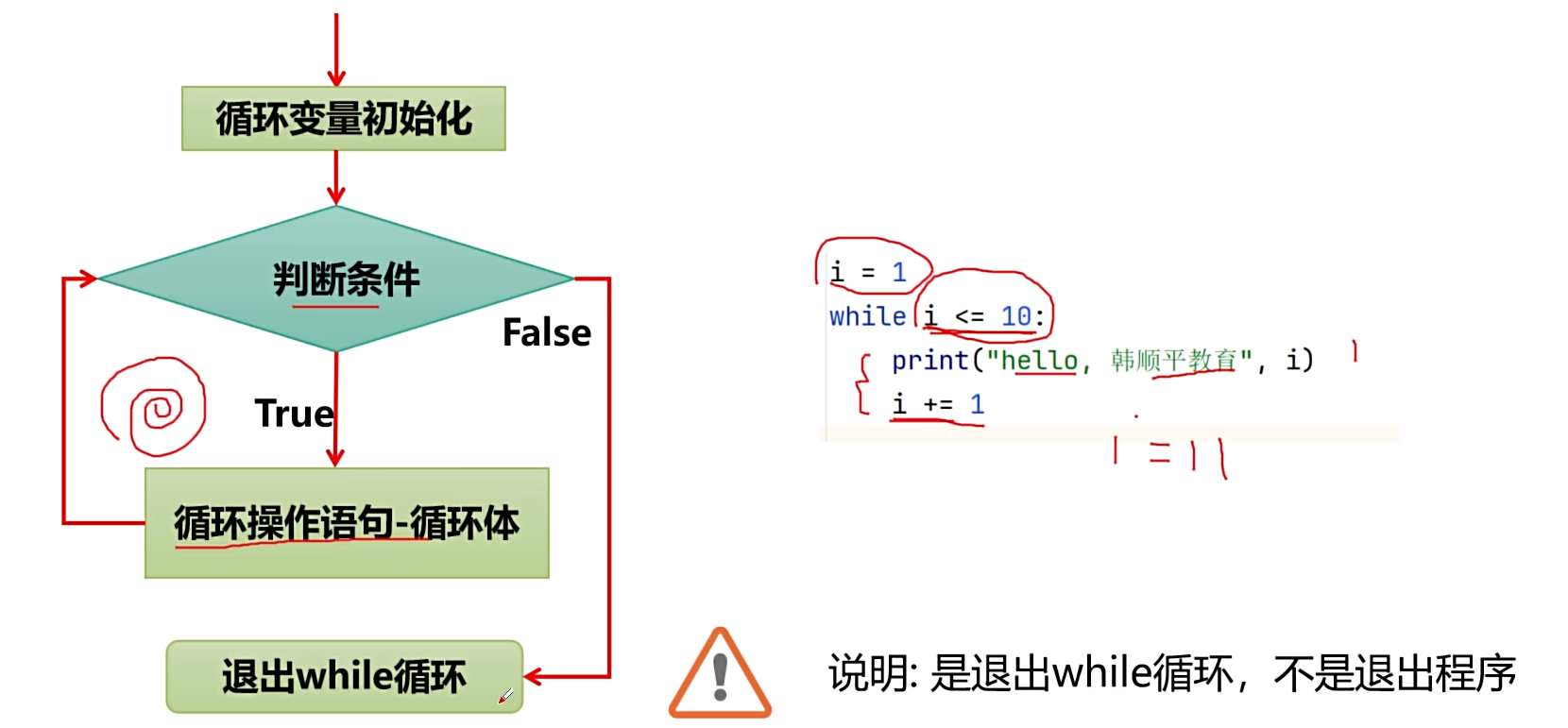
while 循环分支
基本语法
- 基本介绍:while 循环用于在表达式为真的情况下,重复的(循环的)执行,是通过 while 语句来实现的。
- 基本语法
while 判断条件(condition):
循环操作语句(statements)...
- 基本语法说明
- while 是关键字,是规定好的。
- 当判断条件为 True 时,就执行循环操作语句,如果为 False,就退出 while。
- 循环操作语句,这里可以有多条语句,也就是我们要循环执行的代码,也叫循环体。
while 循环执行流程分析
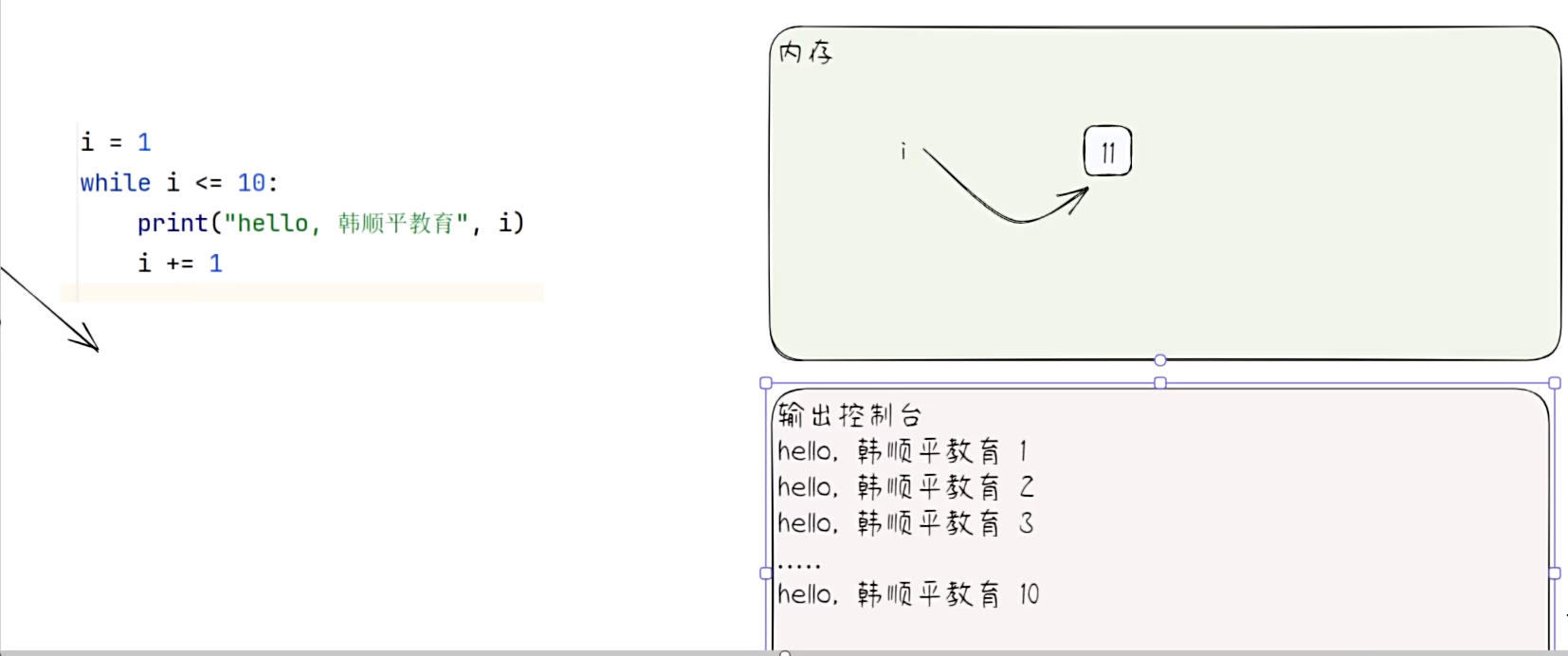
- 代码演示
# 使用while完成10句 “hsp”
i = 1
while i <= 10:
print("hsp")
i += 1
- while 循环控制流程图
- 代码执行内存分析法
注意事项和细节说明
- while 可以和 else 配合使用
- 语法格式
while 判断条件(condition):
循环操作语句(statements)
else:
其它语句<additional_statements(s)>
- 解读:在 while … else 判断条件为 false 时,会执行 else 的语句块,即:在遍历过程中,没有被打断(解释:比如没有执行到 break 语句)。
- 使用案例
# while-else使用案例
i = 0
while i < 3:
print("hsp")
i += 1
# 演示break 中断
# if i == 1:
# break
else:
print("i < 3 不成立 i =", i)
练习
# 1、打印 1-100 之间所有能被3整除的数
i = 1
max_num = 100
while i <= max_num:
if i % 3 == 0:
print(i)
i += 1
# 2、打印 40-200 之间所有的偶数
i = 40
max_num = 200
while i <= max_num:
if i % 2 == 0:
print(i)
i += 1
# 3、不断输入姓名,知道输入“exit”为止
name = ""
while name != "exit":
name = input("Enter your name: ")
print("输入的内容是:", name)
# 4、打印 1~100 之间所有是9的倍数的整数,统计个数及总和
i = 1
max_num = 100
count = 0
sum = 0
while i <= max_num:
if i % 9 == 0:
print(i)
count += 1
sum += i
i += 1
print("count:", count)
print("sum:", sum)
# 5、完成下列表达式输出
num = int(input("请输入一个整数:"))
i = 0
while i <= num:
print(f"{i} + {num - i} = {num}")
i += 1
多重循环控制
基本介绍
- 基本介绍
- 将一个循环放在另一个循环体内,就形成了嵌套循环。其中,for、while 均可以作为外层循环和内层循环。[建议一般使用两层,最多不要超过三层,否则,代码的可读性不好]。
- 实际上,嵌套循环就是把内层循环当做外层循环的循环体。
- 如果外层循环次数为 m 次,内层为 n 次,则内层循环体实际上需要执行 m*n 次。
# 如果外层循环次数为m次,内层为n次,则内层循环体实际上需要执行m*n次。
for i in range(2):
for j in range(3):
print("i=", i, "j=", j)
应用案例
- 编程思想:化繁为简,先死后活。
- 打印空心金字塔
# 打印空心金字塔
"""
思路分析
- 先死后活
1、先不考虑层数的变化,嘉定就是5层,后面做活
- 化繁为简
1、打印矩形
2、打印直角三角形
3、打印金字塔
4、打印空心金字塔
"""
# 总层数
total_level = 5
# i 控制层数
for i in range(1, total_level + 1):
# k 控制输出空格数
for k in range(total_level - i):
print(" ", end="")
# j 控制每层输出的*号个数
for j in range(2 * i - 1):
if j == 0 or j == 2 * i - 2 or i == total_level:
print("*", end="")
else:
print(" ", end="")
# 每层输出后,换行
print("")
- 打印空心菱形
# 空心菱形
n = 5
for i in range(n):
if i == 0:
print(" " * (n - i - 1) + "*" * (2 * i + 1))
else:
print(" " * (n - i - 1) + "*" + " " * (2 * i - 1) + "*")
for i in range(n - 2, -1, -1):
if i == 0 or i == n - 1:
print(" " * (n - i - 1) + "*" * (2 * i + 1))
else:
print(" " * (n - i - 1) + "*" + " " * (2 * i - 1) + "*")
- 使用 while 循环来实现空心金字塔
# while实现空心金字塔
i = 0
n = 5
while i < n:
if i == 0 or i == n - 1:
print(" " * (n - i - 1) + "*" * (2 * i + 1))
else:
print(" " * (n - i - 1) + "*" + " " * (2 * i - 1) + "*")
i += 1
- 统计班级情况
"""
统计3个班成绩情况,每个班有5名同学,要求:
1、求出每个班的平均分和所有班的平均分,学生的成绩从键盘输入
2、统计三个班及格人数
编程思想:(1)化繁为简(2)先死后活【先考虑3个班,每个班5名同学】
# 化繁为简
1. 先统计1个班成绩情况,求出一个班的平均分
2. 统计3个班成绩情况,求出各个班的平均分、所有班级的平均分和 及格人数
"""
total = 0.0
pass_num = 0
class_num = 3
student_num = 5
# 循环地处理3个班级的成绩
for j in range(class_num):
# 统计一个班成绩情况
sum = 0.0
for i in range(student_num):
score = float(input(f"请输入第{j + 1}班的 第{i + 1}个学生的成绩:"))
# 判断是否及格
if score >= 60.0:
pass_num += 1
sum += score
print(f"第{j + 1}班级的情况:平均分{sum / 5}")
total = total + sum
print(f"所有班级的平均分 {total / (student_num * class_num)},及格人数 {pass_num}")
- 打印九九乘法表
# 九九乘法表
for i in range(1, 10):
for j in range(1, i + 1):
print(f"{j} * {i} = {i * j}", end="\t")
print()
break 语句
基本介绍
- 基本介绍
- break 语句用于终止某个语句块的执行,使用在循环中
- 基本语法
...
break
...
- break 语句流程图
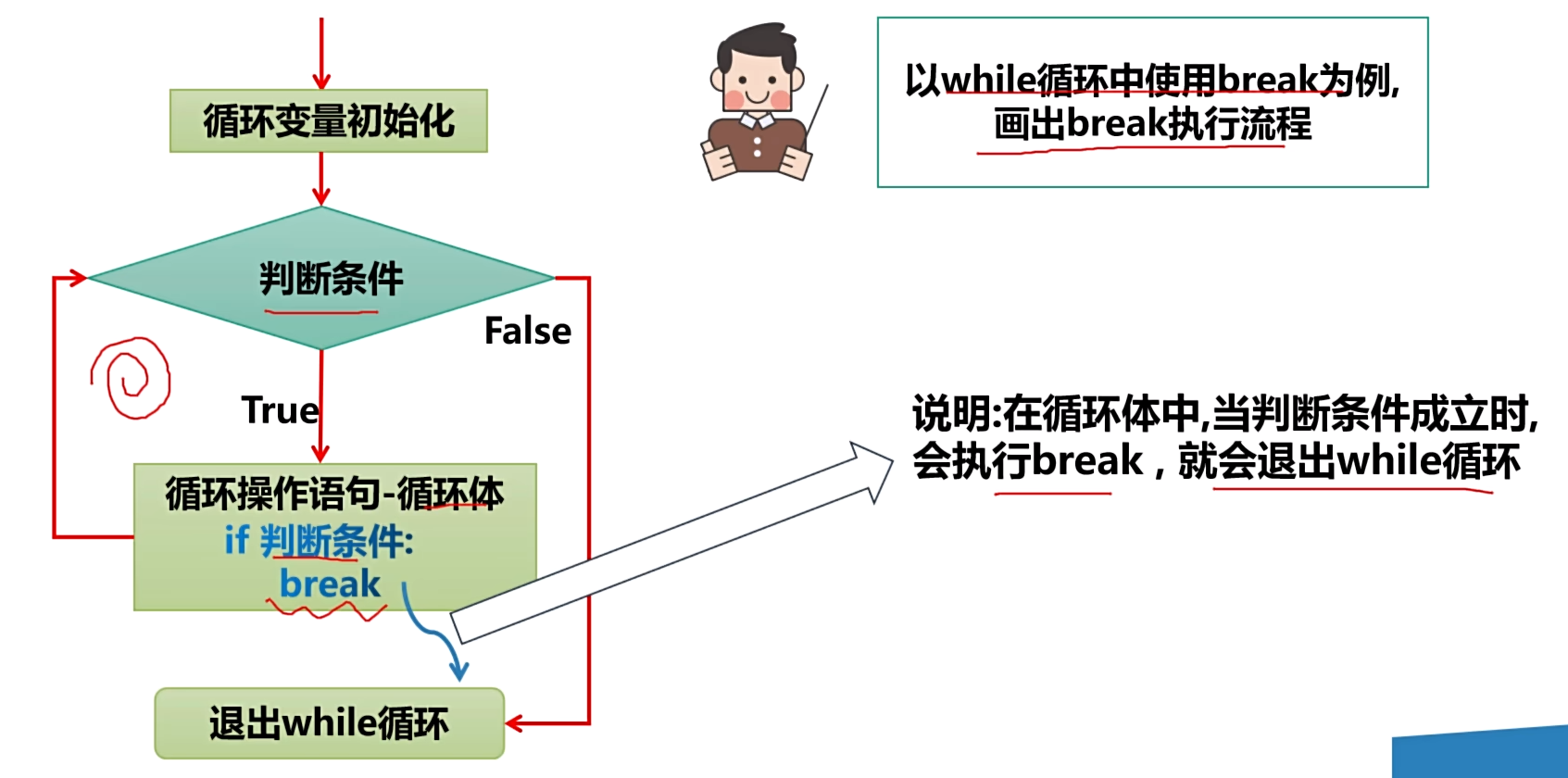
快速入门
# 随机生成 1-100 的一个数,直到生成了97这个数,看看一共用了多少次
# random.randint(a, b) 返回随机整数N满足 a<=N<=b。相当于randrange(a, b+1)
import random
count = 0
while True:
count += 1
n = random.randint(1, 100)
print(n)
if n == 97:
break
print("count =", count)
注意实现和细节说明
- break 语句是用在 for 或 while 循环所嵌套的代码。
- 它会终结最近的外层循环,如果循环有可选的 else 子句,也会跳过该子句。
- 如果一个 for 循环被 break 所终结,该循环的控制变量会保持其当前值。
# 它会终结最近的外层循环,如果循环有可选的else子句,也会跳过该子句。
count = 0
while True:
print("hi")
count += 1
if count == 3:
break
while True:
print("ok")
break
else:
print("hello")
# 如果一个for循环被break所终结,该循环的控制变量会保持其当前值。
nums = [1, 2, 3, 4, 5]
for i in nums:
if i > 3:
break
print("i =", i)
练习
- 1 - 100 以内的求和,求出当和第一次大于 20 的当前控制循环的变量是多少。
sum = 0
for i in range(1, 101):
sum += i
if sum > 20:
break
print(i)
- 实现登录验证,有三次机会,如果用户名为“张无忌”,密码“888” 提示登录成功,否则提示还有几次机会。
change = 3
for i in range(1, 4):
name = input("请输入你的姓名:")
passwd = int(input("请输入你的密码:"))
change -= 1
if name == "张无忌" and passwd == 888:
print("登录成功")
break
else:
print(f"姓名或密码错误,还有{3 - i}次机会")
continue 语句
基本介绍
- 基本介绍
- continue 语句用于 for 或 while 循环所嵌套的代码中。
- continue 语句用于结束本次循环,继续执行循环的下一次轮次。继续执行的是:该 continue 最近的外层循环的下一次轮次。
- 基本语法
...
continue
...
- continue 语句流程图
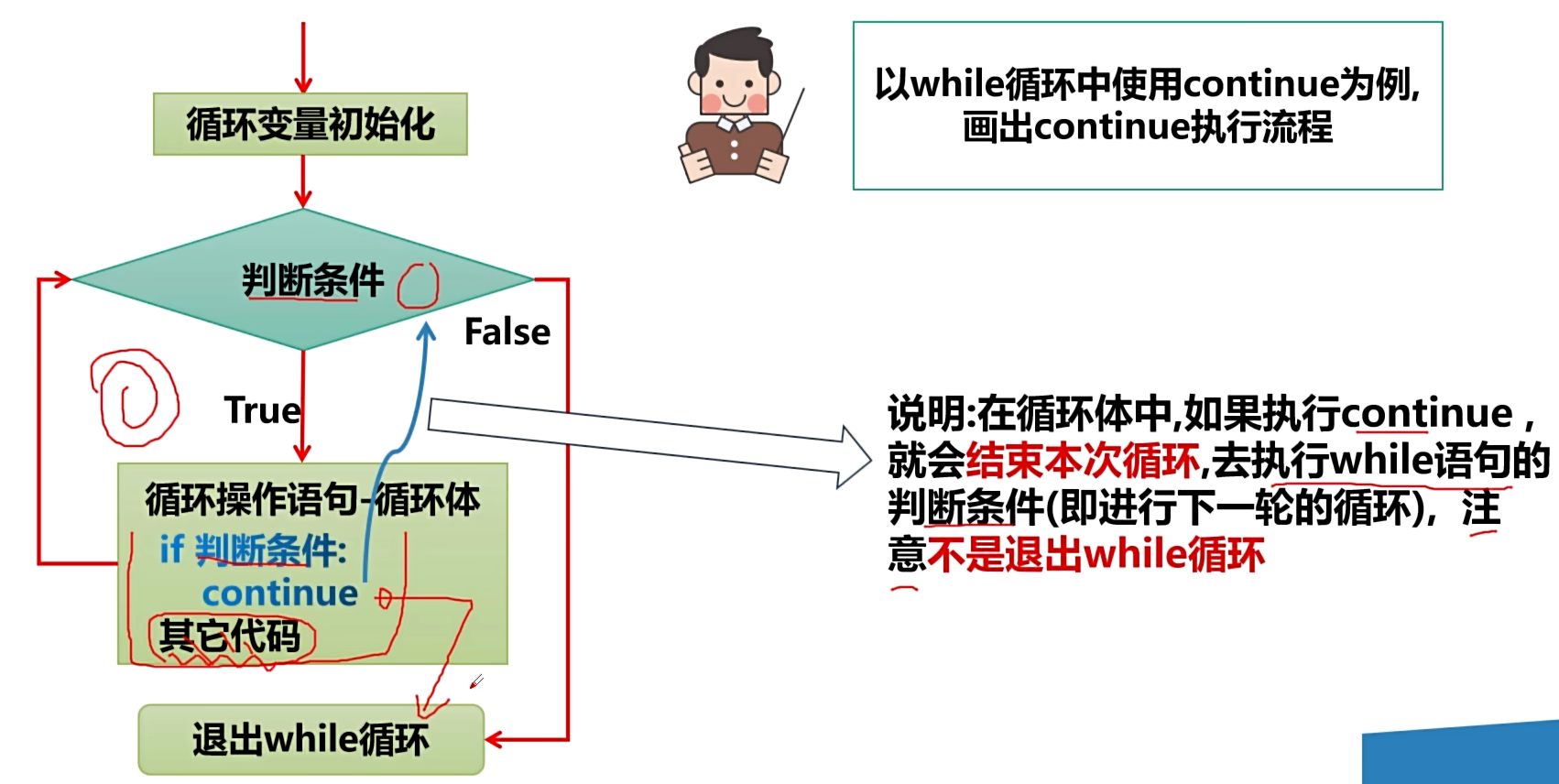
快速入门
# 下面代码输出结果是什么
i = 1
while i <= 4:
i += 1
if i == 3:
continue
print("i =", i)
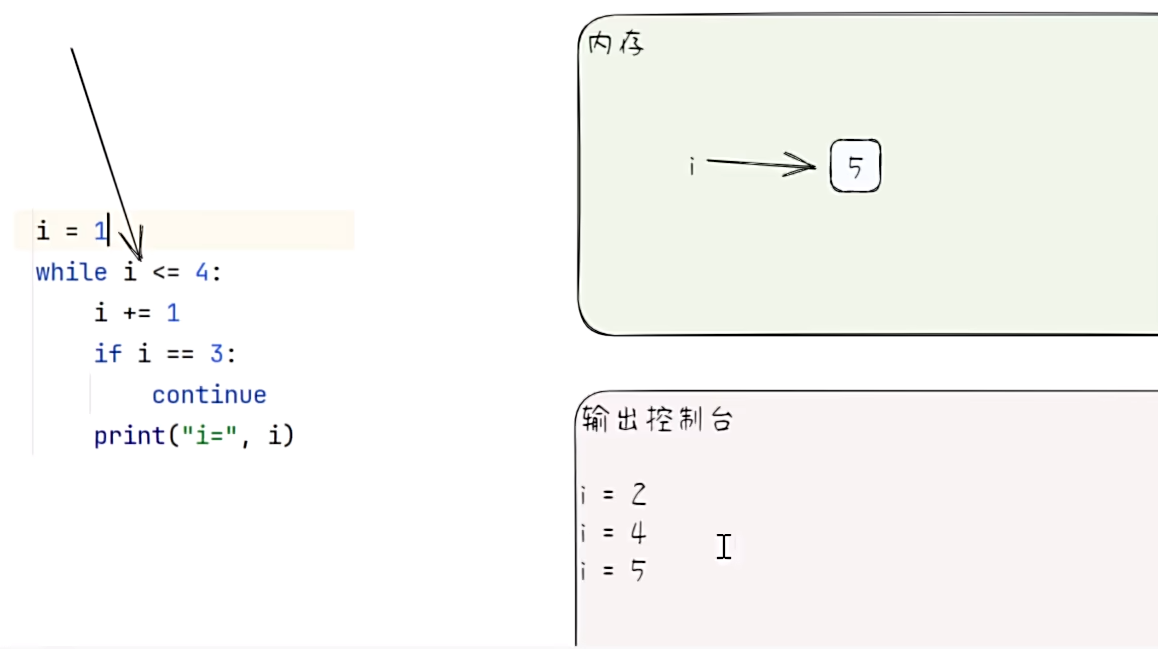
练习
- 请分析下面的代码输出结果是什么。
for i in range(0, 13):
if i == 10:
continue
print("i =", i)
for i in range(0, 2):
for j in range(1, 4):
if j == 2:
continue
print("i =", i, "j =", j)
return 语句
基本介绍
- 基本介绍
- return 使用在函数,表示跳出所在的函数。
- 演示案例
def f1():
for i in range(1, 5):
if i == 3:
return
# break
# continue
print("i =", i)
print("结束for循环!")
f1()
本章作业
"""
某人有100000元,没经过一次路口,需要交费,规则如下:
当现金>50000时,每次交5%;当现金<=50000时,每次交1000.
"""
money = 100000
count = 0
while True:
if money > 50000:
money *= 0.95
count += 1
elif money >= 1000:
money -= 1000
count += 1
else:
break
print("count =", count, "money =", money)
函数
函数介绍
基本介绍
- 为完成某一功能的程序指令(语句)的集合,称为函数。
- 在 Python 中,函数分为:系统函数、自定义函数。
- 即:内置函数和模块中提供的函数都是系统函数(由 Python 提供),自定义函数是程序员根据业务需要开发的。
函数的好处
- 提供代码的复用性。
- 可以将实现的细节封装起来,然后供其他用户来调用即可。
函数的定义
基本语法
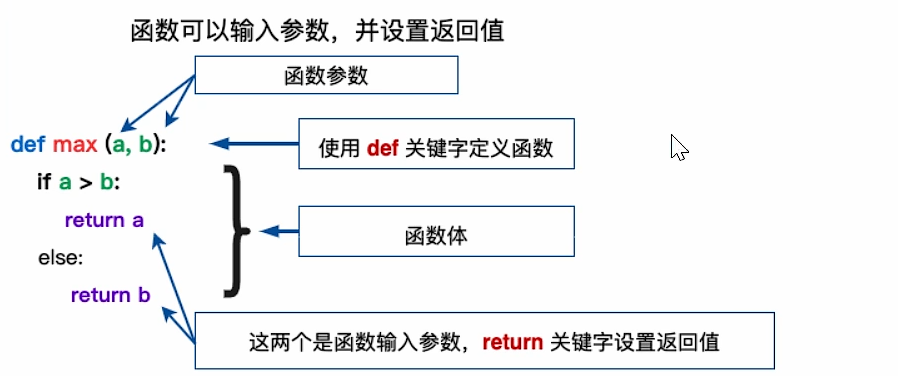
- 函数代码块以
def关键字开头,后接函数标识符名称和圆括号()。 - 函数内容以冒号
:开始,并且缩进。 - 函数参数
(a, b),可以有多个,也可以没有,即直接是(),(a, b)也称为形参列表。 - 函数可以有返回值,也可以没有,如果没有 return 相当于返回 None。
函数的调用
- 函数定义好了,并不会自动执行,需要程序员调用,才会执行。
- 调用方式:函数名(实参列表),比如:max(10, 20)。
快速入门
# 自定义cry 函数,输出“喵喵喵”
# 定义函数
def cry():
print("喵喵喵")
# 调用函数
cry()
# 自定义cal01 函数,可以计算从 1+...+1000的结果
def cal01():
total = 0
for i in range(1, 1001):
total += i
print("total =", total)
cal01()
# 自定义cal02 函数,该函数可以接收一个n,计算从 1+...+n 的结果
def cal02(n):
total = 0
for i in range(1, n + 1):
total += i
print("total =", total)
# (10) 表示我调用函数时,出入了实参 10,即把10赋给了形参n:n = 10
cal02(10)
# 自定义get_sum 函数,可以计算两个数的和,并返回结果
def get_sum(num1, num2):
return num1 + num2
"""
1.调用get_sum(10, 50) 调用get_sum
2.(10, 50) 表示传入了两个实参10, 50,把10赋给num1,把50赋给num2
3.result 就是接收get_sum 函数返回的结果
"""
result = get_sum(20, 30)
print("result =", result)
# 使用函数解决计算问题
def cal04():
n1 = float(input("请输入第一个数:"))
n2 = float(input("请输入第二个数:"))
oper = input("请输入运算符 + - * / :")
res = 0.0
if oper == "+":
res = n1 + n2
elif oper == "-":
res = n1 - n2
elif oper == "*":
res = n1 * n2
elif oper == "/":
res = n1 / n2
else:
print("输入的运算符错误")
print(n1, oper, n2, "=", res)
cal04()
函数的调用机制
函数调用过程
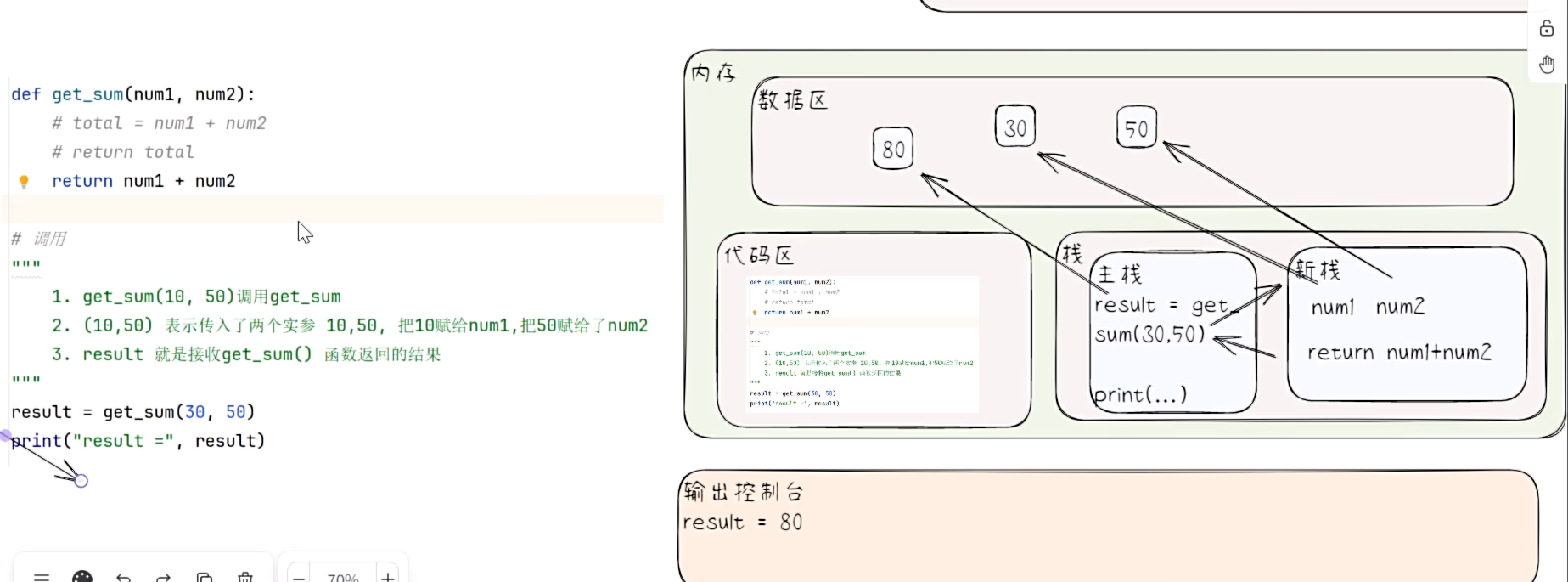
return 语句
- 基本语法
def 函数名(参数列表):
语句...
