






问题:
如何识别一个固定视角下的视频中的红绿灯的状态?
解决思路:
将原视频转为灰度视频,这样不用区分颜色,只需要知道灯是亮还是暗。在灰度视频下选定感兴趣区域,感兴趣区域有三个分别位于三个灯的灯珠中。然后获取三个感兴趣区域中的二维数组中的数据。对三个感兴趣区域中的数据分别进行统计并找出能区分灯亮或不亮的状态的三个值。最后依据这三个值进行进行判断,得出此时红绿灯的实时状态。
流程图:
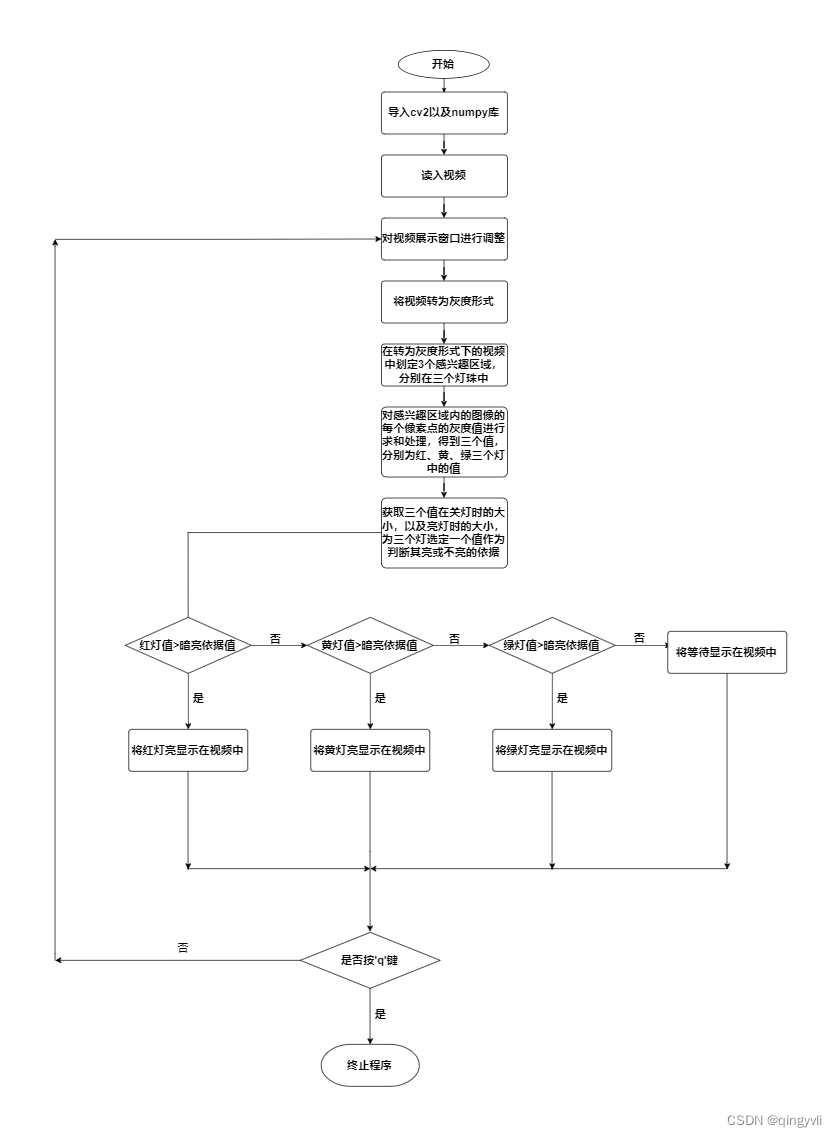
识别红绿灯状态的代码:
import cv2
import numpy as np
cap = cv2.VideoCapture('2.mp4') #读取视频
while cap.isOpened():
ret, frame = cap.read()
# 调整窗口大小
cv2.namedWindow("frame", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一致
cv2.resizeWindow("frame", 960, 540) # 设置长和宽
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #将视频转为灰度视频
#划定三个感兴趣区域分别为R, G, B
#ROI划定规则:图像矩阵名称[上 : 下, 左 : 右]
R = gray[452:454, 594:596]
Y = gray[446:448, 630:632]
G = gray[444:446, 672:674]
#使用numpy中的sum函数对感兴趣区域中的二维数组中的的元素进行求和
sum_R = np.sum(R)
sum_Y = np.sum(Y)
sum_G = np.sum(G)
#判断模块
if sum_R > 200:
# 如果R中那四个像素点的灰度值之和大于200,则显示红灯
cv2.putText(frame, 'Red light', (550, 410), 0, 2, (0, 0, 255), 3)
# 用法 putText(选定的视频[或赋予其的变量], "要显示的文字",
# 要显示的文字的位置坐标( , ), 字体[0为默认], 字体粗细程度, [颜色 BGR]( , , ,), 字体大小)
elif sum_Y > 200:
# 如果Y中那四个像素点的灰度值之和大于200,则显示黄灯
cv2.putText(frame, 'Yellow light', (550, 410), 0, 2, (0, 255, 255), 3)
elif sum_G > 200:
# 如果G中那四个像素点的灰度值之和大于200,则显示绿灯
cv2.putText(frame, 'Green light', (550, 410), 0, 2, (0, 255, 0), 3)
else:
# 如果都小于200,则显示等待
cv2.putText(frame, 'Wait', (550, 410), 0, 2, (255, 255, 255), 3)
cv2.imshow('frame', frame) #显示处理后的原视频
#按 'q' 退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() #释放
cv2.destroyAllWindows()# 用来删除窗口的,()里不指定任何参数,则删除所有窗口,删除特定的窗口,往()输入特定的窗口值。获取像素点坐标:
这部分代码只是实现了识别视频中的红绿灯状态,还需要注意的是如何选出感兴趣区域,可以使用接下来这段代码实现,接下来这段代码可以根据鼠标的左键点击选定某一像素,并将其坐标保存到一个csv文件中。这部分代码出处为bilibli,在注释中有其网址。
#导入opencv和pandas数据包
import cv2
import pandas as pd
# 导入图片
img = cv2.imread('imgs\image0.jpg') #代码参数一般是没有问题的,一本如果不能实现在图上标点的话,基本上都是导图图片出错了
# 建立空列表存放像素坐标
a =[]
b = []
def on_EVENT_LBUTTONDOWN(event, x, y, flags, param):
# 点击鼠标左键
if event == cv2.EVENT_LBUTTONDOWN:
xy = "%d,%d" % (x, y)
a.append(x)
b.append(y)
cv2.circle(img, (x, y), 1, (255, 0, 0), thickness=-1)
cv2.putText(img, xy, (x, y), cv2.FONT_HERSHEY_PLAIN,
1.0, (0, 0, 0), thickness=1)
cv2.imshow("image", img)
cv2.namedWindow("image") #设置窗口名称
cv2.setMouseCallback("image", on_EVENT_LBUTTONDOWN)
cv2.imshow("image", img) #显示图片
cv2.waitKey(0) #按任意键结束程序,之后会得到文件
# print(a[0],b[0])
# 保存数据
data = [a,b]
data = pd.DataFrame(data, index=['h', 'l'] )
#像素坐标保存,r'C:\Users\ASUS\Desktop\ccnu.csv'位置
data.to_csv(r'C:\Users\36204\Desktop\ccnu.csv')
#注意建立的存储像素坐标的格式表格是csv,不是excel默认格式xlsx,否则数据是无妨保存,不信可以试试看。“把这行的csv,改成xlsx格式
#注意点像素坐标时,只能是一次,下次再点时原来的数据就会消失,要特别注意 作者:陶然临风 https://www.bilibili.com/read/cv14973014 出处:bilibili还有一点需要注意,获取像素坐标的代码是获取图片中的像素坐标,所以需要一张由该视频导出的图片,用接下来这部分代码实现。这部分代码获取自一位CSDN博主。
import cv2
import subprocess
video_path = '2.mp4'
# 指定路径下的视频文件
image_save = 'picture'
# 保存的图片路径
cap = cv2.VideoCapture(video_path)
# 从路径捕获视频文件
frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT)
# 获取视频总帧数
for i in range(0,1): # 逐帧抓取图片
_, img = cap.read()
# read返回两个参数,第一个为布尔值,表示有没有读取到图片
# 第二个参数img表示截取到一帧的图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # cv2.COLOR_RGB2HSV cv2.COLOR_BGR2GRAY
# 将每帧图片存储为灰度图
cv2.imwrite((image_save + '/image{}.jpg').format(i), img)
# 将图片以统一命名格式存储在路径下如果想要更多该视频的图片可以修改range的范围,获取该视频的每一张图片可以改为
range(int(frame_count))
获取用于鉴别等的亮暗的值:
视频是由一张张图片构成的,储存这些图片用到的是数组,对视频或图像进行的数据统计,就是对这些数组的统计,灰都图像储存时用的是二维数组,每个像素点用一个值(我用的视频是八位深度的,0~255),然后组成行和列构成一个二维数组。彩色图像用的是三位数组,每个像素由三个值的一维数组表示,三个值分别代表红绿蓝三个颜色的亮度,由此一维数组组成行和列,所以储存一张彩色图片的是一个三维数组。
这里仅用到灰度图像,所以是对二维数组进行处理,可以使用print(要显示的视频或图片[前提是视频或图像已被读入])来观察数值变化并选取。因为我做的时候,转为灰度视频后,发现它的亮度变化很明显,使用print打印出数组后也能轻易的得知其状态变化时数据的变化,可以通过直观感受直接选取该值,我就没有使用复杂的方法。

总结:
这是我上的有关深度学习的第一个课程的第一个作业,只是个开始还未涉及非常困难的问题,但通过这次作业我知道了视频信息处理的大概流程,以及我要处理的数据是数组。还有编程遇到问题时该做什么。















 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