return 返回值
- 说明:如果没有 return 语句,默认返回
None,None是 内置常量,通常用来代表空值的对象。
def f1():
print("hi")
result = f1()
# r: None <class 'NoneType'> 140736690859152
print("r:", result, type(result), id(result))
函数注意事项和使用细节
-
函数的参数列表可以是多个,也可以没有,如:
(),(n1, n2...)。 -
函数的命名规范遵循标识符命名规则和规范,具体参考前面讲过的标识符命名规则和规范。
-
函数中的变量是局部的,函数外不生效。
def hi():
n = 10
print("n:", n)
hi()
# 函数内部定义的n,在函数外部不能使用
# print("n:", n)
- 如果同一个文件,出现两个函数名相同的函数,则以就近原则进行调用。
def cry():
print("hi")
def cry():
print("ok")
# 这个ry会默认就近原则,即第二个cry(),输出OK。
cry()
- 调用函数时,根据函数定义的参数位置来传递参数,这种传参方式就是位置参数,传递的实参和定义的形参顺序和个数必须一致,同时定义的形参,不用指定数据类型,会根据传入的实参决定。
def car_info(name, price, color):
print(f"name: {name}, price: {price}, color: {color}")
# 传递的实参和定义的形参顺序和个数必须一致,否则报 TypeError 错误
# car_info("宝马", 500000, "red", 1) # TypeError: car_info() takes 3 positional arguments but 4 were given
car_info("宝马", 500000, "red")
- 函数可以有多个返回值,返回数据类型不受限制。
def f2(n1, n2):
return n1 + n2, n1 - n2
r1, r2 = f2(10, 20)
print(f"r1: {r1}, r2: {r2}")
- 函数支持关键字参数。
- 函数调用时,可以通过
形参名=实参名形式传递参数。这样可以不受参数传递顺序的限制。
def book_info(name, price, author, amount):
print(f"name: {name}, price: {price}, author: {author}, amount: {amount}")
# 通常调用方式,一一对应
book_info("红楼梦", 60, "曹雪芹", 30000)
# 关键字参数
book_info(name="红楼梦", price=60, amount=60000, author="曹雪芹")
book_info("红楼梦", 60, amount=90000, author="曹雪芹")
- 函数支持默认参数/缺省参数
- 定义函数时,可以给函数提供默认值,调用函数时,指定了实参,则以指定为准,没有指定,则以默认值为准。默认参数放在参数列表后。
# 定义函数时,可以给参数提供默认值,调用函数时,指定了实参,则以指定为准,没有指定,则以默认值为准
def book_info2(name="<<thinking in python", price=66.8, author="龟叔", amount=1000):
print(f"name: {name}, price: {price}, author: {author}, amount: {amount}")
book_info2()
book_info2("<<study python>>")
# 默认参数,需要放在参数列表后
def book_info3(name, price, author="龟叔", amount=1000):
print(f"name: {name}, price: {price}, author: {author}, amount: {amount}")
book_info3("<<python 揭秘>>", 999)
- 函数支持可变参数/不定长参数
- 应用场景:当调用函数时,不确定传入多个实参的情况。
- 传入的多个实参,会被组成一个元组。元组可以存储多个数据项。
# 计算多个数的和,不是不确定是几个数,*表示[0到多],使用可变参数/不定长参数(*args)
def sum(*args):
print(f"args: {args} 类型:{type(args)}")
total = 0
for els in args:
total += els
return total
result1 = sum()
print(result1)
result2 = sum(1, 3, 5)
print(result2)
- 函数的可变参数/不定长参数,还支持多个关键字参数,也就是多个
形参名=实参值。
- 应用场景:当调用函数时,不确定传入多少个关键字的情况。
- 传入的多个关键字参数,会被组成一个字典。字典可以存储多个
键=值的数据项。
# 接收一个人的信息,但是有哪些信息是不确定的,就可以使用关键字可变参数(**kwargs)
def person_info(**kwargs):
print(f"kwargs: {kwargs} 类型:{type(kwargs)}")
for kwargs_name in kwargs:
print(f"参数名:{kwargs_name} 参数值:{kwargs[kwargs_name]}")
person_info(name="hsp", age=18, email="hsp@qq.com")
person_info(name="hsp", age=18, email="hsp@qq.com", sex="男", address="北京")
person_info()
- Python 调用另一个.py 文件的函数
# f1.py
def add(x, y):
print("x + y =", x + y)
# f2.py
# f2.py使用f1.py的函数
# 导入f1.py(模块),就可以使用
import f1
f1.add(10, 30)
函数的传参机制
字符串和数值类型传参机制
- 字符串和数值类型是不可变数据类型,当对应的变量的值发生了变化,它对应的内存地址会发生改变。
- 数值传参机制
- 代码演示
# 字符串和数值类型传参机制
def f1(a):
print(f"f1() a的值:{a} 地址是:{id(a)}")
a += 1
print(f"f1() a的值:{a} 地址是:{id(a)}")
a = 10
print(f"调用f1()前 a的值:{a} 地址是:{id(a)}")
f1(a)
print(f"调用f1()后 a的值:{a} 地址是:{id(a)}")
- 代码执行内存分析法
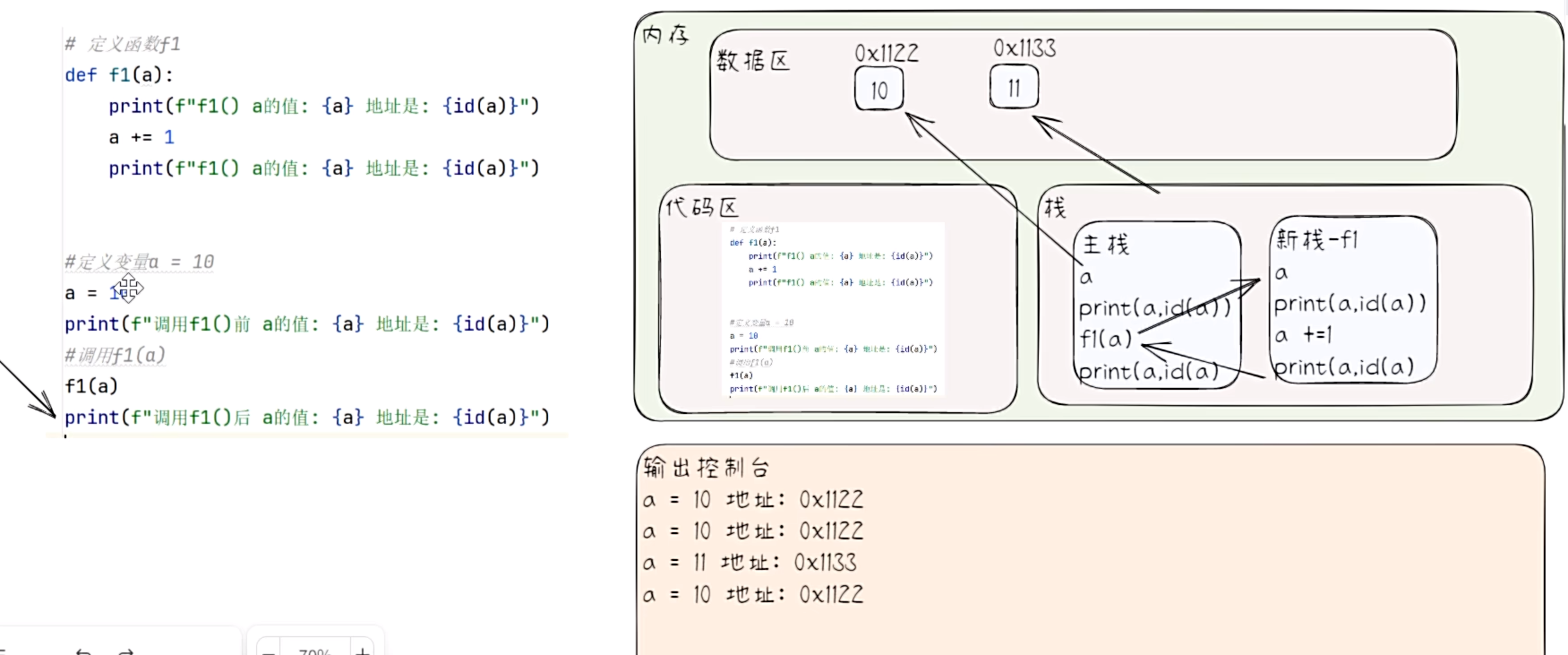
- 字符串传参机制
def f2(name):
print(f"f2() name:{name} 地址是:{id(name)}")
name += "hi"
print(f"f2() name的值:{name} 地址是:{id(name)}")
name = "tom"
print(f"调用f2()前 name的值:{name} 地址是:{id(name)}")
f2(name)
print(f"调用f2()后 name的值:{name} 地址是:{id(name)}")
list、tuple、set 和 dict 传参机制
- 代码展示
def f1(my_list):
print(f"②f1() my_list: {my_list} 地址:{id(my_list)}")
my_list[0] = "jack"
print(f"③f1() my_list: {my_list} 地址:{id(my_list)}")
print("-" * 30 + "list" + "-" * 30)
my_list = ["tom", "mary", "hsp"]
print(f"①my_list: {my_list} 地址:{id(my_list)}")
f1(my_list)
print(f"④my_list: {my_list} 地址:{id(my_list)}")
def f2(my_tuple):
print(f"②f2() my_tuple: {my_tuple} 地址:{id(my_tuple)}")
print(f"③f2() my_tuple: {my_tuple} 地址:{id(my_tuple)}")
print("-" * 30 + "tuple" + "-" * 30)
my_tuple = ("hi", "ok", "hello")
print(f"①my_tuple: {my_tuple} 地址:{id(my_tuple)}")
f2(my_tuple)
print(f"④my_tuple: {my_tuple} 地址:{id(my_tuple)}")
def f3(my_set):
print(f"②f3() my_set: {my_set} 地址:{id(my_set)}")
my_set.add("红楼")
print(f"③f3() my_set: {my_set} 地址:{id(my_set)}")
print("-" * 30 + "set" + "-" * 30)
my_set = {"水浒", "西游", "三国"}
print(f"①my_set: {my_set} 地址:{id(my_set)}")
f3(my_set)
print(f"④my_set: {my_set} 地址:{id(my_set)}")
def f4(my_dict):
print(f"②f4() my_dict: {my_dict} 地址:{id(my_dict)}")
my_dict['address'] = "兰若寺"
print(f"③f4() my_dict: {my_dict} 地址:{id(my_dict)}")
print("-" * 30 + "dict" + "-" * 30)
my_dict = {"name": "小倩", "age": 18}
print(f"①my_dict: {my_dict} 地址:{id(my_dict)}")
f4(my_dict)
print(f"④my_dict: {my_dict} 地址:{id(my_dict)}")
- 代码执行内存分析法
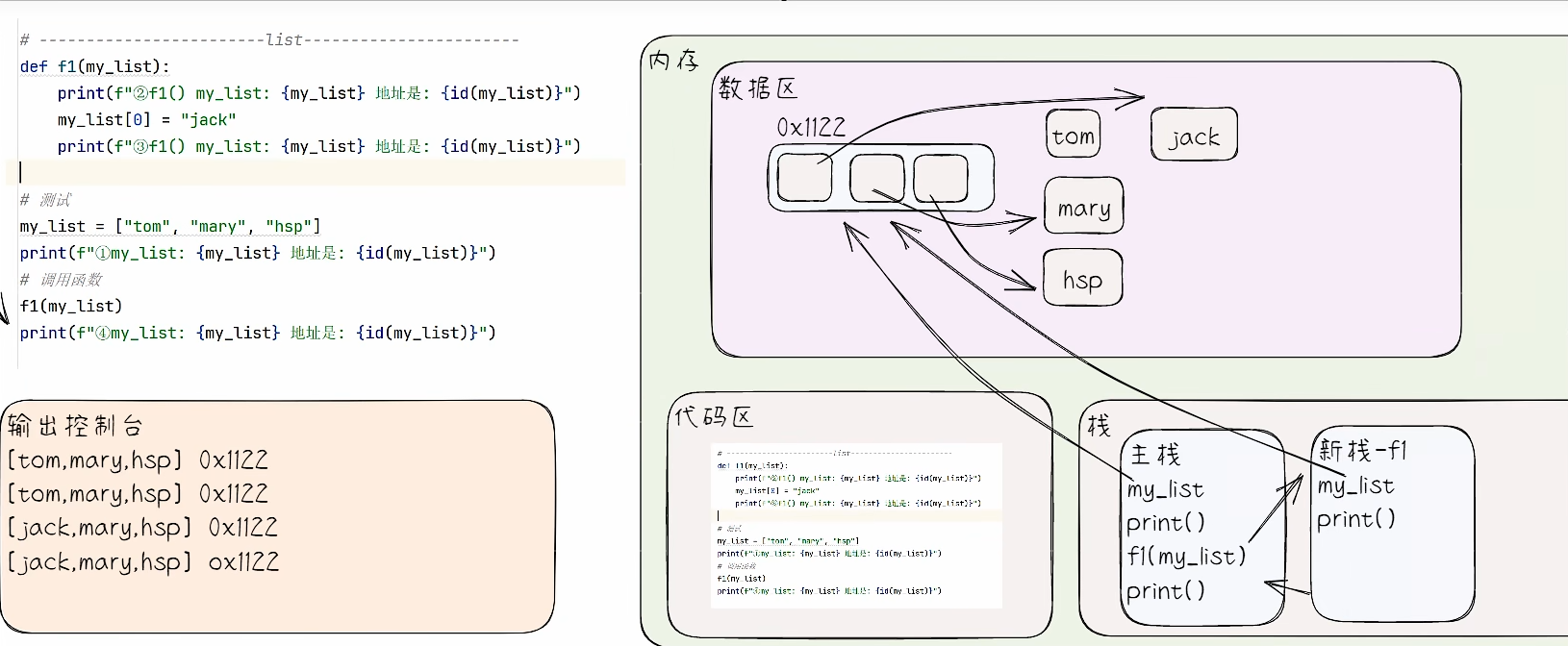
小结
- python 数据类型主要有整型 int / 浮点型 float / 字符串 str / 布尔值 bool / 元组 tuple / 列表 list / 字典 dict / 集合 set,数据类型分为两个大类,一种是可变数据类型,一种是不可变数据类型。
- 可变数据类型和不可变数据类型。
- 可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址不变,那么这个数据类型就是可变数据类型。
- 不可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址改变了,那么这个数据类型就是不可变数据类型。
- python 的数据类型。
- 不可变数据类型:数值类型(int、float)、bool(布尔)、string(字符串)、tuple(元组)。
- 可变数据类型:list(列表)、set(集合)、dict(字典)。
递归机制
基本介绍
- 简单的说:递归就是函数自己调用自己,每次调用时传入不同的值。
- 递归有助于编程者解决复杂问题,同时可以让代码变得简洁。
递归能解决什么问题
- 各种数学问题:8 皇后、汉诺塔、阶乘问题、迷宫问题…
- 各种算法中也会使用到递归,比如:快排,归并排序,二分查找,分治算法。
- 将用栈解决的问题 -> 递归代码比较整洁。
递归举例
- 以下代码输出结果是什么?
- 代码演示
def test(n):
if n > 2:
test(n - 1)
print("n =", n)
test(4)
- 代码执行内存分析法
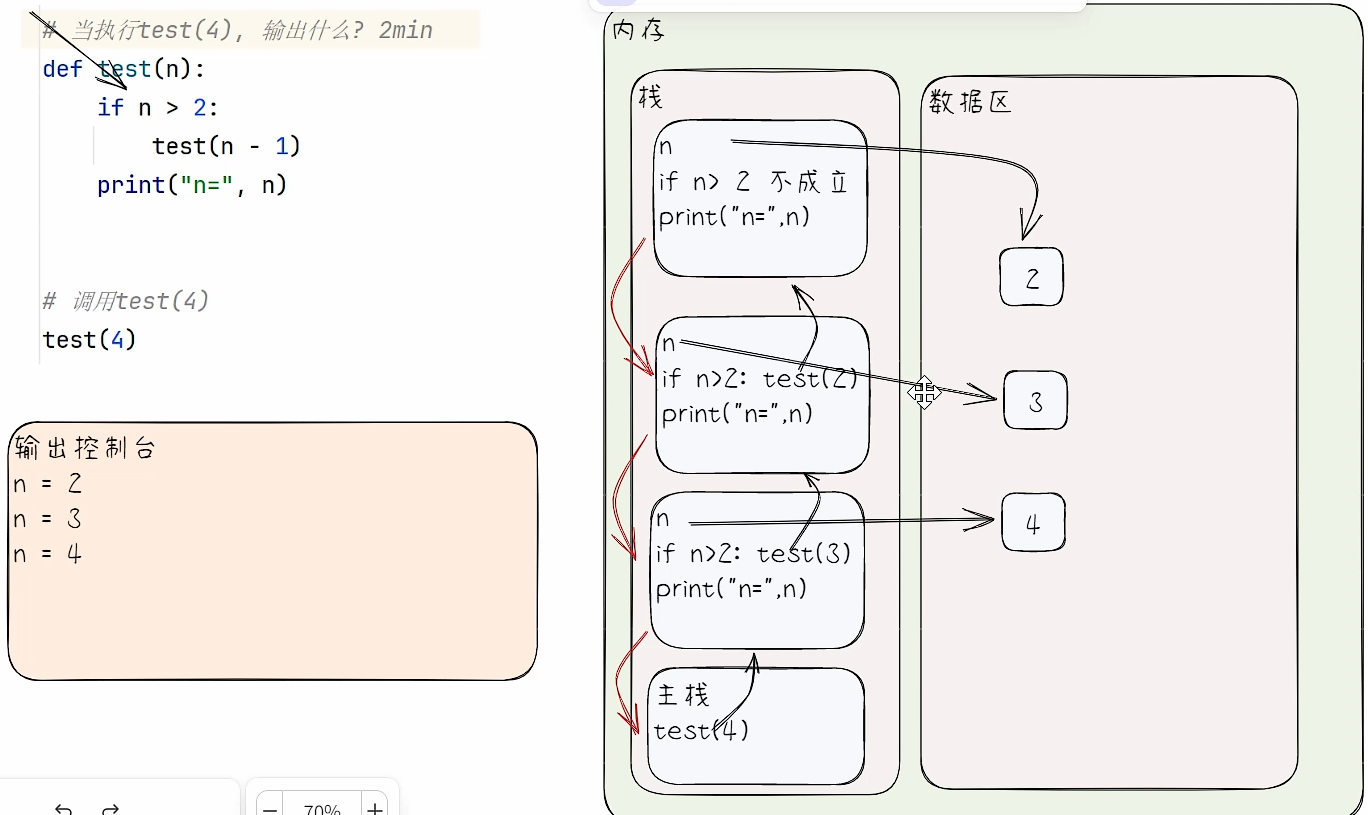
- 阶乘问题
- 代码演示
# 阶乘
def factorial(n):
if n == 1:
return 1
else:
return factorial(n - 1) * n
print(factorial(4))
- 代码执行内存分析法
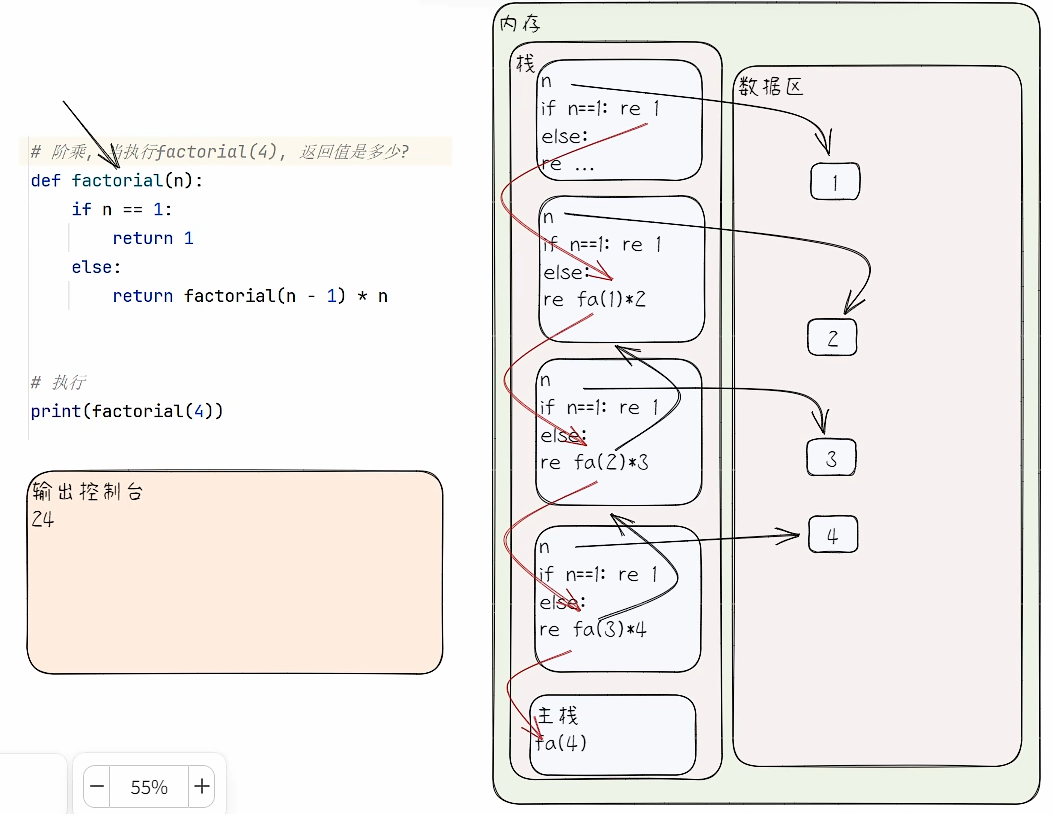
递归重要规则
- 执行一个函数时,就创建一个新的空间(栈空间)。
- 函数的变量是独立的,比如 n 变量。
- 递归必须向退出递归的条件逼近,否则就是无线递归,就会出现
RecursionError: maximum recursion depth exceeded超出最大递归深度。 - 当一个函数执行完毕,或者遇到 return,就好返回,遵守谁调用,就将结果返回给谁。
练习
- 请使用递归的方式,求出斐波那契数 1,1,2,3,5,8,13… 给你一个整数 n,求出它的值是多少?
# 斐波那契数
def fbn(n):
"""
功能:返回n对应的斐波那契数
:param n: 接收一个整数 n>=1.
:return: 返回斐波那契数
"""
if n == 1 or n == 2:
return 1
else:
return fbn(n - 1) + fbn(n - 2)
print(fbn(7))
- 猴子吃桃问题:有一堆桃子,猴子第一天吃了其中的一半,并在多吃了一个。以后每天猴子都吃其中的一半,然后再多吃一个。当到第 10 天时,想再吃时(即还没吃),发现只有 1 个桃子了。问最初共多少个桃子?
# 猴子吃桃
"""
day == 10,桃子树:1
day == 9, 桃子树:(day10的桃子树+1)*2
...
"""
def peach(day):
if day == 10:
return 1
else:
return (peach(day + 1) + 1) * 2
print(peach(1))
- 求函数值,已知 f(1) = 3; f(n)= 2*f(n-1)+1;请使用递归的思想,求出 f(n)的值?
# f(n)
def f(n):
if n == 1:
return 3
else:
return 2 * f(n - 1) + 1
print(f(10))
- 汉诺塔
def hanoi_tower(num, a, b, c):
"""
输出指定num个盘子移动的顺序
:param num: 指定盘子数
:param a: A柱
:param b: B柱
:param c: C柱
"""
if num == 1:
print(f"第1个盘从:{a}->{c}")
else:
# 有多个盘,我们认为只有两个,上面所有的盘和最下面的盘
# 移动上面所有的盘到B柱子,这个过程会借助到C柱子
hanoi_tower(num - 1, a, c, b)
# 移动最下面的盘
print(f"第{num}个盘从:{a}->{c}")
# 把上面所有的盘从B柱子移动到C柱子,这个过程会使用到A柱子
hanoi_tower(num - 1, b, a, c)
hanoi_tower(3, "A", "B", "C")
函数作为参数传递
应用实例
# 定义一个函数,可以返回两个数的最大值
def get_max_val(num1, num2):
max_val = num1 if num1 > num2 else num2
return max_val
def f1(fun, num1, num2):
"""
功能:调用fun返回num1和num2的最大值
:param fun: 表示接收一个函数
:param num1: 传入一个数
:param num2: 传入一个数
:return: 返回最大值
"""
return fun(num1, num2)
def f2(fun, num1, num2):
"""
功能:调用fun返回num1和num2的最大值,同时返回两个数的和
:param fun:
:param num1:
:param num2:
:return:
"""
return num1 + num2, fun(num1, num2)
print(f1(get_max_val, 10, 20))
print(f2(get_max_val, 10, 20))
x, y = f2(get_max_val, 10, 20)
print(f"x: {x}, y: {y}")
注意事项和细节
- 函数作为参数传递,传递的不是数据,而是业务处理逻辑。
- 一个函数,可以接收多个函数作为参数传入。
# f3接收多个函数作为参数传入
def f3(my_fun, num1, num2, my_fun2):
return my_fun2(num1, num2), my_fun(num1, num2)
# 定义一个函数,可以返回两个数的最大值
def get_max_val(num1, num2):
max_val = num1 if num1 > num2 else num2
return max_val
# 定义函数,可以返回两个数的和
def get_sum(num1, num2):
return num1 + num2
print(f3(get_max_val, 100, 200, get_sum))
lambda 匿名函数
基本介绍
- 基本介绍
- 如果我们有这样一个需求,需要将函数作为参数进行传递,但是这个函数只使用一次,这时,我们可以考虑使用 lambda 匿名函数。
- 函数的定义
- def 关键字,可以定义带有名称的函数,可以重复使用。
- lambda 关键字,可以定义匿名函数(无名称),匿名函数只能使用一次。
- 匿名函数用于临时创建一个函数,只使用一次的场景。
- 匿名函数基本语法
- lambda 形参列表:函数体(一行代码)。
- lambda 关键字,表示定义匿名函数。
- 形参列表:比如 num1,num2 表示接收两个参数。
- 函数体:完成的功能,只能写一行,不能写多行代码。
应用实例
def f1(fun, num1, num2):
"""
功能:调用fun返回num1和num2的最大值
:param fun: 接收函数(匿名的)
:param num1:
:param num2:
:return:
"""
print(f"fun类型:{type(fun)}")
return fun(num1, num2)
"""
1. lambda a, b: a if a > b else b
2. 不需要return, 运算结果就是返回值
"""
max_value = f1(lambda a, b: a if a > b else b, 1, 2)
print(max_value)
全局变量和局部变量
基本介绍
- 基本介绍
- 全局变量:在整个程序范围内都可以访问,定义在函数外,拥有全局作用域的变量。
- 局部变量:只能在其被声明的函数范围内访问,定义在函数内部,拥有局部作用域的变量。
- 代码演示
# n1 是全局变量
n1 = 100
def f1():
# n2是局部变量
n2 = 200
print(n2)
# 可以访问全局变量n1
print(n1)
# 调用
f1()
print(n1)
# 不能访问局部变量n2
# print(n2) # NameError: name n2' is not defined.
注意事项和细节
- 未在函数内部重新定义 n1,那么默认使用全局变量 n1。
- 在函数内部重新定义了 n1,那么根据就近原则,使用的就是函数内部重新定义的 n1。
n1 = 100
def f1():
# n1 重新定义了
n1 = 200
print(n1)
f1()
print(n1)
- 在函数内使用 global 关键字,可以标明指定使用全局变量。
n1 = 100
def f1():
# global 关键字标明使用全局变量 n1
global n1
n1 = 200
print(n1)
f1()
print(n1)
数据容器
基本介绍
- 数据容器是一种数据类型,有些地方也简称容器/collections。
- 数据容器可以存放多个数据,每一个数据也被称为一个元素。
- 存放的数据/元素可以是任意类型。
- 简单的说,数据容器就一种可以存放多个数据/元素的数据类型。
列表(list)
基本介绍
- 列表可以存放多个不同数据类型,即:列表就是一列数据(多个数据)。
- 列表也是一种数据类型。
列表的定义
- 列表的定义:创建一个列表,只要用逗号分隔不同的数据项使用方括号括起来即可,示例如下:
list1 = [100, 200, 300, 400, 500]
list2 = ["red", "green", "blue", "yellow", "white", "black"]
- 列表内存图
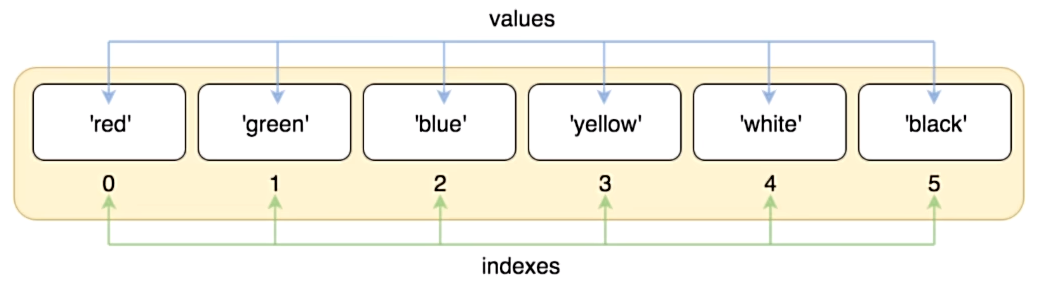
# 列表的定义
list1 = [100, 200, 300, 400, 500]
print(list1)
print(type(list1))
列表的使用
-
列表的使用方法:
列表名 [下标] -
注意:索引是从 0 开始计算的。
list2 = ["red", "green", "blue", "yellow", "white", "black"]
print(list2)
print(f"第三个元素是:{list2[2]}")
列表的遍历
- 简单来说,列表的遍历就是将列表的每个元素以此取出,进行处理的操作,就是遍历/迭代。
# 内置函数 len()可以返回对象的长度(元素个数)。
list_color = ["red", "green", "blue", "yellow", "white", "black"]
index = 0
while index < len(list_color):
print(f"第{index + 1}个元素是:{list_color[index]}")
index += 1
list_color = ["red", "green", "blue", "yellow", "white", "black"]
for ele in list_color:
print(f"元素是:{ele}")
列表解决养鸡场问题
hens = [3, 5, 1, 3.4, 2, 50]
total_weight = 0.0
for ele in hens:
total_weight += ele
print(f"总体重:{total_weight} 平均体重:{round(total_weight/len(hens), 2)}")
注意事项和使用细节
- 如果我们需要一个空列表,可以通过
[]或list()方式来定义。
list1 = []
list2 = list()
print(list1, type(list1))
print(list2, type(list2))
- 列表的元素可以有多个,而且数据类型没有限制,允许有重复元素,并且是有序的。
list3 = [100, "jack", 4.5, True, "jack"]
print(list3)
# 嵌套列表
list4 = [100, "tom", ["天龙八部", "笑傲江湖", 300]]
print(list4)
-
列表的索引/下标是从 0 开始的。
-
列表索引必须在指定范围内使用,否则报 IndexError: list index out of range。
list5 = [1, 2]
print(list5[2]) # IndexError: list index out of range
- 索引也可以从尾部开始,最后一个元素的索引为-1, 往前一位为-2,以此类推。
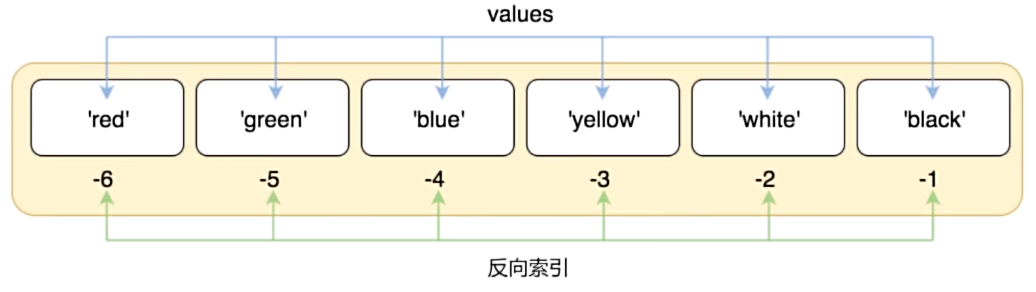
list6 = ["red", "green", "blue", "yellow", "white", "black"]
print(list6[-1])
print(list6[-6])
# 依然不能索引越界
print(list6[-7]) # IndexError: list index out of range
- 通过
列表[索引]=新值对数据进行更新,使用列表.append(值)方法来添加元素,使用del语句来删除列表的元素,注意不能超出有效索引范围。
list_a = ["天龙八部", "笑傲江湖"]
print("list_a:", list_a)
list_a[0] = "雪山飞狐"
print("list_a:", list_a)
list_a.append("倚天屠龙")
print("list_a:", list_a)
del list_a[1]
print("list_a:", list_a)
- 列表是可变序列(要注意其使用特点)。
# 列表是可变序列(要注意其使用特点)。
list1 = [1, 2.1, "hsp"]
print(f"list1: {list1} 地址:{id(list1)} 第三个元素地址 {id(list1[2])}")
list1[2] = "python"
print(f"list1: {list1} 地址:{id(list1)} 第三个元素地址 {id(list1[2])}")
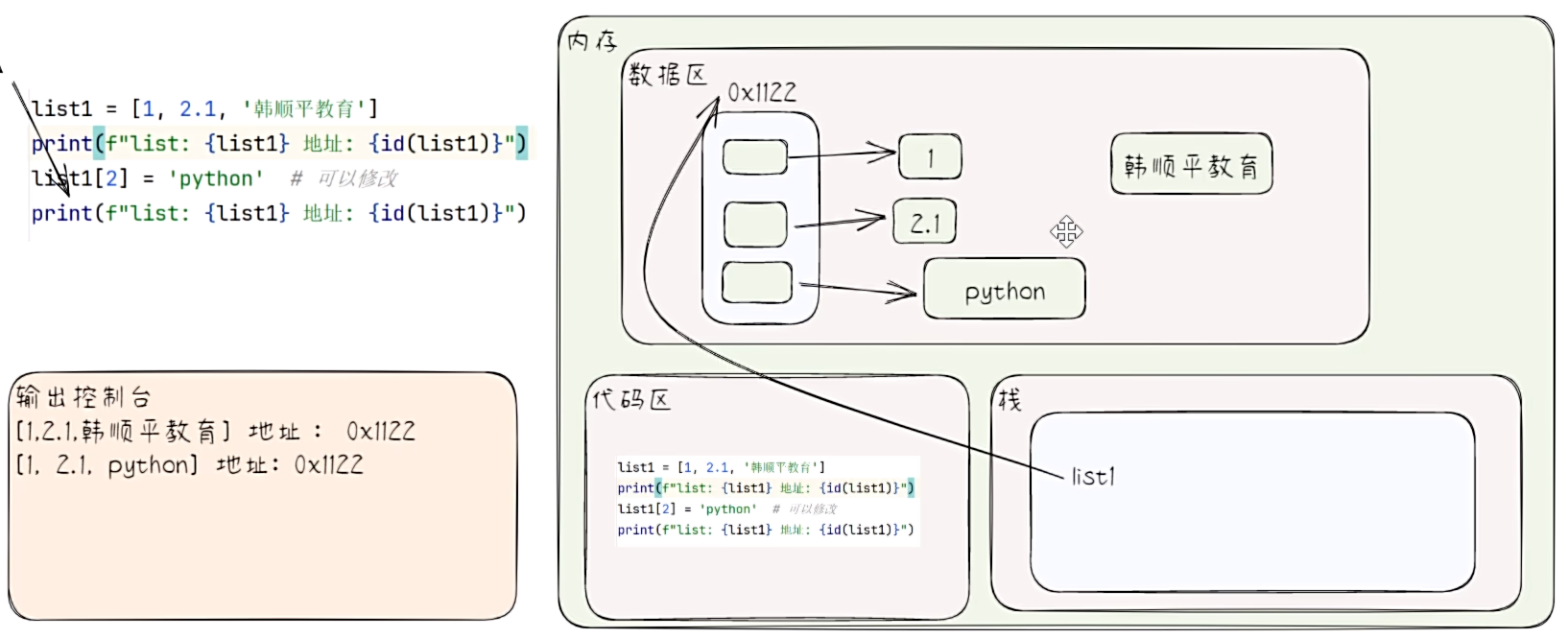
- 列表在赋值时的特点
# 扩展一下,列表在赋值时的特点
list1 = [1, 2.1, "hsp"]
list2 = list1
list2[0] = 500
print("list2:", list2)
print("list1:", list1)
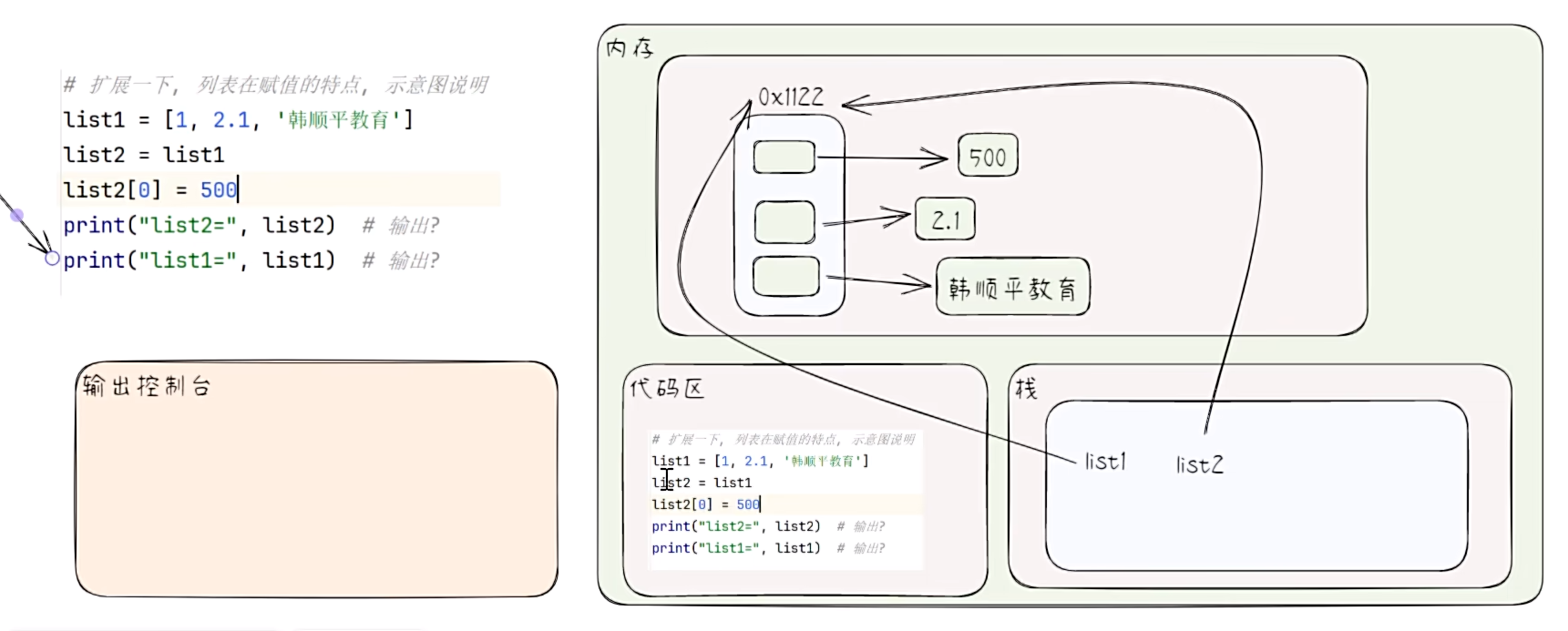
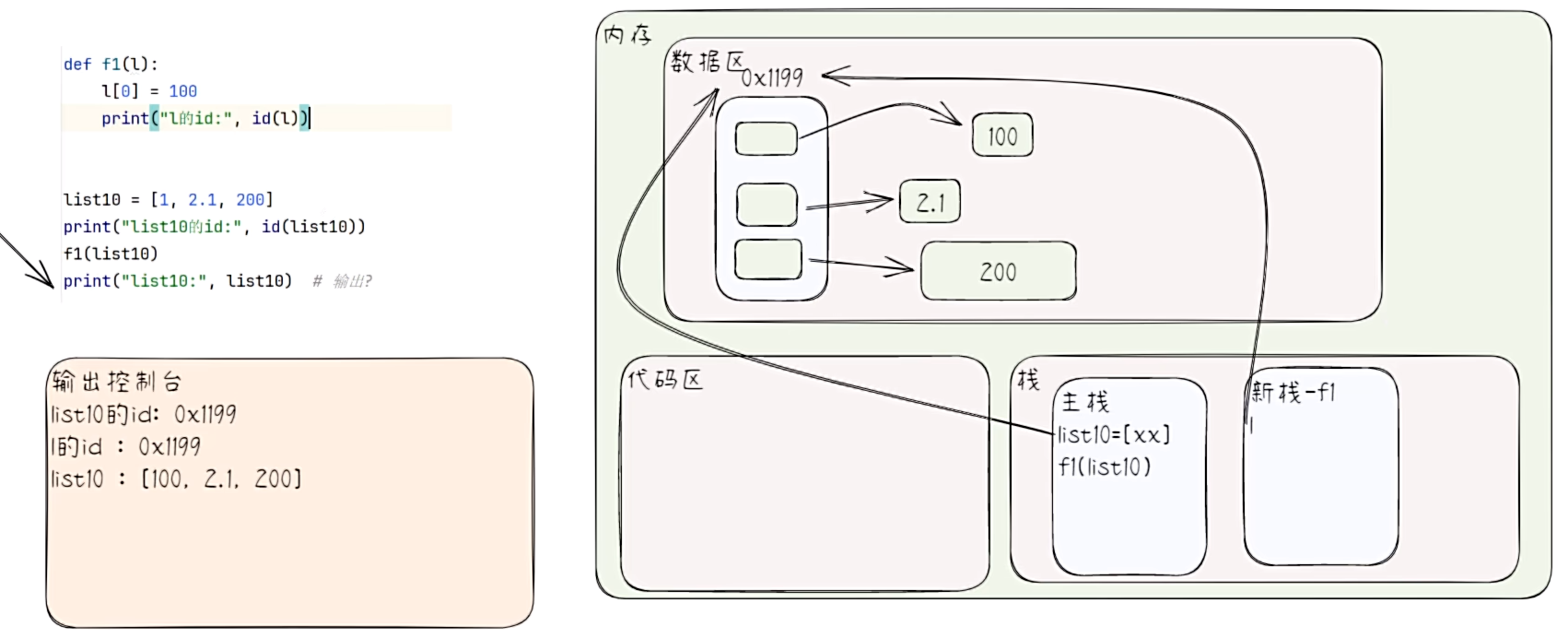
- 列表在函数传参时的特点
# 列表在函数传参时的特点
def f1(l):
l[0] = 100
print("l的id:", id(l))
list10 = [1, 2.1, 200]
print("list10的id:", id(list10))
f1(list10)
print("list10:", list10)
列表的常用操作
- 列表常用操作](https://docs.python.org/zh-cn/3/library/stdtypes.html#lists)
- 常用操作一览
| 序号 | 函数 |
|---|---|
| 1 | len(list):列表元素个数 |
| 2 | max(list):返回列表元素最大值 |
| 3 | min(list):返回列表元素最小值 |
| 4 | list(seq):将元组转换成列表 |
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj):在列表末尾添加新的对象 |
| 2 | list.count(obj):统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj):从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj):将对象插入列表 |
| 6 | list.pop([index =-1]):移除列表中的一个元素(默认最后一个元素),并返回该元素的值 |
| 7 | list.remove(obj):移除列表中某个值的第一个匹配项 |
| 8 | list.reverse():反向列表中元素 |
| 9 | list.sort(key = None, reverse = False):对原列表进行排序 |
| 10 | list.clear():清空列表 |
| 11 | list.copy():复制列表 |
- 演示列表常用操作
# 演示列表常用操作
list_a = [100, 200, 300, 400, 600]
print("list_a 列表元素个数:", len(list_a))
print("list_a 列表最大元素:", max(list_a))
print("list_a 列表最小元素:", min(list_a))
# list.append(obj):在列表末尾添加新的对象
list_a.append(900)
print("list_a:", list_a)
# list.count(obj):统计某个元素在列表中出现的次数
print("100出现的次数:", list_a.count(100))
# list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list_b = [1, 2, 3]
list_a.extend(list_b)
print("list_a:", list_a)
# list.index(obj):从列表中找出某个值第一个匹配项的索引位置
print("300第1次出现在序列的索引是:", list_a.index(300))
# 如果找不到,会报错:ValueError
# print("1000第1次出现在序列的索引是:", list_a.index(1000)) # ValueError: 1000 is not in list
# list.insert(index, obj):将对象插入列表
list_a.insert(1, 666)
print("list_a:", list_a)
# list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并返回该元素的值
print(list_a.pop())
print("list_a:", list_a)
# list.remove(obj):移除列表中某个值的第一个匹配项 |
list_a.remove(666)
print("list_a:", list_a)
# list.reverse():反向列表中元素
list_a.reverse()
print("list_a:", list_a)
# list.sort(key=None, reverse=False):对原列表进行排序
list_a.sort()
print("list_a:", list_a)
# list.copy():复制列表
list_c = list_a.copy()
print("list_c:", list_a)
# list.clear():清空列表
list_a.clear()
print("list_a:", list_a)
- 列表生成式
- 列表生成式就是“生成列表的公式”
- 基本语法
[列表元素的表达式 for 自定义变量 in 可迭代对象]
- 案例演示
# 列表生成式
list_1 = [ele * 2 for ele in range(1, 5)]
print("list_1:", list_1) # list_1: [2, 4, 6, 8]
list2 = [ele + ele for ele in "hsp"]
print("list2:", list2) # list2: ['hh', 'ss', 'pp']
list3 = [ele * ele for ele in range(1, 11)]
print("list3:", list3)
练习
# 循环从键盘输入5个成绩,保存到列表,并输出。
scores = []
for _ in range(5):
score = float(input("请输入成绩:"))
scores.append(score)
print(f"成绩情况:{scores}")
元组(tuple)
基本介绍
- 元组(tuple)可以存放多个不同类型数据,元组是不可变序列。
- tuple 不可变是指当你创建了 tuple 时,它就不能改变了,也就是说它没有 append(),insert() 这样的方法,但它也有获取某个索引值的方法,但是不能重新复制。
- 元组也是一种数据类型。
元组的定义
- 创建一个元组,只要把逗号分隔不同的数据线,使用圆括号括起来即可。
# 元组的定义
tuple_a = (100, 200, 300, 400, 500)
print("tuple_a =", tuple_a, type(tuple_a))
元组的使用
- 元组使用语法:
元组名[索引]
# 元组的使用
tuple_b = ("red", "green", "blue", "yellow", "white", "black")
print("第三个元素是:", tuple_b[2])
元组的遍历
- 简单来说,就是将元组的每个元素以此取出,进行处理的操作,就是遍历/迭代。
# while 遍历元组
tuple_color = ("red", "green", "blue", "yellow", "white", "black")
index = 0
while index < len(tuple_color):
print(tuple_color[index])
index += 1
# for 变量元组
tuple_color = ("red", "green", "blue", "yellow", "white", "black")
for ele in tuple_color:
print(ele)
注意事项和使用细节
- 如果我们需要一个空元组,可以通过(),或者 tuple() 方式来定义。
tuple_a = ()
tuple_b = tuple()
print(f"tuple_a : {tuple_a}")
print(f"tuple_b : {tuple_b}")
- 元组的元素可以有多个,而且数据类型没有限制(甚至可以嵌套元组),允许有重复元素,并且是有序的。
tuple_c = (100, "jack", 4.5, True, "jack")
print(f"tuple_c : {tuple_c}")
# 嵌套元组
tuple_d = (100, "tom", ("天龙八部", "笑傲江湖", 300))
print(f"tuple_d : {tuple_d}")
- 元组的索引/下标是从 0 开始的。
- 元组索引必须在指定范围内使用,否则报:IndexError: tuple index out of range 。
tuple_e = (1, 2.1, "hsp")
print(tuple_e[1])
# 索引越界
print(tuple_e[3]) # IndexError: tuple index out of range
- 元组是不可变序列。
tuple_f = (1, 2.1, "hsp")
# 不能修改
# tuple_f[2] = "python" # TypeError: 'tuple' object does not support item assignment
- 可以修改元组内 list 的内容(包括修改、增加、删除等)
tuple_g = (1, 2.1, "hsp", ["jack", "tom", "mary"])
print(tuple_g[3])
print(tuple_g[3][0])
# 修改
tuple_g[3][0] = "HSP"
print(tuple_g)
# 不能替换整个列表元素
# tuple_g[3] = [10, 20] # TypeError: 'tuple' object does not support item assignment
# 删除
del tuple_g[3][0]
print(tuple_g)
# 增加
tuple_g[3].append("smith")
print(tuple_g)
- 索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
tuple_h = (1, 2.1, "hsp", ["jack", "tom", "mary"])
print(tuple_h[-2])
- 定义只有一个元素的元组,需要带上逗号,否则就不是元组类型。
tuplg_i = (100,)
print(f"tuplg_i : {tuplg_i}", type(tuplg_i))
# 输出 tuplg_i : (100,) <class 'tuple'>
tuplg_j = (100)
print(f"tuplg_j : {tuplg_j}", type(tuplg_j))
# 输出 tuplg_j : 100 <class 'int'>
- 既然有了列表,python 设计者为什么还提供元组这样的数据类型呢?
- 在项目中,尤其是多线程环境中,有经验的程序员会考虑使用不变对象(一方面因为对象状态不能修改,索引可以避免由此引起的不必要的程序错误;另一方面一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。可以方便的被共享访问)。所以,如果不需要对元素进行添加、删除、修改的情况下,可以考虑使用元组。
- 元组在创建时间和占用的空间什么都优于列表。
- 元组能够对不需要修改的数据写保护。
元组的常用操作
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(tuple):元组元素个数 |
| 2 | max(tuple):返回元组元素最大值 |
| 3 | min(tuple):返回元组元素最小值 |
| 4 | tuple.count(obj):统计某个元素在元组中出现的次数 |
| 5 | tuple.index(obj):从元组中找出某个值第一个匹配项的索引位置 |
# 演示元组常用操作
tuple_a = (100, 200, 300, 400, 600, 200)
print("tuple_a 元组元素个数:", len(tuple_a))
print("tuple_a 元组最大元素:", max(tuple_a))
print("tuple_a 元组最小元素:", min(tuple_a))
# tuple.count(obj):统计某个元素在列表中出现的次数
print("100出现的次数:", tuple_a.count(100))
print("200出现的次数:", tuple_a.count(200))
# tuple.index(obj):从列表中找出某个值第一个匹配项的索引位置
print("200第1次出现在元组的索引:", tuple_a.index(200))
# 如果找不到,会报错:ValueError: tuple.index(x): x not in tuple
# print("1000第1次出现在元组的索引:", tuple_a.index(1000)) # ValueError: tuple.index(x): x not in tuple
# x in s:s中的某项等于x 则结果为True,否则为False
print(300 in tuple_a) # True
练习
"""
定义一个元组:("大话西游", "周星驰", 80, ["周星驰", "小甜甜"])
信息为:(片名, 导演, 票价, 演员列表)
"""
tuple_move = ("大话西游", "周星驰", 80, ["周星驰", "小甜甜"])
print("票价对应的索引:", tuple_move.index(80))
# 遍历所有演员
for ele in tuple_move[3]:
print(ele)
# 删除 "小甜甜", 增加演员 "牛魔王",“猪八戒”
del tuple_move[3][1]
tuple_move[3].append("牛魔王")
tuple_move[3].append("猪八戒")
print(tuple_move)
字符串(str)
基本介绍
- 在 python 中处理文本数据是使用 str 对象,也称为字符串。字符串是由 Unicode 码位构成的不可变序列。
- Unicode 码是一种字符编码。
- ord():对表示单个 Unicode 字符的字符串,返回代表它 Unicode 码点的整数。例如
ord('a')返回整数97。 - chr():返回 Unicode 码位为整数 i 的字符的字符串格式。例如,
chr(97)返回字符串'a'。
- 字符串字面值有三种写法。
- 单引号:‘允许包含有“双”引号’。
- 双引号:“运行嵌入’单’引号”。
- 三重引号:‘’‘三重单引号’‘’,“” “三重双引号” “”,使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中。
- 字符串是字符的容器,一个字符串可以存放多个字符,比如 “hi-韩顺平教育”。
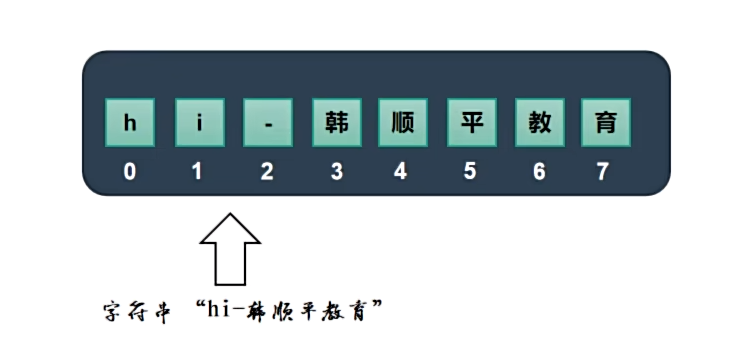
字符串支持索引
- 使用语法:
字符串名[索引]
str_a = "red-green"
print("str_a的第三个值/字符是:", str_a[2], type(str_a[2]))
字符串的变量
- 简单的说,就是将字符串的每个元素依次取出,进行处理的操作,就是遍历/迭代。
# 使用while和for遍历字符串
str_b = "hi-韩顺平教育"
index = 0
while index < len(str_b):
print(str_b[index])
index += 1
for ele in str_b:
print(ele)
注意事项和使用细节
- 字符串索引必须在指定范围内使用,否则报: 。索引也可以从尾部开始,最后一个元素的索引为-1,往前一位为-2,以此类推。
- 字符串是不可变序列,不能修改。
str_b = "hi-韩顺平教育"
# 通过索引可以访问指定元素
print(str_b[3])
# 不能修改元素
# str_b[3] = "李" # TypeError: 'str' object does not support item assignment
- 在 Python 中,字符串长度没有固定的限制,取决于计算机内存大小。
字符串常用操作
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(str):字符串的长度,也就是包含多少个字符 |
| 2 | str.replace(old, new [, count]):返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。如果给出了可选参数 count,则只替换前 count 次出现。 |
| 3 | str.split(sep = None, maxaplit =-1):返回一个由字符串内单词组成的列表,使用 seq 作为分隔字符串。如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有 maxsplit + 1 个元素)。如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分) |
| 4 | str.count(sub):统计指定字符串在字符串中出现的次数 |
| 5 | str.index(sub):从字符串中找出指定字符串第一个匹配项的索引位置 |
| 6 | str.strip([chars]):返回原字符串的副本,移除其中的前导和末尾字符。chars 为指定要移除字符的字符串 |
| 7 | str.lower():返回原字符串小写的副本 |
| 8 | str.upper():返回原字符串大写的副本 |
# 演示字符串常用操作
str_names = " jack tom mary hsp nono tom "
# len(str):字符串的长度,也就是包含多少个字符
print(f"{str_names}有{len(str_names)}个字符")
# str.replace(old, new[, count]):返回字符串的副本,其中出现的所有子字符串 old 都将被替换为 new。如果给出了可选参数 count,则只替换前 count 次出现。
# 说明:返回字符串的副本:表示原来的字符串不变,而是返回一个新的字符串。
str_names_new = str_names.replace("tom", "汤姆", 1)
print("str_names_new:", str_names_new)
print("str_names:", str_names)
# str.split(sep=None, maxaplit=-1):返回一个由字符串内单词组成的列表,使用 seq 作为分隔字符串。如果给出了 maxsplit,则最多进行 maxsplit 次拆分(因此,列表最多会有
# maxsplit + 1个元素)。如果 maxsplit 未指定或为 -1,则不限制拆分次数(进行所有可能的拆分)
str_names_split = str_names.split(" ")
print("str_names_split:", str_names_split, type(str_names_split))
# str.count(sub):统计指定字符串在字符串中出现的次数
print("tom出现的次数:", str_names.count("tom"))
# str.index(sub):从字符串中找出指定字符串第一个匹配项的索引位置
print(f"tom出现的索引:{str_names.index('tom')}")
# str.strip([chars]):返回原字符串的副本,移除其中的前导和末尾字符。chars 为指定要移除字符的字符串
# 说明:这个方法通常用于除去前后的空格,或者去掉制定的某些字符
str_names_strip = str_names.strip()
print("str_names_strip:", str_names_strip)
print("123t2om13".strip("123"))
# str.lower():返回原字符串小写的副本
str_names = "hspHaHa"
str_names_lower = str_names.lower()
print("str_names_lower:", str_names_lower)
# str.upper():返回原字符串大写的副本
str_names_upper = str_names.upper()
print("str_names_upper:", str_names_upper)
字符串比较
- 字符串比较
- 运算符:>,>=,<,<=,==,!=
- 比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的后续字符将不再比较。
- 比较原理:两个字符进行比较时,比较的是其
ordinal value(原始值/码值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符。
# ord()与chr()使用
print(ord('1'))
print(ord('A'))
print(ord('a'))
print(ord('h'))
print(chr(49))
print(chr(65))
print(chr(97))
print(chr(104))
# 字符串比较
print("tom" > "hsp")
print("tom" > "to")
print("tom" > "tocat")
print("tom" < "老韩")
print("tom" > "tom")
print("tom" <= "tom")
"""
定义一个字符串,str_names="tom jack mary nono smith hsp"
统计一共有多个人名;如果有"hsp"则替换成"老韩";如果人名是英文,则把首字母改为大写
str.capitalize():字符串首字符改为大写
"""
str_names = str("tom jack mary nono smith")
str_names_list = str_names.split(" ")
print(f"人名的个数:{len(str_names_list)}")
str_names_re = str_names.replace("hsp", "韩顺平")
print(str_names_re)
str_names_upper = ""
for ele in str_names_list:
if ele.isalpha():
str_names_upper += ele.capitalize() + " "
# 去掉两边的" "
str_names_upper = str_names_upper.strip(" ")
print(str_names_upper)
切片
基本介绍
- 切片:从一个序列中,取出一个子序列,在实际开发中,程序员经常对序列进行切片操作。
- 序列:序列是指,内容连续、有序,可使用索引的一类数据容器。
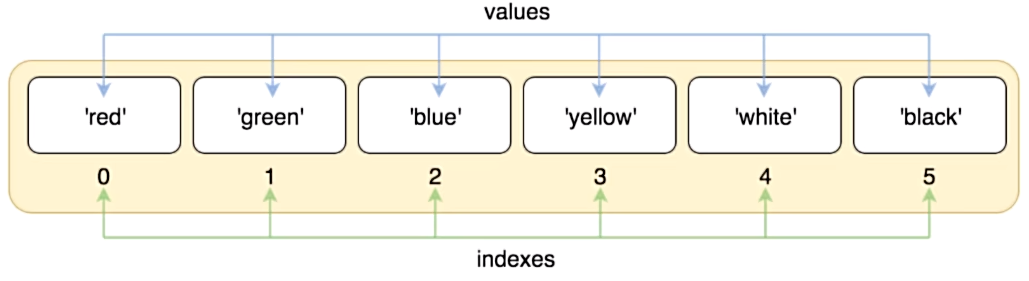
- 上文的列表(list)、元组(tuple)、字符串均可视为序列。
基本语法
- 基本语法:
序列[起始索引:结束索引:步长]- 表示从序列中,从指定的起始索引开始,按照指定的步长,依次取出元素,到指定结束索引为止,截取到一个新的序列。
- 切片操作是前闭后开,即
[其实索引:结束索引),截取的子序列包括起始索引,但是不包括结束索引。 - 步长表示,依次取出元素的间隔。
- 步长为 1:一个一个的取出元素;
- 步长为 2:每次跳过一个元素取出;
- 步长为 3,每次跳过 N-1 个元素取出。
# 字符串切片,截取"hello"
str_a = "hello,world"
print(str_a[0:5:1])
# 列表切片,截取["tom", "nono"]
list_a = ["jack", "tom", 'yoyo', "nono", "hsp"]
print(list_a[1:4:2])
# 元组切片,截取(200, 300, 400, 500)
tuple_a = (100, 200, 300, 400, 500, 600)
print(tuple_a[1:5:1])
注意事项和使用细节
- 切片语法:
序列[起始索引:结束索引:步长],起始索引如果不写,默认为 0,结束索引如果不写,默认截取到结果,步长如果不写,默认为 1。
str_a = "hello,hspjy"
str_slice01 = str_a[:5:1]
print("str_slice01", str_slice01)
str_slice02 = str_a[1::1]
print("str_slice02", str_slice02)
str_slice03 = str_a[::1]
print("str_slice03", str_slice03)
str_slice04 = str_a[2:5:]
print("str_slice04", str_slice04)
- 切片语法:
序列[起始索引:结束索引:步长],步长为负数,表示反向取,同时注意起始索引和结束索引也要反向标记。
str_b = "123456"
str_slice05 = str_b[-1::-1]
print("str_slice05", str_slice05)
str_slice06 = str_b[-1:-6:-1]
print("str_slice06", str_slice06)
- 切片操作并不会影响原序列,而是返回了一个序列。
str_c = "ABCD"
str_slice07 = str_c[1:3:1]
print("str_slice07", str_slice07)
print("str_c", str_c)
练习
# 定义列表 list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]
# 取出前三个名字;取出后三个名字,,并且保证原来顺序
list_name = ["Jack", "Lisa", "Hsp", "Paul", "Smith", "Kobe"]
list_name_f = list_name[0:3:1]
list_name_b = list_name[-1:-4:-1]
list_name_b.reverse()
print(f"前三个名字:{list_name_f}")
print(f"后三个名字:{list_name_b}")
集合(set)
基本介绍
- python 支持集合这种数据类型,集合是由不重复元素组成的无序容器。
- 不重复元素:集合中不会有相同的元素。
- 无序:集合中元素取出的顺序,和你定义时元素顺序并不能保证一致。
- 集合对象支持合集、交集、差集等数学运算。
- 既然有了列表、元组这些数据容器,python 设计者为什么还提供集合这样的数据类型呢?
- 在项目中,我们可能有这样的需求:需要记录一些数据,而这些数据必须保证是不重复的,而且数据的顺序并没有要求,就可以考虑使用集合。
- 回顾:列表、元组的元素是可以重复,而且有序。
集合的定义
- 创建一个集合,只要用逗号分隔不同的数据项,并使用{}括起来即可。
set_a = {100, 200, 300, 400, 500}
basket = {"apple", "orange", "pear", "banana"}
print(f"set_a = {set_a}, basket = {basket}")
print(f"set_a类型 = {type(set_a)}")
print(f"basket类型 = {type(basket)}")
注意事项和使用细节
- 集合是由不重复元素组成的无序容器。
# 不重复元素组成,可以理解成自动去重
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
print(f"basket: {basket}")
# 无序,也就是你定义元素的顺序和取出的顺序不能保证一致
# 集合底层会按照自己的一套算法来存储和取数据,所以每次取出顺序是不变的
set_a = {100, 200, 300, 400, 500}
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")
print(f"set_a: {set_a}")
- 集合不支持索引。
set_a = {100, 200, 300, 400, 500}
# print(set_a[0]) # TypeError: 'set' object is not subscriptable
- 既然集合不支持索引,所以对集合进行遍历不支持 while,只支持 for。
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
for ele in basket:
print(ele)
- 创建空集合只能用
set(),不能用{},{}创建的是空字典。
set_b = {} # 定义空集合不对,这是空字典
set_c = set() # 创建空集合
print(f"set_b: {type(set_b)}")
print(f"set_c: {type(set_c)}")
集合常用操作
- 集合常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(集合):集合元素个数 |
| 2 | x in s:检测 x 是否为 s 中的成员 |
| 3 | add(elem):将元素 elem 添加到集合中 |
| 4 | remove(elem):从集合中移除元素 elem。如果 elem 不存在于集合中则会引发 KeyError |
| 5 | pop():从集合中移除并返回任意一个元素。如果集合为空则会引发 KeyError |
| 6 | clear():从集合中移除所有元素 |
| 7 | union(*others) set | other | … :返回一个新集合,其中包含来自原集合以及 others 指定的所有集合中的元素 |
| 8 | intersection(*others) set & other & …:返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素 |
| 9 | difference(*others) set - other - … :返回一个新集合,其中包含原集合以及 others 指定的其他结合中不存在的元素 |
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
# len(集合):集合元素个数
print("basket元素个数:", len(basket))
# x in s:检测x是否为s中的成员
print("apple" in basket)
# add(elem):将元素elem添加到集合中
basket.add("grape")
print("basket:", basket)
# remove(elem):从集合中移除元素elem。如果elem不存在于集合中则会引发KeyError
basket.remove("apple")
print("basket:", basket)
# basket.remove("aaa") # KeyError: 'aaa'
# pop():从集合中移除并返回任意一个元素。如果集合为空则会引发KeyError
ele = basket.pop()
print("ele:", ele, "type:", type(ele))
print("basket:", basket)
# clear():从集合中移除所有元素
basket = {"apple", "orange", "apple", "pear", "orange", "banana"}
print("basket:", basket)
# union(*others) <br />set | other | ... :返回一个新集合,其中包含来自原集合以及 others 指定的所有集合中的元素
books = {"天龙八部", "笑傲江湖"}
books_2 = {"雪山飞狐", "神雕侠侣", "天龙八部"}
books_3 = books.union(books_2)
books_3 = books | books_2 # 等价于上一行代码
print("books_3:", books_3)
# intersection(*others) <br />set & other & ...:返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素
books_4 = books.intersection(books_2)
books_4 = books & books_2 # 等价于上一行代码
print("books_4:", books_4)
# difference(*others)<br />set - other - ... :返回一个新集合,其中包含原集合以及 others 指定的其他结合中不存在的元素
books_5 = books.difference(books_2)
books_5 = books - books_2
print("books_5:", books_5)
books_6 = books_2 - books
print("books_6:", books_6)
集合生成式
- 集合生成式就是“生成集合的公式“
- 基本语法:
{集合元素的表达式 for 自定义变量 in 可迭代对象}。
set1 = {ele * 2 for ele in range(1, 5)}
print("set1:", set1)
set2 = {ele + ele for ele in "hsp"}
print("set2:", set2)
- 注意:集合生成式和列表生成式的区别就在于,集生成式使用
{},列表生成式使用[]。
练习
s_history = {"小明", "张三", "李四", "王五", "Lily", "Bob"}
s_politic = {"小明", "小花", "小红", "二狗"}
s_english = {"小明", "Lily", "Bob", "Davil", "李四"}
# 求选课学生共有多少人
total = s_history.union(s_politic).union(s_english)
print("总人数:", len(total))
# 求只选了第一个学科(history)的学生数量和学生姓名
total_history = s_history.difference(s_politic).difference(s_english)
print("数量:", len(total_history), "姓名:", total_history)
# 求只选了一门学科的学生数量和学生姓名
total_politic = s_politic.difference(s_english).difference(s_history)
total_english = s_english.difference(s_history).difference(s_politic)
total_one = total_history.union(total_politic).union(total_english)
print("数量:", len(total_one), "姓名:", total_one)
# 求选了三门学科的学生数量和学生姓名
total_three = s_history.intersection(s_politic).intersection(s_english)
print("数量:", len(total_three), "姓名:", total_three)
字典(dict)
基本介绍
- 字典(dict,完整单词是dictionary)也是一种常用的python数据类型,其他语言可能把字典称为联合内存或联合数组。
- 字典是一种映射类型,非常适合处理通过xx查询yy的需求,这里的xx我们称为Key(键/关键字),这里的yy我们称为Value(值),即Key—Value的映射关系。
字典的定义
- 字典的定义:创建一个字典,只要把逗号分隔的不同的元素,用{}括起来即可,存储的元素是一个个的
键值对。
dict_a = {key: value, key: value, key: value ...}
- 通过key取出对应的Value的语法:
字典名[key]。
dict_a [key]
tel = {"jack": 100, "bob": 200}
print(f "tel:{tel}, type(tel):{type(tel)}")
print("jack 的 tel:", tel ['jack'])
注意事项和使用细节
- 字典的key(关键字)通常是字符串或数字,value可以是任意数据类型。
字典是以 键 进行索引的,键可以是任何不可变类型;字符串和数字总是可以作为键。 如果一个元组只包含字符串、数字或元组则也可以作为键;如果一个元组直接或间接地包含了任何可变对象,则不能作为键。 列表不能作为键,因为列表可以使用索引赋值、切片赋值或者
append()和extend()等方法进行原地修改列表。
dict_a = {
"jack": [100, 200, 300],
"mary": (10, 20, "hello"),
"nono": {"apple", "pear"},
"smith": "计算机老师",
"周星驰": {
"性别": "男",
"age": 18,
"地址": "香港"
},
"key1": 100,
"key2": 9.8,
"key3": True
}
print(f "dict_a = {dict_a} type(dict_a) = {type(dict_a)}")
- 字典不支持索引,会报KeyError。
print(dict_a [0]) # KeyError: 0
- 既然字典不支持索引,所以对字典进行遍历不支持while,只支持for,注意直接对字典进行遍历,遍历得到的是key。
dict_b = {"one": 1, "two": 2, "three": 3}
# 遍历方式 1:依次取出 key,再通过 dict [key] 取出对应的 value
for key in dict_b:
print(f "key: {key}, value: {dict_b [key]}")
# 遍历方式 2:依次取出 value
for value in dict_b.values():
print(f "value: {value}")
# 遍历方式 3:依次取出 key-value
for key, value in dict_b.items():
print(f "key: {key}, value: {value}")
- 创建空字典可以通过
{},或者dict()。
dict_c = {}
dict_d = dict()
print(f "dict_c = {dict_c} dict_c.type = {type(dict_c)}")
print(f "dict_d = {dict_d} dict_d.type = {type(dict_d)}")
- 字典的key必须是唯一的,如果你指定了多个相同的key,后面的键值对会覆盖前面的。
dict_e = {"one": 1, "two": 2, "three": 3, "two": 4}
print(f "dict_e = {dict_e} dict_e.type = {type(dict_e)}")
字典常用操作
- 常用操作一览
| 序号 | 操作 |
|---|---|
| 1 | len(d):返回字典d中的项数 |
| 2 | d[key]:返回d中以key为键的项。如果映射中不存在key则会引发KeyError |
| 3 | d[key] = value:将d[key]设为value,如果key已经存在,则是修改value,如果key没有存在,则是增加key-value |
| 4 | del d[key]:将d[key]从d中移除。如果映射中不存在key,则会引发KeyError |
| 5 | pop(key[, default]):如果key存在于字典中则将其移除并返回其值,否则返回default。如果default未给出且key不存在于字典中,则会引发KeyError |
| 6 | keys():返回字典所有的key |
| 7 | key in d:如果d中存在键key则返回True,否则返回False |
| 8 | clear():移除字典中的所有元素 |
dict_a = {"one": 1, "two": 2, "three": 3}
# len(d):返回字典 d 中的项数
print(f "dict_a 元素个数:{len(dict_a)}")
# d [key]:返回 d 中以 key 为键的项。如果映射中不存在 key 则会引发 KeyError
print(f "key 为 three 对应的 value:{dict_a ["three"]}")
# print(f "key 为 four 对应的 value:{dict_a ["four"]}") # KeyError: 'four'
# d [key] = value:将 d [key] 设为 value,如果 key 已经存在,则是修改 value,如果 key 没有存在,则是增加 key-value
dict_a ["one"] = "第一"
print(f "dict_a: {dict_a}")
dict_a ["four"] = 4
print(f "dict_a: {dict_a}")
# del d [key]:将 d [key] 从 d 中移除。如果映射中不存在 key,则会引发 KeyError
del dict_a ["four"]
print(f "dict_a: {dict_a}")
# del dict_a ["five"] # KeyError: 'five'
# pop(key [, default]):如果 key 存在于字典中则将其移除并返回其值,否则返回 default。如果 default 未给出且 key 不存在于字典中,则会引发 KeyError
val = dict_a.pop("one")
print(f "val: {val}")
print(f "dict_a: {dict_a}")
# val2 = dict_a.pop("four") # KeyError: 'four'
val = dict_a.pop("four", "哈哈")
print(f "val: {val}")
print(f "dict_a: {dict_a}")
# keys():返回字典所有的 key
dict_a_keys = dict_a.keys()
print(f "dict_a_keys: {dict_a_keys} type: {type(dict_a_keys)}")
for k in dict_a_keys:
print(f "k: {k}")
# key in d:如果 d 中存在键 key 则返回 True,否则返回 False
print("two" in dict_a)
# clear():移除字典中的所有元素
dict_a.clear()
print(f "dict_a: {dict_a}")
字典生成式
- 内置函数zip()
- zip()可以将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,返回由这些元组组成的列表。
- 字典生成式基本语法
{字典 key 的表达式: 字典 value 的表达式 for 表示 key 的变量, 表示 value 的变量 in zip(可迭代对象, 可迭代对象)}
books = ["红楼梦", "三国演义", "西游记", "水浒传"]
author = ["曹雪芹", "罗贯中", "吴承恩", "施耐庵"]
dict_book = {book: author for book, author in zip(books, author)}
print(dict_book)
str1 = "hsp"
dict_str1 = {k: v * 2 for k, v in zip(str1, str1)}
print(dict_str1)
english_list = ["red", "black", "yellow", 'white']
chinese_list = ["红色", "黑色", "黄色", '白色']
dict_color = {chinese: english.upper() for chinese, english in zip(chinese_list, english_list)}
print(dict_color)
练习
# 一个公司有多个员工,请使用合适的数据类型保存员工信息(员工号、年龄、姓名、入职时间、薪水)
clerks = {
"0001": {
"age": 20,
"name": "贾宝玉",
"entry_time": "2011-11-11",
"salary": 12000
},
"0002": {
"age": 21,
"name": "薛宝钗",
"entry_time": "2015-12-12",
"salary": 10000
},
"0010": {
"age": 18,
"name": "林黛玉",
"entry_time": "2018-10-10",
"salary": 20000
}
}
print(f "员工号为 0010 的信息为:姓名-{clerks ['0010']['name']} "
f "年龄-{clerks ['0010']['age']} "
f "入职时间-{clerks ['0010']['entry_time']} "
f "薪水-{clerks ['0010']['salary']}")
# 增加
clerks ['0020'] = {
"age": 30,
"name": "老韩",
"entry_time": "2020-08-10",
"salary": 6000
}
print("clerks:", clerks)
# 删除
del clerks ['0001']
print("clerks:", clerks)
# 修改
clerks ['0020']['name'] = '韩顺平'
clerks ['0020']['entry_time'] = '1999-10-10'
clerks ['0020']['salary'] += clerks ['0020']['salary'] * 0.1
print("clerks:", clerks)
# 遍历
keys = clerks.keys()
for key in keys:
clerks [key]['salary'] += clerks [key]['salary'] * 0.2
print("clerks:", clerks)
# 格式化输出
for key in keys:
print(f "员工号为{key}的员工信息如下 年龄:{clerks [key]['age']}"
f "名字:{clerks [key]['name']}"
f "入职时间:{clerks [key]['entry_time']}"
f "薪水:{clerks [key]['salary']}")
print("-" * 60)
for key in keys:
clerk_info = clerks [key]
print(f "员工号为{key}的员工信息如下 年龄:{clerks [key]['age']}"
f "名字:{clerk_info ['name']}"
f "入职时间:{clerk_info ['entry_time']}"
f "薪水:{clerk_info ['salary']}")
小结
数据容器特点比较
| 比较项 | 列表(list) | 元组(tuple) | 字符串(str) | 集合(set) | 字典(dict) |
|---|---|---|---|---|---|
| 是否支持多个元素 | Y | Y | Y | Y | Y |
| 元素类型 | 任意 | 任意 | 只支持字符 | 任意 | Key:通常是字符串或数字 Value:任意 |
| 是否支持元素重复 | Y | Y | Y | N | Key 不能重复 Value 可以重复 |
| 是否有序 | Y | Y | Y | N | 3.6 版本之前是无序的 3.6 版本之后开始支持元素有序 |
| 是否支持所有 | Y | Y | Y | N | N |
| 可修改性/可变性 | Y | N | N | Y | Y |
| 使用场景 | 可修改、可重复的多个数据 | 不可修改、可重复的多个数据 | 字符串 | 不可重复的多个数据 | 通过关键字查询对应数据的需求 |
| 定义符号 | [] | () | "" 或 '' | {} | {key: value} |
数据容器操作小结
- 通用序列操作。
大多数序列类型,包括可变类型和不可变类型都支持下表的操作。
| 运算 | 结果 |
|---|---|
| x in s | 如果 s 中的某项等于 x 则结果为 True,否则为 False |
| x not in s | 如果 s 中的某项等于 x 则结果为 False,否则为 True |
| s + t | s 与 t 相拼接 |
s*n 或 n*s | 相当于 s 与自身进行 n 次拼接 |
| s [i] | s 的第 i 项,起始为 0 |
| s [i: j] | s 从 i 到 j 的切片 |
| s [i: j: k] | s 从 i 到 j 步长为 k 的切片 |
| len(s) | s 的长度 |
| min(s) | s 的最小项 |
| max(s) | s 的最大项 |
| s.index(x [, i[, j]]) | x 在 s 中首次出现的索引号(索引号在 i 或其后且在 j 之前) |
| s.count(x) | x 在 s 中出现的总次数 |
- 通用转换操作一览。
| 序号 | 操作 |
|---|---|
| 1 | list([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成列表 |
| 2 | str(容器):将制定的容器转为字符串 |
| 3 | tuple([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成元组 |
| 4 | set([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象, 将指定的容器转成集合 |
str_a = "hello"
list_a = ["jack", "tom", "mary"]
tuple_a = ("hsp", "tim")
set_a = {"red", "green", "blue"}
dict_a = {"0001": "小倩", "0002": "黑山老妖"}
# list([iterable]):iterable可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成列表
print(list(str_a))
print(list(tuple_a))
print(list(set_a))
print(list(dict_a))
print("-" * 60)
# str(容器):将制定的容器转为字符串
print(str(list_a))
print(str(tuple_a))
print(str(set_a))
print(str(dict_a))
print("-" * 60)
# tuple([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成元组
print(tuple(str_a))
print(tuple(list_a))
print(tuple(set_a))
print(tuple(dict_a))
print("-" * 60)
# set([iterable]):iterable 可以是序列、支持迭代的容器或其他可迭代对象,<br />将指定的容器转成集合
print(set(str_a))
print(set(list_a))
print(set(tuple_a))
print(set(dict_a))
- 其它操作说明:请参考官方文档
排序和查找
排序的介绍
- 排序是将多个数据,按照指定的顺序进行排列的过程。
- 排序的分类
- 冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序,基数排序。
冒泡排序法
基本介绍
- 冒泡排序(Bubble Sorting)的基本思想是:重复地走访需要排序的元素列表,依次比较两个相邻的元素,如果排序(如从大到小或从小到大)错误就交换它们的位置。重复地进行直到没有相邻的元素需要交换,则元素列表排序完成。
- 在冒泡排序中,值最大(或最小)的元素会通过交换慢慢“浮”到元素列表的“顶端”。就像“冒泡”一样,所以被称为冒泡排序。
冒泡排序法案例
- 列表[24, 69, 80, 57, 13] 有5个元素,使用冒泡排序法使其排成一个从小到大的有序列表。
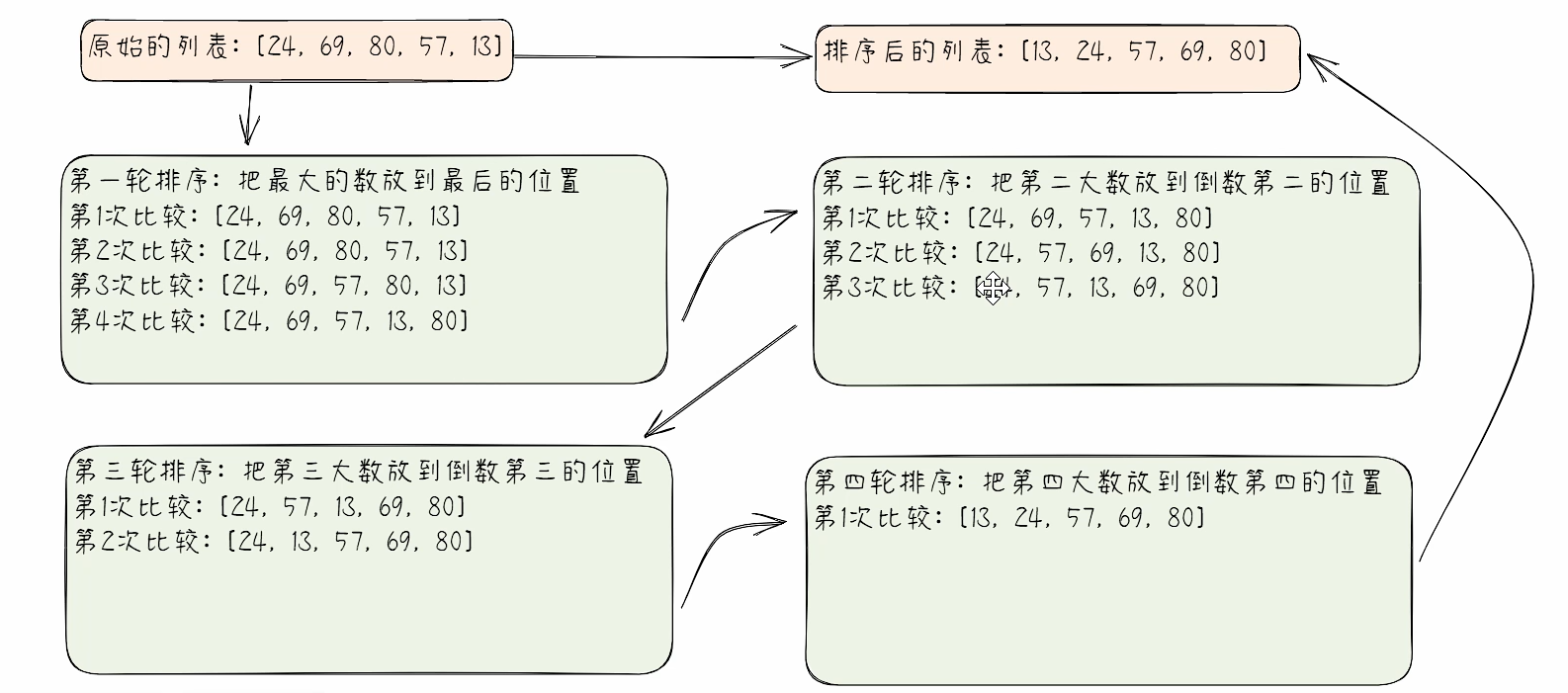
# 使用 sort 方法完成排序
num_list = [24, 69, 80, 57, 13]
print("排序前".center(32, "="))
print(f "num_list: {num_list}")
num_list.sort()
print("排序后".center(32, "="))
print(f "num_list: {num_list}")
# 定义函数-完成排序
def bubble_sort(my_list):
"" "
功能;对传入的列表排序-顺序是从小到大
: param my_list: 传入的列表
: return: 无
"" "
# i 变量控制多少轮排序
for i in range(1, len(my_list)):
# j 变量控制比较的次数,同时可以作为比较元素的索引下标
for j in range(len(my_list) - i):
# 如果前面的数 > 后面的数,就交换
if my_list [j] > my_list [j + 1]:
my_list [j], my_list [j + 1] = my_list [j + 1], my_list [j]
# print(f "第{i}轮排序后的结果 my_list: {my_list}")
print(f "排序后的结果 my_list: {my_list}")
num_list = [24, 69, 80, 57, 13]
bubble_sort(num_list)
num_list = [24, 69, 80, 57, 13, 0, 900]
bubble_sort(num_list)
查找
基本介绍
-
在Python中,我们应该掌握两种常见的查找方法:顺序查找、二分查找。
-
其它查找方法:插值查找、斐波那契查找、树表查找、分块查找、哈希查找。
顺序查找
- 列表[“白眉鹰王”, “金毛狮王”, “紫衫龙王”, “青翼蝠王”],猜名字游戏:从键盘中任意输入一个名称,判断列表中是否包含此名称【顺序查找】,要求找到了,提示找到,并给出下标值。
names_list = ["白眉鹰王", "金毛狮王", "紫衫龙王", "青翼蝠王"]
find_name = "金毛狮王"
# 使用 list.index 完成查找
res_index = names_list.index(find_name)
print("res_index:", res_index)
def seq_search(my_list, find_val):
"" "
功能:顺序查找指定的元素
: param my_list: 传入的列表(即要查找的列表)
: param find_val: 要查找的值/元素
: return: 如果查找到则返回对应的索引下标,否则返回-1
"" "
find_index = -1
for i in range(len(my_list)):
if my_list [i] == find_val:
print(f "恭喜,找到对应的值{find_val} 下标是{i}")
break
else:
print(f "没有找到对应的值{find_val}")
return find_index
res_index = seq_search(names_list, find_name)
print("res_index:", res_index)
- 如果列表中有多个要查找的元素/值,比如前面的列表有两个金毛狮王,怎样才能把满足查询条件的元素的下标都返回。
# 编写查找函数,把满足查询条件的元素的下标都返回
def seq_search2(my_list, find_val):
find_index = []
for i in range(len(my_list)):
if my_list [i] == find_val:
# 将找到的下标添加到 find_index
find_index.append(i)
return find_index
names_list = ["白眉鹰王", "金毛狮王", "紫衫龙王", "金毛狮王", "青翼蝠王"]
find_name = "金毛狮王"
res_index = seq_search2(names_list, find_name)
print("res_index:", res_index)
二分查找
- 请对一个列表[1, 8, 10, 89, 1000, 1234](元素是从小到大排序的)进行二分查找,输入一个数看看该列表是否存在此数,并且求出下标,如果没有就返回-1。

num_list = [1, 8, 10, 89, 1000, 1234]
def binary_search(my_list, find_val):
"" "
功能:完成二分查找
: param my_list: 要查找的列表(该列表是由大小顺序)
: param find_val: 要查找的元素/值
: return: 如果找到返回对应的下标,若果没有找到,返回-1
"" "
left_index = 0
right_index = len(my_list) - 1
find_index = -1
while left_index <= right_index:
mid_index = (left_index + right_index) // 2
# 如果 mid_index > find_val,则到如果 mid_index 左边查找
if my_list [mid_index] > find_val:
right_index = mid_index - 1
# 如果 mid_index < find_val,则到如果 mid_index 右边查找
elif my_list [mid_index] < find_val:
left_index = mid_index + 1
else:
find_index = mid_index
break
return find_index
res_index = binary_search(num_list, 1)
if res_index == -1:
print("没有找到该数")
else:
print(f "找到数,对应的下标{res_index}")
- 注意事项和细节
- 二分查找的前提是该列表已经是一个排好序的列表(从小到大或从大到小)。
- 排序的顺序是从小到大还是从大到小,会影响二分查找的代码逻辑。
本章作业
- 随机生成10个整数(1-100的范围)保存到列表,使用冒泡排序,对其进行从大到小排序
import random
list_num = []
for _ in range(10):
list_num.append(random.randint(1, 100))
print("list_num", list_num)
def bubble_sort(my_list):
for i in range(1, len(my_list)):
for j in range(len(my_list) - i):
if my_list [j] < my_list [j + 1]:
my_list [j], my_list [j + 1] = my_list [j + 1], my_list [j]
bubble_sort(list_num)
print("list_num", list_num)
- 在第1题的基础上,使用二分查找,查找是否有8这个数,如果有,则返回对应的下标,如果没有,返回-1。
def binary_search(my_list, find_val):
left_index = 0
right_index = len(my_list) - 1
find_index = -1
while left_index <= right_index:
mid_index = (left_index + right_index) // 2
if my_list [mid_index] < find_val:
right_index = mid_index - 1
elif my_list [mid_index] > find_val:
left_index = mid_index + 1
else:
find_index = mid_index
break
return find_index
res_index = binary_search(list_num, 8)
if res_index == -1:
print("Not Found")
else:
print(f "找到数,对应的下标{res_index}")
断点调试(Debug)
基本介绍
断点调试介绍
- 断点调试是指在程序的某一行设置一个断点,调试时,程序运行到这一行就会停住,然后你可以一步一步往下调试,调试过程中可以看各个变量当前的值,出错的话,调试到出错的代码即显示错误,停下进行分析从而找到这个Bug。
- 断点调试是程序员必须掌握的技能。
- 断点调试也能帮助我们进入到函数/方法内,学习别人是怎么实现功能的,提高程序员的编程水平。
断点调试的快捷键
- F7:跳入方法/函数内。
- F8:逐行执行代码。
- Shift+F8:跳出方法/函数。
- F9:直接执行到下一个断点。
断点调试应用案例
查看变量的变化情况
sum_num = 0
for i in range(10):
sum_num += i
print(f "i ={i}")
print(f "sum_num ={sum_num}")
print("end...")
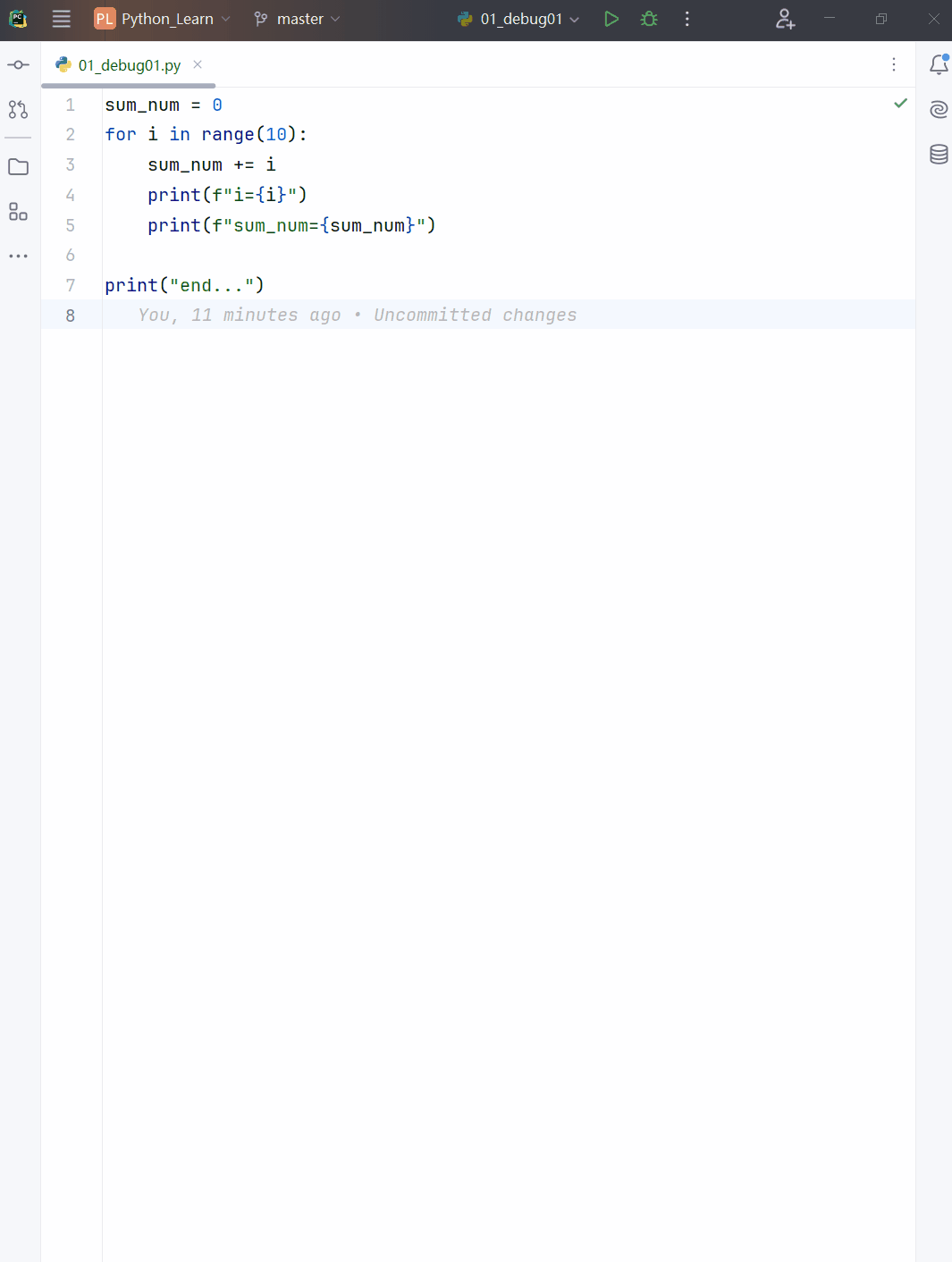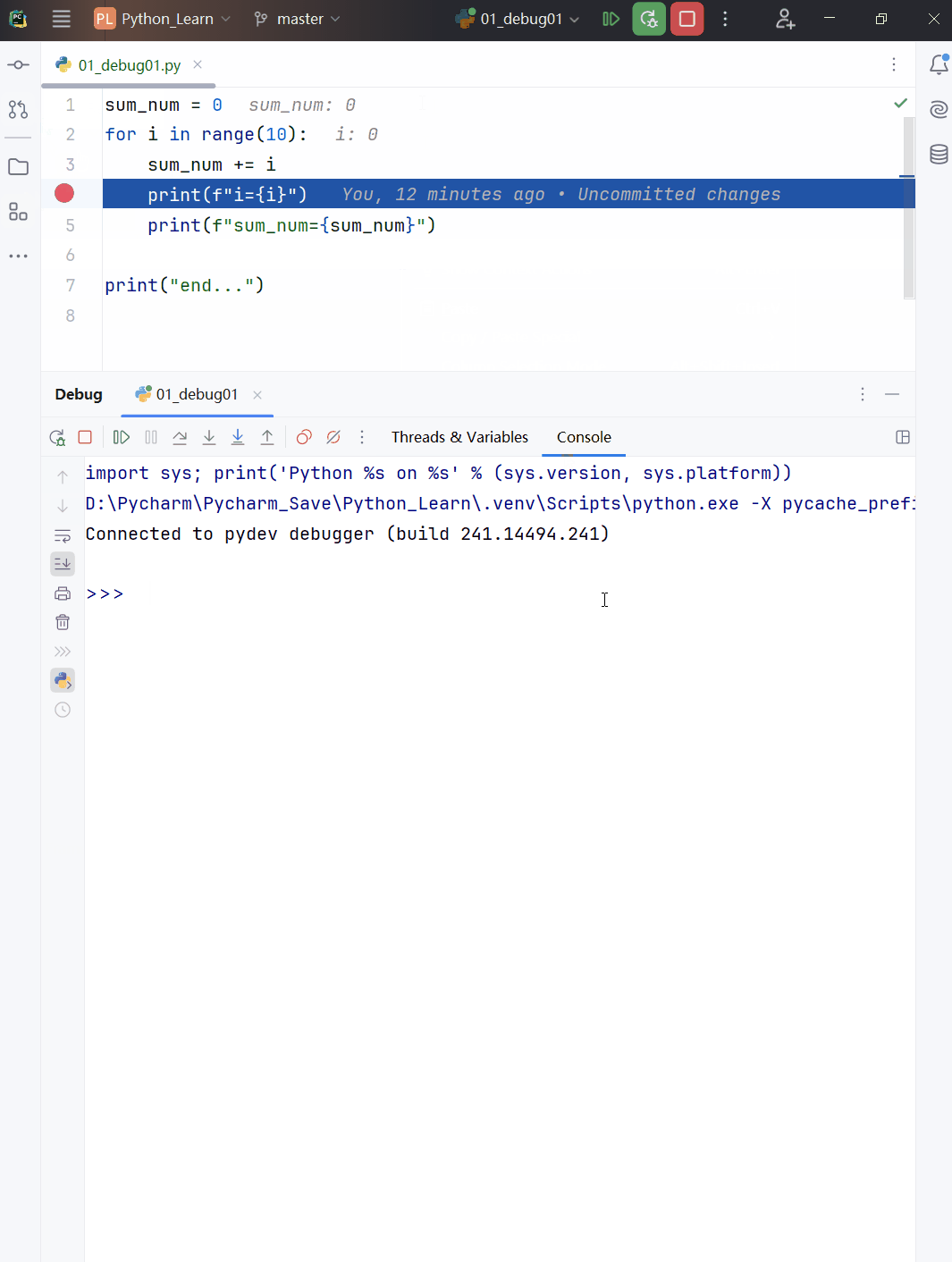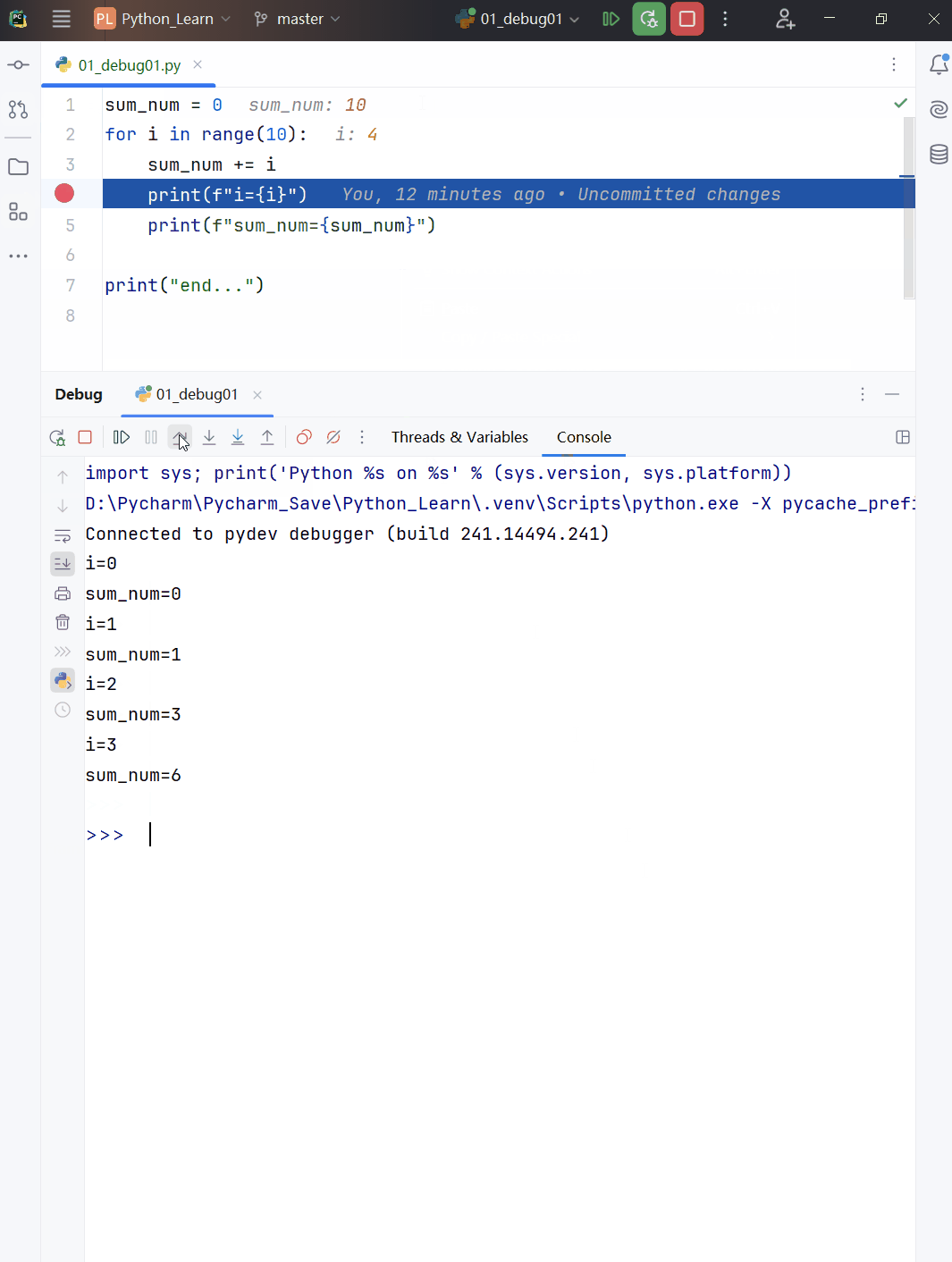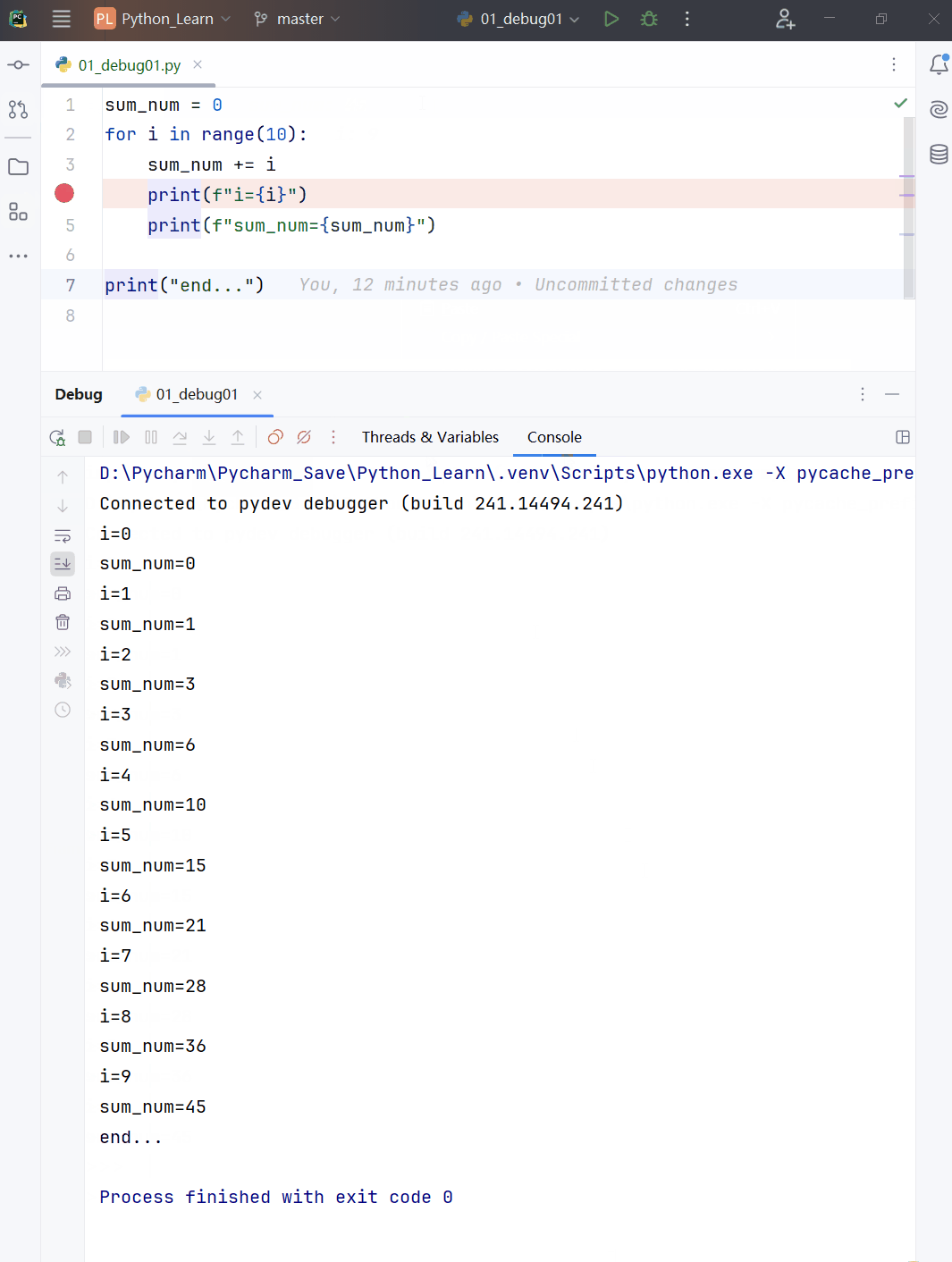
查看list越界的异常
names_list = ["jordan", "kobe", "james", "Messi"]
i = 0
# debug list 索引越界
while i <= len(names_list):
print(f "names_list [{i}] = {names_list [i]}")
i += 1
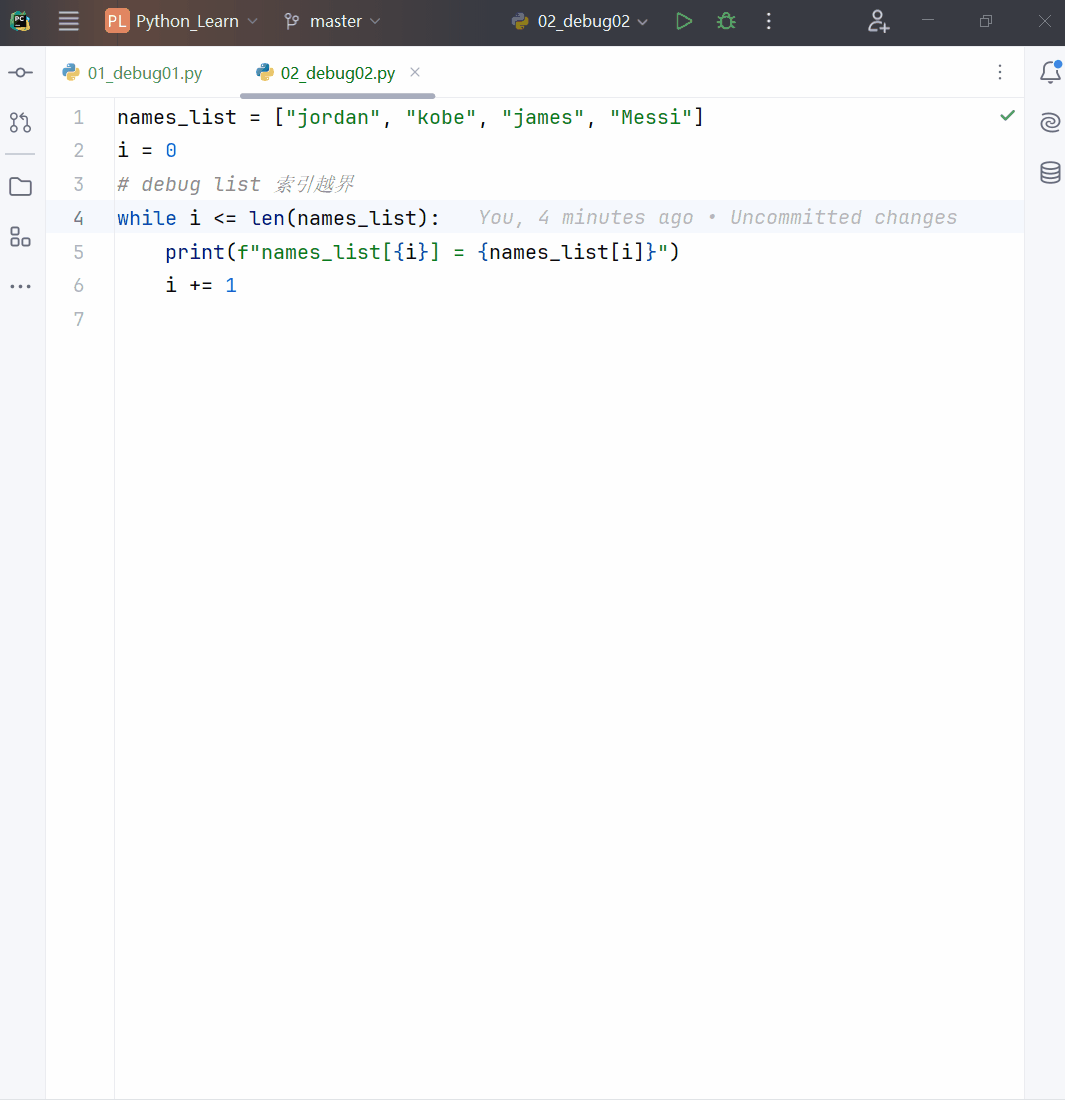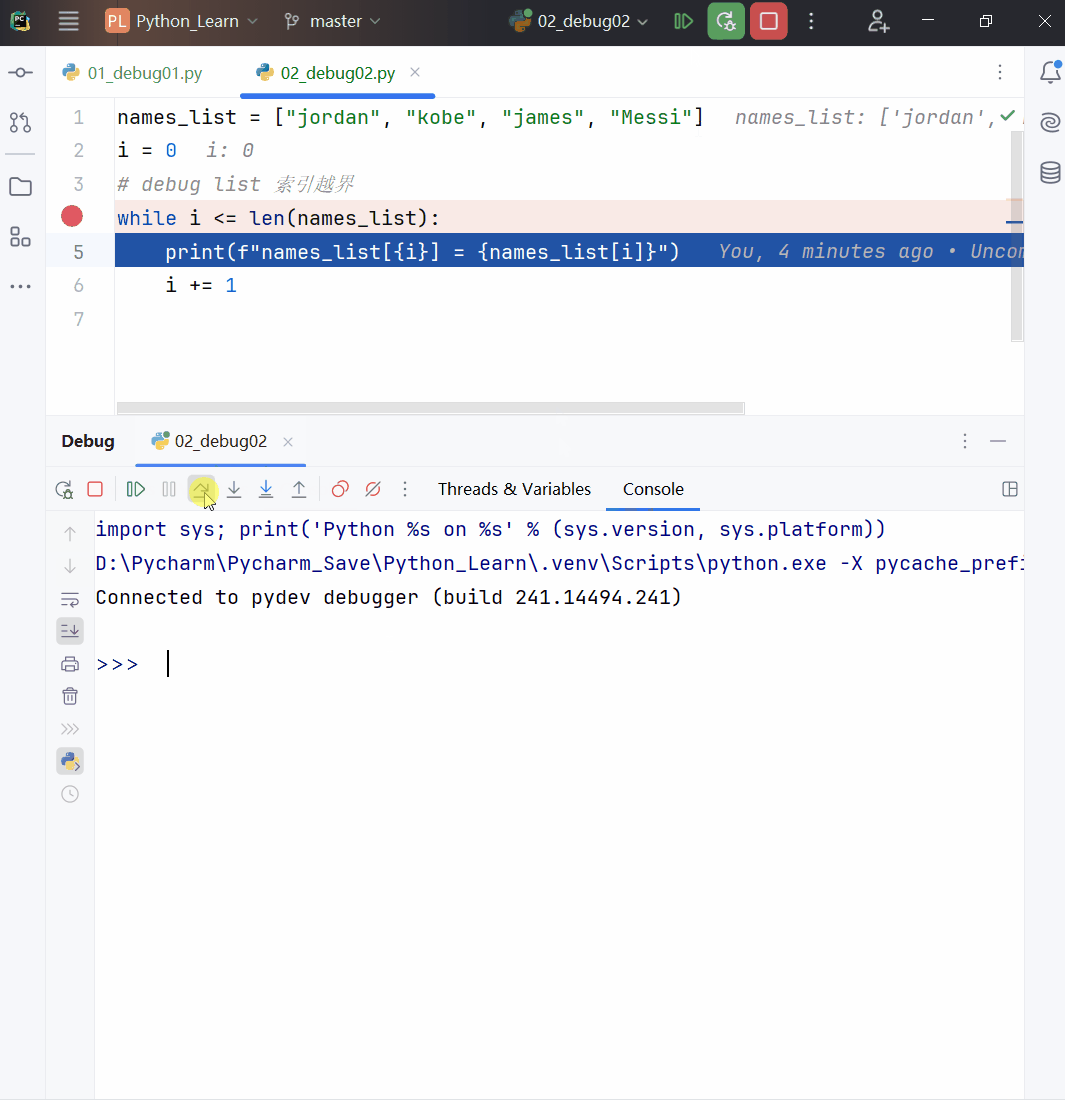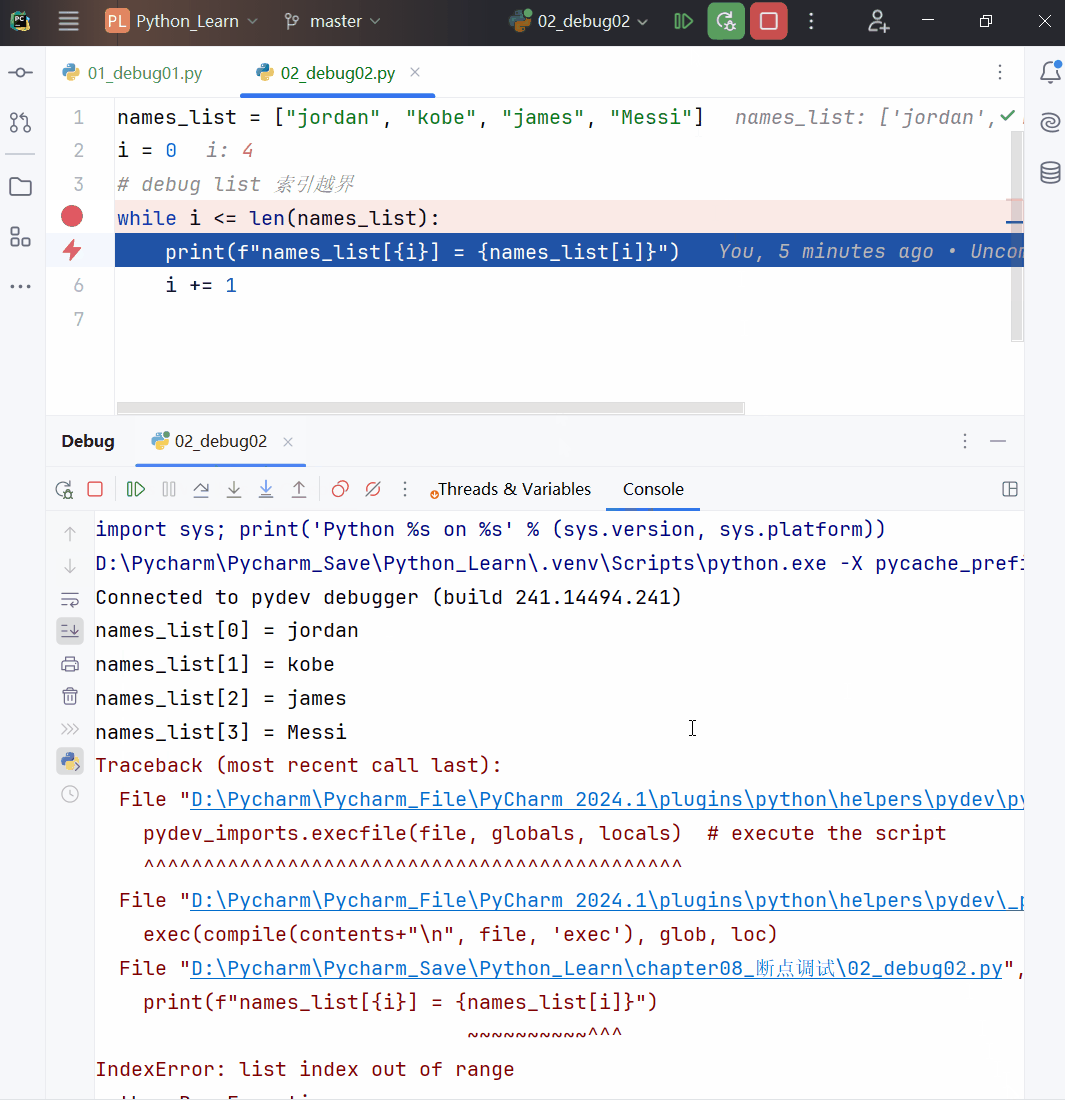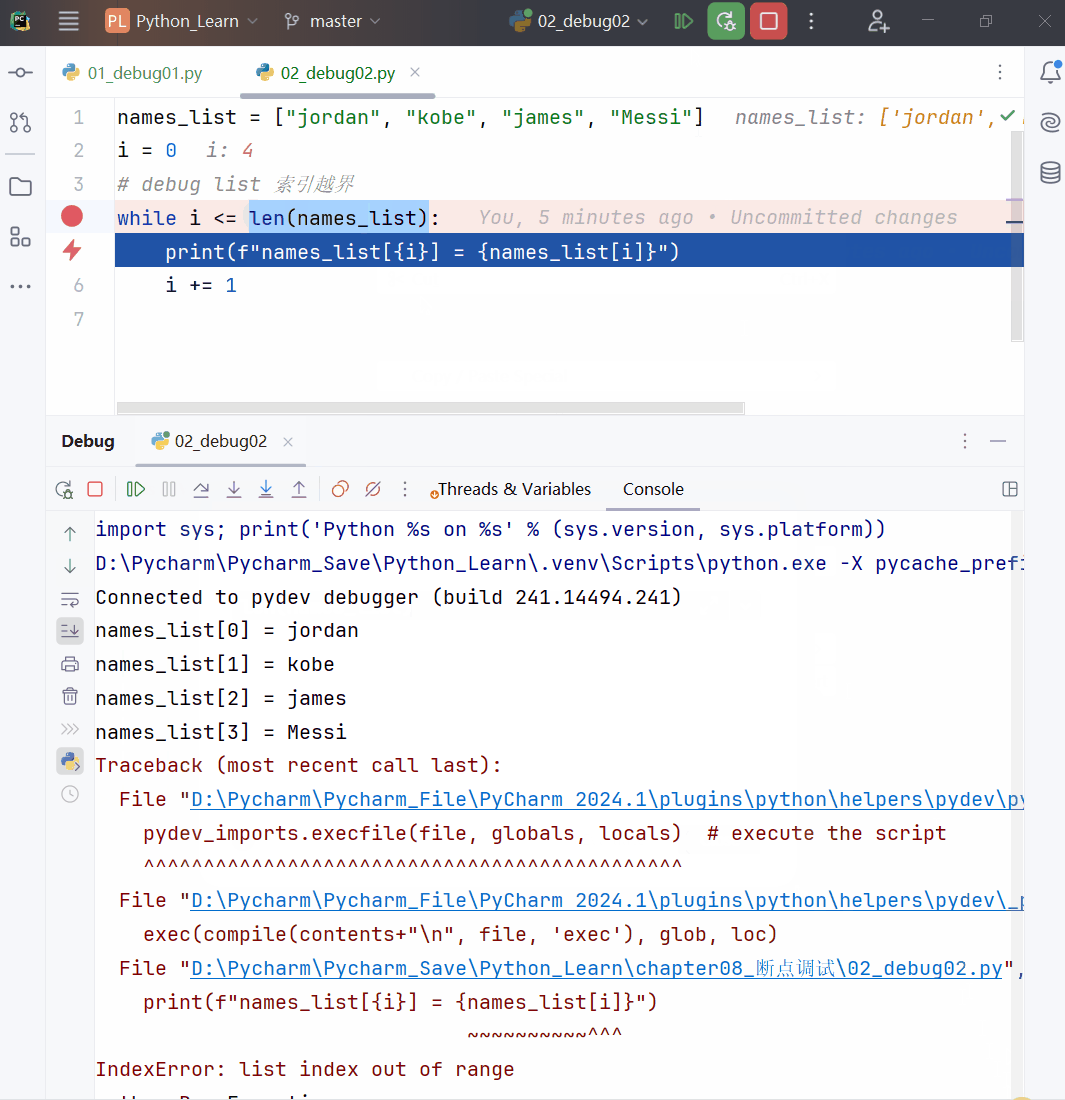
演示进入到函数/方法内容
- 将光标放在某个变量上,可以看到最新的数据。
def f2(num):
res = 0
for i in range(1, num + 1):
res += i
return res
def f1(name):
print(f "name ={name} 1")
print(f "name ={name} 2")
print(f "name ={name} 3")
r = f2(3)
print(f "r ={r}")
print(f "name ={name} 4")
f1("hsp")
print("end...")
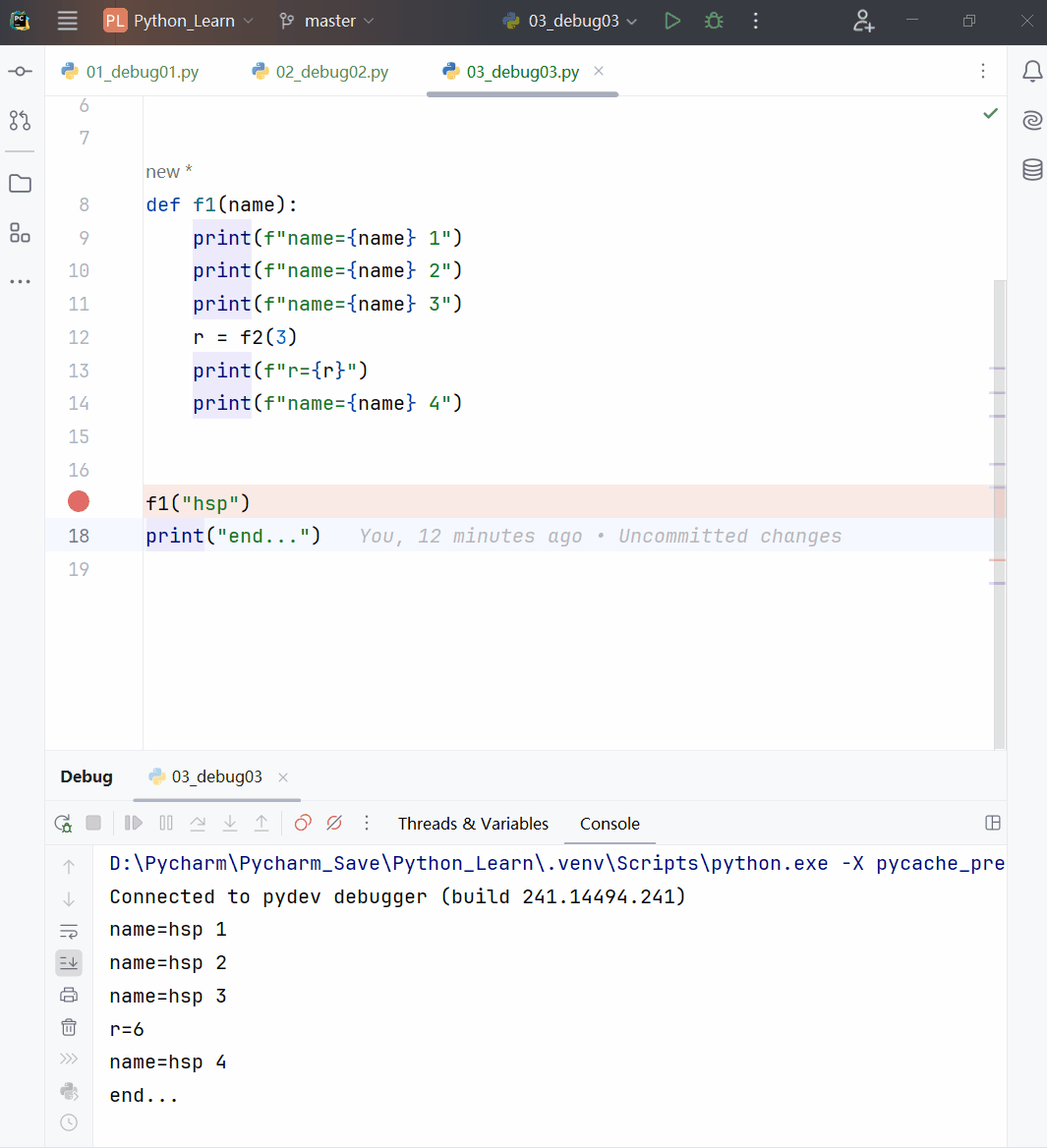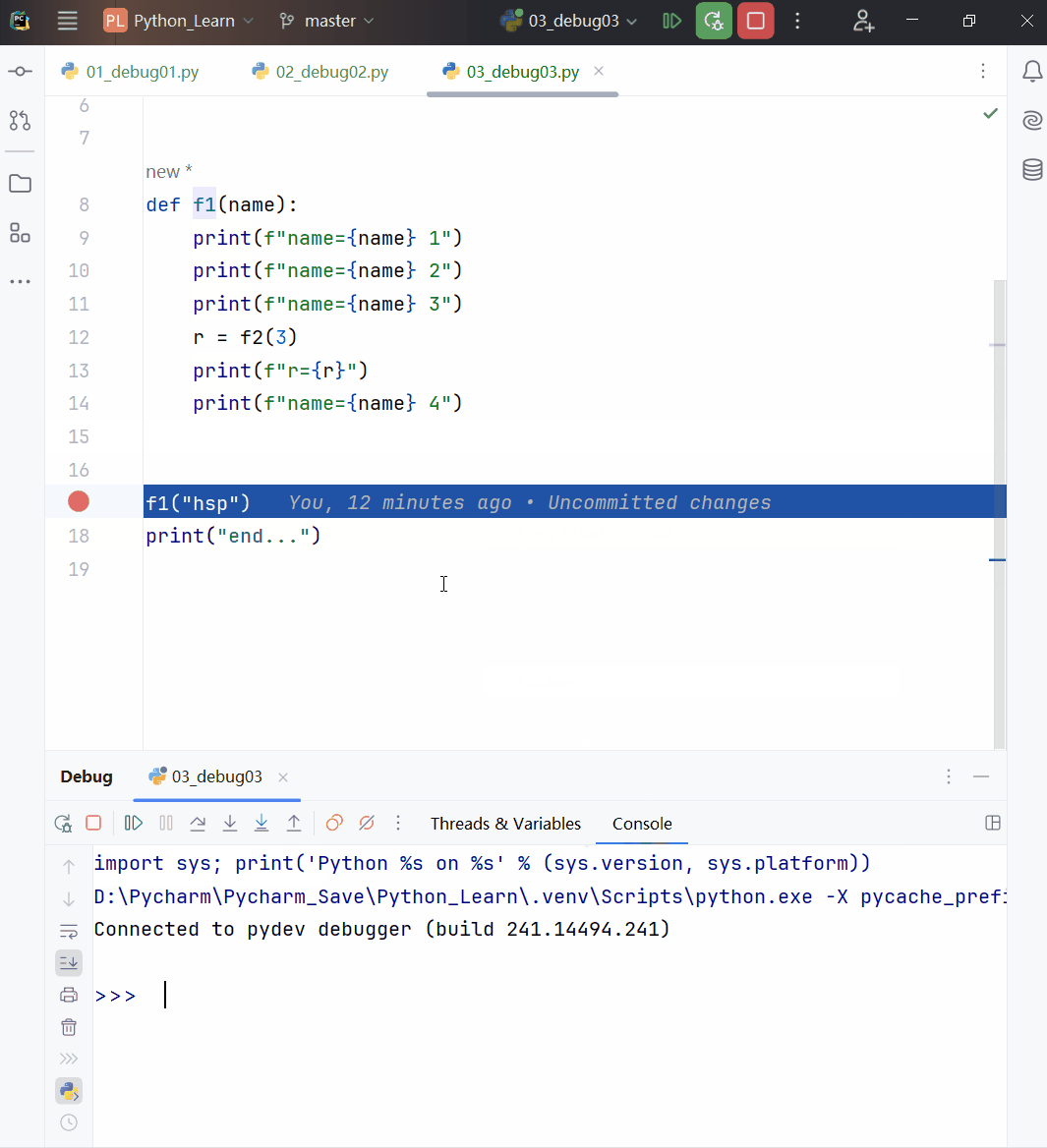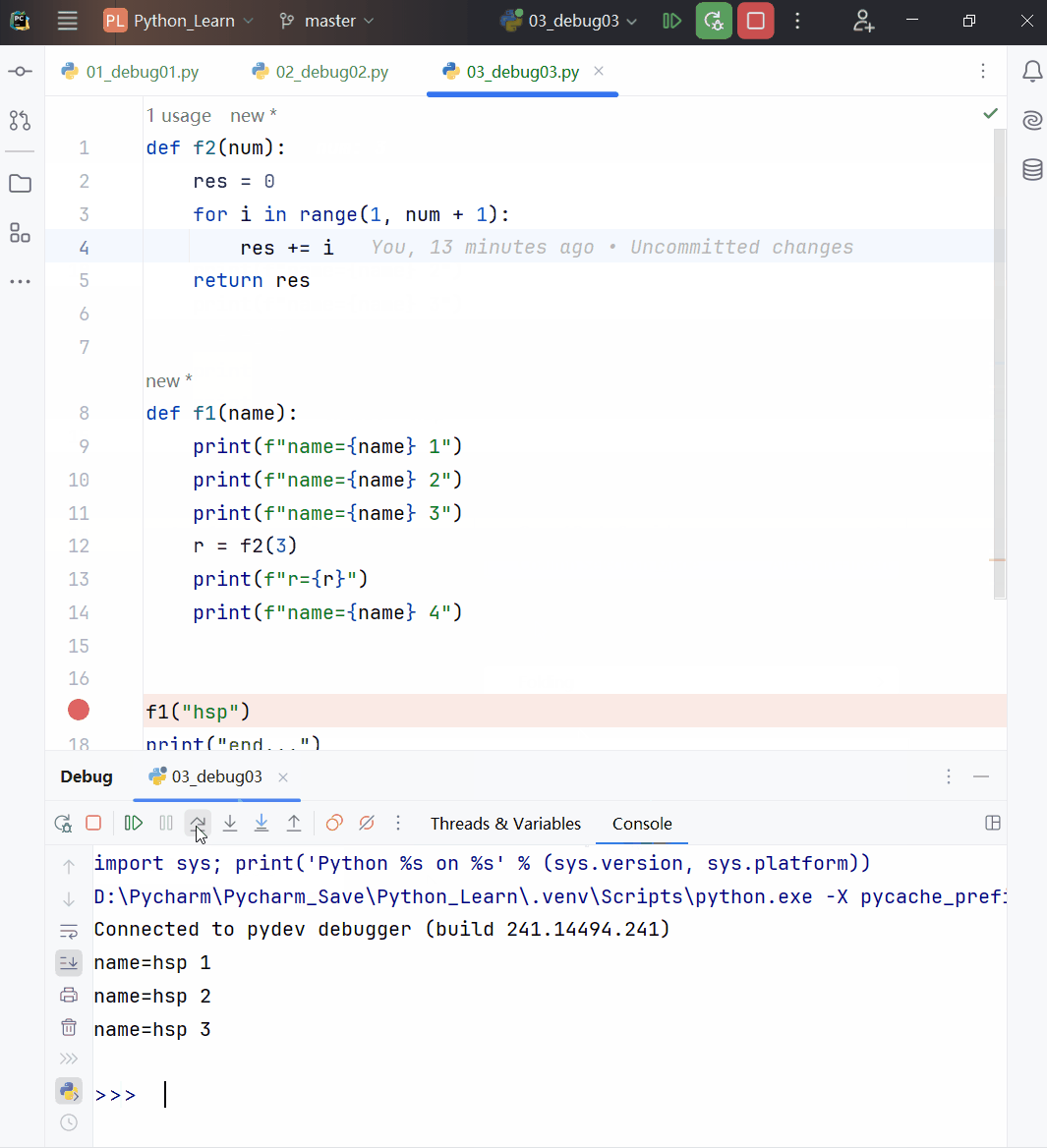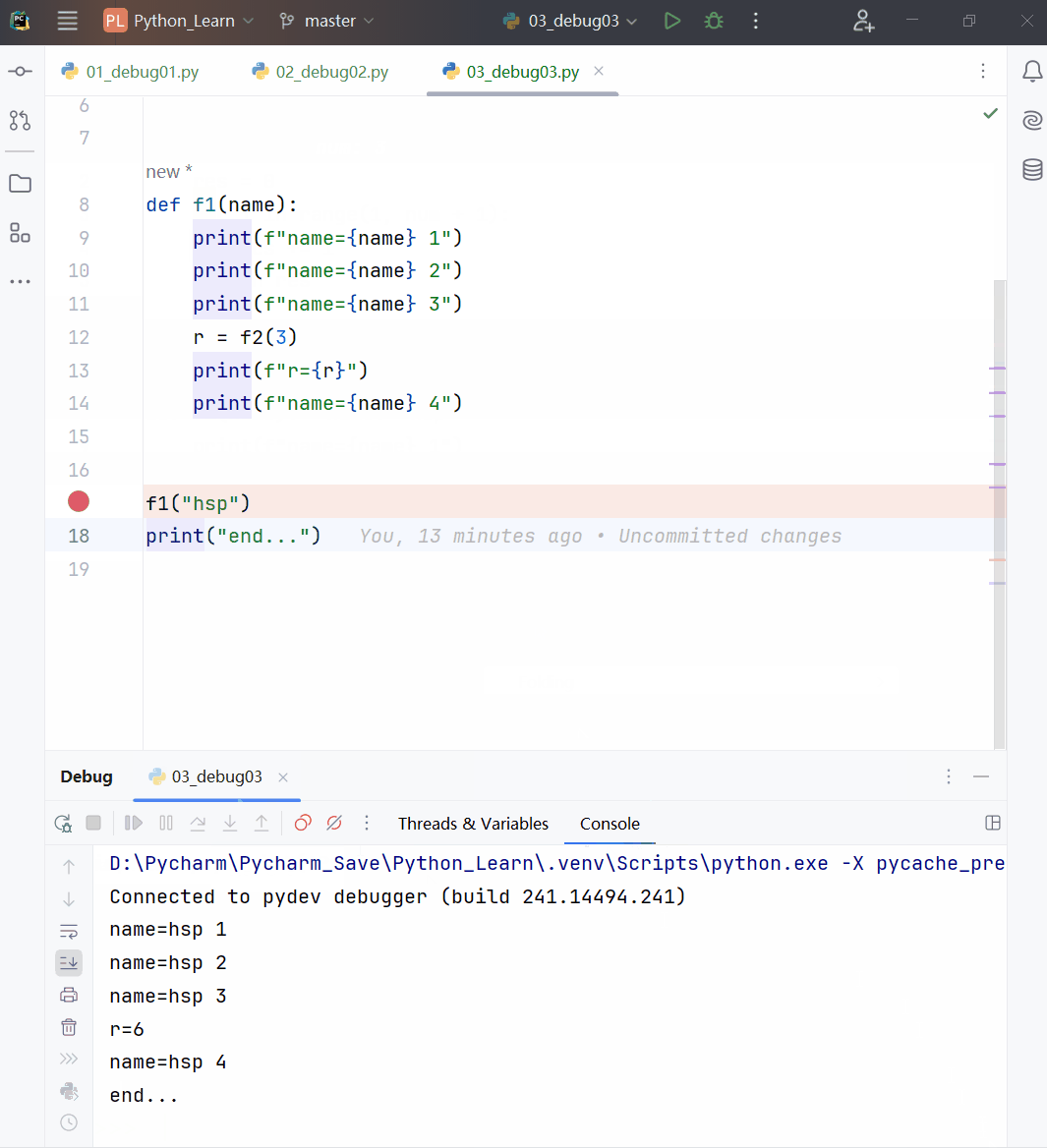
演示如何直接执行到下一个断点
- 可以在debug过程中,动态地下断点。
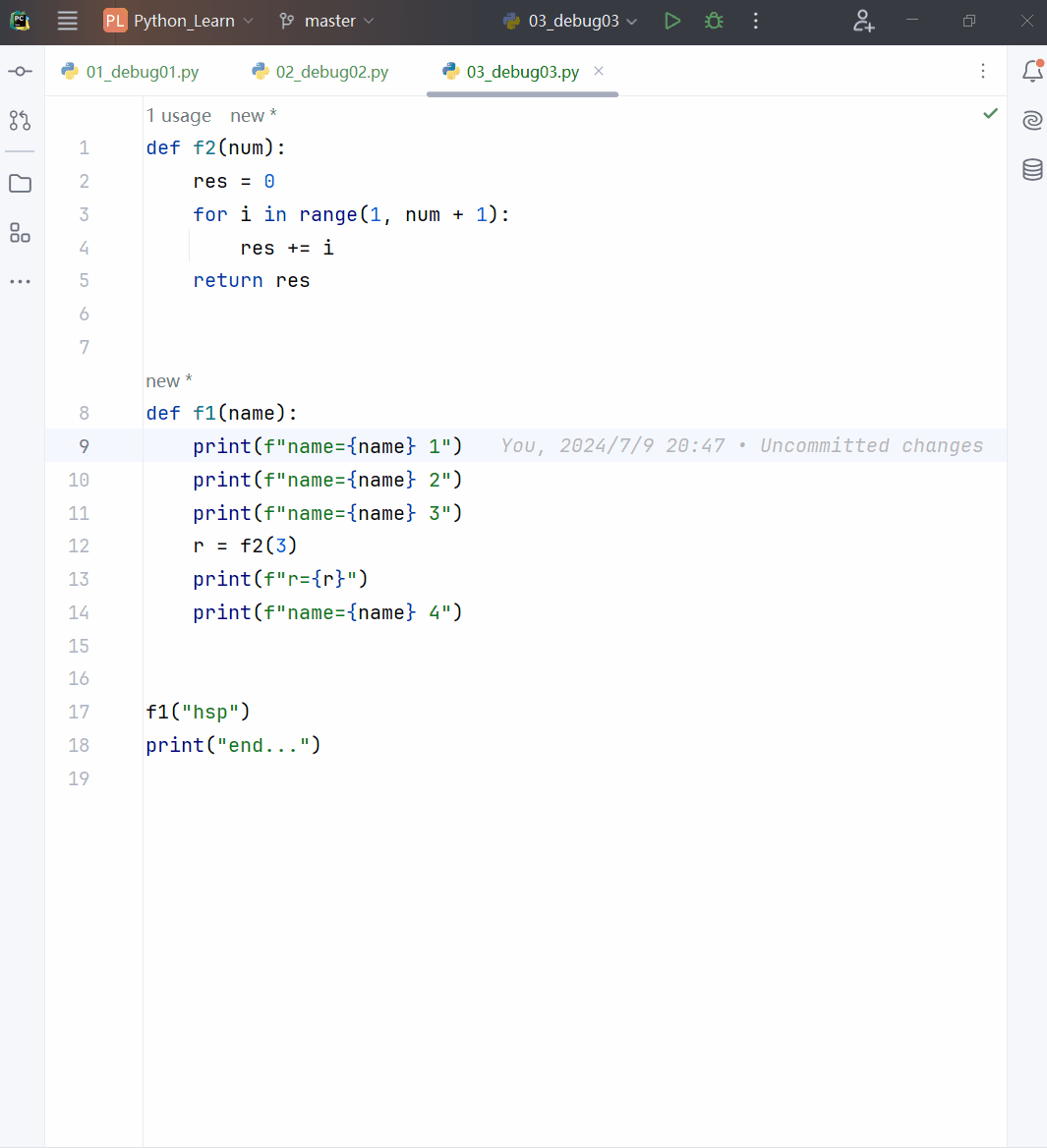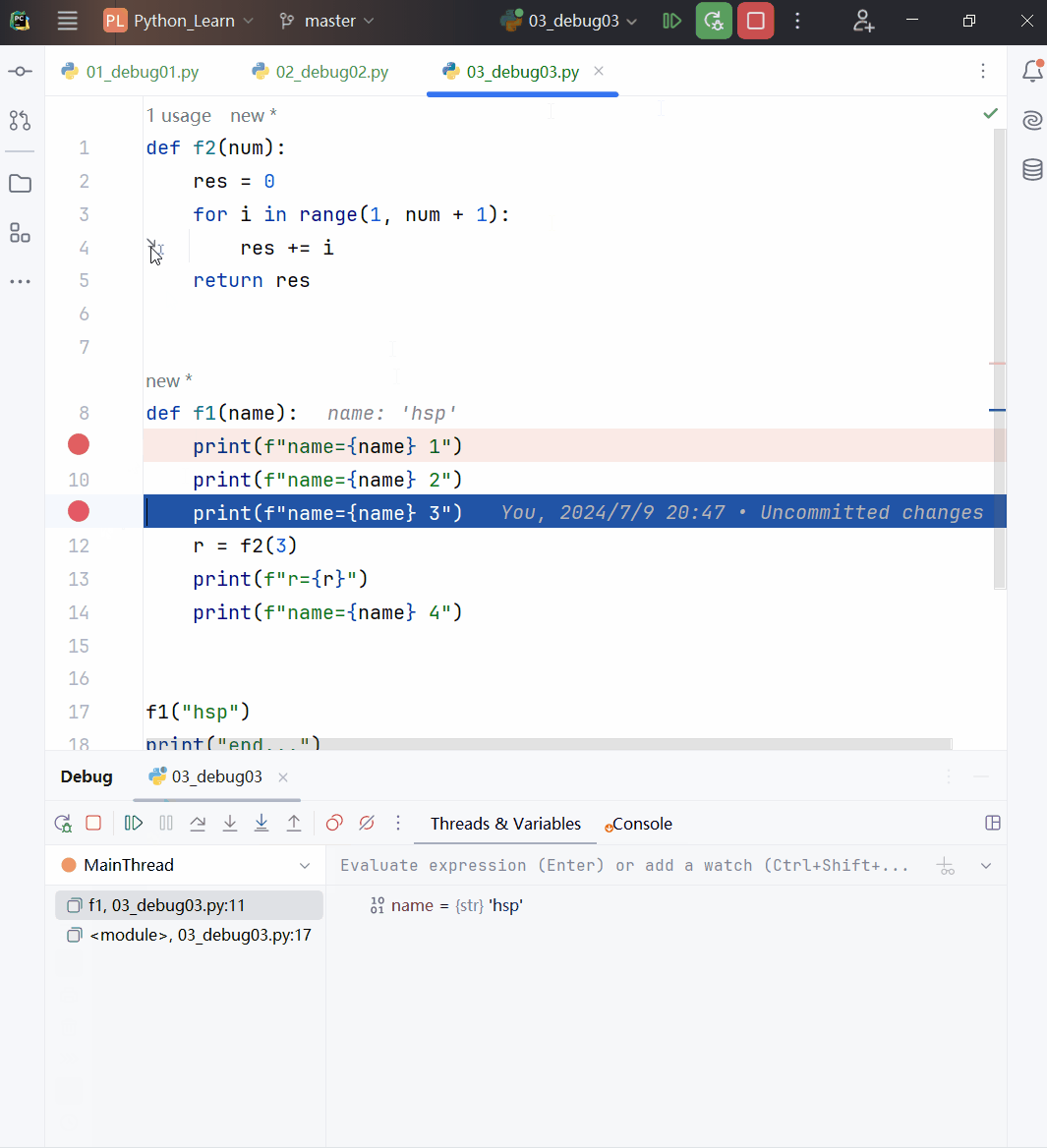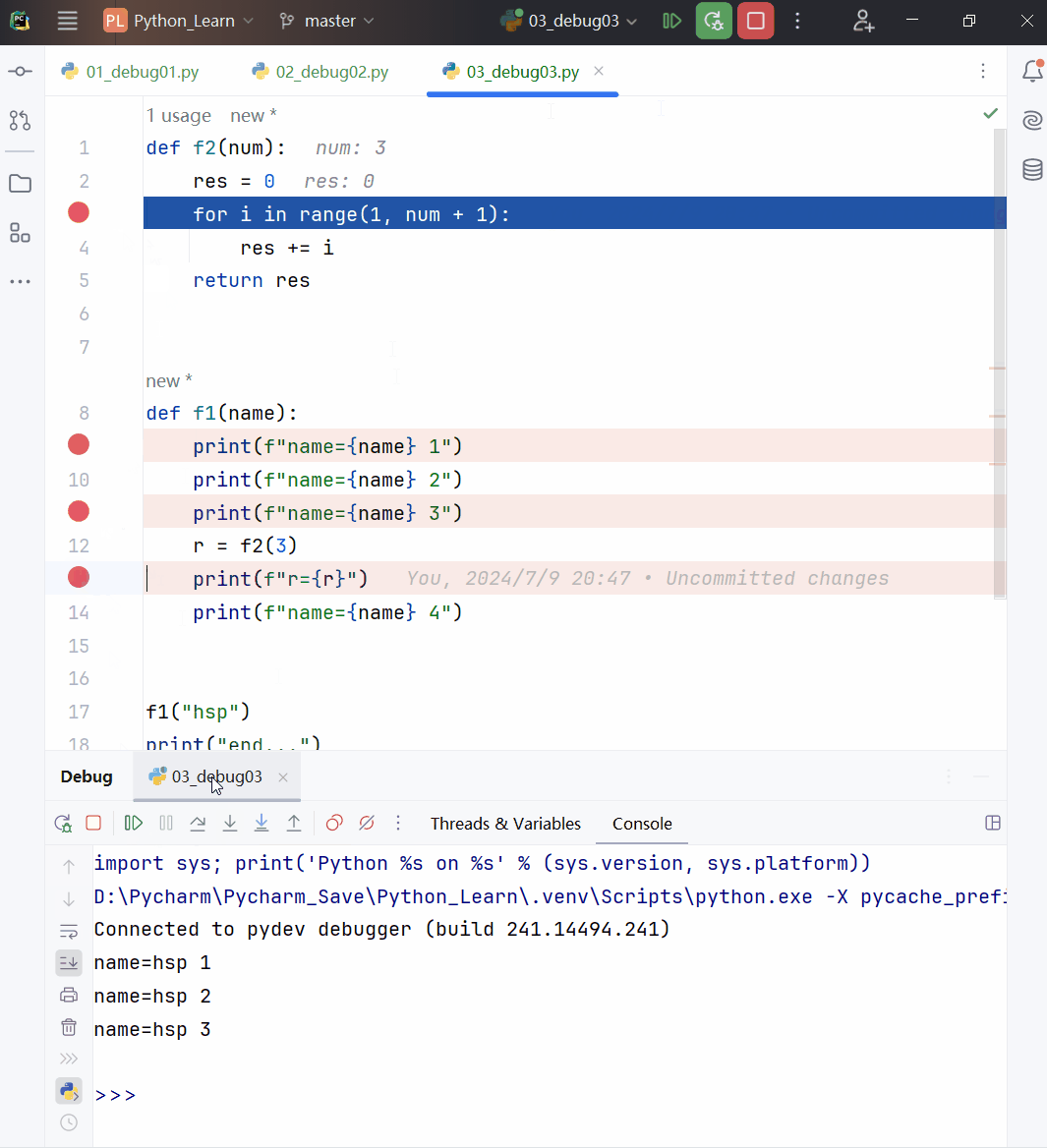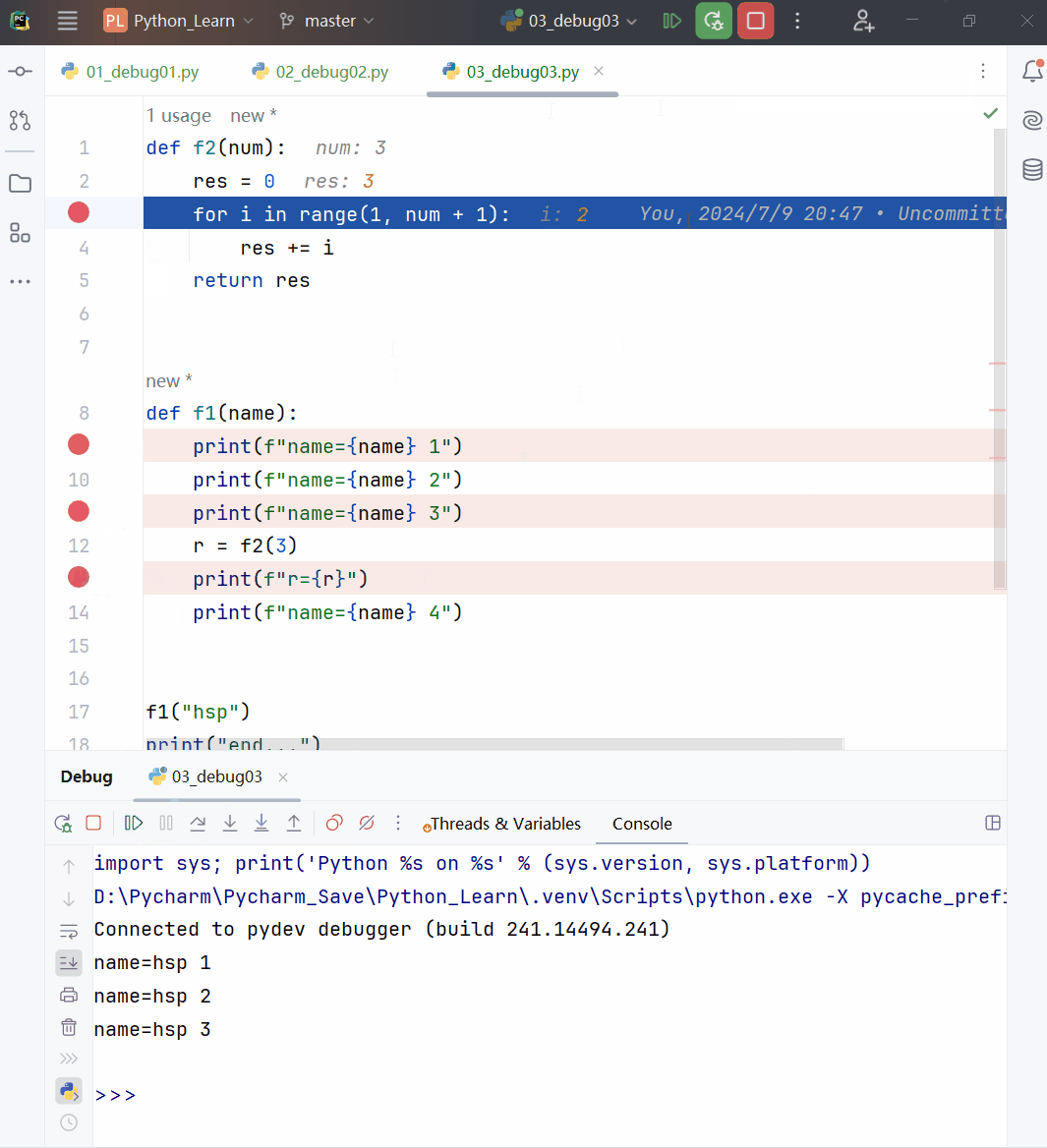
模块和包
快速体验
# jack_module.py
def hi():
print("hi jack")
# tom_module.py
def hi():
print("hi tom")
# 导入模块(文件)
import jack_module
import tom_module
# 使用 jack-hi
jack_module.hi()
# 使用 tom-hi
tom_module.hi()
模块的基本介绍
模块(Module)是什么
- 模块是一个
py文件,后缀名.py。 - 模块可以定义函数、类和变量,模块里也可能包含可执行的代码。
模块的作用有哪些
- 当函数、类和变量很多时,可以很好的进行管理。
- 开发中,程序员可以根据业务需要,把同一类型的功能代码,写到一个模块文件中,即方便管理,也方便调用。
- 一个模块就是一个工具包,供程序员开发使用,提高开发效率。
- Python自带标准模块库,每个模块可以帮助程序员快速实现相关功能。也可根据模块索引查找。
导入模块-import
基本语法
[from 模块名] import (函数 | 类 | 变量 | *) [as 别名]
# [] 是可选项,可以根据需求,选择合适的形式进入导入。
实例演示
- 导入一个或者多个模块
import 模块
import 模块 1, 模块 2, ...
# 导入一个或多个模块,建议导入多个模块时,还是一行导入一个模块。
# 使用:模块.xx 方法来使用相关功能,.表示层级关系,即模块中的 xx。
# import 语句通常写在文件开头。
# import math, random
import math
import random
print(math.fabs(-11.2))
print(random.choice(['a', 'b', 'c']))
- 导入模块的指定功能
from 模块 import 函数、类、变量...
# 导入模块指定功能。
# 使用:因为导入了具体函数、类、变量,直接使用即可,不需要再带模块名。
from math import fabs
print(fabs(-11.2))
- 导入模块的全部功能
from 模块 import *
# 导入模块的全部功能
# 使用:直接使用,不需要带模块名。
from math import *
print(fabs(-234.5))
print(sqrt(9))
- 给导入的模块或者功能取别名
import 模块 as 别名
from 模块 import 函数、类、变量... as 别名
# import 模块 as 别名:给导入的模块取别名,使用:别名.xx。
# from 模块 import 函数、类、变量... as 别名:给导入的某个功能取别名,使用时,直接用别名即可。
import random as r
from math import fabs as fa
print(r.choice([100, 200, 600]))
print(fa(-900.2))
自定义模块
基本介绍
- 自定义模块:在实际开发中,Python提供的标准库模块不能满足开发需求,程序员需要一些个性化的模块,就可以进行自定义模块的实现。
注意事项和细节
- 使用
__name__可以避免模块中测试代码的执行。
# module1.py 文件
def hi():
print("hsp hi")
def ok():
print("hsp ok")
# 测试代码,当导入模块文件时,也会执行测试代码
# hi()
print(f "module1: {__name__}")
# 如果我们不希望导入模块时,去执行测试代码 hi(),可以使用 __name__
if __name__ == "__main__":
hi()
# a.py 文件
# 导入 module1 的所有功能
from module1 import *
hi()
ok()
print(f "a.py: {__name__}")
- 使用
__all__可以控制import *时,哪些功能被导入,注意:import 模块方式,不受__all__的限制。- 在module1.py中,没有
__all__时,会导入所有的功能 - 使用了
__all__=[‘ok’] 在其它文件使用from module1 import *只会导入ok() - 注意:import 模块 方式,不受
__all__的限制
- 在module1.py中,没有
# module1.py 文件
# 表示如果其它文件使用 from module1 import * 导入,则只能导入 ok()函数
__all__ = ["ok"]
def hi():
print("hsp hi")
def ok():
print("hsp ok")
# a.py 文件
# 导入 module1 的所有功能
from module1 import *
# hi() # __all__ = ["ok"],设置了只允许 ok()函数被导入
ok()
# a.py 文件
# import 模块方式,不受 `__all__` 的限制
import module1
module1.hi()
module1.ok()
包
基本介绍
- 从结果上看,包就是一个文件夹,在该文件夹下包含了一个
__init__.py,该文件可以用于包含多个模块文件,从逻辑上看,包可以视为模块集合。 - 包的结构示意图
__init__.py:控制包的导入操作。- 导入包和使用的基本语法
- 导入:
import 包名.模块 - 使用:
包名.模块.功能
- 导入:
快速入门
def hi():
print("module01 hi()...")
def ok():
print("module02 ok()...")
# 导入包下的模块
import package.module01
import package.module02
# 使用导入的模块
package.module01.hi()
package.module02.ok()
注意实现和使用细节
- 导入包基本语法
import 包名.模块from 包名 import 模块- 这种方式导入,在使用时,
模块.功能,不用带包名。
- 这种方式导入,在使用时,
from package import module01
module01.hi()
- 导入包的模块的指定函数、类、变量
from 包名.模块 import 函数、类、变量- 在使用时,直接调用功能。
from 包名.模块 import *:表示导入包的模块的所有功能。
# 导入包的模块的指定函数、类、变量
from package.module01 import hi
# 直接使用功能名调用即可
hi()
# from 包名.模块 import *:表示导入包的模块的所有功能。
from package.module01 import *
hi()
hello()
__init__.py通过__all__控制允许导入的模块- 在
__init__.py中增加__all__==[允许导入的模块列表] - 针对
from 包 import *方式生效,对import xx方式不生效。
- 在
# __init__.py 文件
# 控制包允许导入的模块
__all__ = ['module02']
# __init__.py 通过 __all__ 控制允许导入的模块
from package import *
module02.ok()
# 引入限制了 module01 模块导入,因此不能使用
# module01.hi()
# __all__ = ['module02'] 不能限制下面的导入方式
import package.module01
import package.module02
package.module01.hi()
package.module02.ok()
- 包可以有多个层级
- 包下还可以再创建包。
- 在使用时,通过
.来确定层级关系。
# 使用方式 1
import package.package2.module03
package.package2.module03.cal(10, 20)
# 使用方式 2
from package.package2.module03 import cal
cal(10, 20)
# 使用方式 3
from package.package2 import module03
module03.cal(10, 20)
- 快捷导入
alt + enter:提示你选择解决方案。alt + shift + enter:直接导入。
第三方库
基本介绍
- 第三方库/包:就是非python官方提供的库,python语言有很多的第三方库,覆盖几乎所有领域,比如:网络爬虫、自动化、数据分析和可视化、web开发、机器学习等。
- 使用第三方库,可以大大提高开发效率。
- 常见的第三方库:网络爬虫、自动化、数据分析及可视化、web开发、机器学习等。
pip安装
- 基本使用
- pip介绍:pip 是python的包管理器,是一个工具,允许你安装和管理第三方库和依赖。
- pip使用方式
- 语法:
pip install 库名/包名 - 注意:pip是通过网络安装的,需要网络是连通的
- 语法:
- 快速入门
# 使用 pip 安装 requests
pip list
pip install requests
- 指定pip源
- python pip常用源地址
- 默认的pip源:
https://pypy.python.org/simple,因为在国外,有时候速度比较慢。 - 国内常用源:
- 豆瓣:
https://pypi.douban.com/simple - 清华:
https://pypi.tuna.tsinghua.edu.cn/simple - 阿里云:
https://mirrors.aliyun.com/pypi/simple - 中科大:
https://pypi.mirrors.edu.cn/simple
- 豆瓣:
- 指定源,安装第三方库:
pip install -i 指定源 库名/包名
- 默认的pip源:
- python pip常用源地址
# 使用 pip 指定源安装 requests
pip uninstall requests
pip install -i https://mirrors.aliyun.com/pypi/simple requests
面向对象编程(基础)
类与对象
类与实例的关系
- 类与实例的关系示意图
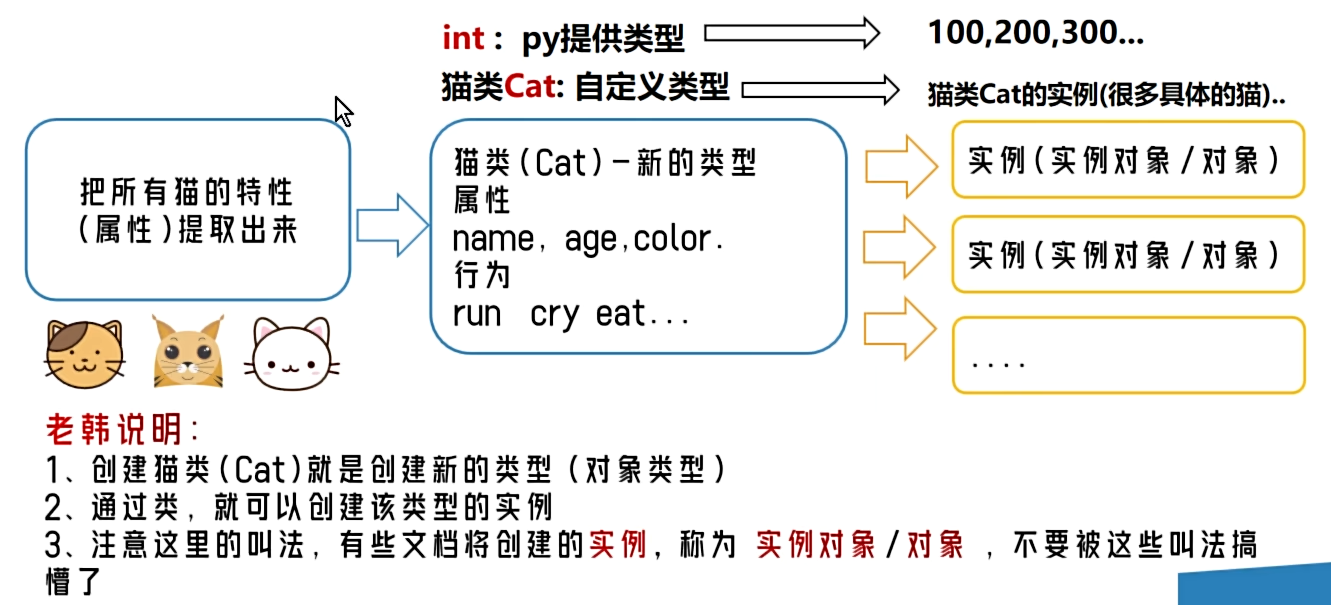
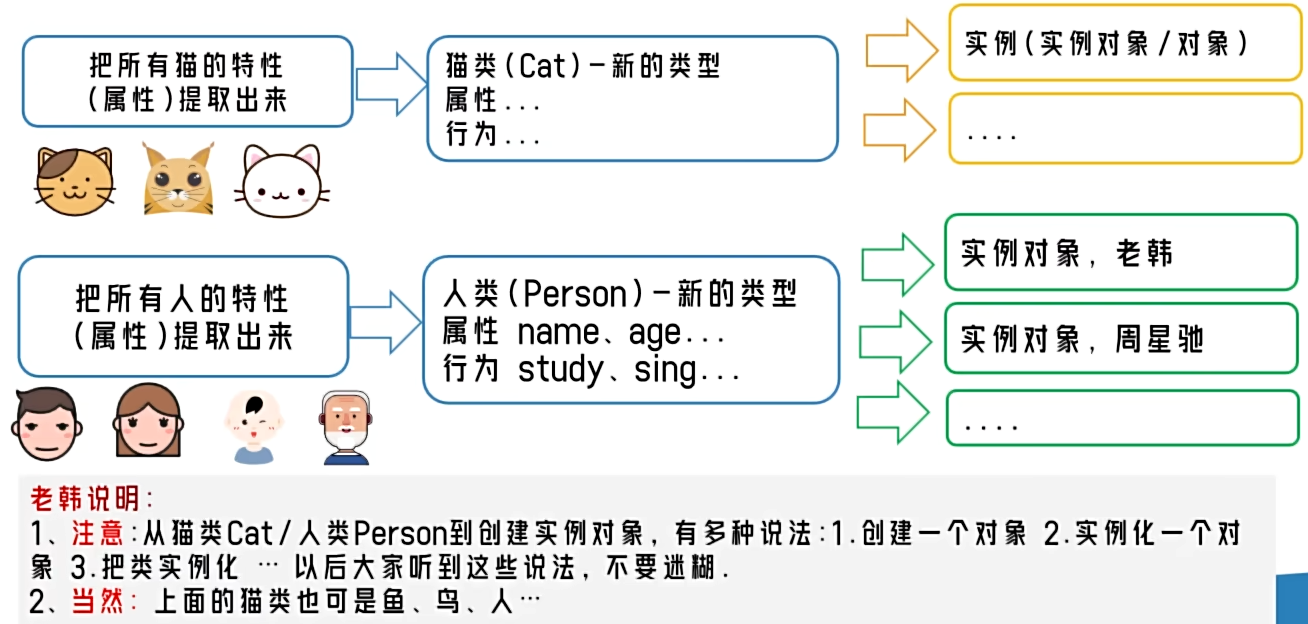
快速入门—面向对象的方式解决养猫问题
# 定义一个猫类,age, name, color 是属性,或者称为成员变量
# Cat 类 就是你自己定义的一个新类型
# 定义 Cat 类
class Cat:
# age, name, color 是属性
age = None # 年龄属性
name = None # 名字属性
color = None # 颜色属性
# 通过 Cat 类,创建实例(实例对象/对象)
cat1 = Cat()
# 通过对象名.属性名 可以给各个属性赋值
cat1.name = "小白"
cat1.age = 2
cat1.color = "白色"
# 通过对象名.属性名,可以访问到属性
print(f "cat1 的信息为:name: {cat1.name} age {cat1.age} color {cat1.color}")
# 小结:通过上面的 oop 解决问题,可以更好地管理小猫的属性
类和对象的区别和联系
- 类是抽象的,概念的,代表一类事物,比如人类,猫类,…,即它是数据类型。
- 对象是具体的,实际的,代表一个具体事物,即是实例。
- 类是对象的模板,对象是类的一个个体,对应一个实例。
对象在内存中的存在形式
- 内存分析图
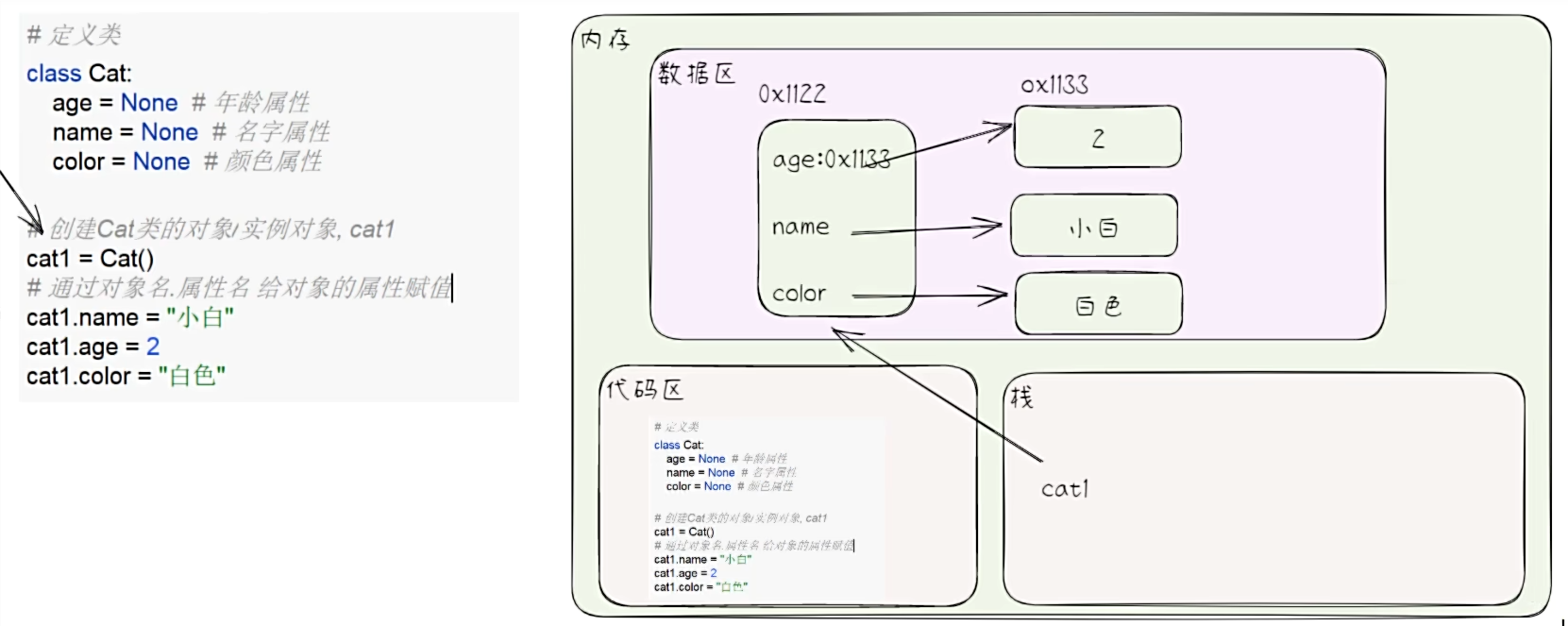
属性/成员变量
- 基本介绍
- 类中定义的属性(变量),我们成为:成员变量。
- 属性是类的一个组成部分,一般是字符串、数值,也可以是其它类型(list、dict等),比如前面定义Cat类的name、age就是属性。
- 注意事项和细节说明
- 属性的定义语法同变量,实例:
属性名 = 值,如果没有值,可以赋值None。- None 是python的内置常量,通常被用来代表空值的对象。
- 如果给属性指定的有值,那么创建的对象属性就有值。
- 属性的定义语法同变量,实例:
# 定义 Cat 类
class Cat:
# age, name, color 是属性
age = 2 # 年龄属性
name = "小白" # 名字属性
color = "白色" # 颜色属性
# 创建对象
cat1 = Cat()
print(f "age:{cat1.age}, name:{cat1.name}, color:{cat1.color}")
类的定义和使用
- 如何定义类
class 类名:
属性...
行为...
# class 是关键字,表示后面定义的是类。
# 属性:定义在类中的变量(成员变量)
# 行为:定义在类中的函数(成员方法)
- 如何创建对象
对象名 = 类名()
# 举例
cat = Cat()
- 如何访问属性
对象名.属性名
# 举例
cat.name
对象的传递机制
class Person:
age = None
name = None
p1 = Person()
p1.age = 10
p1.name = "小明"
p2 = p1
print(p2.age)
print(f "id(p1.name): {id(p1.name)}, id(p2.name): {id(p2.name)}")
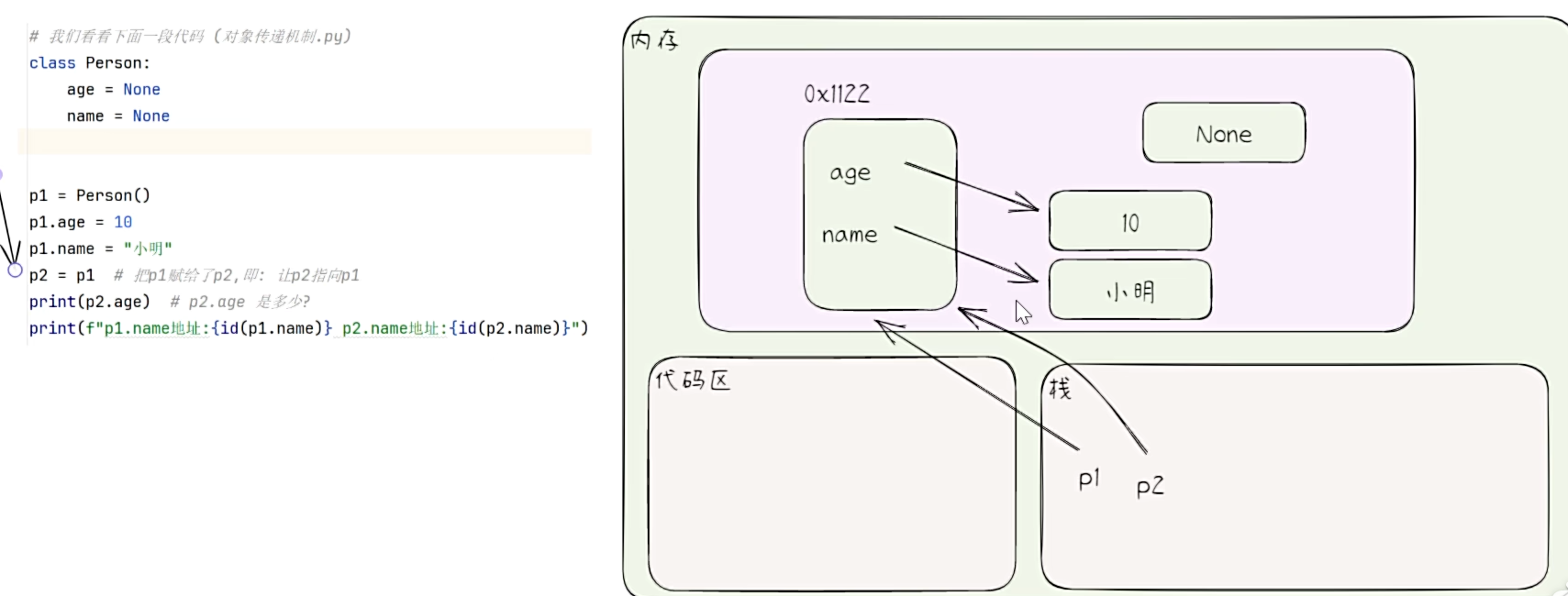
a = Person()
a.age = 10
a.name = "jack"
b = a
print(b.name)
b.age = 200
b = None
print(a.age)
print(b.age) # AttributeError: 'NoneType' object has no attribute 'age'
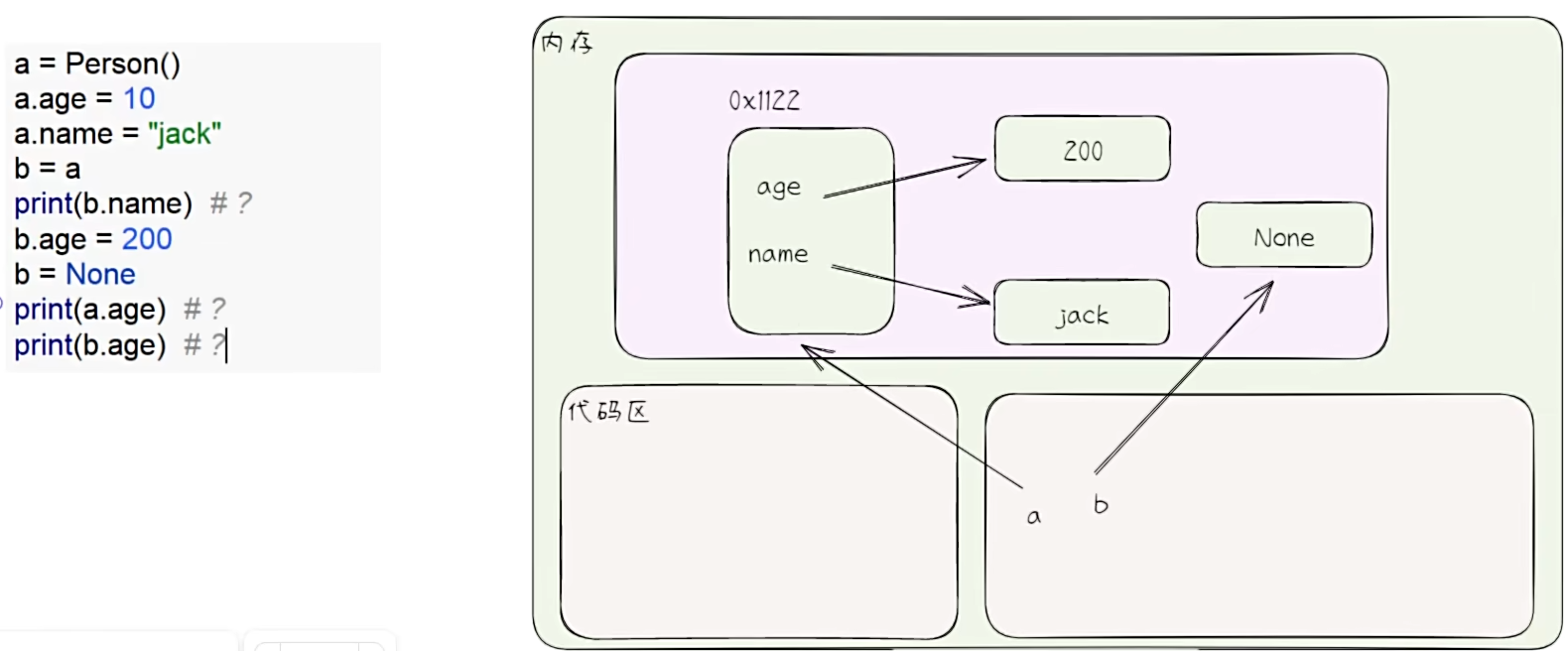
对象的布尔值
- Python一切皆为西,所有对象都有一个布尔值,可以通过内置函数
bool()可以获取对象的布尔值。 - 下面对象的布尔值为False
- False、数值0、None、空字符串、空列表、空字典、空元组、空集合。
print("---下面对象的布尔值为 False---")
print(bool(False))
print(bool(0))
print(bool(None))
print(bool(""))
print(bool([]))
print(bool(()))
print(bool({}))
print(bool(set()))
# 因为所有对象都有一个布尔值,所有有些代码直接使用对象的布尔值做判断
content = "hello"
if content:
print(f "hi {content}")
else:
print("空字符串")
lst = [1, 2]
if lst:
print(f "lst {lst}")
else:
print("空列表")
成员方法
基本介绍
- 类出来有一些属性外,还会有一些行为,比如人类有年龄、姓名等属性,我们人类还有一些行为,比如:可以说话、跑步、…,通过学习,还可以做算术题。这时就要用成员方法才能完成。
class 类名:
属性...
行为...
# 类中定义的行为(函数),我们成为:成员方法/方法
成员方法的定义和使用
- 成员方法的定义
- 在类中定义成员方法和前面学习过的定义函数,基本是一样的(原理和运行机制是一样的),但是还是有点不同(形式上有不同)。
def 方法名(self, 形参列表):
方法体
# 在方法定义的参数列表中,有一个 self
# self 是定义成员方法时,需要写上的
# self 表示当前对象本身
# 当我们通过对象调用方法时,self 会隐式的传入
# 在方法内部,需要使用 self,才能访问到成员变量
- 案例演示
class Person:
age = None
name = None
# 成员方法
def hi(self):
print("hi, python")
def cal01(self):
result = 0
for i in range(1, 1001):
result += i
print(f "result: {result}")
def cal02(self, n):
result = 0
for i in range(1, n + 1):
result += i
print(f "result: {result}")
def get_sum(self, n1, n2):
return n1 + n2
# 测试
p = Person()
p.hi()
p.cal01()
p.cal02(10)
print(p.get_sum(10, 20))
使用细节
- python也支持对象动态的添加方法
# 函数
def hi():
print("hi, python")
# 定义类
class Person:
age = None
name = None
def ok(self):
pass
# 创建对象 p、p2
p = Person()
p2 = Person()
# 动态地给 p 对象添加方法 m1,注意:只是针对 p 对象添加方法
# m1 是你新增加的方法的名称,由程序员指定名称
# 即 m1 方法和函数 hi 关联起来,当调用 m1 方法时,会执行 hi 函数
p.m1 = hi
# 调用 m1(即 hi)
p.m1()
print(type(p.m1), type(hi)) # <class 'function'> <class 'function'>
print(type(p.ok)) # <class 'method'>
# 因为没有动态的给 p2 添加方法,会报错
p2.m1() # AttributeError: 'Person' object has no attribute 'm1'
self
访问对象的属性/成员变量
class Cat:
name = "波斯猫"
age = 2
def info(self, name):
print(f "name: {name}") # 加菲猫
# 通过 self.属性名 可以访问对象的属性/成员变量
print(f "属性 name:{self.name}") # 波斯猫
cat = Cat()
cat.info("加菲猫")
基本介绍
- 基本语法
def 方法名(self, 形参列表):
方法体
# 在方法定义的参数列表中,有一个 self
# self 是定义方法时,需要写上的,如果不写,则需要使用 @staticmethod 标注,否则会报错
# 将方法转换为静态方法:https://docs.python.org/zh-cn/3/library/functions.html#staticmethod
class Dog:
name = "藏獒"
age = 2
def info(self, name):
print(f "name: {name}")
# @staticmethod 可以将普通方法转换为静态方法。
# 如果是一个静态方法,可以不带 self
# 静态方法的调用形式有两种:通过对象调用、通过类名调用
@staticmethod
def ok():
print("ok()...")
dog = Dog()
dog.info("德牧")
# 通过对象调用
dog.ok()
# 通过类名调用
Dog.ok()
- self 表示当前对象本身,简单的说,哪个对象调用,self 就代表哪个对象。
class Dog:
name = "藏獒"
age = 2
def hi(self):
print(f "hi self: {id(self)}")
dog2 = Dog()
print(f "dog2: {id(dog2)}")
dog2.hi()
dog3 = Dog()
print(f "dog3: {id(dog3)}")
dog3.hi()
-
当我们通过对象调用方法时,self 会隐式的传入。
-
在方法内部,要访问成员变量和成员方法,需要使用 self。
# 在方法内部,要访问成员变量和成员方法,需要使用 self。
class Dog:
name = "藏獒"
age = 2
def eat(self):
print(f "{self.name} 饿了...")
def cry(self, name):
print(f "{name} is crying")
print(f "{self.name} is crying")
self.eat()
# 不能直接调用
# eat()
dog = Dog()
# 修改 dog 对象的属性 name
dog.name = "中华田园犬"
dog.cry("金毛")
- 练习题
class Person:
name = None
age = None
def compare_to(self, other):
# 名字和年龄都一样,就返回 True,否则返回 False
return self.name == other.name and self.age == other.age
p1 = Person()
p1.name = "jack"
p1.age = 3
p2 = Person()
p2.name = "jack"
p2.age = 3
print(p1.compare_to(p2))
对象作为参数传递
- 对象的传参机制
class Person:
name = None
age = None
# 分析对象作为参数传递到函数/方法的机制
def f1(person):
print(f "②person 的地址:{id(person)}")
person.name = "james"
person.age += 1
# 创建对象 p1
p1 = Person()
p1.name = "jordan"
p1.age = 21
print(f "①p1 的地址:{id(p1)} p1.name: {p1.name} p1.age: {p1.age}")
f1(p1)
print(f "③p1 的地址:{id(p1)} p1.name: {p1.name} p1.age: {p1.age}")
- 示意图
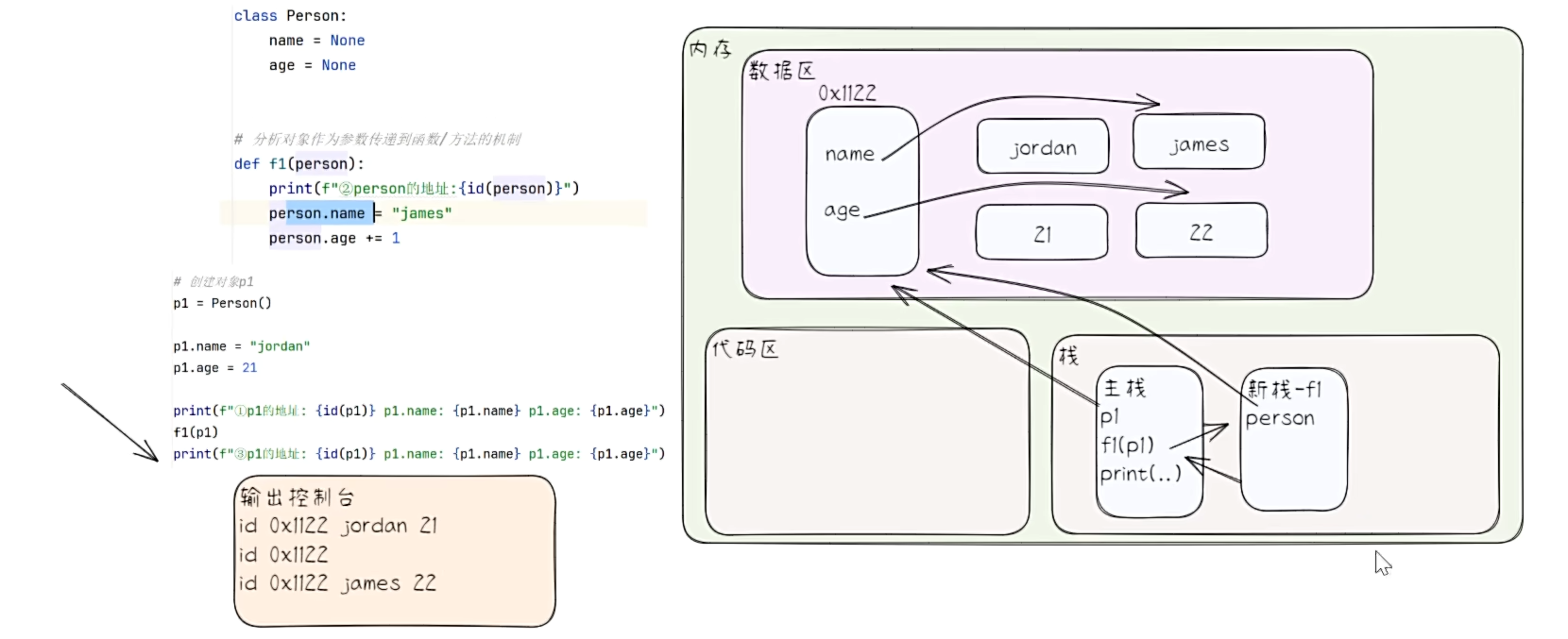
作用域
- 在面向对象编程中,主要的变量就是成员变量(属性)和局部变量。
class Cat:
# 属性(成员变量)
name = None
age = None
# n1, n2, result 就是局部变量
def cal(self, n1, n2):
result = n1 + n2
print(f "result = {result}")
- 我们说的局部变量,一般指在成员方法中定义的变量。
- 作用域的分类:属性作用域为整个类,比如 Cat类:cry eat 等方法使用属性。
class Cat:
# 属性
name = None
age = None
# n1, n2, result 就是局部变量
def cal(self, n1, n2):
result = n1 + n2
print(f "cal() 使用属性 name {self.name}")
def cry(self):
print(f "cry() 使用属性 name {self.name}")
def eat(self):
print(f "eat() 使用属性 name {self.name}")
cat = Cat()
cat.cal(10, 20)
cat.cry()
cat.eat()
- 局部变量:也就是方法中定义的变量,作用域是它在方法中。
- 属性和局部变量可以重名,访问时带上 self,表示访问的属性,没有带 self,则是访问局部变量。
class Cat:
# 属性
name = None
age = None
def hi(self):
name = "皮皮"
print(f "name is {name}")
print(f "self.name is {self.name}")
cat = Cat()
cat.name = "小咪"
cat.hi()
构造方法
基本介绍
def __init__(self, 参数列表):
代码...
- 在初始化对象时,会自动执行
__init__方法 - 在初始化对象时,传入的参数,自动传递给
__init__方法。 - 构造方法是python预定义的,名称是
__init__,注意init前后都有两个_。
# 在初始化对象时,会自动执行 __init__ 方法
class Person:
name = None
age = None
# 构造方法/构造器
# 构造方法是完成对象的初始化任务
def __init__(self, name, age):
print(f "__init__ 执行了 {name} {age}")
# 把接收到的 name 和 age 赋给属性(name, age)
# self 就是你当前创建的对象
print(f "self id: {id(self)}")
self.name = name
self.age = age
# 创建对象
p1 = Person("kobe", 20)
print(f "p1 id: {id(p1)}")
print(f "p1 的信息: {p1.name} {p1.age}")
p2 = Person("tim", 30)
print(f "p2 id: {id(p2)}")
print(f "p2 的信息: {p2.name} {p2.age}")
注意事项和使用细节
- 一个类只有一个
__init__方法,即使你写了多个,也只有最后一个生效。
class Person:
name = None
age = None
def __init__(self, name, age):
print(f "__init__ 执行了... 得到了{name} {age}")
self.name = name
self.age = age
def __init__(self, name):
print(f " __init__ 执行了~~ 得到了{name}")
self.name = name
# TypeError: Person.__init__() takes 2 positional arguments but 3 were given
# p1 = Person("tim", 20)
# 后面的 __init__()生效
p1 = Person("tim")
print(f "p1 的 name ={p1.name} age ={p1.age}")
- python实现多个构造方法。
- python可以动态的生成对象属性。
# 为了代码简洁,我们也可以通过 __init__ 动态的生成对象属性
# python 可以动态的生成对象属性。
class Person:
def __init__(self, name, age):
print(f "__init__ 执行了... 得到了{name} {age}")
# 将接收到的 name 和 age 赋给当前对象的 name 和 age 属性
# python 支持动态生成对象属性
self.name = name
self.age = age
p1 = Person("tim", 30)
print(f "p1 的 name ={p1.name} age ={p1.age}")
- 构造方法不能有返回值。
class Person:
def __init__(self, name, age):
print(f "__init__ 执行了... 得到了{name} {age}")
self.name = name
self.age = age
return "hello" # TypeError: __init__() should return None, not 'str'
练习
1、编写A01,定义方法max_lst,实现求某个float 列表list = [1.1, 2.9, -1.9, 67.9]的最大值,并返回。
# 1、编写 A01,定义方法 max_lst,实现求某个 float 列表 list = [1.1, 2.9, -1.9, 67.9] 的最大值,并返回。
"" "
思路分析
1. 类名:A01
2. 方法:max_lst(self, lst), 功能:返回列表的最大值
"" "
class A01:
def max_lst(self, lst):
return max(lst)
# 测试
a = A01()
print("最大值:", a.max_lst([1.1, 2.9, -1.9, 67.9]))
2、编写类Book,定义方法update_price,实现更改某本书的价格,具体:如果价格>150,则更改为150,如果价格>100,更改为100,否则不变。
# 2、编写类 Book,定义方法 update_price,实现更改某本书的价格,具体:如果价格 > 150,则更改为 150,如果价格 > 100,更改为 100,否则不变。
"" "
思路分析:
类名:Book
属性:name, price
构造器:__init__(self, name, price)
方法:update_price, 功能:如果价格 > 150,则更改为 150,如果价格 > 100,更改为 100,否则不变。
"" "
class Book:
def __init__(self, name, price):
self.name = name
self.price = price
def update_price(self):
# 如果价格 > 150,则更改为 150,如果价格 > 100,更改为 100,否则不变。
if self.price > 150:
self.price = 150
elif self.price > 100:
self.price = 100
def info(self):
# 输出书籍的信息
print(f "书的信息:{self.name} {self.price}")
book = Book("天龙八部", 99)
book.info()
book.update_price()
book.info()
3、定义一个圆类Circle,定义属性:半径,提供显示圆周长功能的方法,提供显示圆面积的方法。
# 定义一个圆类 Circle,定义属性:半径,提供显示圆周长功能的方法,提供显示圆面积的方法。
"" "
思路分析:
类名:Circle
属性:radius
构造器:__init_(self, radius)
方法:len(self) 显示圆周长
方法:area(self) 显示圆面积
"" "
import math
class Circle:
def __init__(self, radius):
self.radius = radius
def len(self):
len = 2 * math.pi * self.radius
print("周长:", round(len, 2))
def area(self):
area = math.pi * (self.radius ** 2)
print("面积:", round(area, 2))
# 测试
circle = Circle(5)
circle.len()
circle.area()
4、编程创建一个Cal计算类,在其中定义2个成员变量表示两个操作数,定义四个方法实现求和、差、乘、商(要求除数为0的话,要提示)并创建对象,分别测试。
# 编程创建一个 Cal 计算类,在其中定义 2 个成员变量表示两个操作数,定义四个方法实现求和、差、乘、商(要求除数为 0 的话,要提示)并创建对象,分别测试
"" "
思路分析:
类名:Cal
属性:num1, num2
构造器/构造方法:__init__(self, num1, num2)
定义四个方法实现求和 def sum(), 求差 def minus(), 求积 def mul(), 求商 def div()
商(要求除数为 0 的话,要提示)
"" "
class Cal:
def __init__(self, num1, num2):
self.num1 = num1
self.num2 = num2
def sum(self):
return self.num1 + self.num2
def minus(self):
return self.num1 - self.num2
def mul(self):
return self.num1 * self.num2
def div(self):
if self.num2 == 0:
print("num2 不能为 0")
else:
return self.num1 / self.num2
cal = Cal(1, 0)
print("和 =", cal.sum())
print("差 =", cal.minus())
print("积 =", cal.mul())
print("商 =", cal.div())
5、定义Music类,里面有音乐名name,音乐时长times属性,并有播放play功能,和返回本身属性信息的方法get_info。
# 定义 Music 类,里面有音乐名 name,音乐时长 times 属性,并有播放 play 功能,和返回本身属性信息的方法 get_info
"" "
思路分析:
类名:Music
属性:name, times
构造器:__init__(self, name, times)
方法:play, get_info
"" "
class Music:
def __init__(self, name, times):
self.name = name
self.times = times
def play(self):
print(f "音乐名 {self.name} 正在播放中... 时长为 {self.times}")
def get_info(self):
return f "音乐的信息: name:{self.name} times:{self.times}"
# 测试
music = Music("月光曲", 300)
music.play()
print(music.get_info())
6、分析下列代码输出结果。
class Demo:
i = 100
def m(self):
self.i += 1
j = self.i
print("i =", self.i)
print("j =", j)
d1 = Demo()
d2 = d1
d2.m()
print(d1.i)
print(d2.i)
"" "
输出结果:
i = 101
j = 101
101
101
"" "
7、石头剪刀布游戏,0表示石头,1表示剪刀,2表示布。
import random
class Tom:
def __init__(self):
self.wins = 0
self.losses = 0
self.choices = ['石头', '剪刀', '布']
def play(self):
user_choice = int(input("请输入你的选择(0 = 石头,1 = 剪刀,2 = 布):"))
if user_choice not in [0, 1, 2]:
print("输入错误,请输入 0、1 或 2。")
return
computer_choice = random.randint(0, 2)
print(f "Tom 的选择是:{self.choices [user_choice]},电脑的选择是:{self.choices [computer_choice]}")
if user_choice == computer_choice:
print("平局!")
elif (user_choice == 0 and computer_choice == 1) or \
(user_choice == 1 and computer_choice == 2) or \
(user_choice == 2 and computer_choice == 0):
print("Tom 赢了!")
self.wins += 1
else:
print("Tom 输了!")
self.losses += 1
def show_scores(self):
print(f "Tom 的赢的次数:{self.wins},输的次数:{self.losses}")
# 使用示例
tom = Tom()
tom.play()
tom.play()
tom.show_scores()
面向对象编程(进阶)
面向对象编程三大特征
- 面向对象编程有三大特征:封装、继承、多态。
面向对象编程—封装
封装介绍
- 封装(encapsulation)就是把抽象出的数据[属性]和对数据的操作[方法]封装在一起,数据被保护在内部。
- 程序只有通过被授权的操作,才能对数据进行访问。
- 封装经典案例:电视机的操作就是典型封装。
封装的理解和好处
- 隐藏实现细节:方法(绘制柱状图)<——调用(传入参数…)。
- 可以对数据进行验证(比如:age: 1~120、password: 长度要求),保证安全合理。
- 可以保护数据隐私(比如salary),要求授权才可以访问。
私有成员
- 公共的变量和方法介绍。
- 默认情况下,类中的变量和方法都是公有的,它们的名称前都没有下划线。
- 公共的变量和方法,在类的外部、类的内部,都可以正常访问。
- 如何将属性/方法进行私有化。
- 类中的变量或方法以双下划线
__开头命名,则该变量或方法为私有的,私有的变量或方法,只能在本类内部使用,类的外部无法使用。
- 类中的变量或方法以双下划线
- 如何访问私有的属性/方法:提供公共的方法,用于对私有成员的操作。
快速入门
# 创建职员类(Clerk),属性:name, job, salary
# 1、不能随便查看职员 Clerk 的职位和工资等隐私,比如职员 ("tiger", "python 工程师", 20000)
# 2、提供公共方法,可以对职员和工资进行操作
class Clerk:
# 公共属性
name = None
# 私有属性
__job = None
__salary = None
# 构造方法
def __init__(self, name, job, salary):
self.name = name
self.__job = job
self.__salary = salary
# 提供公共的方法,对私有属性操作(根据实际的业务编写即可)
def set_job(self, job):
self.__job = job
def get_job(self):
return self.__job
# 私有方法
def __hi(self):
print("hi()")
# 提供公共方法,操作私有方法
def f1(self):
self.__hi()
clerk = Clerk("tiger", "python 工程师", 20000)
print(clerk.name)
# print(clerk.__job) # AttributeError: 'Clerk' object has no attribute '__ job'
print(clerk.get_job())
clerk.set_job("Java 工程师")
print(clerk.get_job())
# 私有方法不能在类的外部直接调用
# clerk.hi() # AttributeError: 'Clerk' object has no attribute 'hi'
# 通过公共方法,调用私有方法
clerk.f1()
注意事项和细节
- python语言的动态特性,会出现伪私有属性的情况
class Clerk:
# 公共属性
name = None
# 私有属性
__job = None
__salary = None
# 构造方法
def __init__(self, name, job, salary):
self.name = name
self.__job = job
self.__salary = salary
# 提供公共的方法,对私有属性操作
def get_job(self):
return self.__job
clerk = Clerk("apple", "python 工程师", 20000)
# 如果这样使用,因为 python 语言的动态特性,会动态的创建属性 __job,但是这个属性和我们在类中定义的私有属性 __ job 不是同一个变量,我们在类中定义的__job 私有属性完整的名字是 _Clerk__job,而并不是
# 可以通过 debug 的“Evaluate Expression”来观察。
clerk.__job = "Go 工程师"
print(f " job = {clerk.__job}") # job = Go 工程师
# 获取真正的私有属性__job
print(f "{clerk.get_job()}")
- 练习
# Account 类要求具有属性:姓名(长度为 2-4 位)、余额(必须 > 20)、密码(必须是六位),如果不满足,则给出提示
# 通过 set_xx 的方法给 Account 的属性赋值
# 编写 query_info() 接收姓名和密码,如果姓名和密码正确,返回该账号信息
"" "
思路分析:
类名:Account
私有属性:姓名(长度为 2-4 位)、余额(必须 > 20)、密码(必须是六位)
构造器:无
方法:set_xx(self, 属性名) 进行赋值,并且对各个接收到的数据进行校验
方法:query_info(self, name, pwd) 而且需要验证,才返回响应信息
"" "
class Account:
__name = None
__balance = None
__pwd = None
def set_name(self, name):
if 2 <= len(name) <= 4:
self.__name = name
else:
print("名字的长度不在 2-4 位之间")
def set_balance(self, balance):
if balance > 20:
self.__balance = balance
else:
print("余额(必须 > 20)")
def set_pwd(self, pwd):
if len(pwd) == 6:
self.__pwd = pwd
else:
print("密码(必须是六位)")
def query_info(self, name, pwd):
if name == self.__name and pwd == self.__pwd:
return f "账户信息:{self.__name} {self.__ balance}"
else:
return "请输入正确的名字和密码"
# 测试
account = Account()
account.set_name("tim")
account.set_pwd("000000")
account.set_balance(100)
print(account.query_info("tim", "000000"))
面向对象编程—继承
基本介绍
-
继承基本介绍
- 基础可以解决代码复用,让我们的编程更加靠近人类思维。
- 当多个类存在相同的属性(成员变量)和方法时,可以从这些类中抽象出方法,在父类中定义这些相同的属性和方法,所有的子类不需要重新定义这些属性和方法。
-
示意图
- 基本语法
class DerivedClassName(BaseClassName):
<statement-1>
...
<statement-N>
# 派生类就会自动拥有基类定义的属性和方法
# 基类习惯上也叫父类
# 派生类习惯上也叫子类
快速入门
# 编写父类
class Student:
name = None
age = None
__score = None
def __init__(self, name, age):
self.name = name
self.age = age
def show_info(self):
print(f " name ={self.name}, age ={self.age}, score ={self.__score}")
def set_score(self, score):
self.__score = score
# 小学生类,继承 Student
class Pupil(Student):
def testing(self):
print("小学生在考小学数学...")
# 大学生类,继承 Student
class Graduate(Student):
def testing(self):
print("大学生在考高等数学...")
# 测试
student1 = Pupil("apple", 10)
student1.testing()
student1.set_score(70)
student1.show_info()
student2 = Graduate("grape", 22)
student2.testing()
student2.set_score(80)
student2.show_info()
- 继承给编程带来的便利
- 代码的复用性提高了。
- 代码的扩展性和维护性提高了。
继承的注意事项和细节
- 子类继承了所有的属性和方法,非私有的属性和方法可以在子类直接访问,但是私有属性和方法在子类不能在子类直接访问,要通过父类提供公共的方法去访问。
# 子类继承了所有的属性和方法,非私有的属性和方法可以在子类直接访问,但是私有属性和方法在子类不能在子类直接访问,要通过父类提供公共的方法去访问。
class Base:
# 公共属性
n1 = 100
# 私有属性
__n2 = 200
def __init__(self):
print("Base 构造方法")
def hi(self):
print("hi() 公共方法")
def __hello(self):
print("__hello() 私有方法 ")
# 提供公共方法,访问私有属性和私有方法
def test(self):
print("属性:", self.n1, self.__n2)
self.__hello()
class Sub(Base):
def __init__(self):
print("Sub 构造方法")
def say_ok(self):
print("say_ok() ", self.n1)
self.hi()
# print(self.__n2) # AttributeError: 'Sub' object has no attribute '_Sub__n2'
# self.__hello() # AttributeError: 'Sub' object has no attribute '_Sub__n2'
# 测试
sub = Sub()
sub.say_ok()
# 调用子类继承父类的公共方法,去实现访问父类的私有成员的效果
sub.test()
-
Python语言中,
object是所有其它类的基类。Ctrl + H可以查看一个类的继承关系。 -
Python支持多继承。
class A:
n1 = 100
def sing(self):
print("A sing()...", self.n1)
class B:
n2 = 200
def dance(self):
print("B dance()...", self.n2)
class C(A, B):
# Python pass 是空语句,是为了保持程序结构的完整;pass 不做任何事情,一般用作站位语句。
pass
c = C()
# 继承的属性信息
print(f "属性信息:{c.n1} {c.n2}")
# 调用继承的方法
c.dance()
c.sing()
- 在多重继承中,如果有同名的成员,遵守从左到右的继承优先级(即:写在左边的父类优先级高,写在右边的父类优先级低)。
class A:
n1 = 100
def sing(self):
print("A sing()...", self.n1)
class B:
n2 = 200
def dance(self):
print("B dance()...", self.n2)
def sing(self):
print("B sing()...", self.n2)
class C(A, B):
# Python pass 是空语句,是为了保持程序结构的完整;pass 不做任何事情,一般用作站位语句。
pass
c = C()
# 继承的属性信息
print(f "属性信息:{c.n1} {c.n2}")
# 调用继承的方法
c.dance()
c.sing() # A sing()... 100
继承的练习题
class GrandPa:
name = "大头爷爷"
hobby = "旅游"
class Father(GrandPa):
name = "大头爸爸"
age = 39
class Son(Father):
name = "大头儿子"
son = Son()
print(f "son.name is {son.name} and son.age is {son.age} and son.hobby is {son.hobby}")
class Computer:
cpu = None
memory = None
disk = None
def __init__(self, cpu, memory, disk):
self.cpu = cpu
self.memory = memory
self.disk = disk
def get_details(self):
return f "CPU: {self.cpu}, Memory: {self.memory}, Disk: {self.disk}"
class PC(Computer):
brand = None
def __init__(self, cpu, memory, disk, brand):
# 初始化子类的属性——方式 1
# self.cpu = cpu
# self.memory = memory
# self.disk = disk
# self.brand = brand
# 初始化子类的属性——方式 2
# 通过 super().xx 方式可以去调用父类方法,这里通过 super().__init__(cpu, memory, disk, brand) 去调用父类的构造器
super().__init__(cpu, memory, disk)
self.brand = brand
def print_info(self):
print(f "品牌:{self.brand}\t{self.get_details()}")
pc = PC("inter", 32, 1000, "戴尔")
pc.print_info()
调用父类成员
基本介绍&实例
- 基本介绍
- 如果子类和父类出现同名的成员,可以通过
父类名、super()访问父类的成员。
- 如果子类和父类出现同名的成员,可以通过
- 基本语法
- 访问父类成员方式1
- 访问成员变量:
父类名.成员变量 - 访问成员方法:
父类名.成员方法(self)
- 访问成员变量:
- 访问父类成员方式2
- 访问成员变量:
super().成员变量 - 访问成员方法:
super().成员方法()
- 访问成员变量:
- 访问父类成员方式1
- 案例演示
class A:
n1 = 100
def run(self):
print("A-run()...")
class B(A):
n1 = 200
def run(self):
print("B-run()...")
# 通过父类名去访问父类的成员
def say(self):
print(f "父类的 n1 ={A.n1} 本类的 n1 ={self.n1}")
# 调用父类的 run
A.run(self)
# 调用本类的 run()
self.run()
# 通过 super()方式去访问父类对象
def hi(self):
print(f "父类的 n1 ={super().n1}")
b = B()
b.say()
b.hi()
注意事项和使用细节
- 子类不能直接访问父类的私有成员
class A:
n1 = 100
__n2 = 600
def run(self):
print("A-run()...")
def __jump(self):
print("A-jump()...")
class B(A):
# 子类不能直接访问父类的私有成员
def say(self):
# print(A.__n2) # AttributeError: type object 'A' has no attribute '_B_ _n2'. Did you mean: '_A__n2'?
# print(super().__n2) # AttributeError: 'super' object has no attribute '_B__n2'
# A.__jump(self)
# super().jump()
print("B-say()...")
b = B()
b.say()
- 访问不限于直接父类,而是建立从子类向上级父类的查找关系 A->B->C…
class Base:
n3 = 800
def fly(self):
print("Base-fly()...")
class A(Base):
n1 = 100
__n2 = 600
def run(self):
print("A-run()...")
def __jump(self):
print("A-jump()...")
class B(A):
# 访问不限于直接父类,而是建立从子类向上级父类的查找关系 B-> A-> Base...
def say(self):
print(Base.n3, A.n3, super().n3)
Base.fly(self)
A.fly(self)
super().fly()
self.fly()
b = B()
b.say()
- 建议使用
super()的方式,因为如果使用父类名方式,一旦父类变化,类名统一需要修改,比较麻烦。
练习题
- 分析下面的代码,看看输出什么内容?
class A:
n1 = 300
n2 = 500
n3 = 600
def fly(self):
print("A-fly()...")
class B(A):
n1 = 200
n2 = 400
def fly(self):
print("B-fly()...")
class C(B):
n1 = 100
def fly(self):
print("C-fly()...")
def say(self):
print(self.n1) # 100
print(self.n2) # 400
print(self.n3) # 600
print(super().n1) # 200
print(B.n1) # 200
print(C.n1) # 100
c = C()
c.say()
- 针对上面的程序,想在C的say()中,调用C的fly()和A的fly(),应该如何调用?
self.fly() # C-fly()...
A.fly(self) # A-fly()...
方法重写
基本介绍&实例
- 基本介绍
- 重写又称覆盖(override),即子类继承父类的属性和方法后,根据业务需要,再重新定义同名的属性和方法。
- 案例演示

练习题
class Person:
name = None
age = None
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
return f "名字:{self.name} 年龄:{self.age}"
class Student(Person):
id = None
score = None
def __init__(self, id, score, name, age):
# 调用父类的构造器完成继承父类的属性和属性的初始化
super().__init__(name, age)
# 子类的特有的属性,我们自己完成初始化
self.id = id
self.score = score
def say(self):
return f "id:{self.id} score:{self.score} {super().say()}"
person = Person("tom", 12)
print(person.say())
student = Student("tom", 14, "tom", 18)
print(student.say())
类型注解-type hint
基本介绍
- 为什么需要类型注解
- 随着项目越来越大,代码也就会越来越多,在这种情况下,如通过没有类型注解,很容易不记得某一个方法的参数类型是什么。
- 一旦传入了错误类型的参数,python是解释性语言,只有运行时候才能发现问题,这对大项目来说是一个巨大的灾难。
# 对字符串进行遍历
# a: str 给形参 a 进行类型注解,标注 a 的类型是 str。
def fun1(a: str):
for ele in a:
print(ele)
# Ctrl + P 提示参数时,没有类型提示
# 如果类型传错了,就会出现异常
fun1(100) # TypeError: 'int' object is not iterable
- 类型注解作用和说明
- 从Python3.5开始,引入了类型注解机制,作用和说明如下:
- 类型提示,防止运行时出现参数类型、返回值类型、变量类型不符合。
- 作为开发文档附加说明,方便使用者调用时传入和返回类型参数。
- 加入后并不会影响程序的运行,不会报正式的错误,只有提示。
- Pycharm支持类型注解,参数类型错误会黄色提示。
- 从Python3.5开始,引入了类型注解机制,作用和说明如下:
变量的类型注释
-
基本语法:
变量: 类型。 -
基础数据类型注解
n1: int = 10 # 对n1进行类型注解,标注n1的类型为int;如果给出的类型与标注的类型类型不一致,则Pycharm会给出黄色警告
n2: float = 10.1
is_pass: bool = True
name: str = "Tom"
- 实例对象类型注解
class Cat:
pass
cat: Cat = Cat() # 对cat进行类型注解,标注cat类型是Cat
- 容器类型注解
my_list: list = [1, 2, 3] # 对my_list进行类型注解,标注my_list类型为list。
my_tuple: tuple = ("run", "sing", "fly")
my_set: set = {1, 2, 3}
my_dict: dict = {"name": "Tom", "age": 22}
- 容器详细类型注解
my_list1: list[int] = [1, 2, 3] # 对my_list1进行类型注解,标注my_list1类型是list,而且该list元素是int。
# 元组类型设置详细类型注解,需要把每个元素类型都标注一下
my_tuple1: tuple[str, str, str, float] = ("run", "sing", "fly", 1.1)
my_set1: set[int] = {1, 2, 3}
# 字典类型设置详细类型注解,需要设置两个类型,即[key类型, value类型]
# 对my_dict1进行类型注解,标注my_dict1类型是dict,而且key的类型是str,values的类型是int。
my_dict1: dict[str, int] = {"score": 100, "score2": 80}
- 在注释中使用注解
- 基本语法:
# type: 类型。
- 基本语法:
# # type: float 用于标注变量n3的类型是float。
n3 = 89.9 # type: float
my_list3 = [100, 200, 300] # type: list[int]
email = "hsp@sohu.com" # type: str
函数(方法)的类型注解
- 基本语法
def 函数/方法名(形参名: 类型, 形参名: 类型 ...) -> 返回值类型:
函数/方法体
- 实例演示
# 对字符串进行遍历
# name: str 对形参name进行类型注解:标注name类型是str;在调用方法/函数时,传入的实参类型不是一样的,则给出黄色的警告。
def fun1(name: str):
for ele in name:
print(ele)
fun1("hsp")
# 接收两个整数,返回整数
# a: int, b: int 对形参a、b进行类型注解,标注a、b的类型为int; -> int 对返回值进行类型注解,标注返回值的类型为int。
def fun2(a: int, b: int) -> int:
return a + b
print(f"结果是:{fun2(1, 2)}")
类型注解是提示性的,并不是强制性的,如果你给的类型和指定/标注的类型不一致,Pycharm检测到会给出黄色警告,但是仍然可以运行。
Union类型
- 基本介绍
- Union类型可以定义联合类型注解。
- 在变量、函数(方法)都可以使用Union联合类型注解。
- 使用的时候,需要先导入Union:
from typing import Union。
- 基本语法
Union[类型, 类型...]
比如:联合类型:Union[X, Y] 等价于 X|Y,意味着满足X或Y之一。
- 实例演示
from typing import Union
# 联合类型注解, a可以是int或str
a: Union[int, str] = 100
# my_list是str类型,元素可以是int或str
my_list: list[Union[int, str]] = [1, 2, 3, "tom"]
# 函数/方法使用联合函数注解
# 接收两个数(可以是int/float),返回数(int/float)
def cal(num1: Union[int, float], num2: Union[int, float]) -> Union[int, float]:
return num1 + num2
print(cal(1, 2.1))
面向对象编程—多态
问题引入
- Master类中有一个feed(喂食)方法,可以完成主人给动物喂食物的信息。
# 使用传统的方式
class Food:
name = None
def __init__(self, name):
self.name = name
class Fish(Food):
pass
class Bone(Food):
pass
class Animal:
name = None
def __init__(self, name):
self.name = name
class Dog(Animal):
pass
class Cat(Animal):
pass
class Master:
name = None
def __init__(self, name):
self.name = name
# 给猫喂鱼
def feed_cat(self, cat: Cat, fish: Fish):
print(f"主任{self.name} 给动物{cat.name} 喂{fish.name}")
# 给狗喂骨头
def feed_dog(self, dog: Dog, bone: Bone):
print(f"主人{self.name} 给动物{dog.name} 喂{bone.name}")
master = Master("老韩")
cat = Cat("小花猫")
fish = Fish("黄花鱼")
dog = Dog("大黄狗")
bone = Bone("大棒骨")
master.feed_cat(cat, fish)
master.feed_dog(dog, bone)
- 传统方法带来的问题:代码的复用性不高,而且不利于代码维护和功能扩展。解决方法是使用多态。
多态介绍
- 多态
- 多态顾名思义即多种状态,不同的对象调用相同的方法,表现出不同的状态,称为多态。
- 多态通常作用在继承关系上。
- 举例说明:一个父类,具有多个子类,不同的子类对象调用相同的方法,执行的时候产生不同的状态,就是多态。
- 代码演示
class Animal:
def cry(self):
pass
class Cat(Animal):
def cry(self):
print("喵喵喵")
class Dog(Animal):
def cry(self):
print("汪汪汪")
class Pig(Animal):
def cry(self):
print("噜噜噜")
# 在Python面向对象编程中,子类对象可以传递给父类类型
def func(animal: Animal):
print(f"animal类型:{type(animal)}")
animal.cry()
cat = Cat()
dog = Dog()
pig = Pig()
func(cat)
func(dog)
func(pig)
-
多态的好处
- 增加了程序的灵活性,以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal),代码说明。
- 增加了程序的可扩展性,通过继承Animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用。
-
Python多态特点
- Python中函数/方法的参数是没有类型限制的,所以多态在Python中的体现并不是很严谨(与Java等强类型语言比)。
- Python并不要求严格的继承体系,关注的不是对象的类型本身,而是它是否具有要调用的方法(行为)。
class AA:
def hi(self):
print("AA-hi()...")
class BB:
def hi(self):
print("BB-hi()...")
def test(obj):
obj.hi()
aa = AA()
bb = BB()
test(aa)
test(bb)
二说喂动物问题
# 使用多态的方式
class Food:
name = None
def __init__(self, name):
self.name = name
class Fish(Food):
pass
class Bone(Food):
pass
class Animal:
name = None
def __init__(self, name):
self.name = name
class Dog(Animal):
pass
class Cat(Animal):
pass
# 扩展 Horse、Grass,体会多态的机制带来的好处
class Horse(Animal):
pass
class Grass(Food):
pass
class Master:
name = None
def __init__(self, name):
self.name = name
def feed(self, animal: Animal, food: Food):
print(f"主人{self.name} 给动物{animal.name} 喂{food.name}")
master = Master("老韩")
cat = Cat("小花猫")
fish = Fish("黄花鱼")
dog = Dog("大黄狗")
bone = Bone("大棒骨")
horse = Horse("枣红马")
grass = Grass("嫩草")
master.feed(cat, fish)
master.feed(dog, bone)
master.feed(horse, grass)
isinstance函数
- 基本说明
- isinstance() 用于判断对象是否为某个类或其子类的对象
- 基本语法:
isinstance(object, classinfo)。- object:对象。
- classinfo:可以是类名、基本类型或者由它们组成的元组。
class AA:
pass
class BB(AA):
pass
class CC:
pass
obj = BB()
obj2 = AA()
print(f"obj 是不是BB的对象 {isinstance(obj, BB)}")
print(f"obj 是不是AA的对象 {isinstance(obj, AA)}")
print(f"obj 是不是CC的对象 {isinstance(obj, CC)}")
num = 9
print(f"num 是不是int:{isinstance(num, int)}")
print(f"num 是不是str:{isinstance(num, str)}")
print(f"num 是不是str/int/list:{isinstance(num, (str, int, list))}")
练习
- 分析代码输出结果。
当调用对象成员的时候,会和对象本身动态关联。
class A:
i = 10
def sum(self):
# self是A还是B?——B
# 当调用对象成员的时候,会和对象本身动态关联
return self.getI() + 10
def sum1(self):
return self.i + 10
def getI(self):
return self.i
class B(A):
i = 20
# def sum(self):
# return self.i + 20
def getI(self):
return self.i
# def sum1(self):
# return self.i + 10
b = B()
print(b.sum()) # 30
print(b.sum1()) # 30
- 编程题
定义员工类Employee,包含私有属性(姓名和月工资),以及计算年工资get_annual的方法。
普通员工(Worker)和经理(Manager)继承员工类,经理类多了奖金bonus属性和管理manage方法,普通员工类多了work方法,普通员工和经理类要求根据需要重写get_annual方法。
编写函数show emp annual(e:Employee),实现获取任何员工对象的年工资。
编写函数working(e:Employee),如果是普通员工,则调用work方法,如果是经理,则调用manage方法。
class Employee:
__name = None
__salary = None
# 构造器
def __init__(self, name, salary):
self.__name = name
self.__salary = salary
def get_annual(self):
return self.__salary * 12
def set_name(self, name):
self.__name = name
def get_name(self):
return self.__name
def get_salary(self):
return self.__salary
class Worker(Employee):
def work(self):
print(f"普通工人 {self.get_name()} 正在工作中")
class Manager(Employee):
__bonus = None
def __init__(self, name, salary, bonus):
super().__init__(name, salary)
self.__bonus = bonus
def manage(self):
print(f"经理 {self.get_name()} 正在工作中")
def get_annual(self):
return super().get_annual() + self.__bonus
def show_emp_annual(e: Employee):
print(f"{e.get_name()} 年工资: {e.get_annual()}")
worker = Worker("king", 10000)
show_emp_annual(worker)
manager = Manager("tim", 20000, 100000)
show_emp_annual(manager)
def working(e: Employee):
if isinstance(e, Worker):
e.work()
elif isinstance(e, Manager):
e.manage()
else:
print("无法确定工作状态")
working(worker)
working(manager)
[魔术方法](3. 数据模型 — Python 3.13.0 文档)
基本介绍
- 什么是魔术方法
- 在Python中,所有以双下划线
__包起来的方法,统称为Magic Method(魔术方法),它是一种特殊方法,普通方法需要调用,而魔术方法不需要调用就可以自动执行。 - 魔术方法在类或对象的某些事情发生时会自动执行,让类具有神奇的“魔力”。如果希望根据自己的程序定制特殊功能的类,那么就需要对这些方法进行重写。
- Python中常用的运算符、for循环以及类操作都是运行在魔术方法之上的。
- 在Python中,所有以双下划线
- 常见的魔术方法
| 序号 | 操作 |
|---|---|
| 1 | __init__:初始化对象的成员 |
| 2 | __str__(self):定义对象转字符的行为:print(对象)或str(对象) |
| 3 | __eq__(self, other):定义等于号的行为:x == y |
| 4 | __lt__(self, otehr):定义小于号的行为:x < y |
| 5 | __le__(self, otehr):定义小于等于号的行为:x ≤ y |
| 6 | __ne__(self, otehr):定义不等号的行为:x != y |
| 7 | __gt__(self, self):定义大于号的行为:x > y |
| 8 | __ge__(self, other):定义大于等于号的行为:x ≥ y |
__str__
- 基本介绍
- 打印对象默认返回:类型名+对象内存地址,子类往往重写
__str__,用于返回对象的属性信息。<__main__.Monster object at 0x000002414EC85070>
- 重写
__str__方法,print(对象)或str(对象)时,都会自动调用该对象的__str__。
- 打印对象默认返回:类型名+对象内存地址,子类往往重写
- 应用实例
class Monster:
name = None
age = None
gender = None
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 请输出 Monster[name, job, sal] 对象的属性信息
"""
1. 在默认情况下,调用的是父类。Monster的父类object的__str__
2. 父类object的__str__ 返回的就是类型+地址
3. 可以根据需要重写__str__
"""
def __str__(self):
# return super().__str__()
return f"{self.name} {self.age} {self.gender}"
m = Monster("青牛怪", 500, "n男")
print(m) # 默认输出类型+对象的地址
print(m, hex(id(m)))
__eq__
-
基本介绍
- == 是一个比较运算符:对象之间进行比较时,比较的内存地址是否相等,即判断是不是同一个对象。
- 重写
__eq__方法,可以用于判断对象内容/属性是否相等。
-
应用实例
判断两个Person对象的内容是否相等,如果两个Person对象的各个属性值都一样,则返回True,反之返回False。
Person类,属性(name, age, gender)
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 判断两个Person对象的内容是否相等,如果两个Person对象的各个属性值都一样,则返回True,反之返回False。
def __eq__(self, other):
# 判断other 是不是 Person
if isinstance(other, Person):
return (self.name == other.name and
self.age == other.age and
self.gender == other.gender)
return False
class Dog:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 没有重写 __eq__ 前, == 比较的是内存地址;重写 __eq__ 后, == 比较的是属性/内容
p1 = Person("smith", 20, "male")
p2 = Person("smith", 20, "male")
dog = Dog("smith", 20, "male")
print(f"p1 == p2: {p1 == p2}")
print(f"p1 == dog: {p1 == dog}")
其它几个魔术方法
-
其它几个魔术方法
__lt__(self, otehr):定义小于号的行为:x < y。__le__(self, otehr):定义小于等于号的行为:x ≤ y。__ne__(self, otehr):定义不等号的行为:x != y。__gt__(self, self):定义大于号的行为:x > y。__ge__(self, other):定义大于等于号的行为:x ≥ y。
-
应用实例
判断两个Person对象的年龄进行比较大小,重写相应的魔术方法。
Person类,属性(name, age, gender)
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 判断两个Person对象的内容是否相等,如果两个Person对象的各个属性值都一样,则返回True,反之返回False。
def __eq__(self, other):
# 判断other 是不是 Person
if isinstance(other, Person):
return (self.name == other.name and
self.age == other.age and
self.gender == other.gender)
return False
# 重写 __lt__
def __lt__(self, other):
if isinstance(other, Person):
return self.age < other.age
return "类型不一致,不能比较"
# 重写 __lt__
def __le__(self, other):
if isinstance(other, Person):
return self.age <= other.age
return "类型不一致,不能比较"
# 重写 __ne__
def __ne__(self, other):
return not self.__eq__(other)
class Dog:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 没有重写 __eq__ 前, == 比较的是内存地址;重写 __eq__ 后, == 比较的是属性/内容
p1 = Person("smith", 20, "male")
p2 = Person("smith", 20, "male")
dog = Dog("smith", 20, "male")
print(f"p1 == p2: {p1 == p2}")
print(f"p1 == dog: {p1 == dog}")
print(f"p1 < p2: {p1 < p2}")
print(f"p1 <= p2: {p1 <= p2}")
print(f"p1 != p2: {p1 != p2}")
class对象和静态方法
[class 对象](9. 类 — Python 3.13.0 文档)
- 基本介绍
- 类本身也是对象,即:Class对象。
- 应用实例
class Monster:
name = "蝎子精"
age = 300
def hi(self):
print(f"hi() {self.name} {self.age}")
# 下一个断点,可以看到Monster的情况
print(Monster)
# 通过Class对象,可以引用属性(没有创建实例对象也可以引用/访问)
print(f"Monster.name is {Monster.name} Monster.age is {Monster.age}")
# 通过类名如何调用非静态成员方法
Monster.hi(Monster)
[静态方法](描述器指南 — Python 3.13.0 文档)
@staticmethod将方法转换为静态方法。- 静态方法不会接收隐式的第一个参数,要声明一个静态方法。
class C:
@staticmethod
def f(arg1, arg2, argN): ...
- 静态方法既可以由类调用(如
C.f()),也可以由实例中调用(如C().f())。
class Monster:
name = "蝎子精"
age = 300
def hi(self):
print(f"hi() {self.name} {self.age}")
@staticmethod
def ok():
print("ok()")
# 不需要实例化,通过类即可调用静态方法
Monster.ok()
# 通过实例对象,也可以调用静态方法
monster = Monster()
monster.ok()
[抽象类](abc — 抽象基类 — Python 3.13.0 文档)
抽象类的介绍
- 基本介绍
- 默认情况下,Python不提供抽象类,Python附带一个模块,该模块为定义抽象基类提供了基础,该模块名称为
abc。 - 当我们需要抽象基类时,让类继承
ABC(abc模块的ABC类),使用@abstractmethod声明抽象方法(@abstractmethod用于声明抽象方法的装饰器,在abc模块中),那么这个类就是抽象类。 - 抽象类的价值更多作用是在于设计,是设计者设计好后,让子类基础病实现抽象类的抽象方法。
- 默认情况下,Python不提供抽象类,Python附带一个模块,该模块为定义抽象基类提供了基础,该模块名称为
快速入门
from abc import ABC, abstractmethod
# 将 Animal 做成抽象类,并让子类 Tiger 实现。
# Animal 是抽象类
class Animal(ABC):
def __init__(self, name, age):
self.name = name
self.age = age
# cry() 是抽象方法
@abstractmethod
def cry(self):
pass
# 注意:抽象类(含有抽象方法),不能实例化。
# TypeError: Can't instantiate abstract class Animal without an implementation for abstract method 'cry'
# animal = Animal("动物", 3)
# 编写子类 Tiger,继承 Animal 并实现抽象方法。
class Tiger(Animal):
def cry(self):
print('Tiger is crying')
tiger = Tiger('Tiger', 20)
tiger.cry()
注意事项和细节讨论
- 抽象类不能被实例化。
- 抽象类需要继承
ABC,并且需要至少一个抽象方法。
# 抽象类需要继承`ABC`,并且需要至少一个抽象方法。
from abc import ABC, abstractmethod
class AAA(ABC):
name = "tim"
# @abstractmethod
# def f1(self):
# pass
# 如果没有一个抽象方法,能实例化。
obj1 = AAA()
- 抽象类中可以有普通方法。
# 抽象类中可以有普通方法。
from abc import ABC, abstractmethod
class AAA(ABC):
name = "tim"
@abstractmethod
def f1(self):
pass
def hi(self):
print("hi()")
def ok(self):
pass
class BBB(AAA):
# 实现父类的f1抽象方法
def f1(self):
print("BBB-f1")
obj2 = BBB()
obj2.f1()
obj2.hi()
obj2.ok()
- 如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,否则它仍然是一个抽象类。
# 如果一个类继承了抽象类,则它必须实现抽象类的所有抽象方法,否则它仍然是一个抽象类。
from abc import ABC, abstractmethod
class AAA(ABC):
name = "tim"
@abstractmethod
def f1(self):
pass
@abstractmethod
def f2(self):
pass
def hi(self):
print("hi()")
def ok(self):
pass
class BBB(AAA):
# 实现父类的f1抽象方法
def f1(self):
print("BBB-f1")
# 如果没有完全实现AAA的抽象方法
# TypeError: Can't instantiate abstract class BBB without an implementation for abstract method 'f2'
def f2(BBB):
print("BBB-f2")
obj2 = BBB()
obj2.f1()
obj2.hi()
obj2.ok()
练习题
编写一个Employee类,做成抽象基类,包含如下三个属性:name,id,salary,提供必要的构造器和抽象方法:work()。
对应Manager类来说,他既是员工,还具有奖金(bonus)的属性,请使用继承的思想,设计CommonEmployee类和Manager类,要求实现work(),提示“经理/普通员工 名字 工作中"。
OOP基础 + 抽象类
from abc import abstractmethod, ABC
class Employee(ABC):
def __init__(self, name, id, salary):
self.name = name
self.id = id
self.salary = salary
@abstractmethod
def work(self):
pass
class CommonEmployee(Employee):
def work(self):
print(f"普通员工 {self.name} 工作中")
class Manager(Employee):
def __init__(self, name, id, salary, bonus):
super().__init__(name, id, salary)
self.bonus = bonus
def work(self):
print(f"经理 {self.name} 工作中")
manager = Manager("king", "1-111", 10000, 100000)
manager.work()
commonEmployee = CommonEmployee("time", "2-222", 5000)
commonEmployee.work()
最佳实践—模板设计模式
什么是设计模式
- 设计模式是在大量实践中总结和理论化之后优选的代码结构、编程风格、以及解决思考的思考方式。
- 设计模式就像是经典的棋谱,不同的棋局,我们用不同的棋谱,免去我们自己再思考和摸索。
模板设计模式—介绍
- 基本介绍
- 抽象类体现的就是一种模板模式的设计,抽象类作为多个子类的通用模版,子类在抽象类的基础上进行扩展、改造,但子类总体上会保留抽象类的行为方式。
- 模板设计模式能解决的问题
- 当功能内部一部分实现是确定,一部分实现是不确定的。这时可以把不确定的部分暴露出去,让子类去实现。
- 编写一个抽象父类,父类提供了多个子类的通用方法,并把一个或多个方法留给其子类实现,就是一种模板模式。
模板设计模式—最佳实践
需求:有多个类,完成不同的任务job,要求统计得到各自完成任务的时间。
- 传统方法
import time
class AA:
def job(self):
# 得到开始的时间,秒数
start = time.time()
num = 0
for i in range(1, 800001):
num += 1
# 得到结束的时间,秒数
end = time.time()
print("计算任务执行时间(秒)", (end - start))
class BB:
def job(self):
# 得到开始的时间,秒数
start = time.time()
num = 1
for i in range(1, 90001):
num -= 1
# 得到结束的时间,秒数
end = time.time()
print("计算任务执行时间(秒)", (end - start))
if __name__ == '__main__':
aa = AA()
bb = BB()
aa.job()
bb.job()
- 优化—使用模板设计模式来解决。
编写方法 calc_time(),可以计算某段代码的耗时时间。
编写抽象方法 job()。
编写一个子类,基础抽象类 Template,并实现 job 方法。
import time
from abc import abstractmethod, ABC
class Template(ABC):
@abstractmethod
def job(self):
pass
# 统计任务执行时间
def cal_time(self):
# 得到开始的时间,秒数
start = time.time()
self.job()
# 得到结束的时间,秒数
end = time.time()
print("计算任务执行时间(秒)", (end - start))
class AA(Template):
def job(self):
num = 0
for i in range(1, 800001):
num += 1
class BB(Template):
def job(self):
num = 1
for i in range(1, 90001):
num -= 1
if __name__ == '__main__':
aa = AA()
bb = BB()
aa.cal_time()
bb.cal_time()
练习
- 定义一个Person类,属性:name,age,job,创建Person,有3个person对象,并按照age从大到小排序。
class Person:
def __init__(self, name, age, job):
self.name = name
self.age = age
self.job = job
def __str__(self):
return f'{self.name}, {self.age}, {self.job}'
p1 = Person('smith', 21, 'python')
p2 = Person('king', 30, 'java')
p3 = Person('tom', 40, '老师')
my_list = [p1, p2, p3]
for p in my_list:
print(p)
# 实现按照age从大到小排序。
# 解决方案1:冒泡排序
# def bubble_sort(my_list: list[Person]):
# for i in range(1, len(my_list)):
# # j变量控制比较的次数,同时可以作为比较元素的索引下标
# for j in range(len(my_list) - i):
# # 如果前面的年龄 < 后面的年龄,就交换
# if my_list[j].age < my_list[j + 1].age:
# my_list[j], my_list[j + 1] = my_list[j + 1], my_list[j]
# bubble_sort(my_list)
# print("排序后".center(50, '='))
#
# for p in my_list:
# print(p)
# 解决方案2:直接使用列表的 .sort
# key=lambda ele: ele.age 表示指定按照列表元素的age属性进行排序。
# reverse=True 表示倒序
print("排序后".center(50, '='))
my_list.sort(key=lambda ele: ele.age, reverse=True)
for p in my_list:
print(p)
- 文件中有 Grand、Father 和 Son,问:父类和子类中通过self和super()都可以调用哪些属性和方法。
class Grand:
name = 'AA'
__age = 100
def g1(self):
print('Grand-g1()')
class Father(Grand):
id = '001'
__score = None
def f1(self):
# super() 可以访问哪些成员(属性和方法)
super().name
super().g1()
# self() 可以访问哪些成员
self.id
self.__score
self.name
self.f1()
self.g1()
print('Father-f1()')
class Son(Father):
name = 'BB'
def g1(self):
print('Son-g1()')
def __show(self):
# super() 可以访问哪些成员(属性和方法)
super().id
super().name
super().f1()
super().g1()
# self() 可以访问哪些成员
self.name
self.id
self.g1()
self.__show()
self.f1()
print('Son-show()')
- 编写Doctor类,属性:name, age, job, gender, sal 5个参数的构造器,重写
__eq__()方法,并判断测试类中创建的两个对象是否相等(相等就是判断属性是否相同)。
class Doctor:
def __init__(self, name, age, gender, sal):
self.name = name
self.age = age
self.gender = gender
self.sal = sal
def __eq__(self, other):
if not isinstance(other, Doctor):
return False
return self.name == other.name and self.age == other.age and self.sal == other.sal
doctor1 = Doctor('tom', 24, 1, 'male')
doctor2 = Doctor('tom', 24, 1, 'male')
doctor3 = Doctor('tom', 25, 1, 'male')
print(doctor1 == doctor2)
print(doctor1 == doctor3)
欢迎关注我的博客,如有疑问或建议,请随时留言讨论。


















 2439
2439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











